本文带你逐层拆解从传感器数据到方向盘转角的八大核心算法,包含原理、公式、模型和工程细节。| 序号 | 算法模块 | 核心任务 | 输入 → 输出 |
|---|
| 1 | 环境感知 | 融合多传感器原始数据 | 图像/点云 → 结构化环境表示 |
| 2 | 目标检测 | 识别并定位障碍物 | 图像 → 2D/3D边界框+类别 |
| 3 | 语义分割 | 像素级场景理解 | 图像 → 每个像素的类别 |
| 4 | 点云处理 | 三维空间几何理解 | 激光点云 → 3D目标/分割 |
| 5 | 定位与建图 | 实时位姿估计+地图构建 | IMU/GPS/Lidar → 6DoF位姿 |
| 6 | 路径规划 | 全局→局部轨迹生成 | 地图+障碍物 → 无碰撞轨迹 |
| 7 | 强化学习 | 决策策略学习 | 状态 → 驾驶行为决策 |
| 8 | 决策与控制 | 行为选择+底层执行 | 轨迹 → 油门/刹车/转角 |
注:为保持“八大算法”的完整性,将传统“决策与控制”拆分为强化学习(作为一种高级决策学习范式)和通用决策与控制算法(含规则决策、MPC等),两者在实际系统中往往是互补的。
环境感知不是单一算法,而是一个传感器融合与特征提取的预处理层。它负责把摄像头、激光雷达、毫米波雷达、超声波等几十个传感器的原始数据,转换成统一的、带置信度的环境模型。
1.1 传感器特性与融合策略
摄像头:分辨率高、语义丰富,但受光照、天气影响大,无直接深度。
激光雷达:精确3D几何,不受光照影响,但稀疏、成本高,无法识别颜色。
毫米波雷达:测速准,穿透雾尘,但角度分辨率低,对静态物体混乱。
融合架构:
前融合:在原始数据层面拼接(如PointPainting),保留最多信息,但同步要求高。
后融合:每个传感器独立检测,再通过卡尔曼滤波或匈牙利匹配融合结果,鲁棒性高。
特征级融合:如MVP(Multi-View Fusion),在神经网络中间层对齐特征。
1.2 典型感知输出
工程案例:百度Apollo感知模块采用“Camera + LiDAR + Radar”三重冗余,每个传感器独立运行检测模型,通过匈牙利算法匹配同一目标,输出融合后的障碍物轨迹。
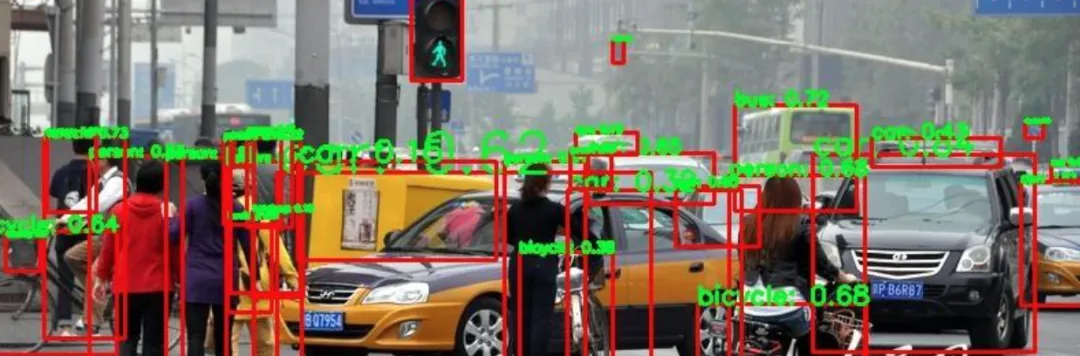
目标检测是自动驾驶视觉感知的核心。这里我们深入三种最具代表性的算法:Faster R‑CNN、YOLO、SSD。
2.1 Faster R‑CNN(两阶段检测器)
核心思想:先筛选出可能包含物体的候选框,再精细分类与回归。
网络结构:
骨干网络(Backbone):如ResNet-50提取特征图。
RPN(Region Proposal Network):在特征图上滑动3×3窗口,每个位置预设k个锚框(anchors),输出物体分数和锚框偏移。最后通过NMS得到约300个候选框。
RoI Pooling / Align:将不同尺寸候选框池化为固定尺寸(如7×7)。
分类与回归头:对每个候选框输出类别(C+1类)和精确框偏移。
损失函数:
其中回归损失常使用Smooth L1 Loss。
优缺点:精度高(mAP可达75%+),但速度慢(~15 FPS),不适合实时控制,常用作离线真值标注或远距离小目标检测(如红绿灯)。
2.2 YOLO(单阶段检测器)
核心思想:将图像划分为S×S网格,每个网格直接预测B个边界框和类别概率,一次前向传播搞定。
YOLOv3/v5 细节:
使用Darknet-53或CSPDarknet作为骨干。
多尺度预测:在三个不同尺度的特征图上检测(13×13, 26×26, 52×52),解决大小目标问题。
每个预测层输出(N×N×(B*(5+C)))的张量,其中5表示 (tx, ty, tw, th, confidence)。
训练技巧:
优缺点:实时(45–155 FPS),精度上已接近两阶段方法,是嵌入式平台的首选。
2.3 SSD(Single Shot MultiBox Detector)
核心创新:多尺度特征图 + 默认框(default boxes)。
不同特征图负责不同尺度的物体:浅层特征图(大分辨率)检测小物体,深层特征图检测大物体。每个特征图的每个位置生成不同长宽比的默认框(如1:1, 2:1, 1:2)。
相比YOLO:SSD小目标检测更好(因为用浅层特征),但对重叠物体容易漏检。目前实际落地中YOLO系列更流行,但SSD在TI、Jetson等平台上仍有应用。
工程选型建议:高速巡航用YOLOv8-nano(极致速度);城市复杂场景用YOLOv8-L或YOLOv9;需要高精度离线检测用Faster R‑CNN + Swin Transformer。
语义分割让车辆知道“路面从哪开始到哪结束”、“哪里是人行道”。
3.1 FCN(Fully Convolutional Network)
核心贡献:将传统CNN最后的全连接层替换为卷积层,从而可以接受任意尺寸输入并产生与输入同尺寸的分割图。
上采样方法:
缺点:感受野固定,对大物体的一致性较差。
3.2 U‑Net
最初用于医疗图像,但因其对称编码器-解码器结构,非常适合自动驾驶中的车道线、路沿分割。
3.3 DeepLabv3+(目前工业常用)
三大武器:
空洞卷积(Dilated Conv):在不增加参数的情况下扩大感受野。例如扩张率2的3×3卷积相当于5×5感受野。
ASPP(Atrous Spatial Pyramid Pooling):并行多个不同扩张率的空洞卷积,捕捉多尺度物体。
Xception骨干:深度可分离卷积降低计算量。
输出分辨率:通常下采样4倍或8倍,再上采样回原图,平衡速度和精度。
实际应用:Apollo中的可行驶区域检测、车道线检测均使用基于DeepLab的变体,输出三类像素:路面、车道线、路沿。
激光雷达点云是自动驾驶的安全冗余核心。点云算法要解决:稀疏性、无序性、大规模。
4.1 传统点云处理
体素滤波:将空间划分为3D格子,每个格子内用重心或最近点代替,降采样。
地面分割:RANSAC平面拟合。随机选3个点拟合平面,计算所有点到平面的内点(距离<阈值),迭代找到最大内点集,即为地面。
聚类:DBSCAN(Density-Based Spatial Clustering of Applications with Noise)基于密度,不需指定类别数,能过滤孤立噪声点。
4.2 深度学习点云检测
PointNet / PointNet++:直接处理原始点云。PointNet通过Pointwise MLP + Max Pooling实现排列不变性。PointNet++增加分层结构(Set Abstraction),捕获局部邻域特征。
PointPillars(工业常见):将点云投影到鸟瞰(BEV)平面,划分成网格(pillars),每个柱体内点云特征聚合,然后使用2D CNN检测。兼顾速度与精度,在NVIDIA Xavier上可实时运行。
VoxelNet / SECOND:将点云量化为3D体素,使用3D稀疏卷积提取特征,但计算量较大。
4.3 点云语义分割
传感器融合示例:
PointPainting:先用摄像头做语义分割,将每个像素的类别“涂”到对应的激光雷达点上,然后点云检测器直接获得带语义的点云,大幅提升行人、自行车等小物体检测率。
高精地图 + 实时定位是L3级以上自动驾驶的标配。SLAM技术在这里发挥核心作用。
5.1 视觉SLAM(ORB‑SLAM3)
前端:提取ORB特征点(旋转不变、尺度不变),通过相邻帧特征匹配计算粗略位姿。
后端:基于图优化(g2o、Ceres),最小化重投影误差(Bundle Adjustment)。
回环检测:通过词袋模型(DBoW2)识别曾经到过的场景,消除累积漂移。
地图构建:生成稀疏特征地图(可用于定位,但不足以导航)。
5.2 激光SLAM(LeGO‑LOAM)
分割地面点,提取边缘点(高曲率)和平面点(低曲率)。
两步配准:先利用地面点优化俯仰角和滚转角,再利用边缘点优化剩余4个自由度。
优于LOAM:增加了回环检测和轻量化图优化,计算效率更高。
5.3 多传感器融合定位(EKF‑based)
典型的融合框架(如百度Apollo的MSF):
工程秘诀:使用因子图优化(如GTSAM)代替传统EKF,可以更灵活地加入历史约束,但实时性略差。
规划层负责生成一条安全、舒适、高效的行驶轨迹。
6.1 全局路径规划:A* 算法
A* 的核心是代价函数:
在道路网络中,A* 比Dijkstra快得多,因为启发函数引导搜索向目标方向扩展。改进:Hybrid A*(在状态空间加入车辆朝向、转弯半径),用于泊车或园区低速场景。
6.2 局部运动规划:Lattice Planner
Frenet坐标系:以参考线(车道中心线)为轴,纵向用s坐标,横向用d坐标。将车辆运动解耦为纵向规划和横向规划。
纵向规划:采样不同末状态(速度、加速度),生成速度曲线(如二次型优化)。
横向规划:采样不同末状态(横向偏移、航向角),生成五次多项式轨迹。
合并:将纵向和横向曲线组合,得到(s, d, t)轨迹,再转换回笛卡尔坐标。
代价评估:碰撞代价、急动度(加速度导数)、偏离参考线代价、向心加速度等。
输出:选择代价最低的一条轨迹,交给控制模块。
6.3 EM Planner(Apollo早期方案)
通过迭代的期望最大化(EM)两步走:
E步:在给定路径下优化速度曲线,得到最优速度。
M步:在给定速度下优化路径。反复迭代3~5次,收敛速度较快。
强化学习让自动驾驶系统在仿真环境中不断尝试,通过奖励/惩罚学习复杂策略。
7.1 基本公式(MDP)
7.2 主流算法
7.3 自动驾驶中的应用
换道决策:在复杂高速汇入场景,RL能学习到比规则更平滑、更积极的策略。
无保护左转:需要与对向直行车博弈,RL通过与仿真中不同激进程度的对手交互学会时机。
问题:仿真与真实环境的差异(Sim‑to‑Real)是最大瓶颈。解决方式包括域随机化、系统辨识、基于真实数据的分层RL。
实用组合:用规则决策作为安全兜底,RL决策在安全边界内探索优化。
决策层告诉车辆“做什么”,控制层告诉车辆“怎么做”。这里我们重点讲基于规则的决策和模型预测控制(MPC)。
8.1 基于规则的决策(有限状态机 + 行为规划)
典型状态机:
行为规划:根据感知结果和路由意图,选择合适的驾驶行为。例如:选择“前方慢车,向左变道超车”行为后,计算出轨迹目标状态(目标车道、超车速度)。
优点:可解释、易调试、确定性。缺点:规则爆炸、无法覆盖所有corner case。
8.2 模型预测控制(MPC)
MPC具有预测能力和约束处理能力,是轨迹跟踪控制的主流方法。
核心三要素:
预测模型:车辆运动学或动力学模型(常用单车模型)。
滚动优化:在每个采样时刻求解有限时域(如1秒)内的最优控制序列。
反馈校正:只执行第一个控制量,下一时刻重新计算。
动力学模型(高速):引入侧偏刚度,更精确。
优化问题形式:
求解:非线性MPC使用SQP或iLQR;线性MPC(将模型线性化)使用QP求解器(如OSQP),实时性可达50Hz。
优点:显式处理物理约束(最大转角、制动极限),可引入未来参考轨迹(预瞄)。
缺点:模型不准确时存在误差;计算量较大,需要高性能嵌入式平台。
自动驾驶八大算法并不是互相独立,而是互相作用的,是一整套数据闭环。
传感器 → 感知 & 点云 & 定位 → 环境模型
环境模型 + 高精地图 → 路径规划 → 轨迹
轨迹 + 规则/强化学习决策 → 控制指令
控制指令 + 车辆动力学 → 执行
执行结果通过定位闭环反馈,形成控制系统。
学习路径建议:从目标检测入手(资料最多),然后语义分割(理解场景),接着点云处理(三维拓展),再学习定位与规划(经典算法),最后挑战强化学习与MPC(进阶控制)。






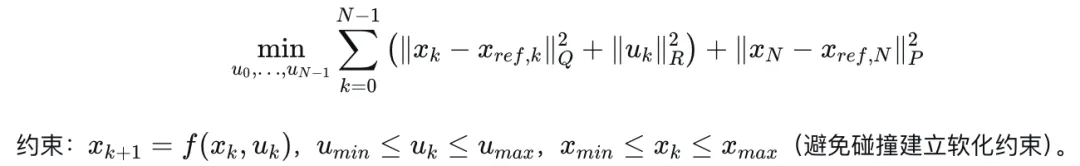
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
