自动驾驶VLA新范式!北大联合NVIDIA提出Fast-dDrive!让扩散模型比自回归快11.8倍!
- 2026-05-31 04:17:17
🔗 点击加入➡️【AIGC/LLM/MLLM/3D/自动驾驶】 技术交流群
知识星球

数源AI 最新论文解读系列
论文信息:Fast-dDrive: Efficient Block-Diffusion VLM for Autonomous Driving | arXiv:2605.23163 | Peking University & NVIDIA & The University of Hong Kong & MIT |
引言
端到端自动驾驶通过视觉-语言-动作(VLA)模型将感知、推理和规划统一在单一可训练系统中取得了快速进展。然而,现有范式通常难以兼顾高精度轨迹规划与高效推理:自回归(AR)VLA在边缘硬件上受内存带宽限制,且容易产生曝光偏差漂移;而全序列扩散模型无法复用KV缓存,并存在违反"先感知后规划"因果关系的"逻辑泄漏"问题。本文提出Fast-dDrive,一种块扩散VLA,它在语义单元内执行双向细化,同时在单元间强制执行严格的因果顺序,从而同时解决上述瓶颈。
简介
本文提出Fast-dDrive,一种块扩散VLA,它在语义单元内执行双向细化,同时在单元间强制执行严格的因果顺序。利用驾驶VLA常输出结构化类JSON数据的观察,Fast-dDrive将结构token冻结为章节支架,并采用优先关注安全关键规划的章节感知训练策略。我们进一步引入支架投机解码(Scaffold Speculative Decoding),以显著更高的吞吐量实现与AR相当的质量。最后,我们提出一种低开销的测试时缩放方案:通过从单一共享前缀KV缓存分叉出个随机轨迹展开并取平均,以极低的计算成本有效抑制预测方差。
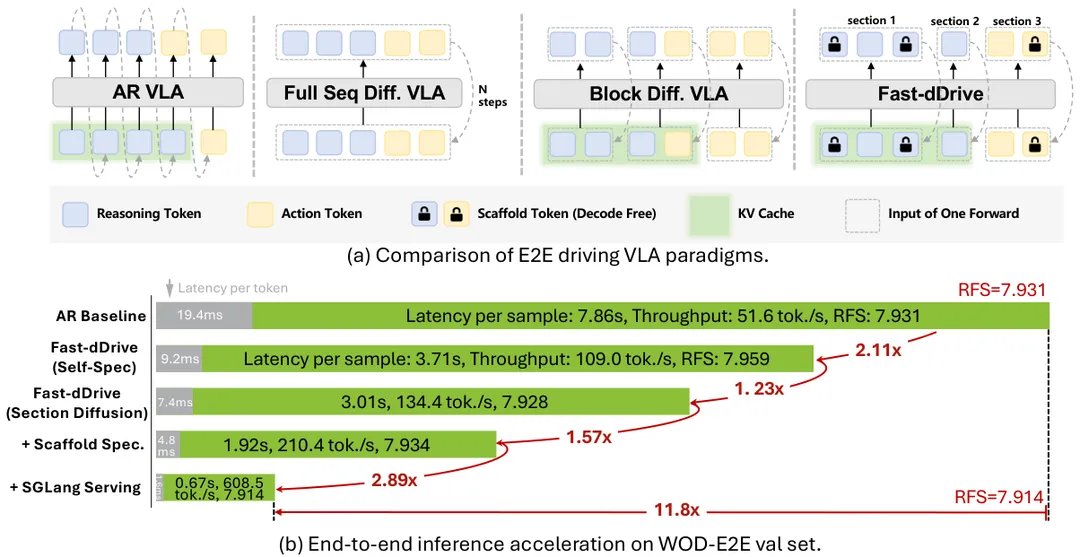 图1:端到端驾驶VLA范式对比。(a) AR VLA受内存带宽限制且单步仅生成一个词元,全序列扩散VLA无法复用KV缓存并存在逻辑泄漏;Fast-dDrive通过章节对齐的块扩散与冻结支架预填充同时解决两大瓶颈。(b) 在单张NVIDIA H100 GPU上,本文方法相比AR基线实现最高11.8倍的端到端加速。
图1:端到端驾驶VLA范式对比。(a) AR VLA受内存带宽限制且单步仅生成一个词元,全序列扩散VLA无法复用KV缓存并存在逻辑泄漏;Fast-dDrive通过章节对齐的块扩散与冻结支架预填充同时解决两大瓶颈。(b) 在单张NVIDIA H100 GPU上,本文方法相比AR基线实现最高11.8倍的端到端加速。
实证结果表明,Fast-dDrive重新定义了驾驶智能体的速度-精度前沿。在WOD-E2E测试集上,Fast-dDrive取得了SOTA的ADE@3s和ADE@5s,同时在基于扩散的VLA中达到最高RFS;在nuScenes上,它将平均L2误差降至米(提升)。与SGLang集成后,我们的框架相比AR基线实现的吞吐量加速,缩小了高容量VLA与实时车载部署效率需求之间的差距。
方法
我们提出Fast-dDrive,一种用于端到端自动驾驶的块扩散VLA。我们首先回顾块扩散形式(§3.1),然后描述我们的结构感知支架扩散训练(§3.2)、其允许的两种推理模式(章节扩散与支架投机解码,§3.3),以及一种低开销的测试时推理缩放方案(§3.4)。
3.1 预备:块因果掩码扩散
掩码扩散语言模型定义了一个前向过程,根据噪声调度随机将token替换为特殊[MASK] token,生成损坏序列。反向过程应用去噪策略,预测被掩码位置的替换。训练最小化掩码交叉熵损失:
其中为步骤的被掩码索引集。
全序列双向扩散无法复用KV缓存,且在每个去噪步骤需要完整重计算。块扩散通过将输出划分为大小为的个块来解决此问题:,其中块以双向注意力在块内、因果注意力跨块的方式从左到右生成。块关注完整提示和所有前序块(其KV缓存可复用),但不关注未来块。这恢复了KV缓存兼容性,同时保留块内的并行生成。
3.2 结构感知支架扩散
遵循先前工作,模型输出包含四个语义章节的结构化JSON:critical_objects(12个二元检测)、explanation(自由形式推理)、future_meta_behavior(分类动作)和trajectory(5秒内的5个路径点坐标)。我们利用固定的JSON模式,预填充所有结构token(键、括号、标点)作为冻结支架,仅保留值token被掩码。令表示支架(锚点)位置,为可编辑值位置;扩散过程仅在上操作:
| 这保证100%的结构正确性,并将去噪工作量减少约30%。我们进一步将块边界与章节边界对齐,将每个章节划分为个块。章节按CO → Expl → FMB → Traj的因果顺序去噪,每个块提供完整的章节内双向上下文。 |
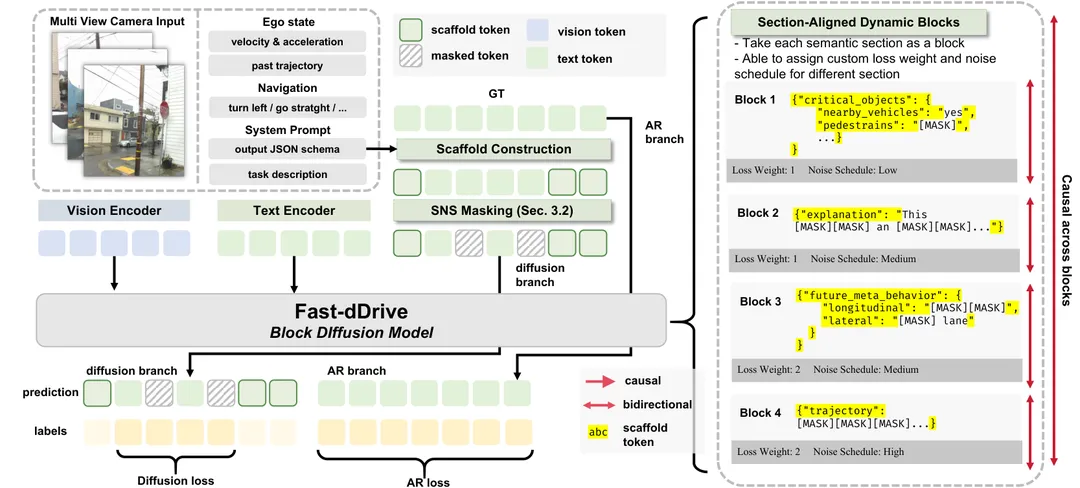 图2:Fast-dDrive训练流程。结构化JSON输出被分解为四个语义章节,模板词元构成冻结支架(灰色,预填充且从不掩码),值词元在章节对齐的块内通过双向注意力去噪,章节间保持严格因果顺序;SASD在训练时引入章节加权损失与Beta噪声调度。
图2:Fast-dDrive训练流程。结构化JSON输出被分解为四个语义章节,模板词元构成冻结支架(灰色,预填充且从不掩码),值词元在章节对齐的块内通过双向注意力去噪,章节间保持严格因果顺序;SASD在训练时引入章节加权损失与Beta噪声调度。
四个章节在安全影响上差异巨大:错误的路径点坐标可能导致碰撞,而略有瑕疵的解释则无此后果。我们引入两种互补的训练时机制,将学习容量偏向安全关键章节。章节加权损失为每个章节分配正标量权重,缩放其每token交叉熵:
其中为安全关键章节分配更大权重。章节自适应噪声用每章节Beta分布替代均匀扩散调度,允许噪声调度针对每个章节的难度特征定制。两种机制均零推理开销。
遵循Fast-dVLM,我们在双流目标下训练,结合我们的章节加权MDM损失(式3)与干净流上相同响应标签的token级因果LM损失:
3.3 推理:章节扩散与支架投机解码
由于式(4)中的联合AR+扩散目标在相同权重上保持两个解码头,Fast-dDrive支持两种互补推理模式。
章节扩散(SD):SD在推理时重用训练时过程:从预填充的支架开始,MDM头在章节对齐动态块上逐节迭代去掩码值位置,通过缓存的因果上下文关注前序块。支架和早前景章节的KV缓存被复用无需重计算,产生不调用AR头的纯扩散基线。
支架投机解码(SS):第二种模式调用自投机解码,其中MDM头并行起草块,AR头顺序验证。普通自投机在固定大小块上操作,无支架或章节结构感知;我们将其扩展为支架投机解码(SS),利用支架进一步减少计算开销。
算法流程如下:给定预填充的支架,支架投机按章节顺序序列处理每个块:
自动接受支架:块内的所有支架位置直接接受,无需起草或验证。仅值位置进入起草-验证循环。 | 2. 起草(MDM头):单次前向传递以块双向注意力同时填充所有$ | \mathcalE}_j i}{i \in \mathcal{E}_j}$。 | 验证(AR头):整个块的因果前向传递计算AR logits。对于每个值位置按从左到右顺序,若,则接受该token;否则AR token替换草稿,且所有后续草稿token被丢弃。在拒绝点始终接受一个奖励token。
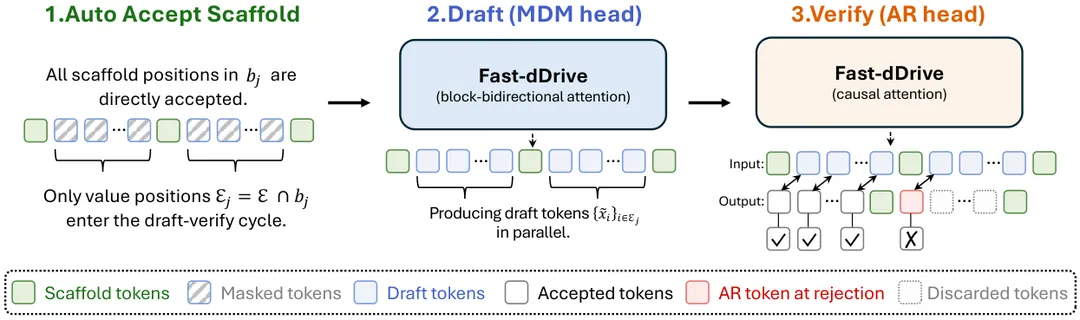 图3:支架投机解码机制。对于每个块,支架词元被自动接受;MDM头通过双向注意力并行起草值词元;AR头以因果注意力验证草稿,接受词元直至首个不匹配处外加一个奖励词元。
图3:支架投机解码机制。对于每个块,支架词元被自动接受;MDM头通过双向注意力并行起草值词元;AR头以因果注意力验证草稿,接受词元直至首个不匹配处外加一个奖励词元。
每个块恰好需要2次前向传递(起草+验证),与块大小无关。相比普通自投机解码的关键加速来自两个来源:(1)支架token以零前向传递自动接受;(2)章节对齐块确保MDM草稿具有完整语义上下文,相比任意固定大小块提高草稿接受率。
3.4 通过共享前缀多轨迹展开的测试时推理缩放
支架投机确定性解码结构化输出:单次SS传递已返回模型最自信的轨迹。为将额外推理计算转化为额外精度,我们在AR验证器内引入随机性并平均个轨迹展开。
仅轨迹随机性:前三个章节(critical_objects、explanation、future_meta_behavior)受模式严格约束且具有尖锐的后验;对它们采样不产生有用的多样性,仅会降低后续章节质量。因此我们在前三个章节保持AR验证器贪婪,仅在解码进入轨迹章节时启用softmax采样。
共享前缀:由于前三个章节是确定性的,其KV缓存在各展开间相同。我们将其解码一次,分叉KV缓存次,并在轨迹章节继续支架投机次,每次独立随机抽取。由于轨迹章节相对于完整输出较短,这仅为每次额外展开增加极低成本,而非完整SS传递。
轨迹平均:令为个展开轨迹,每个通过Jerk-Minimizing Trajectory(JMT)拟合插值到20个路径点。输出为等权平均。根据均值方差论证,平均个展开将残差方差降低倍,同时保持任何确定性偏差不变。
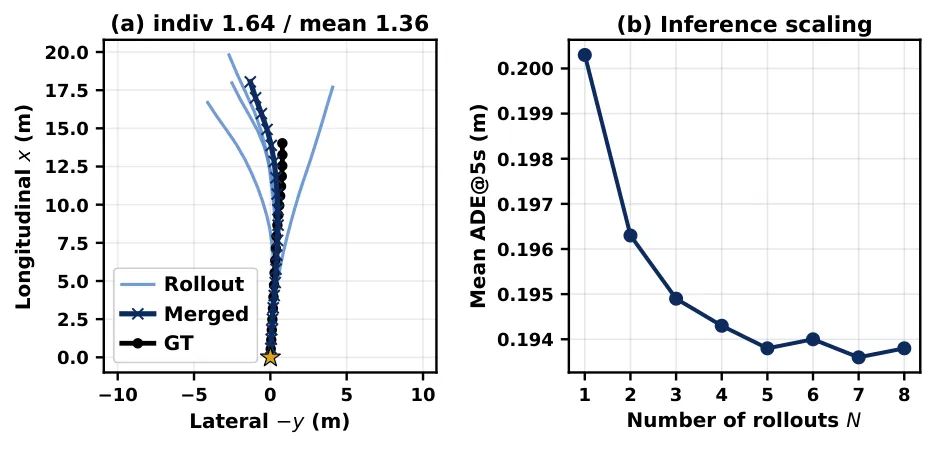 图4:共享前缀多轨迹展开策略。(a) 在WOD-E2E验证集样本中,4次随机展开(浅蓝)在远端路点处分歧显著,其均值(深蓝)更接近真值(黑色)。(b) 平均ADE@5s随展开次数N单调下降,验证了均值方差论证。
图4:共享前缀多轨迹展开策略。(a) 在WOD-E2E验证集样本中,4次随机展开(浅蓝)在远端路点处分歧显著,其均值(深蓝)更接近真值(黑色)。(b) 平均ADE@5s随展开次数N单调下降,验证了均值方差论证。
实验与结果
4.1 实验设置
我们在开环设置下评估两个基准。nuScenes包含1,000个城市驾驶场景,按700/150/150划分训练/验证/测试,以2 Hz采样标注关键帧。Waymo Open Dataset End-to-End(WOD-E2E)包含4,021个20秒的长尾驾驶片段,按2,037/479/1,505划分;对于测试评估,仅提供每个片段的前12秒。我们采用dVLM-AD的四章节结构化输出的思维链标注。
模型接收RGB相机帧、自车状态和高级导航指令;不使用激光雷达、毫米波雷达或高精地图。在nuScenes上使用覆盖过去1秒的3帧前视相机帧,在WOD-E2E上使用当前帧的3个前视相机;每幅图像被缩放至长边最多512像素,然后由Qwen2.5-VL的视觉编码器进行分块。
评估指标包括规划精度(nuScenes上的L2误差,WOD-E2E上的ADE和RFS)和推理效率(延迟、TPS、Tok/Step)。Fast-dDrive基于Qwen2.5-VL-3B构建,转换为Fast-dVLM块扩散架构。SASD使用章节损失权重和Beta噪声参数分别对应trajectory、future_meta_behavior、critical_objects和explanation。
4.2 主要结果
表2:WOD-E2E测试集对比。*:零样本(无需微调)。†:在与我方模型相同条件下使用原始主干网络由我们测量。TPS和Tok/Step在单张H100上测量。
在WOD-E2E测试集上,通过单次推理,Fast-dDrive(支架投机解码)达到了对比方法中最低的ADE@3s和ADE@5s,以及明显高于扩散基线dVLM-AD且与最强自回归基线相当的RFS。添加共享前缀多轨迹展开进一步降低了ADE值,相对于单次支架投机解码传递,墙钟时间成本低于2倍。在效率方面,Fast-dDrive的运行吞吐量是dVLM-AD和自回归基线的4倍–6倍,同时每轮模型前向传递提交约5个词元。
表3:nuScenes验证集L2误差。*:零样本。
在nuScenes验证集上,Fast-dDrive在列出的具有推理能力的VLM/VLA系统中实现了最低的平均L2,在所有三个时间跨度上均优于扩散和带CoT的自回归基线;它也达到或优于缺乏可解释推理的经典基于训练的驾驶策略。
4.3 效率与性能分析
表4:WOD-E2E验证集推理效率与精度对比。延迟:每样本平均墙钟时间。TPS:每秒词元数(包含脚手架词元)。Tok/Step:每轮模型前向传递的有效提交词元数。
在Fast-dDrive变体中,支架投机解码实现了最低延迟和最高吞吐量,TPS几乎是普通自推测解码的两倍,同时精度相当。加速源于支架自动接受,它从起草-验证循环中移除了约30%的词元。与每步去噪都需要全序列重计算的dVLM-AD相比,支架投机解码通过结合块级KV缓存复用和支架感知推测接受,实现了约6倍的吞吐量。自回归基线尽管共享相同的主干网络和训练数据,但速度较慢且精度低于块扩散变体。将支架投机解码集成到SGLang中,通过优化内核和CUDA图额外获得约3倍加速,达到相比AR基线11.8倍的端到端加速。
4.4 消融实验
表5:SASD消融实验(WOD-E2E验证集,支架投机解码)。IWL:章节重要性加权损失。SNS:章节自适应噪声调度。
通过对SASD训练的两个组件(章节重要性加权损失IWL;章节自适应噪声调度SNS)进行消融,IWL是主要贡献者:通过加大轨迹和元行为词元的权重,它直接放大了对规划质量最关键位置的梯度,相对于均匀权重基线获得了明显的RFS提升。SNS单独提供了较小但互补的增益,通过对安全关键章节偏向更困难的去噪配置来偏置噪声调度。结合使用时,IWL和SNS在所有配置中实现了最佳RFS。
图4(b)显示ADE@5s随轨迹展开次数单调递减;我们采用作为默认值,这提供了有利的精度–延迟权衡。
结论
我们提出了Fast-dDrive,一种利用驾驶输出固有结构以同时推进规划精度和推理效率的块扩散VLA。通过将确定性模式词元视为冻结支架、将扩散块与语义章节对齐、并在训练期间优先处理安全关键词元,Fast-dDrive实现了最先进的轨迹精度,吞吐量是全序列扩散基线的6倍,证明了结构化生成与高效解码是互补而非冲突的目标。共享前缀多轨迹展开方案进一步表明,块扩散自然地接纳了一种自回归模型无法使用的低成本测试时扩展维度。当模型输出具有已知结构时,将该结构编码到扩散过程中可在质量和速度上产生复合增益。

随机文章
-
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
- 为什么国外汽车巨头很少高调聊自动驾驶?买车人真正该懂的不是谁更会宣传
- 运动轿跑SUV新选择?岚图追光S登场!
- 手握35万买豪华SUV,沃尔沃XC70和奥迪Q5L到底怎么选
- 高阶智驾走进30万以内,四款SUV的诚意体现在哪
- 国产SUV被严重低估!王传福掏心窝子说真话,它真比想象中省油耐造!
- 奥迪全系SUV怎么选?从Q2L到Q8,这几个关键差异要看清楚
- 红旗E-HS3:26万买四驱纯电SUV,680牛米的扭矩为什么没人聊
- 15万左右家用SUV推荐:东风本田CR-V,把家用SUV的本质需求做到位
- 2026款坦克300三锁越野SUV先别急着冲,真正要看的是你会不会天天为“硬派”买单
- 雷克萨斯NX 300h:37万买混动SUV,这台车的账该怎么算
