https://github.com/xiaomi-research/onevl
哈喽,大家好,我是 01墨客。
在自动驾驶(Autonomous Driving)领域,开发者一直面临着一个“鱼与熊掌不可兼得”的终极矛盾:解释性与速度。
传统的**显式思维链(Explicit CoT)虽然能让 AI 解释为什么要这么开,但生成推理链的过程太慢,根本跟不上瞬息万变的实时路况;而隐式思维链(Implicit CoT)**虽然快,但却是个“黑盒”,一旦出事,你根本不知道 AI 刚才在想什么。
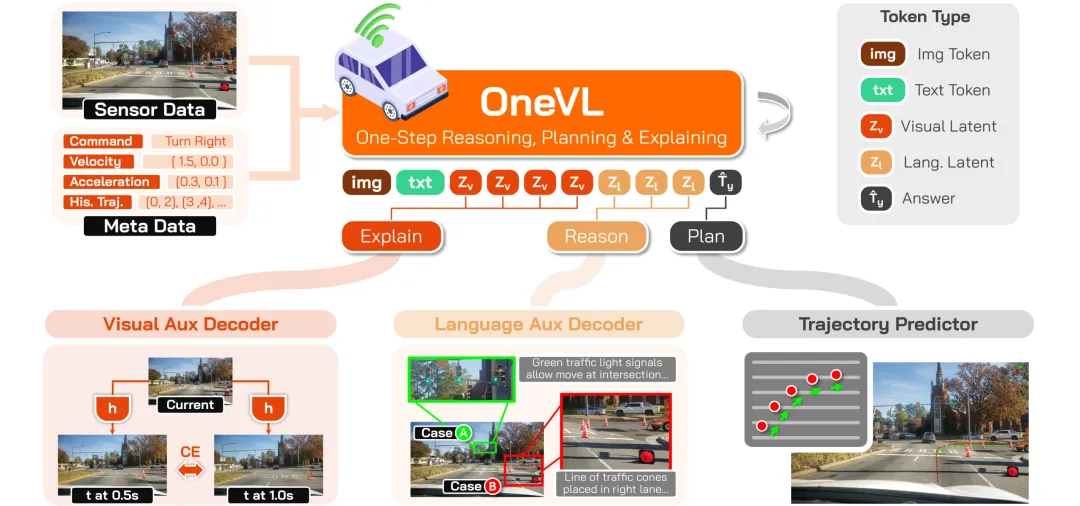
就在最近,小米研究团队正式开源了其全新的 Vision-Language-Action (VLA) 框架 —— OneVL。
它用一种极其优雅的方式,破解了这个难题。
一、 核心突破:既要“快”,又要“懂”
OneVL 最核心的创新在于它引入了双模态辅助解码器(Dual-modal Auxiliary Decoders)。
简单来说,它在训练阶段给 AI 安排了两个“监考老师”:
- • 语言辅助解码器:监督 AI 生成人类可理解的文字推理。
- • 视觉辅助解码器:监督 AI 预测未来的场景画面(世界模型)。
最绝的是,到了推理阶段,这两个解码器会被直接“扔掉”。AI 只需处理压缩后的潜变量(Latent Tokens),推理速度直接拉满,但其决策逻辑却已经深深烙印在了这些潜变量中。
| | |
| 推理速度 | 比显式 CoT 快 1.5~2.3 倍 | |
| 可解释性 | 视觉 + 语言双重解释 | |
| 准确率 | 横扫 NAVSIM、ROADWork 等四大榜单 | |
| 底座模型 | Qwen3-VL-4B-Instruct | |
二、 深度拆解:OneVL 的“三步走”战略
小米 OneVL 之所以能横扫榜单,靠的是三项关键技术创新:
- 1. 潜变量接口(Latent Token Interface):在 Assistant 回复中插入 4 个视觉潜变量和 2 个语言潜变量。
- 2. 预填推理(Prefill Inference):所有潜变量在一次并行 pass 中处理完毕,只有最终的轨迹是自回归生成的。这让它的延迟几乎等同于“不带推理”的纯预测模型。
- 3. 压缩驱动泛化:OneVL 是目前唯一一个在所有四个基准测试中,性能均优于显式自回归 CoT 的潜变量方法。
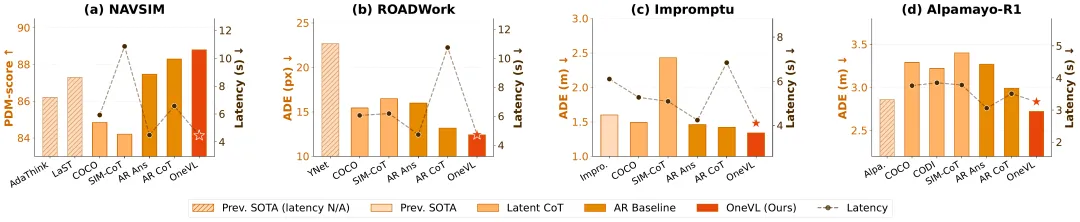
三、 战力实测:性能与效率的“帕累托最优”
在自动驾驶的权威考场上,OneVL 展现了统治级的实力:
- • NAVSIM 榜单:PDM-score 达到 88.84,延迟仅为 4.46s,完美平衡了精准度与实时性。
- • ROADWork(施工区导航):在极其复杂的路况下,其 ADE(平均位移误差)和 FDE(最终位移误差)均大幅领先同类模型。
- • 解释质量:语言辅助解码器恢复了显式 CoT 97% 的解释质量,但速度却提升了数倍。
四、 避坑指南:开发者接入的三点建议
OneVL 已在 GitHub 全量开源(包括权重、推理代码和训练代码),但在实战中建议:
- • 硬件门槛:推理建议配置 16GB 以上显存的 GPU,以确保辅助解码器运行流畅。
- • 分阶段训练:消融实验证明,**分阶段训练(Staged Training)**对 OneVL 至关重要,跳过此步性能会大幅崩塌。
- • 环境版本:务必使用
transformers >= 4.57.0,以获得对 Qwen3-VL 的原生支持。
五、 总结
没有永远的王者,只有在特定赛道上跑得最快的选手。
小米 OneVL 的开源,不仅是提供了一个高效的自动驾驶框架,更重要的是它证明了:AI 的深度推理与实时响应并不冲突。 当自动驾驶能够像人类一样边观察、边思考、边解释,我们离真正的“全无人驾驶”时代,又近了一大步。
你认为自动驾驶最需要“解释”的场景是什么?是复杂的路口博弈,还是突发的紧急避障?欢迎在评论区留言分享!
参考资料
[1] Xiaomi Research. OneVL: One-Step Latent Reasoning and Planning with Vision-Language Explanations. https://github.com/xiaomi-research/onevl[2] OneVL Technical Report. https://arxiv.org/abs/2502.12134 (注:根据GitHub描述推测)
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
