自动驾驶 | SparseVideoNav: 视频生成模型驱动的超视距导航系统
- 2026-05-08 23:44:55
自动驾驶 | SparseVideoNav: 视频生成模型驱动的超视距导航系统
0. 引言
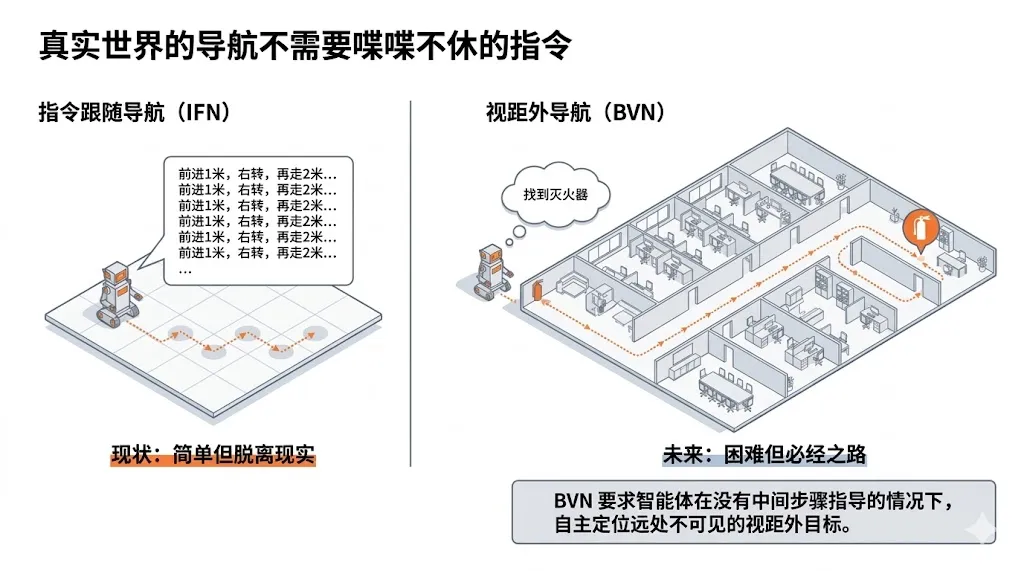
在机器人导航领域,一个长期存在的挑战是如何让机器人像人类一样,仅凭简单的高层次指令就能自主导航到视野之外的目标位置。想象这样一个场景:你对机器人说"去院子里找垃圾桶",而垃圾桶远在几十米外,完全不在当前视野范围内。这种被称为"超视距导航"(Beyond-the-View Navigation, BVN)的任务,对现有的导航系统提出了严峻考验。
SparseVideoNav 是由 OpenDriveLab 团队开发的一套创新性具身智能导航系统,它首次将视频生成模型(Video Generation Models, VGMs)引入真实世界的超视距导航任务中。这一突破性工作不仅在技术范式上实现了重大创新,更在实际部署中展现出卓越的性能表现。该系统能够在亚秒级时间内完成轨迹推理,相比未优化版本实现了惊人的27倍速度提升,并在六个真实场景的零样本测试中,成功率达到现有最先进大语言模型基线的2.5倍。
Github地址:https://github.com/OpenDriveLab/SparseVideoNav

1. 现有导航系统的"短视"困境
1.1 视觉语言导航的发展现状
视觉语言导航(Vision-Language Navigation, VLN)技术使机器人能够根据自然语言指令和视觉观测执行复杂的导航任务。近年来,大语言模型(Large Language Models, LLMs)的兴起为这一领域带来了显著突破。以 Uni-NaVid、StreamVLN 和 InternVLA-N1 为代表的方法,通过将视觉信息与语言理解能力相结合,在模拟环境和部分真实场景中取得了令人瞩目的成果。
然而,这些基于大语言模型的方法存在一个根本性的矛盾:它们高度依赖密集、渐进式的指令引导(Instruction-Following Navigation, IFN)。在这种模式下,系统需要详细的分步指令,例如"向前走10米,在第二个路口左转,然后继续直行至走廊尽头"。这种详尽的指导虽然降低了决策难度,但与真实世界的交互需求背道而驰。在实际应用中,用户更倾向于给出简单的高层次意图,如"去会议室"或"找到最近的充电站"。
1.2 短时序监督的局限性
现有基于大语言模型的导航方法在训练过程中通常采用短时序监督信号,监督范围一般为4到8个时间步。这种设计源于大语言模型的架构特性和训练稳定性考虑。然而,这种短视野的监督机制在面对超视距导航任务时暴露出严重的缺陷。
当目标位置远在视野之外时,机器人必须在长距离范围内进行路径规划和决策。短时序监督导致模型只能"看到"未来几步的情况,无法形成对远距离目标的整体认知。这种局限性在实际部署中表现为两种典型的失败模式:第一,由于无法观测到远处的目标,系统面临巨大的不确定性,常常出现非预期的转向行为或在原地打转;第二,当机器人误入死胡同时,由于缺乏长远规划能力,系统会错误地认为路径已到尽头,从而陷入困境无法脱身。

1.3 扩展监督视野的困境
一个看似直接的解决方案是延长监督时序的长度,让模型能够"看得更远"。然而,研究人员在实践中发现,简单地扩展大语言模型的监督视野会导致训练过程极其不稳定。这种不稳定性源于大语言模型的架构特性:当输入序列过长时,模型难以有效地捕捉长距离依赖关系,梯度传播也会遇到困难。此外,长序列训练还会显著增加计算开销和内存占用,使得训练成本急剧上升。
正是在这样的技术困境下,研究团队开始思考:是否存在一种天然适合处理长时序信息的模型架构?这个问题的答案指向了一个在计算机视觉领域快速发展的方向——视频生成模型。
2. 视频生成模型:天然的长时序预测者
2.1 视频生成模型的独特优势
视频生成模型在预训练阶段就被设计用来捕捉和生成连续的视觉动态变化。与大语言模型主要处理离散的文本符号不同,视频生成模型需要理解物理世界中的运动规律、场景变化和时空关系。这种特性使其天然具备捕捉长时序未来动态的能力,并且能够将这些动态与语言指令进行对齐。
近年来,以 Sora、Wan 等为代表的视频生成模型在生成质量和时长上都取得了突破性进展。这些模型能够根据文本描述生成长达数十秒的连贯视频,展现出对复杂场景动态的深刻理解。SparseVideoNav 的研究团队敏锐地意识到,这种能力正是解决超视距导航问题的关键。如果能让机器人在"脑海"中预演未来的导航过程,生成一段从当前位置到目标位置的视频,那么就能为决策提供长时序的指导信息。
2.2 从连续到稀疏:范式创新的起点
尽管视频生成模型展现出巨大潜力,但直接将其应用于机器人导航仍面临严峻挑战。传统的视频生成范式要求生成连续、流畅的视频帧序列。对于一段20秒的导航过程,如果以每秒4帧的频率生成,就需要生成80帧连续的图像。这种密集的生成过程带来了两个致命问题:首先,计算开销极其庞大,即使使用高性能GPU,生成一段完整视频也需要数十秒甚至更长时间,完全无法满足实时导航的需求;其次,训练这样的模型需要海量的计算资源和时间成本。
研究团队在深入分析后提出了一个关键洞察:对于导航任务而言,是否真的需要生成每一帧连续的画面?人类在规划路径时,往往只需要在脑海中想象几个关键的场景节点,而不是完整的连续画面。受此启发,SparseVideoNav 提出了"稀疏视频生成"(Sparse Video Generation)的创新范式。
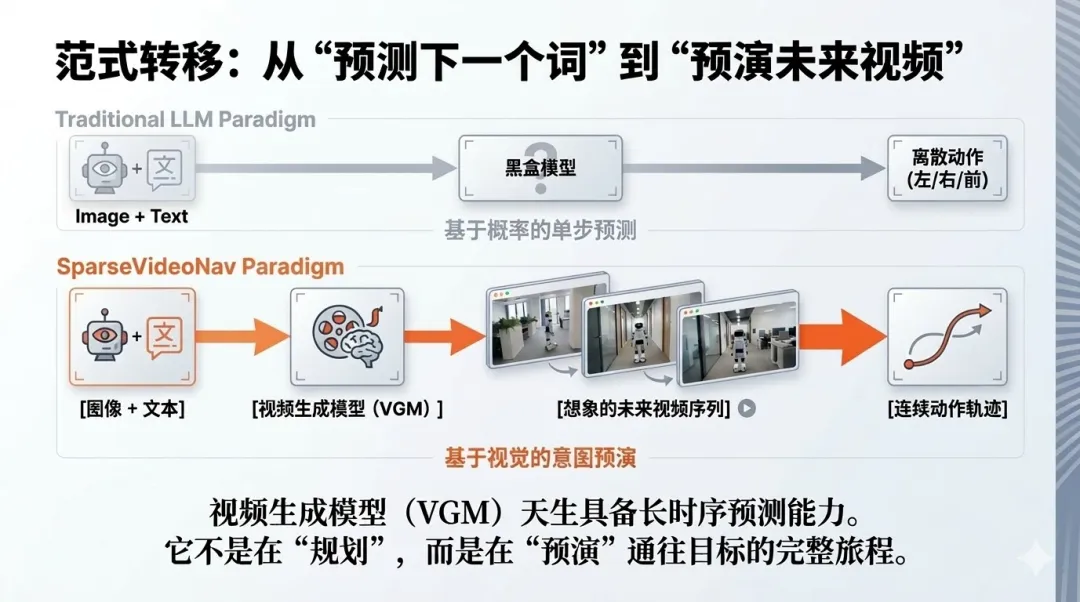
2.3 稀疏视频生成的设计原理
稀疏视频生成的核心思想是战略性地选择关键时间步进行帧生成,而非生成所有连续帧。具体而言,SparseVideoNav 采用固定间隔采样策略,在20秒的预测视野内,仅生成8个关键帧。这些帧对应的时间步为 [T+1, T+2, T+5, T+8, T+11, T+14, T+17, T+20],其中T表示当前时刻。
这种设计经过了精心的权衡考量。研究团队通过大量实验发现,将采样间隔设置为3能够在预测视野长度和视觉保真度之间取得最佳平衡。值得注意的是,为了确保动作预测的准确性,系统对前两个观测块(covering 8 timesteps)保持连续生成,这样既保证了近期动作的精确性,又通过稀疏采样实现了对远期场景的覆盖。
这一创新带来了双重优势:首先,在保持20秒长时序预测能力的同时,大幅降低了计算开销,使得训练速度提升1.4倍,推理速度提升1.7倍;其次,稀疏的监督信号反而帮助模型更好地聚焦于关键的场景变化,避免了在冗余信息上的过度拟合。

3. 系统架构与四阶段训练流程
SparseVideoNav 的成功不仅依赖于稀疏视频生成的范式创新,更得益于精心设计的系统架构和结构化的训练流程。整个系统采用模块化设计,通过四个递进的训练阶段,逐步构建起完整的导航能力。
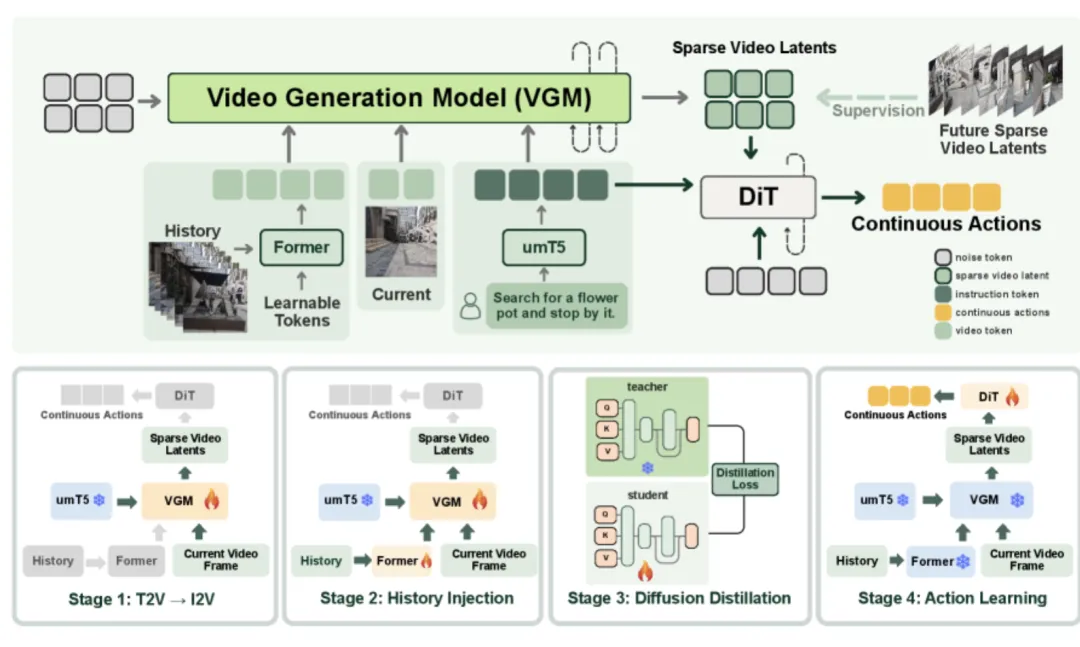
3.1 整体架构设计
系统的核心由两大组件构成:视频生成模型骨干网络和基于扩散变换器(DiT)的动作预测头。视频生成模型负责根据当前观测、历史观测序列和语言指令,生成未来的稀疏视频潜在表示。这些生成的未来场景随后与语言指令一起,被输入到动作预测头中,最终输出连续的导航动作序列。
为了处理长时序的历史观测信息,系统引入了双重压缩机制。Q-Former 负责沿时间维度压缩特征,将长序列的历史观测浓缩为紧凑的时序表示;Video-Former 则负责沿空间维度压缩特征,提取关键的视觉信息。这种双重压缩策略使得系统能够高效地处理任意长度的历史信息,而不会导致计算开销随历史长度线性增长。
3.2 阶段一:从文本到图像的视频生成适配
训练流程的第一阶段旨在将预训练的文本到视频(T2V)模型转换为图像到视频(I2V)模型。这一转换至关重要,因为原始的T2V模型主要依赖文本指令生成视频,而导航任务需要生成的未来场景必须与机器人当前的视觉观测保持高度的物理一致性。
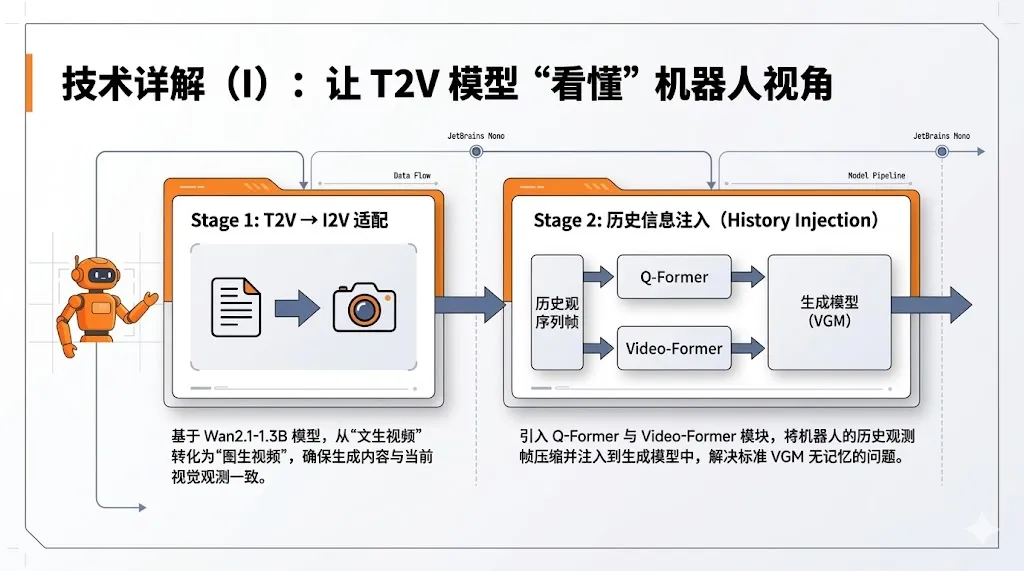
SparseVideoNav 选择 Wan2.1-1.3B 作为基础模型。Wan 采用三维因果变分自编码器(3D Causal VAE)结构,能够将视频压缩到潜在空间进行高效处理。在这一阶段,系统保留了 Wan 原有的流匹配(Flow Matching)训练目标,通过在真实导航数据上进行微调,使模型学会根据当前观测帧生成与之连贯的未来场景。这个过程类似于教会模型"看图说话"的能力,让它能够基于视觉输入而非仅凭文本描述来想象未来。
3.3 阶段二:历史信息的注入与融合
导航任务的一个关键特征是需要利用完整的历史观测序列。机器人需要记住自己走过的路径、见过的场景,这些信息对于理解当前位置和规划未来路径至关重要。然而,视频生成模型的标准架构并不具备处理长序列历史输入的能力。
为解决这一问题,第二阶段在 Wan 骨干网络的每个 Transformer 块中引入了额外的交叉注意力层。这些新增的注意力层专门用于注入历史信息,使模型能够在生成未来场景时参考过去的观测。为了保持第一阶段学到的生成先验知识,系统采用了一个巧妙的初始化策略:将新增交叉注意力层的最终线性层权重初始化为零,这样在训练初期,新增模块不会对原有模型的输出产生影响,而是逐渐学习如何有效利用历史信息。
然而,直接将完整的历史观测序列输入模型会带来巨大的计算负担。一段典型的导航过程可能包含数十甚至上百帧的历史观测,如果不加处理地输入,会导致内存占用和计算时间急剧增加。为此,系统采用了前文提到的双重压缩策略:Q-Former 首先沿时间维度提取关键的时序特征,将长序列压缩为固定长度的表示;随后 Video-Former 沿空间维度进一步压缩,提取最重要的视觉特征。这种设计使得系统能够以恒定的计算开销处理任意长度的历史,实现了效率与性能的平衡。
3.4 阶段三:扩散蒸馏实现实时推理
尽管经过前两个阶段的训练,模型已经具备了生成高质量未来场景的能力,但推理速度仍然是实际部署的瓶颈。传统的扩散模型需要经过数十步甚至上百步的去噪过程才能生成清晰的图像。对于导航场景而言,这个问题尤为严重,因为导航环境中的场景变化剧烈、动态复杂,少步去噪往往难以生成高保真的画面。
第三阶段通过扩散蒸馏技术从根本上解决了这一延迟瓶颈。系统采用基于相位的一致性模型(Phase-based Consistency Model, PCM)方法,将其适配到流匹配范式中。具体而言,将第二阶段训练好的模型作为教师模型,初始化一个结构相同的学生模型。训练过程中,将噪声调度划分为4个阶段,学生模型学习直接预测教师模型在概率流常微分方程轨迹上每个阶段的解点。
通过最小化相邻时间步之间的一致性损失,学生模型逐步学会用更少的步数达到与教师模型相当的生成质量。最终,系统成功将推理所需的去噪步数从50步压缩至仅4步,实现了约10倍的推理加速。实验结果表明,蒸馏后的模型在仅用4步去噪的情况下,生成的视频质量与原始50步模型基本相当,这为实时部署奠定了坚实基础。

3.5 阶段四:动作学习与域对齐
最后一个阶段的任务是将生成的稀疏未来视频转化为具体的导航动作。系统冻结已蒸馏的I2V模型权重,采用逆动力学(Inverse Dynamics)范式训练动作预测头。这个基于扩散变换器架构的动作头接收生成的稀疏未来场景和语言指令作为输入,通过交叉注意力机制融合这些信息,最终输出连续的动作序列。
然而,这里存在一个微妙但关键的问题:生成的未来场景与真实场景之间存在视觉域偏差。即使生成质量很高,生成图像在纹理、光照、细节等方面仍与真实拍摄的图像有所差异。如果直接使用真实场景对应的动作标签来监督基于生成场景的动作预测,会导致监督信号的不对齐,影响最终的动作预测精度。
为解决这一问题,研究团队提出了一个创新的解决方案:使用 Depth Anything 3 (DA3) 深度估计模型对生成的视频重新提取动作标签。DA3 能够从单目图像中估计深度信息,进而推算相机的运动轨迹。通过这种重标注(Relabeling)策略,系统确保了动作监督信号与生成视频在视觉域上的绝对对齐,从而保证了动作预测的准确性。
4. 大规模真实世界数据集的构建
4.1 数据采集的挑战与策略
与基于大语言模型的导航方法不同,视频生成模型无法简单地通过混合仿真数据和真实世界视觉问答数据集来缓解仿真到真实的域差距。完全依赖仿真数据训练的视频生成模型往往会出现模式崩溃(Mode Collapse)现象,生成的视频缺乏真实世界的多样性和复杂性。此外,现有的真实世界导航数据集要么存在严重的鱼眼畸变,要么规模过小,都不适合用于微调视频生成模型。
面对这一困境,研究团队决定从零开始构建一个大规模、高质量的真实世界导航数据集。数据采集过程采用人工操作员手持稳定相机的方式进行。为了最大限度地减少人体抖动对视频质量的影响,团队选用了配备 RockSteady+ 稳定系统的 DJI Osmo Action 4 相机。这种稳定技术对于视频生成模型学习一致的动态变化至关重要,因为过度的抖动会干扰模型对场景运动规律的理解。
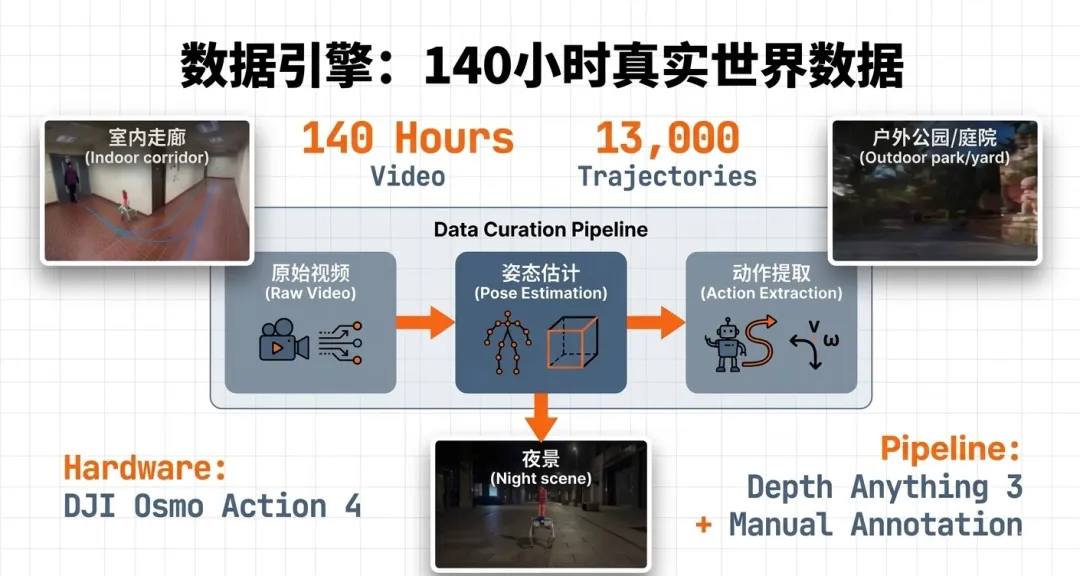
4.2 数据规模与处理流程
经过数月的持续采集,团队累积了约140小时的真实世界导航视频数据,覆盖了室内、室外、白天、夜晚等多种场景。这些原始视频通过均匀时间采样被处理成约13,000条导航轨迹,每条轨迹平均长度为140帧(以4 FPS采样)。这一数据规模在真实世界视觉语言导航领域达到了前所未有的水平,为模型的泛化能力提供了坚实保障。
数据标注过程分为两个部分。首先,使用 Depth Anything 3 对所有视频进行相机位姿估计,提取连续的动作标签。这个过程完全自动化,确保了标注的一致性和效率。其次,语言指令由人类专家手工标注,确保指令的自然性和准确性。这种半自动化的标注策略在保证质量的同时,大幅降低了标注成本。
5. 技术创新的深层洞察
5.1 为何视频生成模型更适合导航任务
SparseVideoNav 的成功揭示了一个重要的技术洞察:视频生成模型与导航任务之间存在天然的契合性。这种契合性源于两者在本质上的相似性——都需要理解和预测物理世界中的动态变化。
大语言模型虽然在语言理解和推理方面表现出色,但其预训练主要基于文本数据,缺乏对物理世界动态规律的直接建模。当面对导航任务时,大语言模型需要将视觉观测转换为抽象的语义表示,再基于这些表示进行推理和决策。这个过程中,大量的空间和动态信息在抽象过程中丢失,导致模型难以形成对未来场景的具体想象。
相比之下,视频生成模型在预训练阶段就学习了物体运动、场景变化、视角转换等物理世界的基本规律。这些知识使其能够根据当前观测和语言指令,直接在像素空间生成未来的场景画面。这种端到端的视觉预测能力为导航决策提供了更加直观和丰富的信息,特别是在处理长距离、复杂环境的导航任务时优势明显。
5.2 稀疏性的哲学:少即是多
稀疏视频生成范式的提出,体现了"少即是多"的设计哲学。在机器学习领域,人们往往倾向于认为更多的信息总是更好的。然而,SparseVideoNav 的实践表明,在特定任务中,精心选择的稀疏信息可能比密集的完整信息更加有效。
这一现象背后有深刻的原因。首先,从信息论角度看,导航决策所需的关键信息主要集中在场景的重要变化点,而连续帧之间的大量冗余信息对决策的边际贡献很小。通过稀疏采样,系统能够聚焦于真正重要的场景变化,避免在冗余信息上浪费计算资源。其次,从学习理论角度看,稀疏监督信号可能帮助模型学习更加鲁棒的表示,因为模型必须学会从有限的关键帧中推断整体的运动趋势,而不是依赖于连续帧之间的微小变化。
5.3 四阶段训练的系统工程智慧
SparseVideoNav 的四阶段训练流程体现了深刻的系统工程智慧。这种渐进式的训练策略并非简单的工程技巧,而是基于对问题本质的深刻理解。
第一阶段的 T2V 到 I2V 适配,解决了视觉一致性问题。如果跳过这一阶段直接训练,模型可能会生成与当前观测不一致的未来场景,导致导航决策失去可靠的基础。第二阶段的历史注入,使模型具备了时序推理能力。通过零初始化策略,系统在保留第一阶段学到的生成先验的同时,逐步学习如何利用历史信息。第三阶段的扩散蒸馏,是实现实时部署的关键。这一阶段的成功依赖于前两阶段已经训练出高质量的教师模型。第四阶段的动作学习,通过重标注策略解决了域对齐问题,确保了整个系统的端到端优化。
这种分阶段训练的策略相比端到端联合训练有明显优势。实验表明,直接从头训练第二阶段需要64小时才能收敛,而采用渐进式策略仅需32小时,实现了2倍的训练加速。这种效率提升不仅节省了计算资源,也使得研究迭代更加快速。
6. 结论
SparseVideoNav 代表了视觉语言导航领域的一次重要突破。通过将视频生成模型引入超视距导航任务,并创新性地提出稀疏视频生成范式,该系统成功解决了现有方法面临的短视问题。精心设计的四阶段训练流程、大规模真实世界数据集的构建,以及一系列工程优化措施的协同作用,使得系统在保持长时序预测能力的同时,实现了实时推理的目标。
在六个真实场景的零样本测试中,SparseVideoNav 的成功率达到现有最先进方法的2.5倍,并首次实现了夜间超视距导航能力。这些成果不仅验证了技术方案的有效性,也为具身智能领域开辟了新的研究方向。系统能够成功应对死胡同、狭窄坡道、高倾角山坡等极具挑战性的场景,展现出卓越的导航能力。
更重要的是,SparseVideoNav 的成功揭示了一个深刻的洞察:在选择技术方案时,应该深入分析任务的本质特征,选择与任务特性最匹配的模型架构。视频生成模型天然具备的长时序动态建模能力,使其成为导航任务的理想选择。稀疏视频生成范式的提出,则展示了如何通过精心的设计在性能和效率之间取得最佳平衡。
更多ROS、具身智能相关内容,请关注古月居
👉 关注我们,发现更多有深度的自动驾驶/具身智能/GitHub 内容!
🚀 往期内容回顾 👀
🔥 十分钟读论文 | DepthVLA:赋予机器人精确空间感知的视觉-语言-动作模型🔥 具身智能 | ACoT-VLA: 让机器人在动作空间中思考🔥 读读代码 | Qwen3-VL 深度源码分析:视觉语言多模态模型的完整解剖
随机文章
-
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
- 远离自动驾驶运营车辆
- 让普通割草机变身"自动驾驶高手"-智能导航控制系统
- 比亚迪闪充旗舰SUV预售订单破10万
- 自动驾驶聊了这么多年 我为什么还是更信自己这双手
- 奔驰终于看清局势了,豪华中型SUV标杆降到25万出头
- 16万落地买德系SUV,探岳比途观L更值吗?你得先想清楚这几点
- 韩系轿车竟比自家高端品牌还豪华!新款现代Grandeur曝光,内饰太惊艳了!
- 山东滨州通报路面塌陷致1辆轿车陷入:被困车辆已移出,无人员受伤,塌陷原因系地下管网跑漏水冲刷路基所致
- 5月2日,4款旗舰SUV即将上市,售价30-50万
- 2026年最新!佳木斯至博尔塔拉轿车托运费用大揭秘,价格让你
