最近面了几家智驾的公司,想了解下这个行业发展到了什么地步,遂写下这篇随想,整理一些自己的观察和思考。
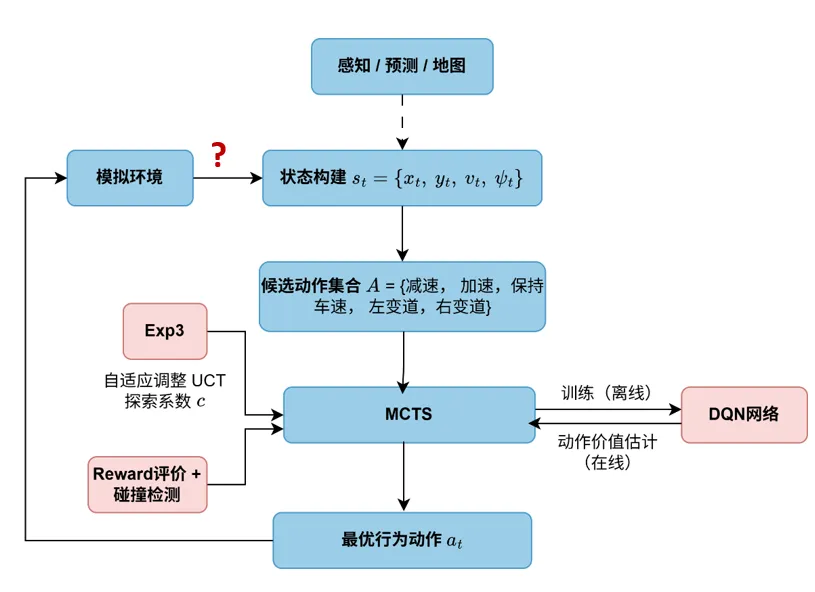
我目前的研究方向主要是智能制造中的算法开发,但在大学期间,我曾经花了相当长一段时间研究自动驾驶,主要负责的是决策规划。那是在2021年左右,当时深度强化学习和蒙特卡罗树搜索是最热门的研究方向。自从 AlphaGo 击败李世石之后,这类结合神经网络与搜索算法的思想,开始被关注,后来逐渐影响到特斯拉对于决策与路径规划问题的思考。
但它毕竟是一种搜索算法,搜索空间与计算资源之间的平衡始终是一个很大的问题。尤其是在自动驾驶这样高度动态、状态空间巨大的场景中,如果每一步都依赖大量采样和 rollout 来估计节点价值,计算成本会迅速上升。因此,一个很自然的想法就是引入训练好的深度神经网络,为搜索过程提供先验,例如对动作选择的初步判断,或者对某一状态价值的快速估计。
从这个角度看,蒙特卡罗树搜索和神经网络本身就是相辅相成的:神经网络可以弥补树搜索效率不足的问题,而树搜索则在一定程度上缓解了神经网络黑盒性带来的不可解释问题。神经网络直接输出决策时,我们往往很难解释它为什么选择某个动作;而通过搜索树,我们至少可以看到算法在不同候选路径之间是如何比较、筛选和权衡风险的。
但这个方案在如今的工程师看来肯定会被毙掉,原因就是实时性,尤其是当时我还在其中加入了些自适应的搜索策略来平衡树搜索的广度和深度,还有一些千奇百怪的碰撞检测模块。如今的决策/规划模块通常要做到 10Hz–20Hz,也就是每 50–100ms 更新一次,很遗憾由于当时的算力和没有AI辅助的代码优化,树搜索模块就已经占到了100ms。总结下来就是自动驾驶不是下棋,环境无时无刻发生着的变化,就算是最聪明的决策没有办法进行快速稳定的输出,那么它就很难落地。
近年来,自动驾驶领域最常被讨论的技术路线之一,便是端到端。所谓端到端,并不一定意味着完全取消所有中间模块,而是说模型不再只优化某一个局部任务,比如车道线检测、目标识别或者轨迹预测,而是希望从更原始的输入出发,直接学习到和最终驾驶行为更相关的表征。
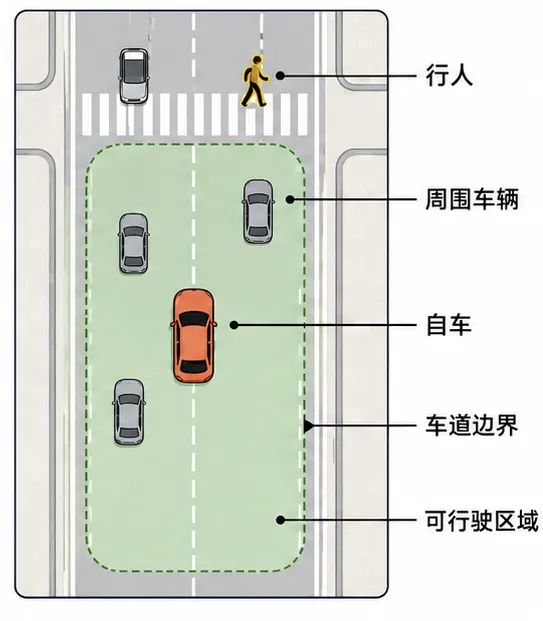
在实际系统中,这个过程通常不会真的简单到“摄像头输入,方向盘输出”。更常见的做法是,系统先把来自多个摄像头的视频信息融合起来,转换成鸟瞰图 BEV 或者某种三维场景表征。BEV 可以理解成站在车辆上方俯视整个道路:周围车辆在哪里,行人在哪里,车道边界在哪里,可行驶区域在哪里,都被压缩到一个更适合机器理解的空间坐标系中。随后,一个更大的神经网络会基于这个空间表征,进一步完成目标运动预测、路径规划,甚至直接输出加速、刹车、转向等动作。
但问题随之而来:车队每天产生的数据量极其庞大,不可能把所有视频都上传、标注并用于训练。因此,数据筛选本身也变成了自动驾驶系统的一部分。这里就会用到类似 trigger 和 Ring Buffer 的机制。可以把 Ring Buffer 理解成一个循环录像机:车辆会持续缓存最近一段时间的传感器数据和驾驶状态,当缓存达到上限时,旧数据会被新数据覆盖,正所谓“旧的不去,新的不来”。但如果系统检测到某些紧急事件,比如驾驶员接管、急刹车、碰撞风险,或者车辆行为和人类驾驶习惯出现明显偏差,那么这个事件前后的一小段数据就会被触发保存下来。某种意义上,它有点像强化学习中的 replay buffer,只不过在自动驾驶中,这个“经验池”来自真实采集的数据,而不是游戏环境中的智能体交互。
这些被保存的数据往往比普通直行、跟车、等红灯的片段更有价值,也就是我们所说的corner case。通过这种方式,自动驾驶公司可以不断发现失败案例、补充训练数据、重新训练模型,再把改进后的模型部署回车辆,形成一个数据闭环。
我之前看 Ashok 在 ICCV 2025 相关演讲中的介绍时,有一个点让我印象很深:未来的自动驾驶不仅仅是在做二维图像识别,而是在试图构建一个更完整的三维世界表征。例如,高斯溅射这类方法可以用一组三维高斯分布来描述场景中的几何结构和外观信息,从而帮助系统从有限的摄像头视角中恢复更立体的环境理解。对自动驾驶来说,这一点非常重要,因为车辆看到的永远只是局部视角,而真正的驾驶决策却需要理解整个三维世界,这就让我觉得解决自动驾驶终极问题的角度往往是在探索人类大脑的思维和认知能力。
在这之前,我时常在思考,特斯拉的端到端和Waymo的rule-based究竟谁会脱颖而出,一个是终极范式,一个是保守的安全工程。
前段时间旧金山大规模停电导致交通信号灯失效,很多 Waymo 车辆在路口停滞甚至造成交通阻塞,这个事件就很有代表性。它并不能简单证明 Tesla 的路线一定更先进,但至少暴露出一个问题:当自动驾驶系统高度依赖规则假设时,一旦现实世界偏离了预设条件,就可能出现非常尴尬的 corner case。
感觉rule-based有太多的corner case需要手动解决,而且很难定义,比如跟车距离的规则需要路面的摩擦系数,暴雨中路面水坑的深浅,也许FSD能够很elegant的解决这类东西,但是往往rule-based对于corner case的修复是非常快的,FSD通常需要更多的时间成本继续训练,不过它真正让人期待的地方在于,一旦模型学到了足够丰富的驾驶经验,它可能不仅能解决已经被定义出来的问题,还能在一些工程师没有提前写规则的 corner case 中,表现出超出预期的泛化能力
我现在更倾向于认为,端到端的方向大概率是对的,而且不需要考虑可解释性的问题(从监管者的角度来说还是需要的,或者说离线可解释性是必要,在线的话太傻了你在打车的时候需要人类司机把他的每一步都告诉你吗),因为人类驾驶员在做出驾驶行为时通常都是下意识的,而不是一步步推理或者检索知识库。举个例子,你在车道上突然窜出一条狗,你就会下意识把车开到对面的车道中去。
最后我想做个反思,就是总结下我在面试中被问到的几个有意思的问题或者主题:
第一,evaluation 本身就是一个非常困难的问题。我们究竟如何定义一个智驾系统“开得好”?传统的 loss 只能反映模型在离线数据上预测得是否接近人类驾驶行为,但这并不一定等价于真实道路上的安全和可靠。尤其在 closed-loop 场景中,模型的一个小错误可能会改变后续环境状态,并导致错误不断累积。
此外,驾驶任务本身并不是只有一个标准答案。比如前方出现障碍物时,车辆可以提前减速、轻微绕行、变道,甚至选择等待,这些行为在不同场景下都可能是合理且安全的。
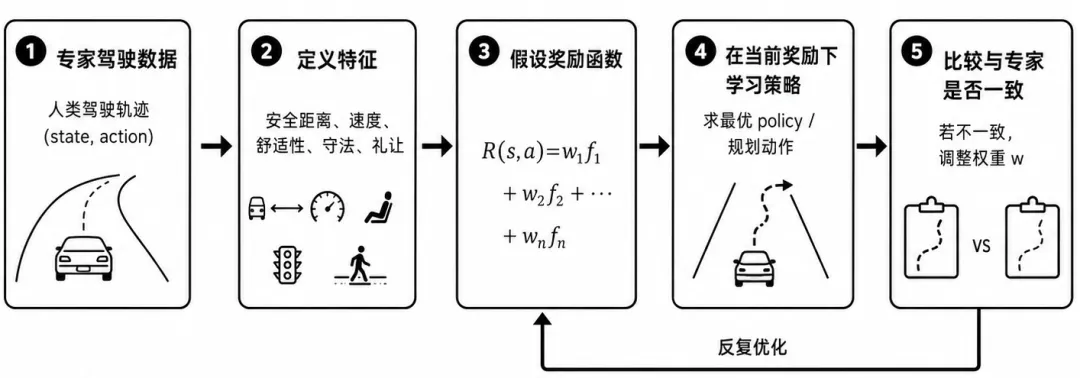
第二,reward function 的定义仍然是一个长期难题。这个问题其实在几年前的强化学习和自动驾驶研究中就已经存在。即使现在模型结构越来越复杂,数据规模越来越大,如何定义“正确的驾驶目标”仍然没有被彻底解决。过去有一种方法叫 Inverse Reinforcement Learning,也就是逆强化学习,它试图从人类驾驶数据中反推出 reward function,让模型学习人类驾驶员隐含的偏好和决策标准。
第三,自动驾驶和机器人的控制究竟谁更能难,如果只从低层控制角度看,机器人可能更难。机器人通常有更多自由度,例如手臂、手指、腿部,而且还涉及复杂的接触动力学。比如一个机器人要拿起杯子,不仅要判断杯子的位置,还要控制力度、摩擦。但如果从系统级安全和开放环境角度看,自动驾驶可能更难。汽车的控制自由度相对较少,通常主要是转向、加速和制动,但它面对的是不可控的真实交通环境。道路上有其他车辆、行人、自行车、施工区域、遮挡、天气变化以及各种场景。自动驾驶一旦判断或控制不当,可能直接造成严重事故甚至人员伤亡。

 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
