
论文速览
- 澳门理工大学、韩国科学技术院(KAIST)、东南大学、佛山大学等联合团队提出了一种名为 NOMAD 的终身轨迹规划框架,通过非参数贝叶斯记忆与扩散模型的结合,使自动驾驶车辆能够持续适应开放世界中的长尾场景。
- 该方法在 nuPlan 闭环评估中,不仅在常规驾驶任务上保持极具竞争力的表现,还在长尾复杂测试中显著超越了现有基线,并展现出优异的克服灾难性遗忘的能力。

论文信息
标题:NOMAD: Lifelong Trajectory Planning via Non-Parametric Bayesian Memory-Adaptive Diffusion Experts「NOMAD:基于非参数贝叶斯记忆自适应扩散专家的终身轨迹规划」作者:Yixian Chen, Rufan Bai, Jiangbin Zheng, Yimin Wang, Tiantian Chen, Wei Wang, Yuhuan Lu会议:International Conference on Machine Learning (ICML)
核心问题
在连续接收新驾驶场景数据的开放世界中,自动驾驶系统如何持续学习并适应罕见的长尾情况,同时避免遗忘已经掌握的驾驶技能?
核心要点
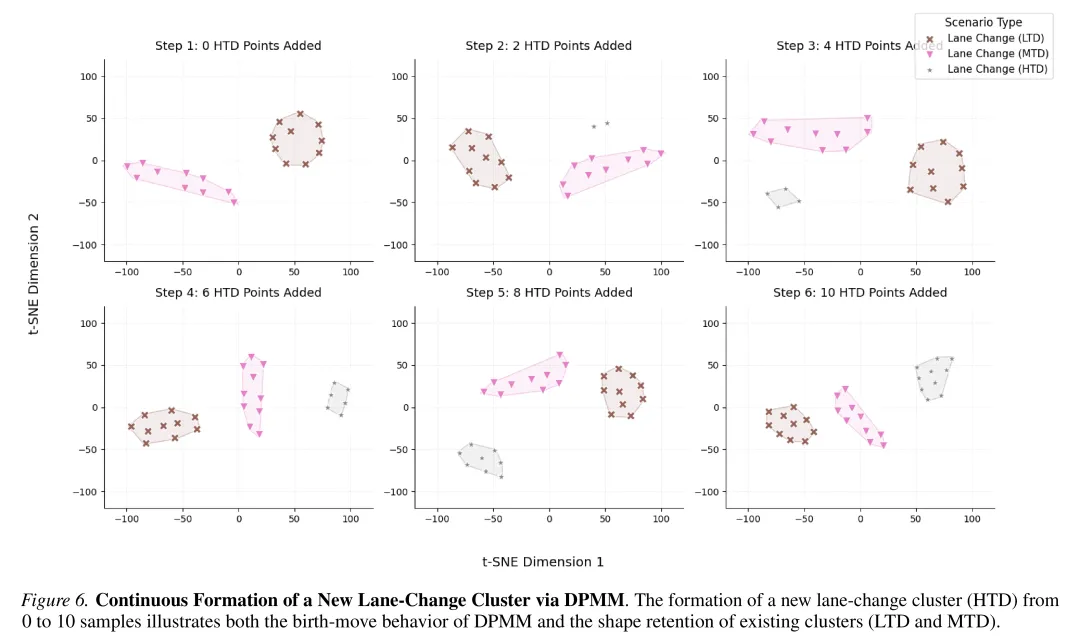
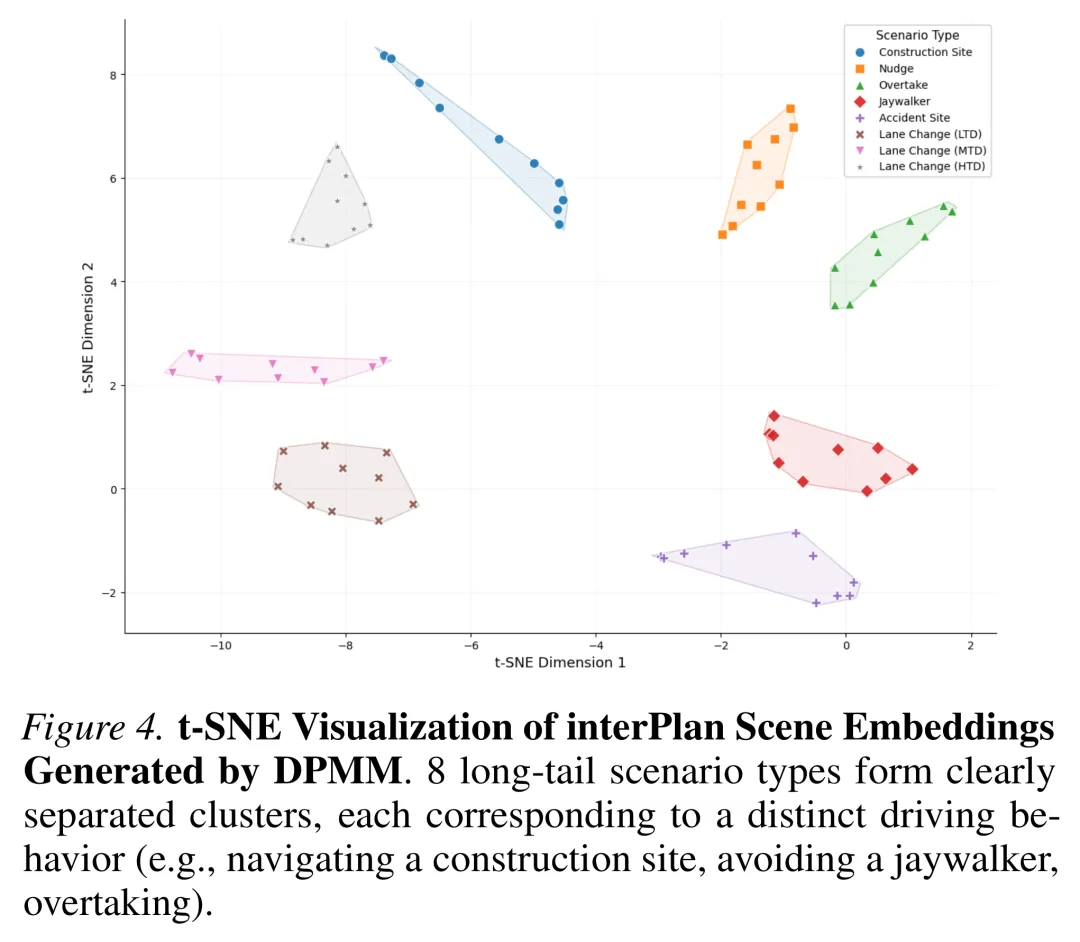
- 提出了一种动态扩展的记忆机制,利用狄利克雷过程混合模型(DPMM),在无需人工预定义类别数的情况下,自动从连续感知数据流中发现并聚类新的长尾场景。
- 设计了基于条件扩散模型的“专家混合”规划器,利用记忆簇索引进行条件化指导,使单一扩散主干网络能够针对不同场景展现出专业化的驾驶行为。
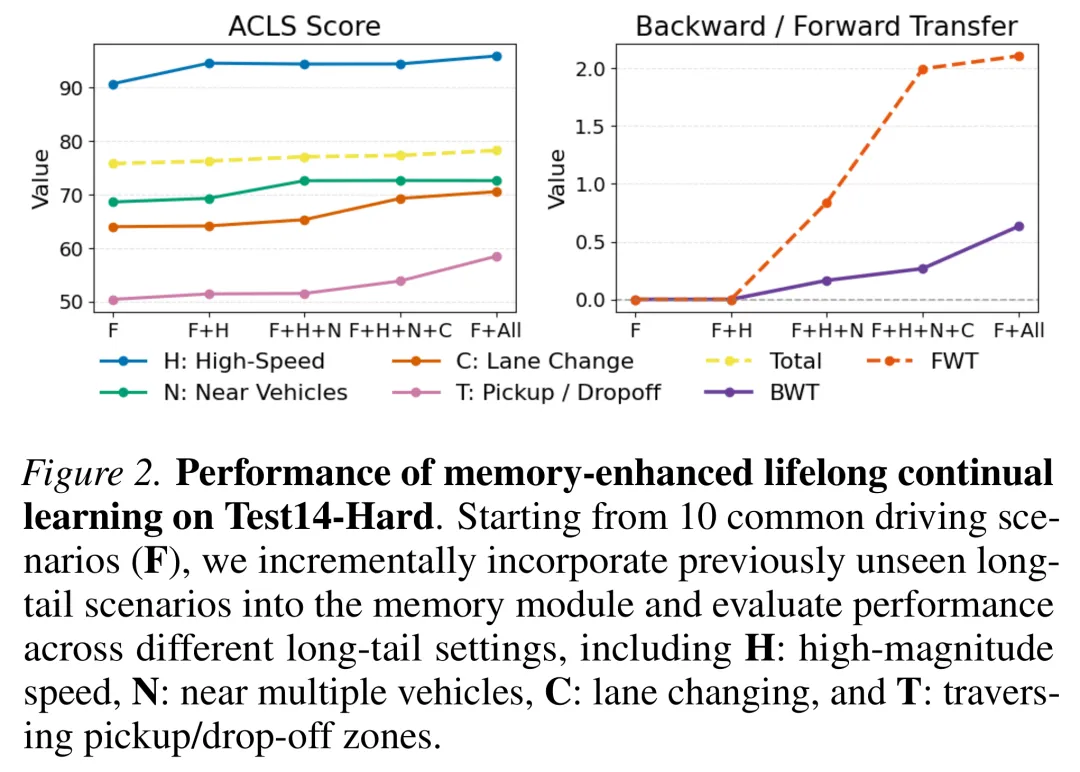
- 引入生成式回放机制应对灾难性遗忘,在 nuPlan 闭环长尾测试中性能较最强基线提升 9.4%,并呈现出正的后向迁移(positive Backward Transfer),说明模型在学习新长尾场景时仍能较好保留旧场景能力。
研究动机
现有的轨迹规划模型在部署后通常是静态的,难以泛化到现实世界中层出不穷的长尾驾驶事件,且在学习新技能时极易陷入“灾难性遗忘”。
在开放世界环境中,自动驾驶汽车会不断遭遇诸如不同城市的交通规范、罕见事故现场或复杂的施工区域等长尾场景。基于规则的控制器在复杂的互动场景下显得脆弱;而基于学习的方法虽然能捕捉多模态行为,但往往在遇到分布外数据时缺乏安全保证,且部署后模型固定,无法持续学习新特征。
要在不进行大规模重新训练的情况下积累经验并适应新领域,系统必须具备终身学习(Lifelong Learning)能力。然而,现有的持续适应方案要么难以克服新旧任务间的稳定性-可塑性权衡,要么依赖沉重的大语言模型推理,难以满足闭环控制的高实时性要求。如何让系统在动态扩充知识的同时保持快速反应,成为进阶自动驾驶面临的关键挑战。
方法思路
NOMAD 框架采用了解耦的模块化设计。上半部分通过分层场景编码器与非参数贝叶斯记忆动态划分并存储场景语义,下半部分利用这些离散记忆指导条件扩散模型作为“专家混合体”生成专业化轨迹,并结合生成式回放与安全推理机制保障系统的持续学习与物理合规。
动态扩展的非参数贝叶斯场景记忆
利用狄利克雷过程混合模型(DPMM),系统能够自动从连续的驾驶场景流中发现并维护离散的潜在记忆簇。
模型将连续的场景特征向量(embeddings)视为由潜在组件混合生成的观测值。与设定固定类别数的静态聚类不同,DPMM 允许组件数量随环境复杂度的增加而动态增长。
在增量学习过程中,通过记忆变分贝叶斯(memoVB)框架进行高效的后验推断。当系统遇到与现有簇拟合较差的新颖长尾场景时,memoVB 机制可通过“诞生”操作实例化新的组件;若合并相似场景能提高模型证据下界,则执行“合并”操作,从而自然地控制簇的规模。
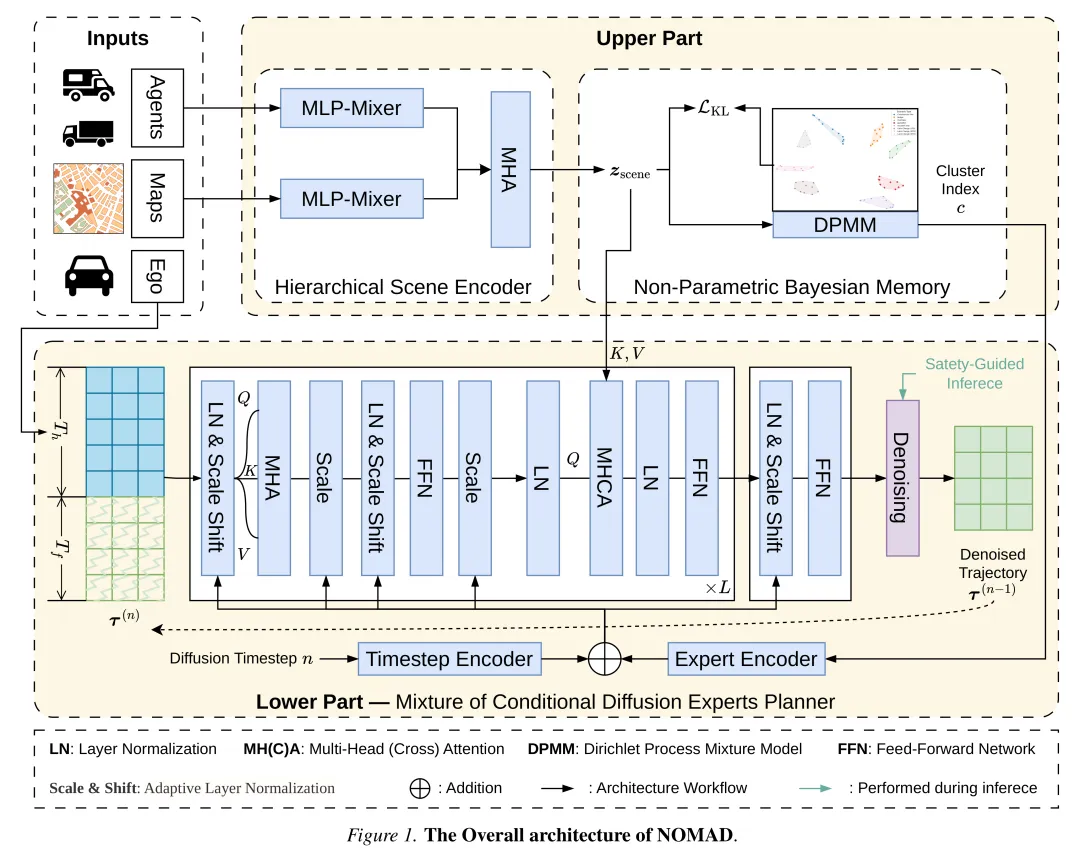
条件扩散专家混合规划器
将轨迹规划重构为以记忆上下文为条件的生成过程,使单个扩散网络能够针对不同场景类型表现出专业策略。
扩散模型接收来自贝叶斯记忆的簇分配索引作为离散的上下文条件。
该离散索引通过自适应层归一化(AdaLN)机制调制网络中的特征通道。这种设计相当于将网络隐式地划分为多个“扩散专家”,共用一个主干参数,从而为无保护左转或高速汇入等截然不同的场景生成特定轨迹。
定义了条件扩散模型的反向去噪过程,轨迹生成不仅依赖于当前噪声状态和时间步,还明确受到场景特征 z 和记忆簇上下文 c 的双重条件约束。
生成式回放与安全引导推理
采用生成式回放机制保护旧知识,并在推理阶段引入分类器引导,使生成轨迹更符合安全性、舒适性和可行驶区域等约束。
为克服灾难性遗忘,当识别出新簇并更新模型时,系统利用冻结的旧模型生成之前记忆簇的合成轨迹,与新任务数据混合训练。该做法避免了直接存储海量原始历史数据,同时维持了历史行为分布的稳定。
在推理阶段,设计了用于量化约束违反程度的可微能量函数,包括目标速度维持、舒适性约束和可行驶区域约束等。在反向采样时,利用该函数的梯度调整轨迹分布的均值,引导车辆避开危险区域。
分类器引导机制的核心公式:通过引入安全能量函数的梯度,系统在不重新训练基础模型的情况下,在采样时引导轨迹向更安全的分布空间偏移。
结果分析
在长尾与常规驾驶场景中均实现性能突破
NOMAD 在显著提升长尾复杂场景应对能力的同时,未对常规驾驶条件下的规划性能造成妥协。
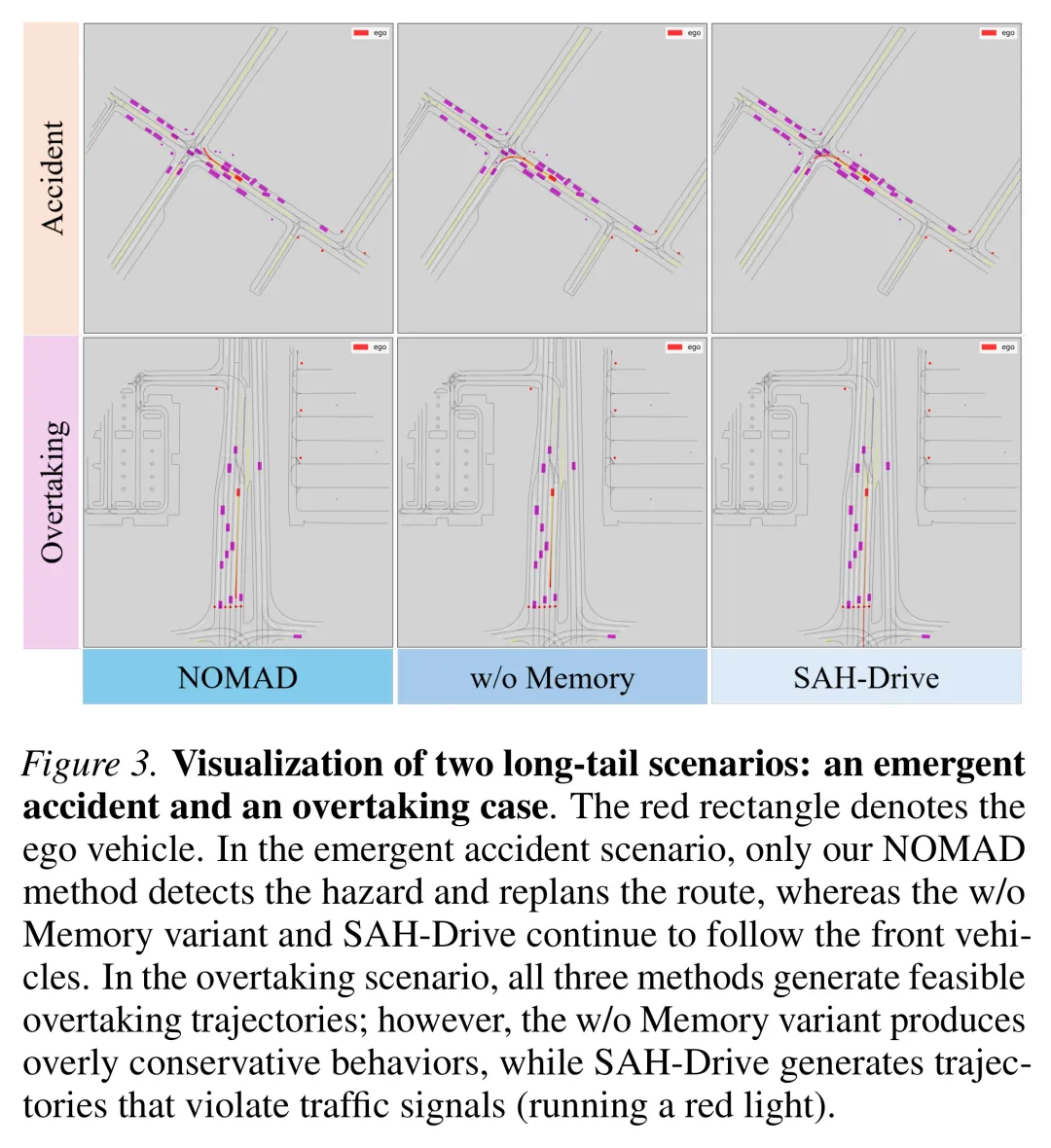
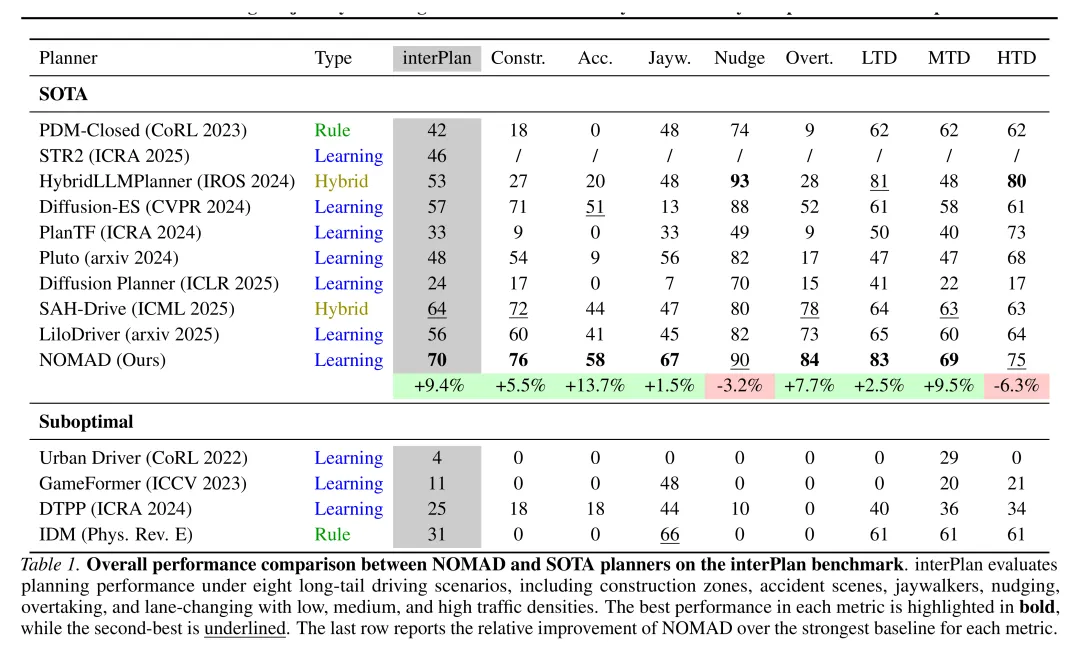
在 nuPlan 平台的闭环长尾基准(interPlan)测试中,NOMAD 取得了 70 的最高综合得分,较最强混合方法基线(SAH-Drive)提升了 9.4%。特别是在施工区域、事故现场、超车等挑战性分类中,NOMAD 表现出明显优势;整体 interPlan 分数达到最高。
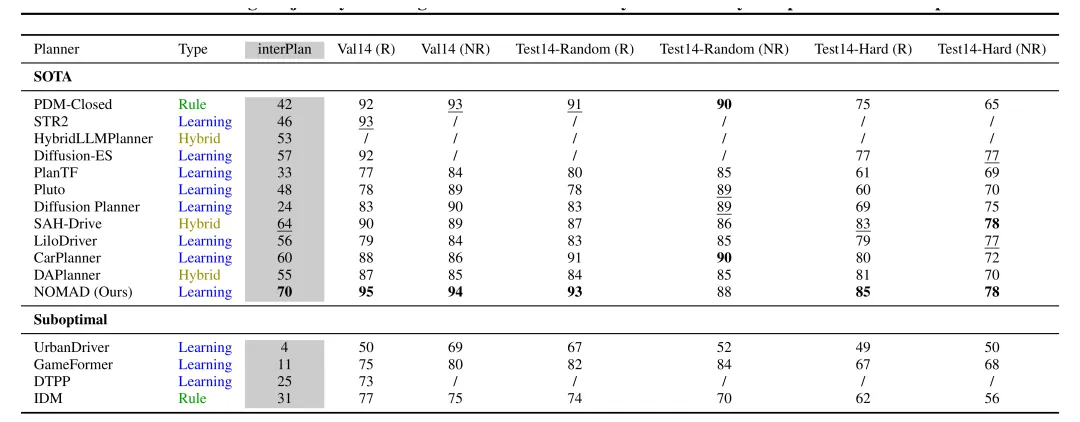
同时,在常规驾驶基准(Val14 和 Test14-Random)上,该方法在多数指标上达到或超过现有先进水平,说明长尾场景性能提升并未以牺牲常规驾驶能力为代价。结果表明,依靠显式记忆进行场景解耦,不仅增强了泛化性,也有力避免了模型在多模态冲突时坍缩为保守策略。
具备优异的防遗忘能力与实时推理效率
在增量引入新场景的评估中,该框架成功避免了灾难性遗忘,并保持了满足闭环要求的高效推理。
持续学习评估显示,随着新的长尾场景按时间顺序被引入,NOMAD 的平均闭环分数(ACLS)呈稳步上升趋势。更重要的是,系统呈现出正向的后向转移指标(Backward Transfer),这证明模型有效保留了早期掌握的驾驶行为。
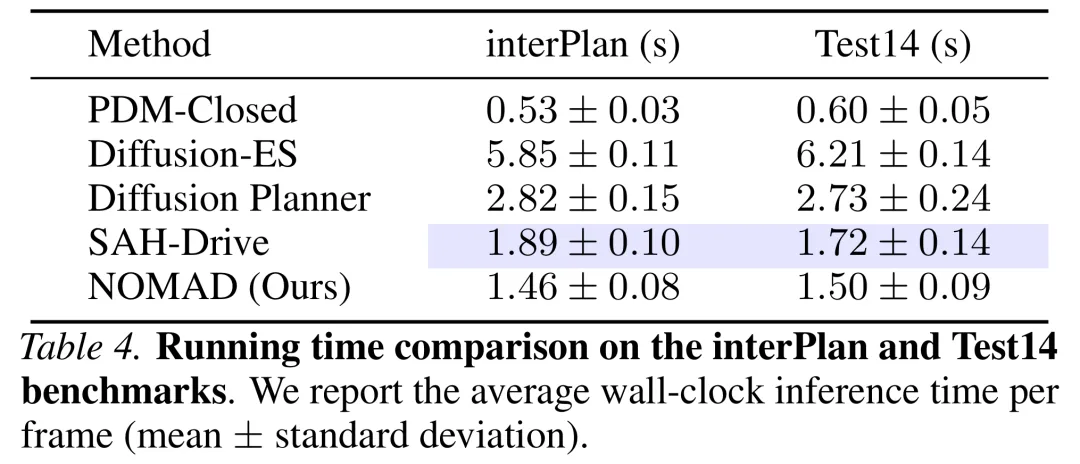
在计算效率方面,由于多个场景“专家”共享单一的扩散主干网络,免去了沉重的大模型推理或复杂的启发式切换,NOMAD 的单帧平均推理时间约为 1.46 秒,媲美轻量级混合规划器,完全能够满足实际闭环控制的实时性需求。
局限与展望
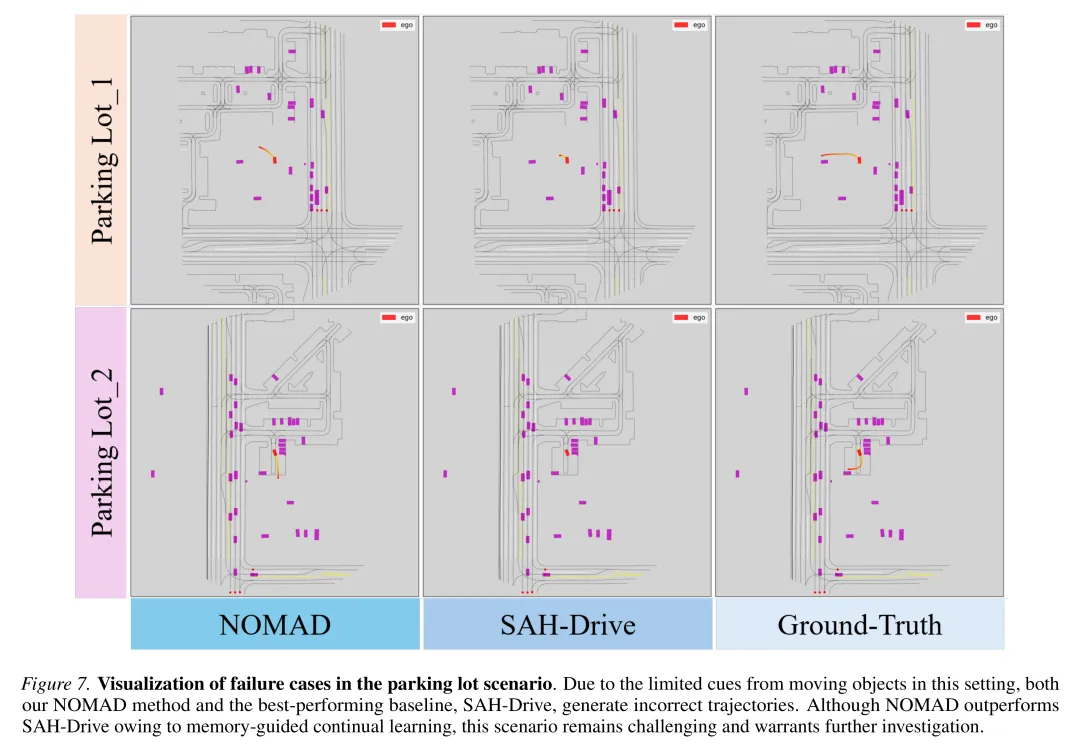
该方法目前在缺乏明确语义结构和动态上下文交互的场景(如标线稀疏的停车场环境)中表现存在局限。在此类场景中,环境线索不足会导致场景嵌入的区分度下降,进而引发记忆分配模糊和轨迹生成次优。未来的工作方向可能需要引入更丰富的空间表征、显式的意图推断机制,或将其与专门的低速机动控制模块相集成以补足短板。
更多图解
论文摘要
在开放世界环境中运行的自动驾驶车辆必须在保持原有驾驶技能的同时,持续适应罕见的“长尾”场景。然而,现有的轨迹规划方法通常依赖静态模型或僵化的基于规则的控制器,无法稳健地处理不断演变且复杂的交通动态,难以平衡稳定性与可塑性。针对这一背景,我们提出了NOMAD,一种将非参数贝叶斯记忆与基于扩散的轨迹生成相结合的终身轨迹规划框架,实现了对长尾场景的持续适应,且不会发生灾难性遗忘。该方法将连续的场景上下文映射到一组动态增长的离散记忆簇,引导条件扩散模型充当一组专门针对不同驾驶行为的“专家混合体”。为了在增量学习中保留过去知识,我们引入了一种生成式重放机制,用于合成来自先前学习到的记忆簇的伪经验。在nuPlan基准测试上的大量闭环评估表明,我们的方法在长尾场景上达到了最先进的性能,interPlan得分比最强基线提高了9.4%,同时在常规驾驶基准测试中保持了极具竞争力的性能。此外,我们的方法表现出稳健的持续学习能力,在适应顺序引入的长尾场景时,实现了最高的平均闭环得分,并呈现出正向的反向迁移效果。
< Fin >

 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
