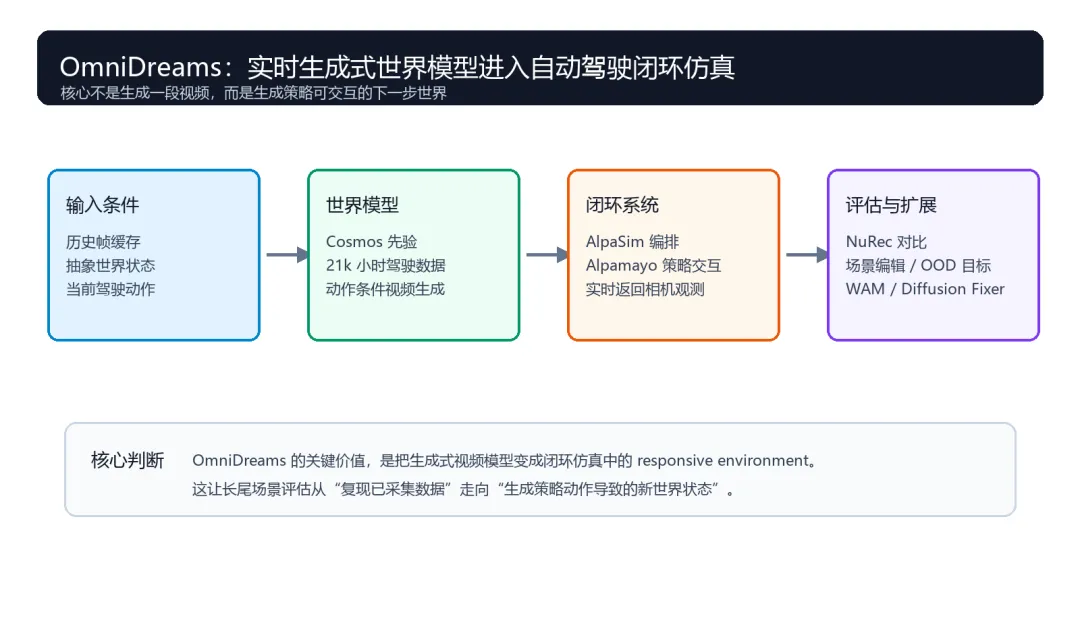
NVIDIA OmniDreams:实时生成式世界模型进入自动驾驶闭环仿真
作者 | NVIDIA
论文标题 | NVIDIA OmniDreams: Real-Time Generative World Model for Closed-Loop Autonomous Vehicle Simulation
arXiv | 2606.03159v1
关键词 | 自动驾驶仿真 / 生成式世界模型 / Cosmos / 闭环评估 / AlpaSim / Alpamayo / WAM前言
自动驾驶模型越强,评估就越难。尤其是在长尾场景中,真实道路测试成本高、风险大,传统闭环仿真又很难同时满足真实感、可交互性和泛化能力。
现有神经仿真器大多偏向 reconstruction-based。它们可以在采集过的场景里做出很逼真的新视角渲染,但本质上仍被初始采集数据限制:当策略车开出原始轨迹、场景出现极端天气,或者动态交通参与者出现未见过的行为时,仿真质量会快速下降。
OmniDreams 的出发点正是解决这个矛盾:不再只重建已经发生过的场景,而是用生成式世界模型实时合成策略下一步会看到的传感器观测。
一句话概括:OmniDreams 把 Cosmos 的生成先验、21k 小时驾驶数据训练和 AlpaSim 闭环仿真系统结合起来,让世界模型从“生成视频”走向“可交互仿真环境”。研究背景:为什么重建式仿真不够用
闭环仿真和离线重放最大的区别在于,策略模型会主动改变环境状态。策略给出动作后,仿真器需要更新自车位置、交通参与者状态和世界场景,并生成下一时刻传感器观测。这个过程不断循环,才能真实评估策略在长尾场景中的行为。
重建式仿真在这里遇到两个核心瓶颈:
- 第一,轨迹一旦偏离原始采集路径,渲染质量容易下降。 因为很多新视角、新遮挡和新交互并没有被原始数据覆盖。
- 第二,动态场景泛化能力有限。 极端天气、少见物体、异常交通参与者行为等,往往不是简单重建可以可靠外推的。
因此,闭环仿真真正需要的是一种能够随策略动作实时反应的生成式环境。OmniDreams 将自己定位为这个环境中的 sensor generator:策略不是观看固定视频,而是在和一个可生成、可响应的世界交互。
图 1:闭环仿真流程。策略模型(这里是 Alpamayo 1)或用户向 AlpaSim 仿真运行时发送动作。AlpaSim 更新仿真状态,并将上下文转发给 OmniDreams;OmniDreams 合成下一组相机帧并返回给策略模型,从而完成闭环。
OmniDreams:动作条件的实时世界模型
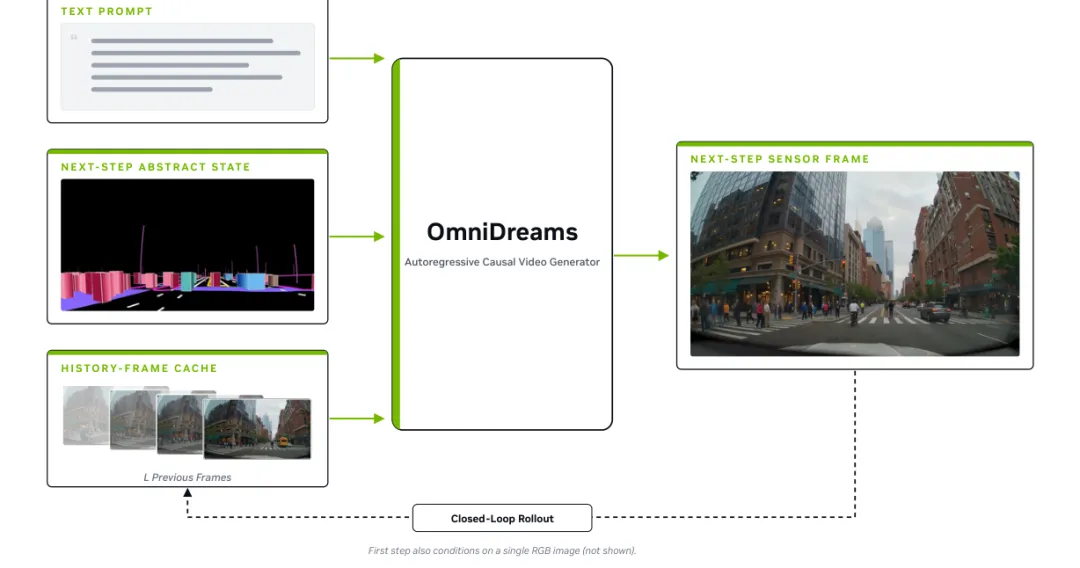
OmniDreams 基于 Cosmos diffusion model 进行 mid-training 和 post-training,目标是自回归生成 action-conditioned video。它的输入不是单一图像,而是由三部分组成:
- 历史帧缓存
- 当前仿真状态:来自 AlpaSim 的抽象 world-scenario map、目标状态和场景结构;
- 即时驾驶动作:策略模型当前给出的动作,决定下一步世界如何响应。
这使 OmniDreams 和普通 text-to-video / image-to-video 模型有本质区别。它不是为了生成一段看起来合理的视频,而是要在闭环系统中持续生成下一组传感器观测,并让这些观测和策略动作、世界状态保持一致。
图 3:OmniDreams 基于三类输入生成下一步传感器帧:文本提示、来自仿真器的下一步抽象状态,以及历史帧缓存。这些帧随后返回给策略模型,用于闭环交互。第一步生成时,OmniDreams 还会条件于一张 RGB 图像,图中未展示。
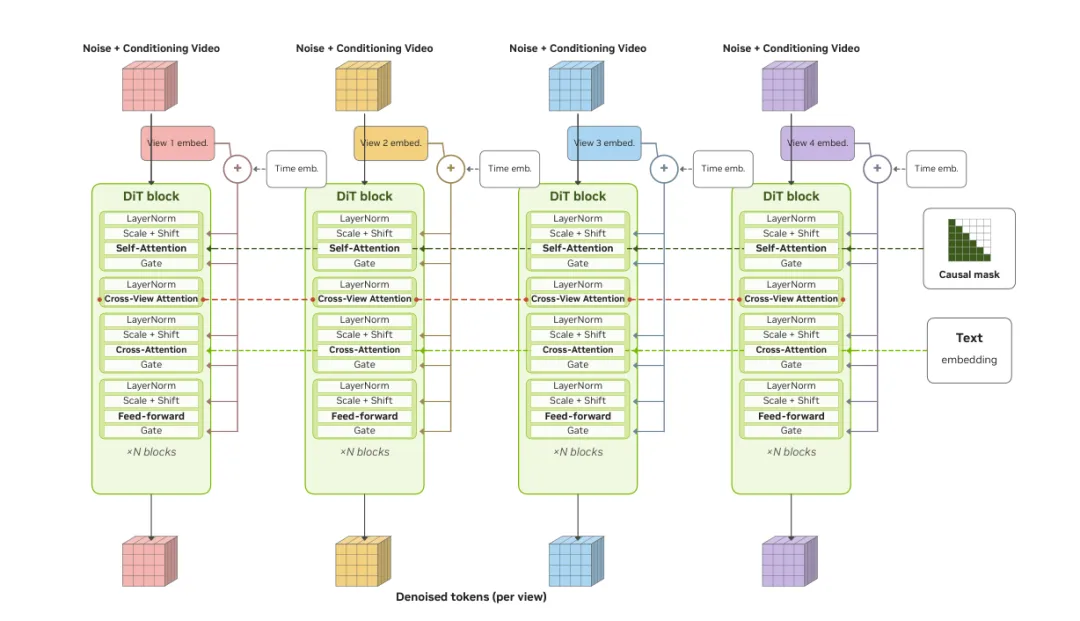
模型结构:多视角一致性是关键
自动驾驶策略通常消费多相机输入,因此世界模型不能只生成单视角视频。OmniDreams 在 Cosmos-Predict 2.5 backbone 基础上做了 multi-view adaptation,在 Multi-View Cross Block 中加入两类关键设计。
第一是 view embedding。不同相机视角会有各自的视角身份信息,并作为 AdaLN 的调制信号进入网络,使模型知道当前 token 来自哪个 camera view。
第二是 Cross-View Attention。它让一个视角中的 token 可以 attend 到其他视角中的 token,从而增强不同相机之间的场景一致性。对自动驾驶来说,这一点很重要:前向、侧向、交叉视角看到的道路结构和动态目标必须属于同一个世界。
关键点:OmniDreams 的难点不只是“生成清晰视频”,而是生成多视角、时间一致、动作响应一致的闭环传感器流。图 4:多视角 OmniDreams DiT。相比单视角 Cosmos-Predict 2.5 backbone,每个 Multi-View Cross Block 增加了 view embedding 和 Cross-View Attention,用于强化不同相机视角之间的一致性。
训练与加速:从能生成到实时生成
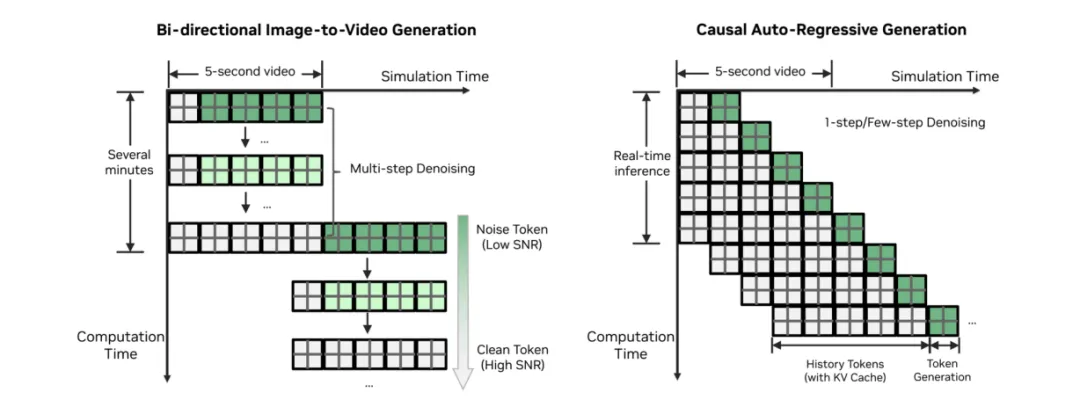
论文在训练上采用了多阶段策略。首先利用 Cosmos 的视觉先验,再通过 21k 小时驾驶场景进行中训练和后训练,让模型适配自动驾驶中的多视角、动作条件和世界状态控制。随后,论文还使用 Diffusion Forcing、Self Forcing 等蒸馏策略,把模型从高质量但较慢的生成过程压缩到更适合实时闭环的推理模式。
为了支持长时间 rollout,OmniDreams 使用基于因果 KV-cache 的自回归生成。直观理解是,模型不需要每次从头处理全部历史,而是维护一个历史状态缓存,让后续 chunk 生成能沿着前面的世界状态继续展开。
图 5:自回归视频生成示意。右侧展示基于因果 KV-cache 的生成方式,用于实现一致的长视频 rollout;左侧为双向 image-to-video 去噪方式。
实时性是这篇论文的另一个核心指标。以四视角 OmniDreams-MV 为例,论文在 NVIDIA GB300 上给出了 per-chunk 推理耗时。每个 chunk 生成 16 个 RGB 帧 / 4 个 latent 帧,KV-cache 更新被放在非关键路径,最终 Effective FPS 按单相机统计。
表 3:NVIDIA GB300 上四视角推理的 per-chunk 耗时。每个 chunk 包含 16 个 RGB 帧 / 4 个 latent 帧;KV-cache 更新不计入 Total,因为它不在关键路径上。Effective FPS 按 K/Totalms 计算,其中 K=16,按单个相机表示。
这里可以把系统贡献拆成三层:第一层是生成质量,要求视频真实且时间连续;第二层是闭环响应,要求生成结果受策略动作影响;第三层是实时推理,要求模型能够接入仿真系统,而不是只离线生成 demo。闭环集成:OmniDreams 接入 AlpaSim
OmniDreams 被部署到 AlpaSim 中,与 Alpamayo 1 policy model 形成闭环。策略根据当前相机观测输出动作,AlpaSim 更新仿真状态,再把状态传给 OmniDreams 生成下一时刻相机帧。这个循环持续进行,形成可交互的仿真环境。
相比离线视频生成,这里的关键在于“反应性”。如果策略向左偏、加速或改变路线,OmniDreams 需要让接下来的视频观测相应变化,而不是沿着原始日志继续播放。
论文还展示了场景编辑和 OOD 目标建模能力。例如,通过修改文本提示、首帧条件和抽象 world-scenario map,可以改变天气、时间、行驶轨迹或插入少见目标,同时保持道路几何和远处背景稳定。这类能力对于长尾场景评估非常重要,因为仿真器需要生成现实中很难大规模采集的风险情境。
实验:它能不能替代重建式仿真?
论文重点比较了 OmniDreams 和 reconstruction-based NuRec。在闭环策略评估中,一个合格的仿真器不一定要在每个像素上完全复刻真实世界,但必须保持策略 ranking 和事件统计的可信性。
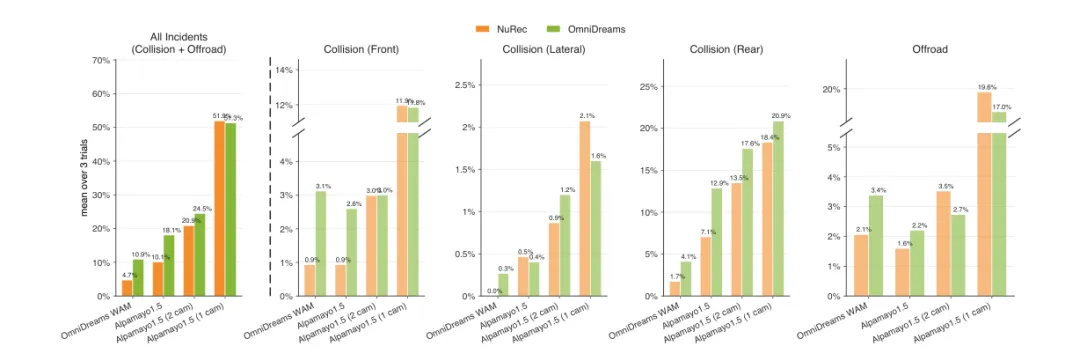
Figure 13 展示了多个 policy class 下 OmniDreams 与 NuRec 的闭环对比。左侧 All Incidents 面板显示,切换到 OmniDreams 后,策略排名仍然能够保持。这说明 OmniDreams 至少可以作为闭环策略评估的 faithful proxy。
图 13:在多种策略类别下,OmniDreams 与 NuRec 的闭环对比。每组柱子比较同一策略在 AlpaSim 传感器仿真器为 NuRec(橙色)和 OmniDreams(绿色)时的结果,基于 Physical AI Autonomous Vehicles NuRec 的 501 个场景子集平均;数值越低越好。左侧 All Incidents 面板在切换到 OmniDreams 后仍保持策略排序,说明 OmniDreams 可作为闭环策略评估的可靠代理。
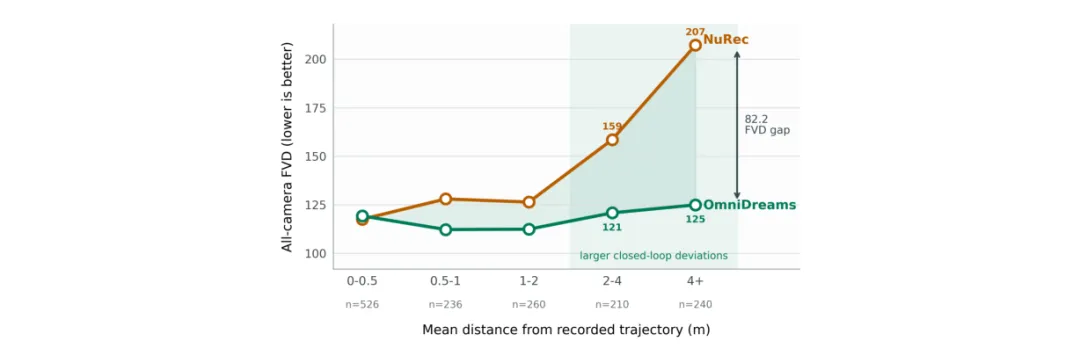
更有意思的是 Figure 14。随着 rollout 轨迹逐渐偏离原始记录,NuRec 这类重建式仿真的视觉质量会明显退化,而 OmniDreams 仍然能维持更稳定的 FVD。这正好对应了论文前面的核心论点:重建式方法擅长复现采集过的场景,但在新轨迹、新动态和长尾变化上泛化不足。
图 14:Physical AI NuRec 数据集上 OmniDreams 与 NuRec 的 FVD 对比。随着新轨迹偏离原始真实记录,OmniDreams 仍能维持视觉仿真质量,而重建式 NuRec 仿真器开始快速退化。
定性结果也体现了这一点。NuRec 依赖每个场景的重建,遇到行人、遮挡或复杂动态时容易出现伪影;OmniDreams 则基于首帧和抽象世界状态生成相机观测,可以更自然地补全动态目标和道路上下文。
图 15:OmniDreams 与 NuRec 的定性对比。NuRec 基于每个场景的重建结果渲染,OmniDreams 则从首帧种子和抽象世界场景生成相机观测。OmniDreams 保留车道几何、交通参与者和场景布局等关键驾驶线索,同时改善行人质量并生成更自然的行人运动。
从世界模型到策略模型:WAM 的信号
论文还有一个值得注意的延伸:OmniDreams 不只可以作为仿真器,也可以 post-train 成 World-Action Model(WAM),直接用于 policy architecture。摘要中提到,基于 OmniDreams 后训练得到的 WAM,在 Physical AI Autonomous Vehicles NuRec 数据集上取得了强结果,超过 VLA-based Alpamayo 1.5 research policy model,同时只使用约 1/5 参数量。
这意味着实时世界模型可能不只是环境生成器,也可能成为策略模型的 backbone。换句话说,模型在学习“世界如何响应动作”的过程中,也学到了一部分可用于决策的动力学和语义结构。
结论:自动驾驶仿真的范式正在变化
OmniDreams 的贡献可以总结为三点。
- 第一,它把生成式世界模型接入闭环仿真。 生成结果不再只是离线视频,而是策略交互后的下一步传感器观测。
- 第二,它把多视角一致性、长 rollout 和实时推理放在同一个系统里解决。 这让世界模型更接近自动驾驶仿真器,而不是普通视频模型。
- 第三,它展示了世界模型向 policy backbone 迁移的可能性。 WAM 的结果说明,学习世界响应也可能帮助模型学习决策。
当然,这条路线仍然有需要继续验证的地方。生成式仿真是否能覆盖足够多真实危险场景?闭环指标和真实道路表现之间的相关性是否稳定?当策略进入模型训练分布之外的行为区域时,世界模型会不会生成看似合理但物理上不可靠的观测?这些问题会决定生成式世界模型在自动驾驶评估中的上限。
总体来看,OmniDreams 的意义不在于又做了一个更好看的驾驶视频生成模型,而在于它把生成模型放进了自动驾驶闭环系统。对于长尾场景评估来说,这可能是比“重建更真实”更重要的一步:仿真器不只要复现过去,还要能响应未来。



 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
