PAPER READING · AUTONOMOUS DRIVING · VLA
MindDrive:当自动驾驶学会在试错中成长
从"模仿专家"到"自我进化"——首个在仿真器中用在线强化学习训练VLA自动驾驶模型的工作
论文信息
MindDrive: A Vision-Language-Action Model for Autonomous Driving via Online Reinforcement Learning
作者:Haoyu Fu, Diankun Zhang, Zongchuang Zhao, Jianfeng Cui, Hongwei Xie, Bing Wang, Guang Chen, Dingkang Liang, Xiang Bai机构:华中科技大学、小米汽车版本:arXiv:2512.13636v3 | 项目主页:https://xiaomi-mlab.github.io/MindDrive/
设想这样一个场景:一辆自动驾驶汽车行驶在城市道路上,前方是一辆缓慢行驶的卡车。变道超车,还是保持跟随?如果变道后恰好赶上红灯,是否当初减速跟随才是更明智的选择?人类司机会在一次次类似场景中积累经验、修正判断——但当前的自动驾驶视觉-语言-行动(VLA)模型,却很难做到这一点。
这篇论文试图回答一个关键问题:能否让自动驾驶VLA模型像人类一样,通过与环境的真实交互来持续提升决策能力?作者提出的MindDrive,是首个在仿真器中成功使用在线强化学习训练VLA自动驾驶模型的工作。仅用轻量级Qwen-0.5B模型,就在Bench2Drive闭环评测中取得了78.04的Driving Score和55.09%的成功率。
一、研究背景:模仿学习的天花板
当前主流的VLA自动驾驶模型几乎全部基于模仿学习(Imitation Learning, IL)训练。它的逻辑很简单:收集大量人类驾驶数据,让模型学会"看见什么场景,就做出什么动作"。这种方法在开环评测中取得了不错的效果,却存在两个根本性缺陷。
一是分布偏移(Distribution Shift):训练数据覆盖的场景终究有限,当模型在真实道路上遇到从未见过的情况,就可能产生不可预知的错误。二是因果混淆(Causal Confusion):模型可能学到的是表面关联而非真正的因果关系——比如"看到直道就加速",却不理解前方是否有慢车、信号灯是否即将变红。
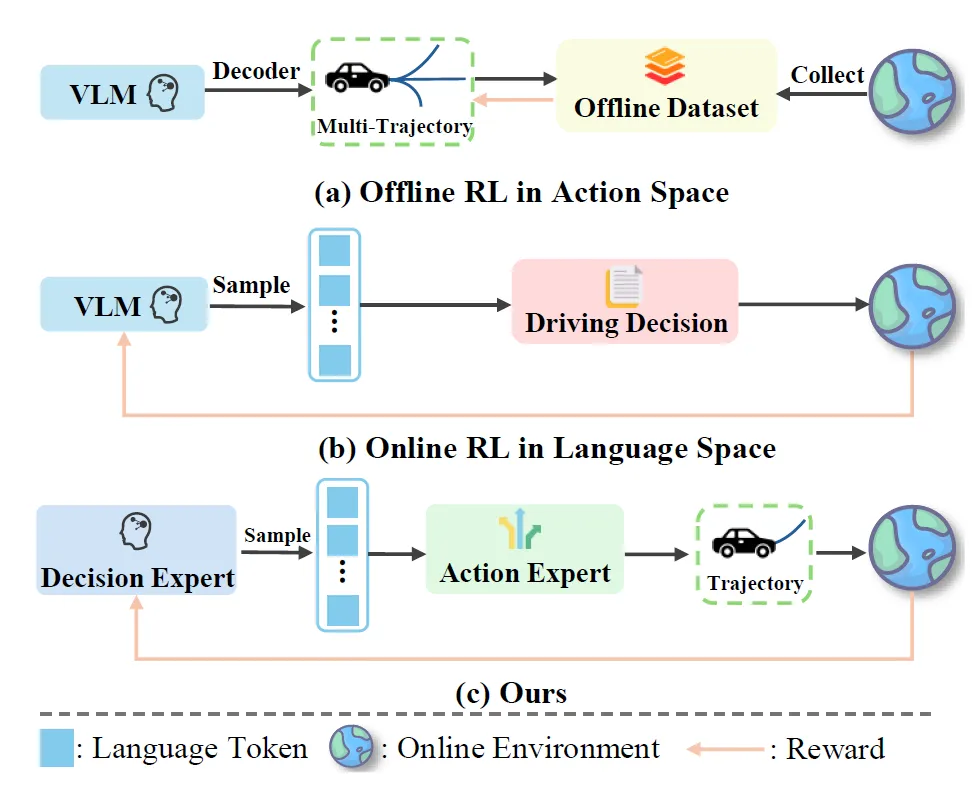
图 1:不同VLA强化学习范式的对比。(a) 离线RL直接在连续动作空间中优化轨迹,缺乏环境交互;(b) 在线RL在语言空间中优化决策,但难以映射为具体轨迹;(c) MindDrive通过语言-动作动态映射,在离散决策空间中进行高效的在线RL。强化学习(Reinforcement Learning, RL)提供了另一条路径:让模型在环境中试错,通过成功和失败的反馈信号来学习真正的因果关联。但将在线RL应用到自动驾驶VLA面临一个关键矛盾——自动驾驶的动作空间是连续的(方向盘转角、油门/刹车量),在连续空间中高效探索极为困难。
如图1所示,已有方案要么退回到离线数据上做RL(失去了与环境的真实交互),要么将决策放在语言空间中做RL却无法有效映射为具体的驾驶轨迹。MindDrive的核心创新正在于此:通过建立语言决策到连续轨迹的动态映射,将RL的探索空间从连续的轨迹空间"折叠"到离散的语言决策空间,同时用轨迹级别的奖励信号反向优化模型的推理能力。
二、核心贡献
1. 提出MindDrive框架。 引入"决策专家(Decision Expert)+ 行动专家(Action Expert)"双LoRA架构,将语言推理与轨迹生成解耦。决策专家负责场景理解和高层决策(如"保持低速·跟车道"),行动专家负责将语言决策映射为具体轨迹。
2. 设计高效的在线强化学习方案。 首个在CARLA仿真器中用在线RL训练VLA自动驾驶模型的工作。通过预计算场景token作为紧凑状态表示、24并行数据采集和大批量PPO训练,实现了稳定的策略优化。
3. 轻量模型即达SOTA。 仅用Qwen2-0.5B作为基座LLM,在Bench2Drive基准上达到78.04 DS和55.09% SR,超过同等规模的IL基线5.15 DS和9.26% SR,甚至超越了许多使用更大模型的方法。
三、方法详解
1. 整体架构:双专家解耦设计
MindDrive的核心设计理念是将一个LLM拆分为两个功能不同的专家,二者共享基座模型权重,仅通过不同的LoRA参数实现功能分化。这种设计确保了它们拥有共享的世界知识基础,同时各自专注于不同任务。
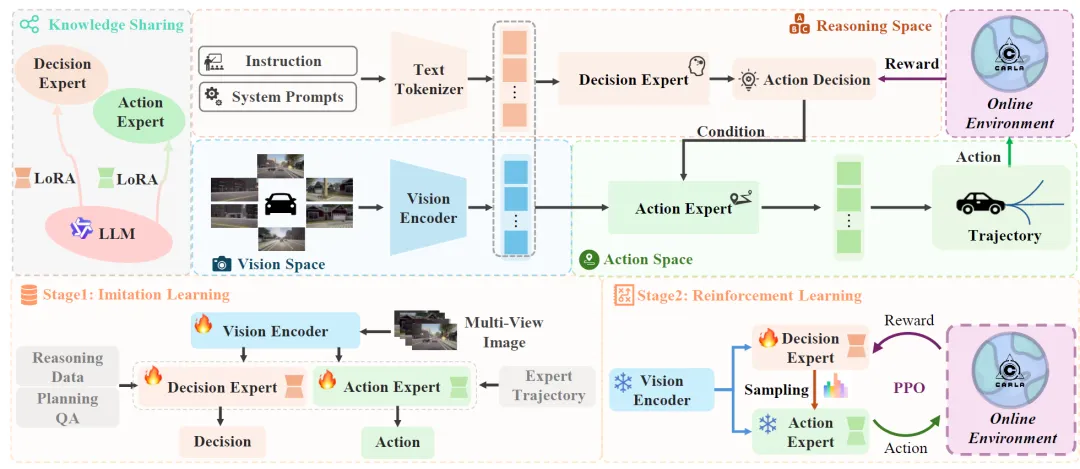
图 2:MindDrive整体架构与训练流程。左侧为第一阶段模仿学习(IL),建立元动作与轨迹的对应关系;右侧为第二阶段在线强化学习(RL),通过动作奖励直接增强模型的推理能力。两个Expert共享基础LLM,仅LoRA参数不同。决策专家(Decision Expert)接收多视图图像和导航指令,进行高层场景推理,输出"元动作"(meta-action)。具体而言,作者将车辆控制分解为纵向(7种速度元动作:加速、减速、急减速、保持低速、保持中速、保持高速、停止)和横向(6种路径元动作:左转、右转、左变道、右变道、直行、跟车道),共42种离散组合。每个时间步,决策专家从这42种选项中做出选择。
行动专家(Action Expert)接收同样的场景信息,但输出的是连续轨迹。它利用VAE+GRU解码器,将视觉-语言表征转化为具体的速度轨迹(6个2Hz采样点,覆盖未来3秒)和路径轨迹(20个1米间隔点,定义20米路径)。关键在于,两个专家通过"元动作token"建立了一一映射关系——决策专家输出什么指令,行动专家就生成对应的轨迹。
2. 第一阶段(IL):建立语言-动作映射
在RL之前,MindDrive先通过IL阶段打下基础。作者使用Qwen2VL-72B生成驾驶推理数据,经人工审查后形成标准化的planning QA对(共收集234,769条样本)。IL训练使决策专家学会根据场景输出正确的元动作,同时行动专家学会生成类人、合理、高质量的候选轨迹。
这一步至关重要:IL提供的不仅是基础驾驶能力,更重要的是为后续RL大幅缩小了探索空间。RL不再需要在无穷大的连续轨迹空间中盲目搜索,只需从已有的高质量轨迹候选中选择最优者——探索效率由此大幅提升。
3. 第二阶段(RL):用动作奖励优化高层推理
这是MindDrive最核心的创新。在线RL的本质是让模型亲自在CARLA仿真器中驾驶,从每一次成功和失败中学习。
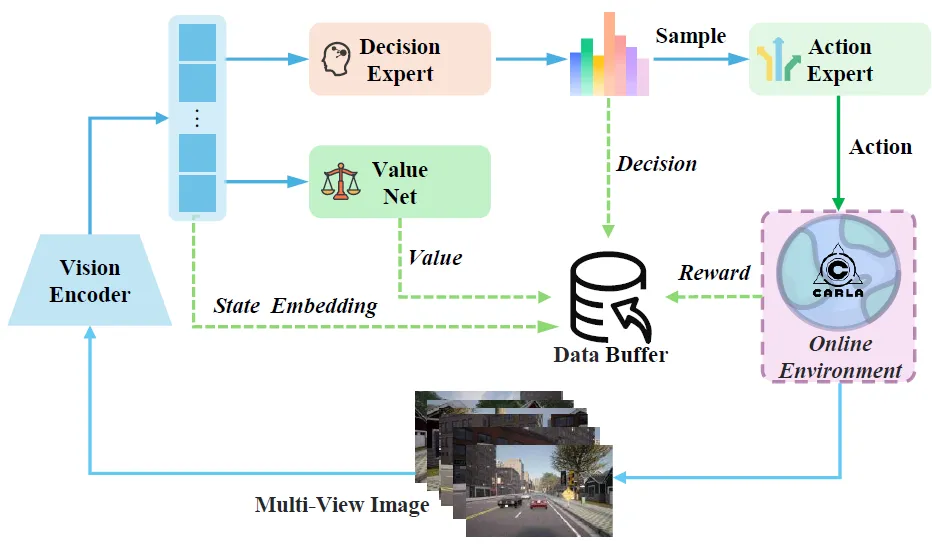
图 3:在线强化学习框架。多视图图像经Vision Encoder编码为状态嵌入,决策专家采样元动作并由行动专家映射为轨迹执行。环境返回奖励信号后,价值网络估计状态价值,数据存入buffer用于PPO训练。如图3所示,具体流程包含四个环节:
数据收集: 部署24个并行CARLA实例,每个实例独立运行驾驶任务。模型在每个决策步根据当前场景采样元动作,由行动专家转化为轨迹执行。
稀疏奖励: 采用极简的奖励设计——到达终点+1,触发惩罚事件(碰撞、闯红灯、偏离路线、无视停止标志)-1,其他情况0。没有任何复杂的奖励工程,模型通过试错自动发现有效策略。
价值估计: 价值网络与LLM共享权重,仅最后一层替换为MLP来预测状态价值。通过TD方法和GAE(广义优势估计)计算优势函数。
策略更新: 使用PPO算法更新决策专家的策略,同时引入KL散度正则化项约束策略更新幅度,防止灾难性遗忘。
一个精妙的设计是状态表示压缩:RL训练不直接使用多视图图像,而是使用IL阶段预计算的视觉编码器输出作为状态嵌入。这避免了重复计算,大幅提升了训练效率,使得大批量PPO训练成为可能。
4. 策略正则化:为什么"不忘"是RL的关键
在线RL的一个经典陷阱是灾难性遗忘:策略在学习新经验时可能覆盖掉IL阶段建立的基础场景理解能力。MindDrive通过KL散度正则化来约束策略更新——要求当前策略的输出分布不要偏离参考策略(IL阶段模型)太远。
消融实验验证了这一点:使用KL正则化的PPO相比Vanilla PPO提升了3.31 DS和8.36% SR,相比仅用熵正则化的方案也有2.33 DS和5.85% SR的提升。熵正则化虽然鼓励探索,但过度的策略随机性反而不利于目标导向的驾驶任务。
四、实验与结果
1. 实验设置
MindDrive基于Bench2Drive数据集和CARLA仿真器进行训练和评测。IL阶段使用1000个clips(950训练/50验证),RL阶段在44条模型可通过采样完成的路线(每条5次rollout)上进行在线训练。闭环评测包含220条短路线,覆盖44种交互场景。训练使用32张NVIDIA A800 GPU(80GB),RL数据收集使用24个并行CARLA实例,约24小时完成。
评估指标包括:Driving Score(DS)——路线完成度扣除违规罚分;Success Rate(SR)——按时完成路线的比例;以及五项细粒度Multi-Ability能力指标:合流(Merging)、超车(Overtaking)、紧急制动(Emergency Brake)、让行(Give Way)、交通标志(Traffic Sign)。
2. 主要结果:小模型,大能量
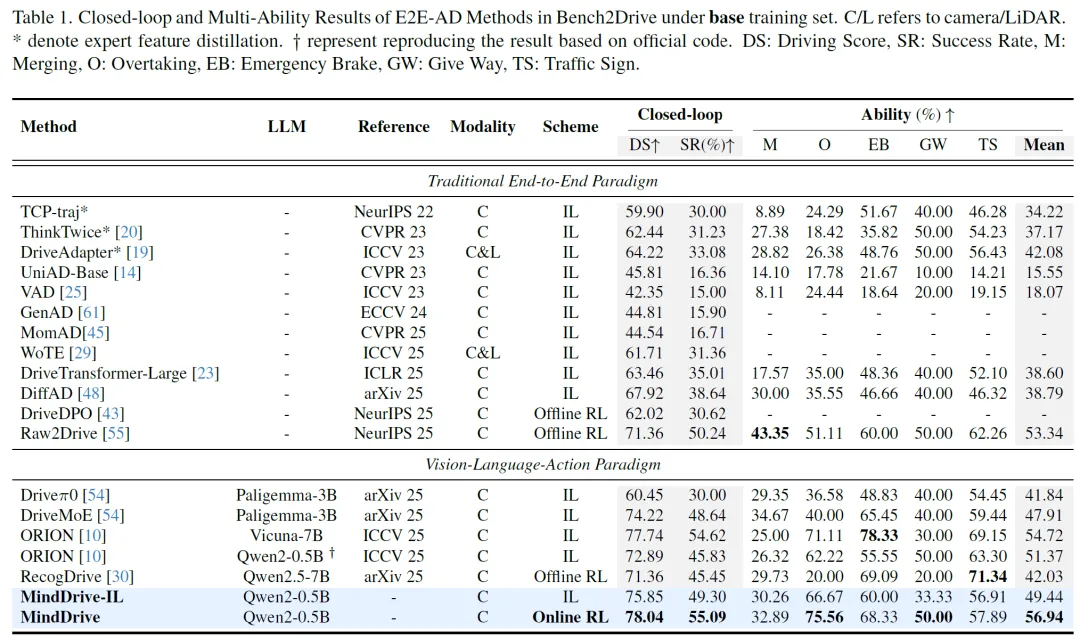
表 1:Bench2Drive闭环评测与Multi-Ability结果。C/L表示相机/激光雷达,*表示专家特征蒸馏。DS:Driving Score,SR:Success Rate,各项能力值越高越好。MindDrive以Qwen2-0.5B这样的轻量级模型,取得了78.04 DS和55.09% SR的成绩(见表1)。在传统端到端方法中,MindDrive超越最新SOTA IL模型DiffAD 10.12 DS和16.45% SR,超出离线RL方法Raw2Drive 6.68 DS和4.85% SR。在VLA范式内,MindDrive与使用Vicuna-7B(14倍参数)的ORION表现相当,超越基于Paligemma-3B的DriveMoE 3.82 DS和6.45% SR。
更重要的是与自身IL基线的对比:MindDrive-IL已取得75.85 DS / 49.30% SR的强劲表现,但在线RL进一步将DS提升至78.04(+2.19),SR提升至55.09%(+5.79个百分点)。在五项细粒度能力中,超车从66.67%跃升至75.56%(+8.89个百分点),让行从33.33%提升至50.00%(+16.67个百分点),平均能力从49.44%提升至56.94%。
与离线RL方法RecogDrive的对比最能说明问题:MindDrive超越其6.68 DS和9.64% SR,平均能力高出14.91%。这说明真正的环境交互带来的收益,是离线奖励工程无法替代的。
3. 消融实验:惩罚事件、Rollout轮次与正则化
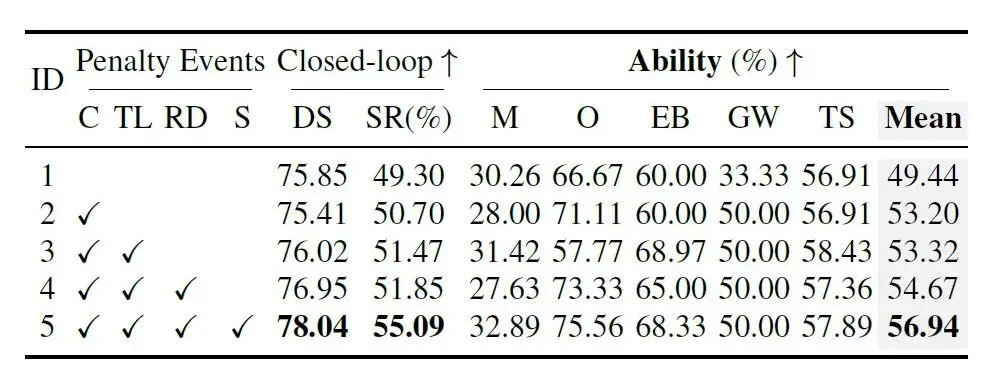
表 2:惩罚事件消融实验。C:碰撞,TL:交通灯,RD:路线偏离,S:停止标志。逐步引入四种惩罚后,DS、SR和各项能力指标持续提升。作者通过逐步引入四种惩罚事件(碰撞→交通灯→路线偏离→停止标志),验证了"试错学习"的有效性(见表2)。每增加一种惩罚,模型表现稳步提升——从IL基线的75.85 DS / 49.30% SR,逐步提升至完整RL的78.04 DS / 55.09% SR。最引人注目的是停止标志惩罚带来了5.26%的合流能力提升,因为它与"停止"元动作强相关,策略学习效率极高。无需复杂的奖励工程,MindDrive就能自主从失败中发现有效驾驶策略。
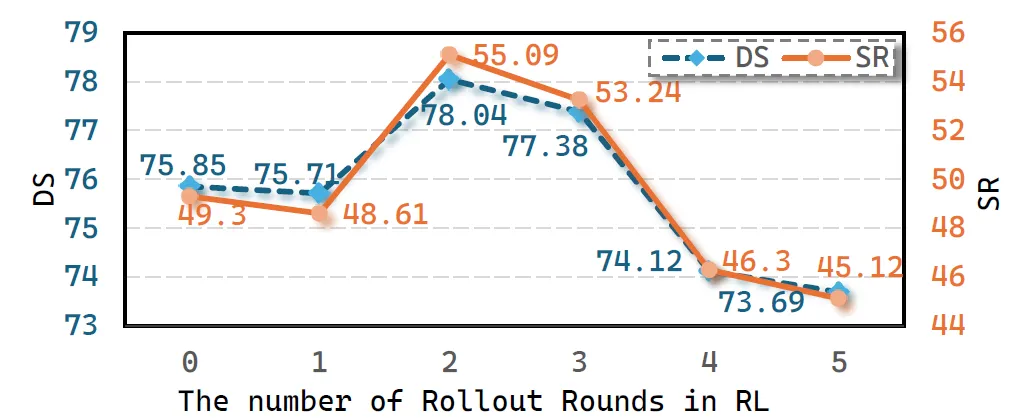
图 4:RL Rollout轮次消融实验。2轮rollout达到最优(78.04 DS),5轮后性能显著下降(73.69 DS),揭示了探索效率与灾难性遗忘之间的权衡。Rollout轮次的消融揭示了RL中的关键平衡(见图4):2轮rollout带来最优性能,但5轮rollout后DS从78.04跌至73.69,SR从55.09%降至45.12%。原因很直观:过度rollout导致策略过拟合近期经验,遗忘了IL阶段学到的场景理解能力。这个发现为后续工作提供了重要参考——在线RL的训练轮次需要仔细调节,而非"越多越好"。
控制方式的消融同样值得关注:使用传统导航指令仅取得68.11 DS,而LLM生成的元动作(IL)达到75.85 DS,经RL优化后进一步提升至78.04 DS。这说明VLM驱动的语义级控制相比传统的导航指令格式,能更有效地应对复杂交通场景。此外,双专家架构被证明是必要的——若用单一专家同时负责推理和轨迹生成,在稀疏奖励下会出现灾难性遗忘和轨迹质量退化。
4. 定性分析:从犹豫到果断
图 5:IL与RL版本MindDrive的定性对比。绿色和蓝色分别表示预测的速度和路径元动作,红色表示碰撞。RL训练后,模型在变道时机选择上更果断,驾驶行为更安全。图5的定性对比非常直观。IL版本的MindDrive在标准驾驶场景中表现不错,但在需要复杂决策的动态交互场景中往往犹豫不决——比如不知道什么时候该变道。经过RL训练后,模型学会了选择更果断的元动作,变道时机更精准,整体驾驶行为更安全、更富决策性。
论文还展示了模型的场景理解能力——MindDrive不仅能输出驾驶动作,还能解释自己的决策逻辑:"前方12.56米处有一辆红色轿车以相似速度行驶,对向车道的车速度更快,此时不建议变道。"这种语义级推理能力在RL过程中得到保留而非退化,说明在线RL并未损害模型的认知功能——它只是让模型在面对相似场景时,做出更优的选择。
五、局限与展望
MindDrive的意义不仅在于一个具体的性能数字。它首次证明了在线强化学习可以有效训练自动驾驶VLA模型,为这一方向打开了新的可能性。
过去,自动驾驶领域的RL大多停留在离线阶段——对着固定数据集做偏好优化,模型始终没有机会真正"上路试错"。MindDrive展示了在线交互的独特价值:通过自主探索失败场景、从惩罚信号中学习因果关联,策略的鲁棒性和交互能力都得到了有意义的提升。尤其值得关注的是,RL带来的性能增长出现在超车和让行这类需要"主动决策"的场景中——这恰恰是模仿学习最容易发生因果混淆的地方。
当然,这项工作也存在局限。评测局限在CARLA仿真器中,距离真实道路环境还有距离;同步多个CARLA仿真器的技术挑战限制了GRPO等更先进RL算法的应用;当前使用稀疏奖励,更丰富的奖励信号(如舒适度、效率)可能是下一步的方向。从另一个角度看,这些局限正指向了未来的研究空间:如何将仿真器中的试错经验泛化到真实世界?如何设计更高效的探索策略?如何处理仿真与现实的分布差异?
MindDrive的价值已不仅在于"第一个吃螃蟹"——它提出的双专家解耦架构、语言空间RL范式以及稀疏奖励下的稳定训练方案,为后续工作提供了清晰的参考框架。当自动驾驶模型学会从错误中成长,"驾驶"就不再是模仿,而是一种经验驱动的智能行为。
论文信息
MindDrive: A Vision-Language-Action Model for Autonomous Driving via Online Reinforcement Learning
Haoyu Fu, Diankun Zhang, Zongchuang Zhao, Jianfeng Cui, Hongwei Xie, Bing Wang, Guang Chen, Dingkang Liang, Xiang Bai
论文地址:arXiv:2512.13636 | 项目主页:https://xiaomi-mlab.github.io/MindDrive/