在自动驾驶芯片的竞争中,TOPS 一直是最容易被传播、也最容易被误读的指标。它简单、直接、好比较:一颗芯片有多少 TOPS,似乎就意味着它能支撑多强的智能驾驶能力。但这只是营销层面的方便叙事,不是工程层面的真实性能。
自动驾驶 SoC 不是一个只做矩阵乘法的孤立计算器,而是一个由传感器输入、预处理、感知网络、BEV 表征、时序融合、预测、规划、控制、诊断和安全监控共同构成的实时数据流系统。算力只是其中一个维度。真正决定系统表现的,常常是数据能否在正确的时间、以正确的格式、经过正确的路径送到正确的计算单元。
也就是说,自动驾驶 SoC 的核心矛盾正在从“算不算得动”转向“数据搬不搬得动”。因此不能只看 TOPS,必须看数据流、内存带宽、NoC 拥塞、缓存一致性、QoS 和软件调度。
图 1:自动驾驶 SoC 性能不是 TOPS 单变量问题
这张图的核心意思很简单:TOPS 只是入口指标,不是系统性能本身。
一、为什么 TOPS 会误导自动驾驶芯片性能判断
TOPS 表示每秒万亿次操作,通常用于衡量 AI 加速器的理论推理能力。但它至少有三个天然限制。
第一,TOPS 通常是峰值指标,不等于实际可持续性能。芯片宣传中的 TOPS 往往建立在特定数据类型、特定稀疏性假设、特定算子形态和理想利用率之上。自动驾驶模型里的算子却远比单一 GEMM 复杂,既包括卷积、矩阵乘法,也包括 attention、grid sample、scatter-gather、indexing、reshape、layout transform 等大量非规则操作。
第二,TOPS 不反映内存带宽。一个算子即使理论计算量很大,如果每次计算都需要频繁从 DRAM 读取数据,那么性能上限会被内存带宽卡住,而不是被算力卡住。
第三,TOPS 不反映系统调度与通信效率。自动驾驶 SoC 内部通常包含 CPU、GPU、NPU/BPU/DLA、ISP、PVA、MCU、安全岛、视频编解码模块、DMA 控制器和内存控制器。这些单元之间的数据交换,需要依赖片上互联、缓存层级、共享内存、驱动和编译器协同。任何一个环节设计不好,都会让峰值算力变成纸面数字。
这一点可以用 Roofline Model 解释。Roofline 模型将性能上限描述为峰值计算能力与内存带宽乘以算术强度之间的较小值,即:性能上限取决于 Peak Compute 和 Memory Bandwidth × Arithmetic Intensity 中更小的那一个。Roofline 模型的核心价值,就是判断一个 kernel 到底是 compute-bound 还是 memory-bound。
表 1:TOPS 指标的价值与盲区
| | | |
|---|
| | | |
| | | |
| | | |
| | | 看 bandwidth、latency、bus efficiency |
| | | 看 tail latency、deadline miss |
| | | |
工程结论是:只拿 TOPS 讲自动驾驶芯片性能,本质上是把复杂系统问题降维成了宣传口径。
二、Roofline:理解“算得动”与“搬得动”的分界线
自动驾驶 SoC 的真实性能,可以用一个简化公式理解:
实际性能 ≈ min(峰值计算能力, 有效内存带宽 × 算术强度)
其中:
| | |
|---|
| | |
| | LPDDR/GDDR/HBM、内存控制器、NoC、DMA |
| | |
| | |
传统 Roofline 模型通常用于 HPC,用 FLOP/s、Byte/s 和 FLOP/Byte 表达。放到自动驾驶推理芯片里,可以泛化为 OP/s、Byte/s 和 OP/Byte。但这里必须非常小心:不同芯片宣传的 TOPS 可能对应 INT8、稀疏 INT8、FP16 或其他口径,不能把不同数据类型的数值直接混在一起比较。
图 2:Roofline 在自动驾驶 SoC 中的简化解释
Roofline 的意义不是给文章装一个公式,而是逼你面对一个事实:如果算术强度不够高,堆再多 TOPS 也没用。
三、自动驾驶 pipeline 的混合算术强度特征
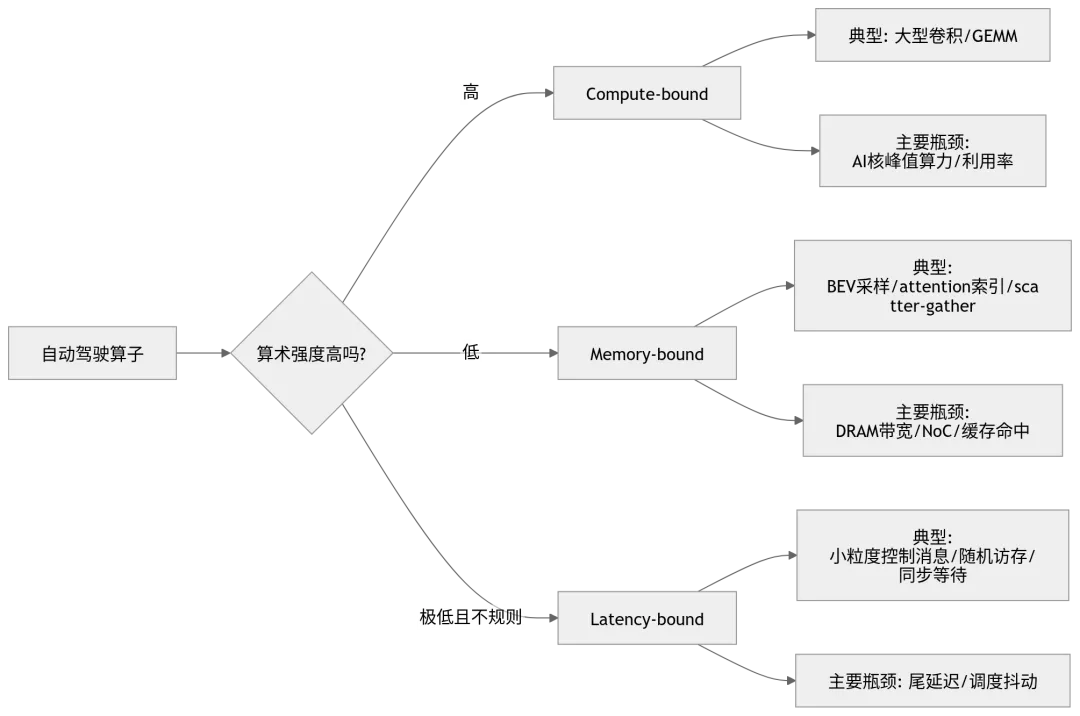
自动驾驶算法栈不是单一负载,而是多类负载混在一起。不同模块的计算密度、访存模式、实时性要求完全不同。
CNN backbone、部分 BEV encoder、Transformer 中的大型矩阵乘法,通常具有较高数据复用率,更容易接近 compute-bound。它们对 AI 加速器的矩阵计算能力要求较高,也更容易从高 TOPS 中获益。
但自动驾驶系统中还有大量 memory-bound 或 latency-bound 操作,例如 BEV 空间变换、grid sample、multi-view attention、scatter-gather、点云体素化、Occupancy 更新、多传感器融合等。这些模块不一定拥有最高理论计算量,却可能消耗大量数据搬移时间。
表 2:自动驾驶典型模块的瓶颈类型
| | | | |
|---|
| | | | |
| grid sample / view transform | | | |
| self-attention / cross-attention | | | |
| voxel update / scatter-gather | | | latency-bound / memory-bound |
| feature concat / temporal fusion | | | |
| graph / trajectory scoring | | | |
| | | | |
这里最容易被外行低估的是 BEV、occupancy、multi-view fusion 和 attention 里的非规则访存。它们看起来不像大矩阵乘法那样“重”,但往往会让系统卡在 feature map 读取、跨视角采样、索引、layout 转换和同步等待上。
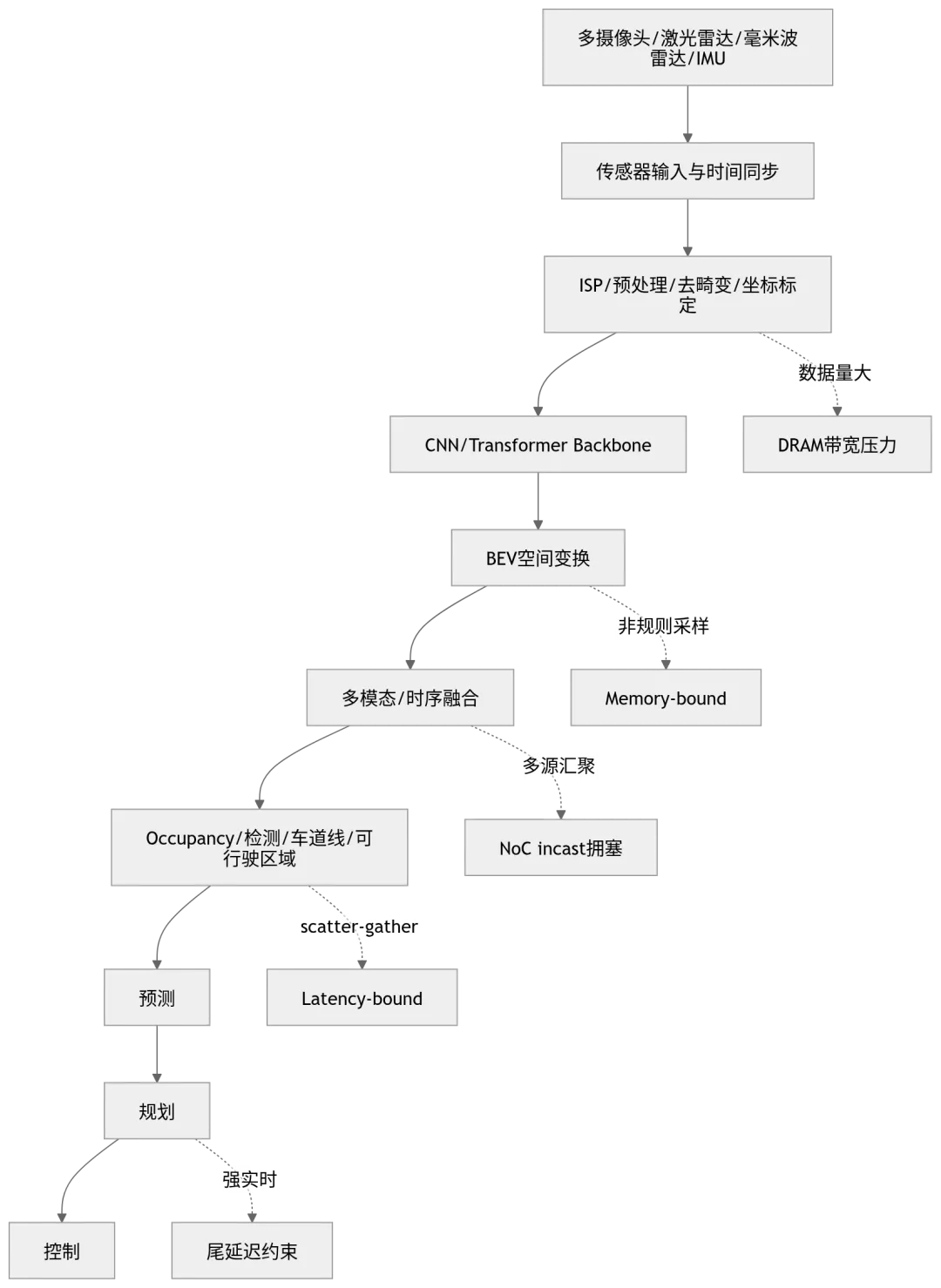
图 3:自动驾驶 pipeline 中的数据流与瓶颈位置
如果只看 TOPS,你会误以为瓶颈在 CNN/Transformer Backbone;但真实系统里,瓶颈经常出现在 BEV 空间变换、多模态/时序融合、Occupancy/检测/车道线/可行驶区域 这些“数据组织和数据搬移”环节。 非规则采样[Memory-bound]、多源汇聚[NoC incast拥塞]、scatter-gather[Latency-bound]。
四、片上互联:自动驾驶 SoC 被低估的内部交通系统
如果把自动驾驶 SoC 比作一座城市,CPU、GPU、BPU/DLA 是不同类型的工厂,SRAM 和缓存是近端仓储,DRAM 是大型物流中心,那么片上互联就是城市道路系统。
工厂产能再强,如果道路堵死、仓库装卸慢、调度混乱,整个城市照样瘫痪。
过去较简单的 SoC 可以使用共享总线。共享总线结构简单、面积小、设计成本低,但它本质上是时分复用通道:同一时刻只有有限主设备可以占用总线。随着 CPU、GPU、AI 加速器、ISP、视频编解码器、安全模块和 DMA 数量增加,共享总线会迅速暴露出可扩展性不足的问题。
随着主设备数量、并发请求和突发流量增加,共享总线的排队延迟和仲裁复杂度会显著恶化,可能呈现线性或超线性增长,具体取决于仲裁策略、请求模式和负载强度。
NoC,即 Network-on-Chip,正是为解决这个问题而出现。NoC 用分布式路由器、点对点链路和多通道流控机制取代单一共享总线,使多个数据流可以并行传输。它不是简单“更宽的总线”,而是芯片内部的网络系统。
表 3:共享总线、多层总线与 NoC 的工程对比
但也不能把 NoC 简化成“Mesh 一定优于 Ring”或“拓扑决定一切”。在真实 SoC 中,NoC 性能取决于拓扑结构、路由策略、链路位宽、频率、buffer 深度、虚拟通道设计、QoS 仲裁、DRAM 控制器分布、cache/snoop 一致性流量、DMA burst 策略和软件调度节奏。
因此,评价自动驾驶 SoC 的片上互联,不能只问“是不是 Mesh”,而要问:在多摄像头输入、BEV 刷新、AI 推理、日志写入、控制信号并发时,它能不能控制拥塞,尤其能不能控制尾延迟。
五、NoC 真正的问题不是平均带宽,而是拥塞与尾延迟
自动驾驶系统是强实时系统。平均性能不够说明问题。真正危险的是 P99、P99.9 甚至最坏情况延迟。
NoC 拥塞不一定只来自总带宽不足,更常见的是局部热点、同步突发和关键资源争用导致的尾延迟恶化。自动驾驶 SoC 中有三类典型拥塞模式。
图 4:三类典型 NoC 拥塞模式
表 4:NoC 拥塞模式、表现与治理方式
| | | | |
|---|
| | | | |
| | | | |
| | | | 加 jitter、调度错峰、pipeline 重排 |
| | | | |
| | | | |
所以,NoC 优化的核心目标不是单纯降低平均延迟,而是控制关键路径的尾延迟上界。对自动驾驶而言,系统“多数时候很快”没有意义;真正重要的是“最坏情况下也不能慢到失控”。
六、QoS 很重要,但 QoS 不是万能解
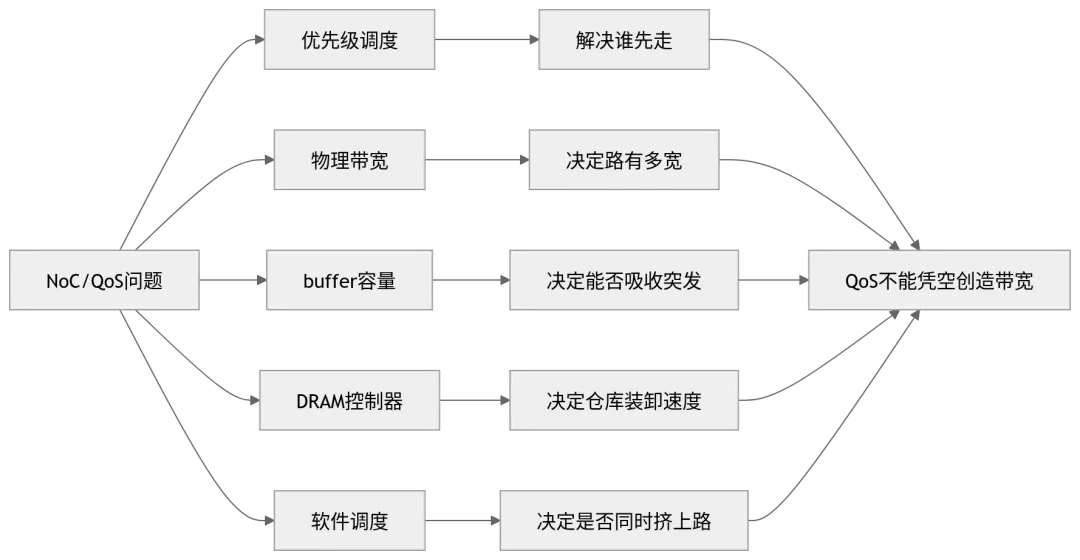
现代 SoC 通常会引入 QoS 机制,为不同类型流量分配不同优先级。例如安全相关数据、传感器同步信号、控制路径消息和故障诊断信息,应当比日志、调试信息、后台地图更新、非关键 DMA 传输拥有更高优先级。
但 QoS 只能回答“谁先走”,不能解决“路够不够宽”。当底层链路、buffer 或 DRAM 控制器已经被大量数据占用时,高优先级流量仍然可能等待,只是等待时间相对较短。
图 5:QoS 的边界
完整的设计应包括:
| | |
|---|
| | |
| credit-based flow control | |
| | |
| | |
| | |
| | |
| | |
真正可靠的实时性,不能只靠优先级,而要靠资源隔离、流量整形和最坏情况分析共同保证。
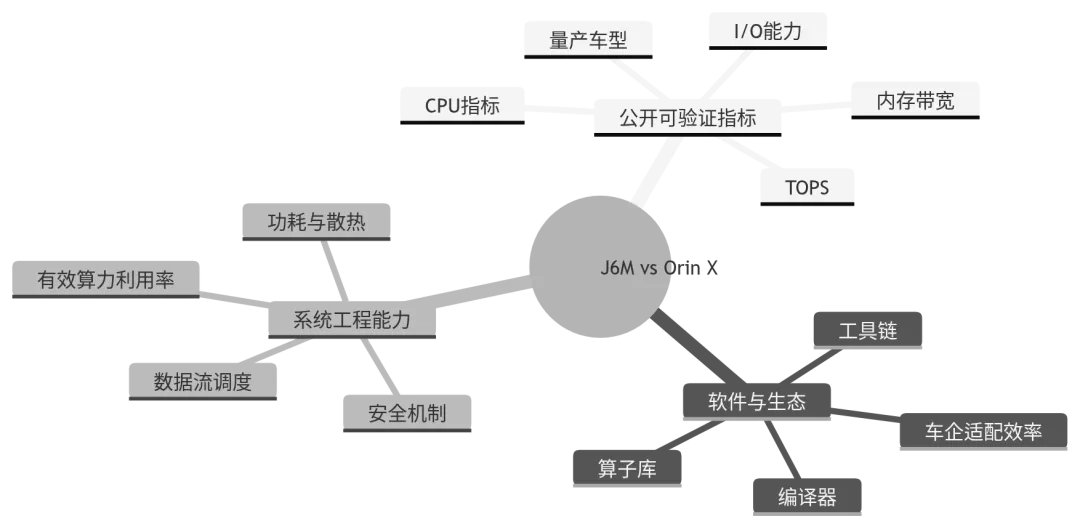
七、J6M 与 Orin X:系统取向对比
两家公司并未充分公开对应产品的片上 NoC 拓扑细节。
地平线公开资料显示,征程 6M 具备 128 TOPS 算力、137K CPU DMIPS,并集成 BPU、CPU、GPU、MCU 等计算资源,面向其目标智驾场景降低系统集成难度;征程 6 系列还公开强调全系搭载 BPU 纳什架构,支持大参数 Transformer、端到端与交互式博弈等先进智驾算法部署。
NVIDIA DRIVE AGX Orin 的公开规格显示,单颗 Orin SoC 包含 12 核 Cortex-A78A CPU,最高 254 INT8 TOPS,具备 256-bit LPDDR5,官方标称最高约 200GB/s 内存带宽,并集成 GPU、DLA、PVA、ISP、视频编解码和车载 I/O 能力。
J6M 的公开叙事更强调面向中国量产智驾场景的高集成度、成本效率、算法协同和单芯片部署能力;Orin 的公开叙事更强调异构计算资源完整性、CUDA/TensorRT/DRIVE 生态、可编程性和平台扩展能力。
表 5:J6M 与 Orin X 的公开指标
| | NVIDIA DRIVE AGX Orin / Orin X |
|---|
| | |
| | |
| | 256-bit LPDDR5,最高约 200GB/s |
| | |
| | |
| | |
| | |
| | |
| | |
图 6:J6M 与 Orin X 对比的正确打开方式
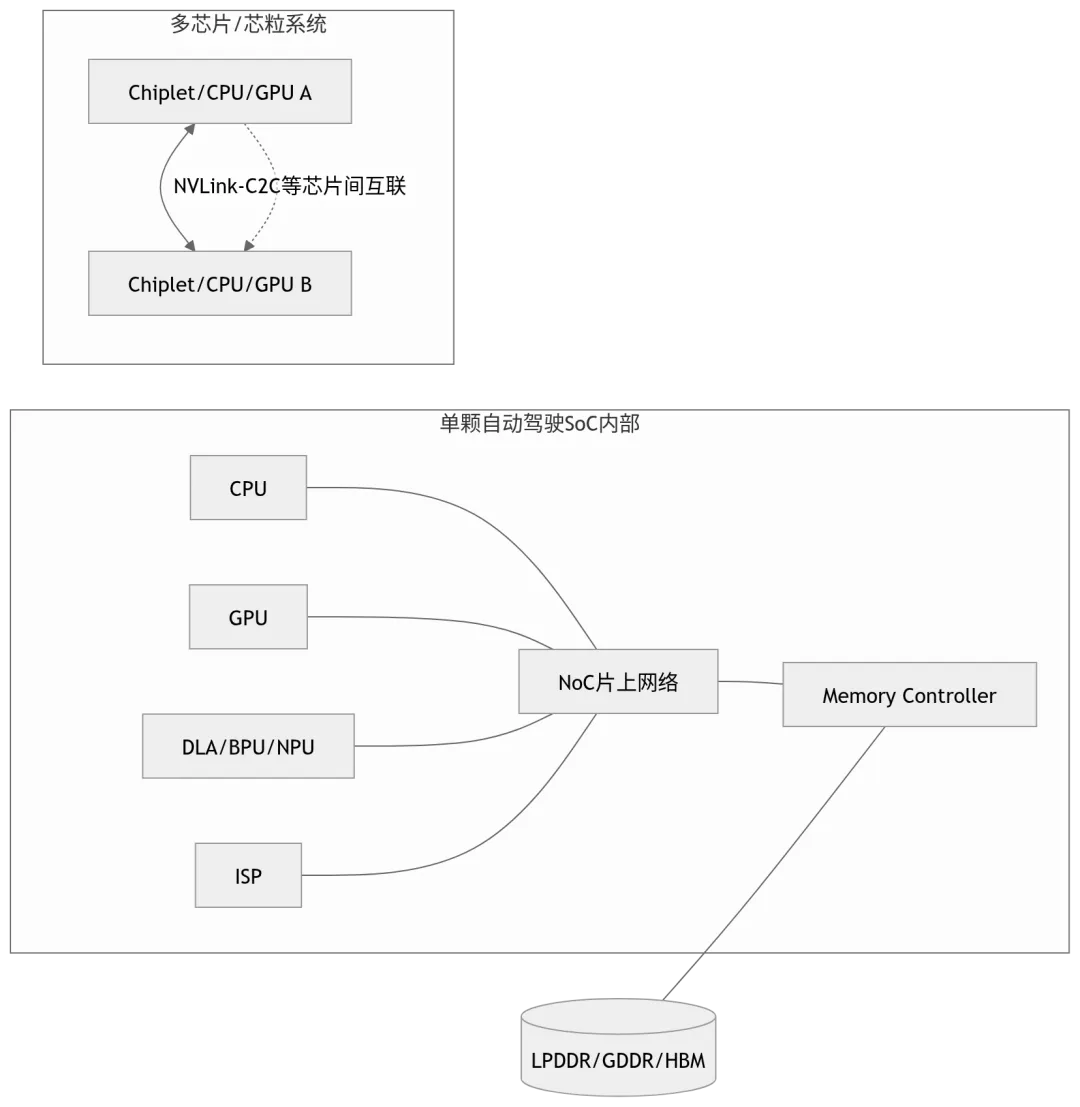
八、关于 NVLink-C2C:必须从 Orin 中拆出来
表 6:NoC、PCIe、NVLink-C2C 的概念边界
| | | |
|---|
| | CPU/GPU/DLA/ISP/内存控制器之间通信 | |
| | | |
| | | |
| | | |
图 7:NoC 与 NVLink-C2C 的边界关系
NoC 是芯片内部交通网;NVLink-C2C 是芯片间或芯粒间高速互联。
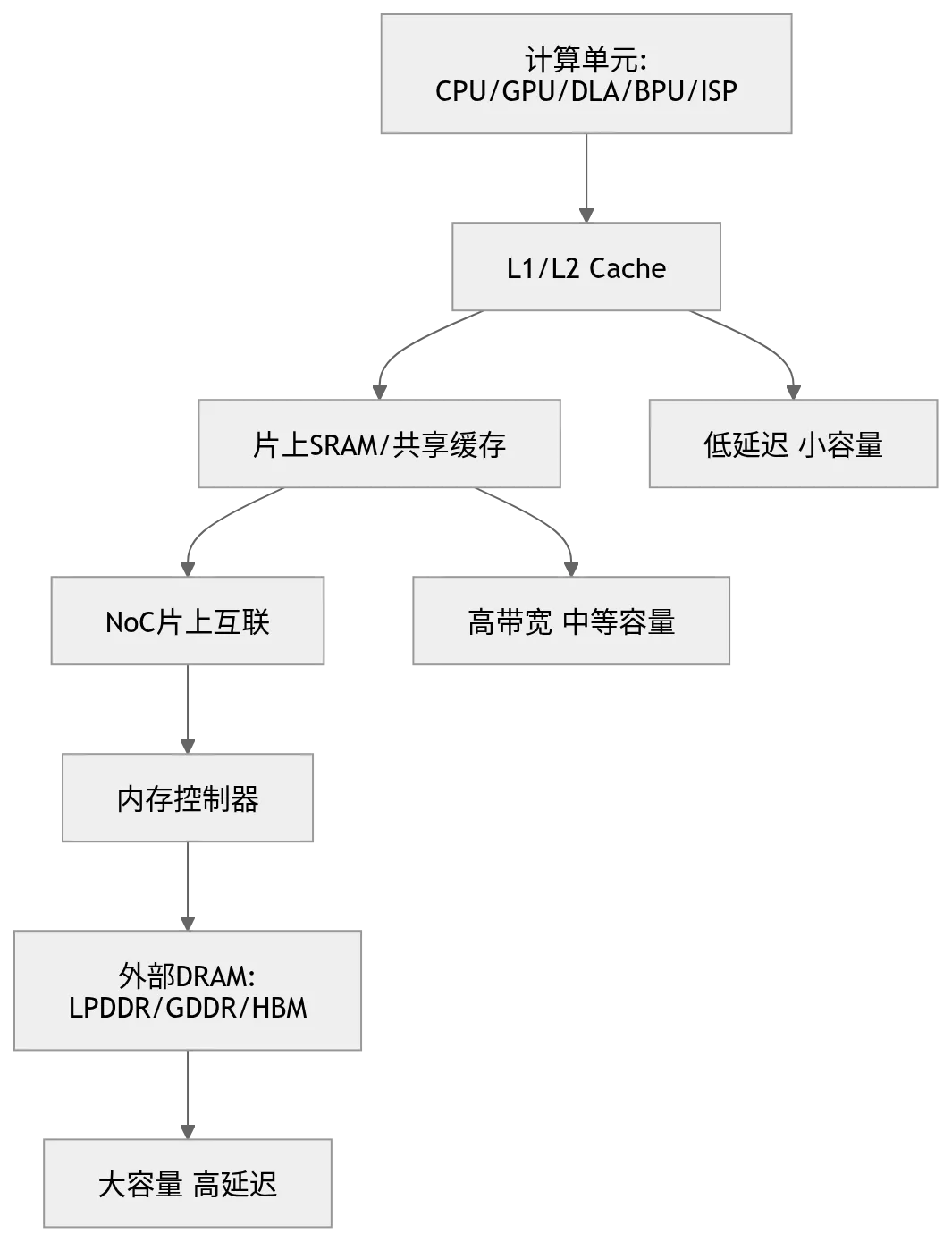
九、内存带宽:自动驾驶 SoC 的生命线
自动驾驶系统中,大量数据交换并不是在计算单元之间直接点对点完成,而是通过共享 DRAM、缓存层级和 DMA 进行。
共享内存架构的优势是明显的:相比独立 CPU 内存和独立 GPU 显存之间通过 PCIe 拷贝,SoC 内部的统一地址空间或共享物理内存可以减少显式数据搬运。但这不等于“共享内存天然高效”。
真实性能仍受以下因素制约:
以 Orin 为例,官方公开规格为 256-bit LPDDR5,最高约 200GB/s 内存带宽。这个数字已经不低,但面对多摄像头输入、BEV 特征构建、多模型并发和后台任务时,仍然需要精细调度。
对 J6M 而言,公开资料确认了 128 TOPS 和 137K CPU DMIPS,但没有充分披露内存位宽与内存带宽。
图 8:自动驾驶 SoC 的存储层级
表 7:存储层级的作用与瓶颈
实际评估中容易被忽略的是:DRAM 带宽不是写在规格表上就能全用上。有效带宽取决于访问是否连续、burst 是否足够、bank 是否冲突、控制器是否拥塞、NoC 是否堵塞、cache 是否命中、DMA 是否合理、layout 是否匹配。
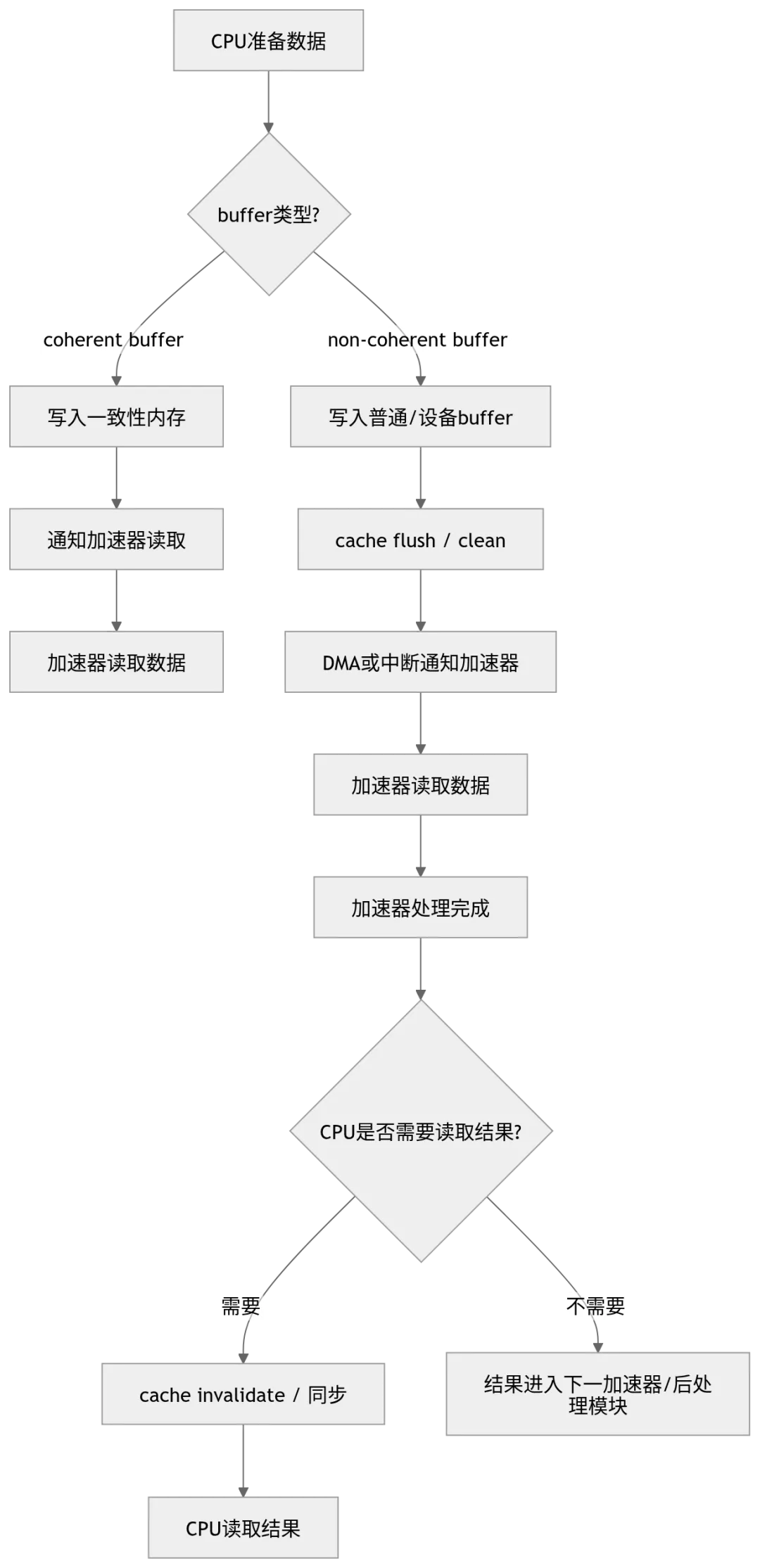
十、缓存一致性:共享内存背后的隐性成本
共享内存通信看起来简单:CPU 写入一块内存,GPU、BPU 或 DLA 去读取即可。但实际工程中,这里有一个复杂问题:缓存一致性。
CPU、GPU 和 AI 加速器可能拥有不同层级的缓存或本地 SRAM。当一个设备修改了某块内存,另一个设备如果仍然看到旧缓存,就会产生数据一致性问题。
传统教材常用 MESI 协议解释缓存一致性,但现代车载 SoC 并不是简单“所有缓存行修改都广播到所有核心”。实际系统往往使用 directory、snoop filter、I/O coherency、AMBA CHI、软件 cache maintenance、non-cacheable mapping 等机制来降低一致性开销。
NVIDIA 对 NVLink-C2C 的公开资料提到其支持面向高带宽一致性连接的 chip-to-chip interconnect,并用于 Grace 等产品;但这类资料不能直接反推 Orin X 内部 NoC 的具体一致性实现。
图 9:CPU 与加速器共享内存的数据同步流程
表 8:coherent 与 non-coherent 路径对比
工程上真正要做的不是迷信“共享内存”,而是减少无意义的数据复制、减少 CPU cache 参与、减少 layout 转换,并保证每一步同步语义明确。
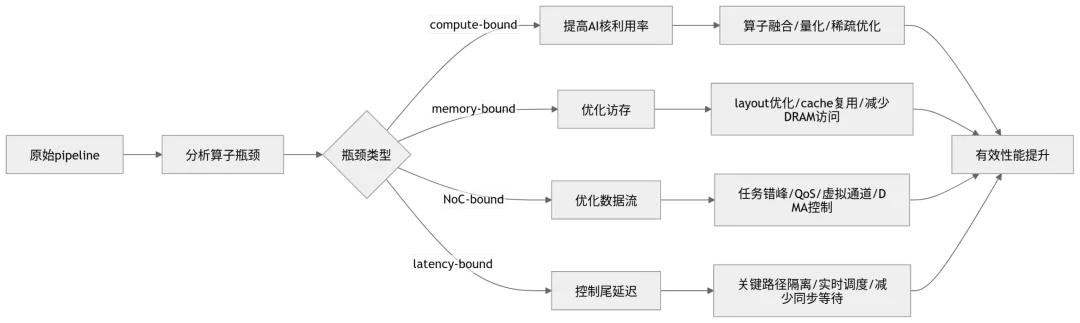
十一、工程优化:比堆 TOPS 更重要的五件事
1. 数据布局必须服从硬件和算子库
不能简单说 NHWC 一定比 NCHW 好,也不能反过来说 NCHW 一定更优。不同硬件、编译器、TensorRT/BPU 编译器、DLA 后端和算子库,对 layout 的偏好不同。
真正的优化目标是:
- 避免为了单个算子局部最优,破坏整条 pipeline 的全局效率。
2. 不要盲目 batch,要控制实时延迟
批量处理可以提高吞吐,但自动驾驶不是离线推理。在线感知链路中,batch 过大可能增加等待时间,导致端到端延迟恶化。
更合理的做法不是简单增大 batch,而是:
3. 双缓冲能隐藏延迟,但不是魔法
双缓冲可以让数据搬移和计算重叠。当计算时间大于或接近传输时间时,它能显著改善吞吐。但它不能消除首帧延迟,也不能在传输时间超过计算时间时完全隐藏数据搬移。
双缓冲提升的是稳态 pipeline 的吞吐效率,而不是无条件降低所有场景下的端到端延迟。
4. DMA burst 长度要控制
过大的 DMA burst 会长时间占用链路资源,使高优先级小消息等待;过小的 burst 又会增加协议开销,降低有效带宽。
合理的策略是根据流量类型分级:
5. 打散同步突发流量
多摄像头、多模型、多 DMA 任务如果完全同步启动,很容易形成 incast。工程上可以通过调度错峰、时间抖动、分片传输、多副本缓存和任务分组,降低瞬时拥塞。
图 10:自动驾驶 SoC 数据流优化路径
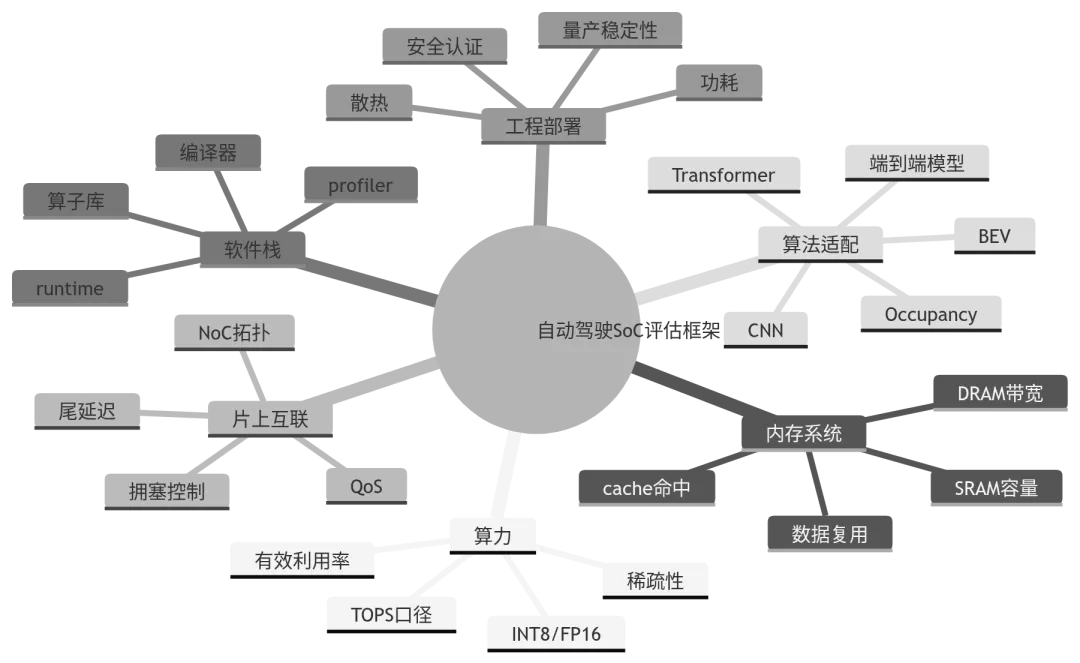
十二、自动驾驶 SoC 评估矩阵:比 TOPS 更实用的检查框架
如果要真正评估一颗自动驾驶 SoC,不应该只问“多少 TOPS”,而应建立多维矩阵。
表 9:自动驾驶 SoC 真实评估矩阵
| | |
|---|
| | |
| BEV、attention、grid sample 是否高效 | |
| | |
| | |
| | |
| burst、scatter-gather、同步机制 | |
| | |
| | |
| | |
| | |
| | |
| | |
图 11:自动驾驶 SoC 评估脑图
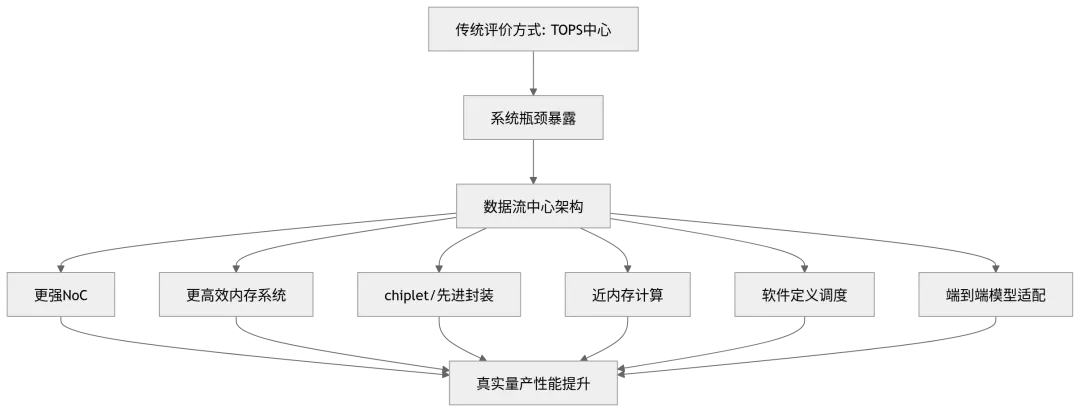
十三、未来趋势:从以计算为中心到以数据流为中心
自动驾驶 SoC 的发展方向,不会只是继续堆 TOPS。下一阶段真正重要的是数据流效率。
1. 更强的片上互联与 QoS
未来 SoC 会继续强化 NoC、系统级缓存、内存控制器调度和 QoS 管理。目标不是让所有流量都最快,而是让关键流量有界、可预测、可验证。
2. Chiplet 与高速芯片间互联
随着单芯片面积、良率和成本压力上升,chiplet 和先进封装会越来越重要。NVLink-C2C 这类技术的意义在于提供高带宽、低延迟、支持一致性的芯片间连接。NVIDIA 官方资料明确将 NVLink-C2C 用于 Grace CPU Superchip 等产品,其中两颗 Grace CPU 通过 NVLink-C2C 以 900GB/s 连接。
但必须再次强调:这不等于 Orin X 使用 NVLink-C2C。
3. 近内存计算
近内存计算会在数据搬移成本高、算术强度低的任务中体现价值。例如传感器预处理、稀疏特征处理、部分压缩/解压、简单滤波和数据重排。它的核心逻辑不是让内存替代 AI 加速器,而是减少低价值数据在芯片内部来回搬运。
4. 软件定义的数据流调度
未来的自动驾驶系统不只是硬件问题。编译器、runtime、驱动和中间件会越来越关键。谁能更好地分析模型图、预测访存压力、融合算子、安排 DMA、控制 NoC 流量,谁就能把同样的硬件跑出更高有效性能。
图 12:下一代自动驾驶 SoC 的演进方向
结论:自动驾驶 SoC 的竞争,正在从峰值算力转向系统效率
自动驾驶 SoC 的性能不能只看 TOPS。TOPS 只是理想计算上限,真实量产表现取决于数据流是否顺畅。
真正决定系统能力的,是计算、内存、片上互联、缓存一致性、DMA、QoS、编译器、驱动和算法结构之间的协同。CNN、Transformer、BEV、Occupancy、Fusion 和规划控制模块具有完全不同的数据访问模式,因此同一颗芯片在不同算法栈下可能表现差异巨大。
J6M 和 Orin X 的对比,也不应被粗暴写成 Mesh 与 Ring 的拓扑对决。公开资料能确认的是:J6M 具备 128 TOPS、137K CPU DMIPS,强调高集成度、单芯片部署、普惠城区 NOA 和算法协同;Orin 公开披露了更完整的异构计算资源、最高 254 INT8 TOPS、12 核 Cortex-A78A CPU、256-bit LPDDR5 和最高约 200GB/s 内存带宽。至于两者内部 NoC 拓扑、缓存一致性域、具体互联平面和流控细节,公开资料不足。
更高级的判断框架应该是:
不问一颗芯片有多少 TOPS,而问它在真实自动驾驶 pipeline 中,有多少 TOPS 能被持续、稳定、低延迟地转化为有效输出。
这才是自动驾驶 SoC 从参数竞赛走向工程成熟的关键。



 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
