自动驾驶的“眼睛”——环境感知系统,正变得越来越强大。但长期以来,纯视觉方案始终面临一个棘手的难题:如何从2D图像中,既准确又高效地复原出带真实物理尺寸(即“度量尺度”)的3D世界? 许多方案都严重依赖精确的相机参数(内外参),一旦更换3车型或摄像头,模型就可能“水土不服”,需要重新标定和适配,费时费力。
最近,来自清华大学和小米汽车等机构的研究者们,带来了一项颇具突破性的工作——DVGT (Driving Visual Geometry Transformer)。它像一个经验丰富的老司机,能仅凭多路摄像头记录的“行车录像”,就直接在脑中构建出一个真实大小、无需后期校准的3D世界地图。

DVGT的命名直截了当,意为“为自动驾驶设计的视觉几何Transformer”。它的核心贡献在于,提出了一种能从无位姿、无标定参数的多视角图像序列中,直接端到端预测出带有度量尺度(metric-scaled)的全局3D点图和车辆自身位姿的框架。这意味着,DVGT向着“即插即用”的通用3D感知迈出了重要一步,尤其在离线数据自动化生产(Auto-labeling)和仿真场景构建领域具有巨大潜力。

- 论文标题:DVGT: Driving Visual Geometry Transformer
- 论文地址:https://arxiv.org/abs/2512.16919
- 代码仓库:https://github.com/wzzheng/DVGT
- 项目主页:https://wzzheng.net/DVGT
“无米之炊”:DVGT如何摆脱几何先验?
传统的多视角3D感知方法,通常遵循一个“标准流程”:首先利用已知的相机内外参数,将2D图像特征“投影”或“提拉”(Lift)到一个三维空间(如BEV视空间)。这个过程强依赖于 Lift-Splat-Shoot 或空间变换器(View Transformer)等模块,相机参数一旦不准,模型性能便会大打折扣。
DVGT则另辟蹊径,它的设计哲学是“去几何先验化”。整个模型在结构上完全不包含任何与相机参数、2D到3D投影相关的显式设计。
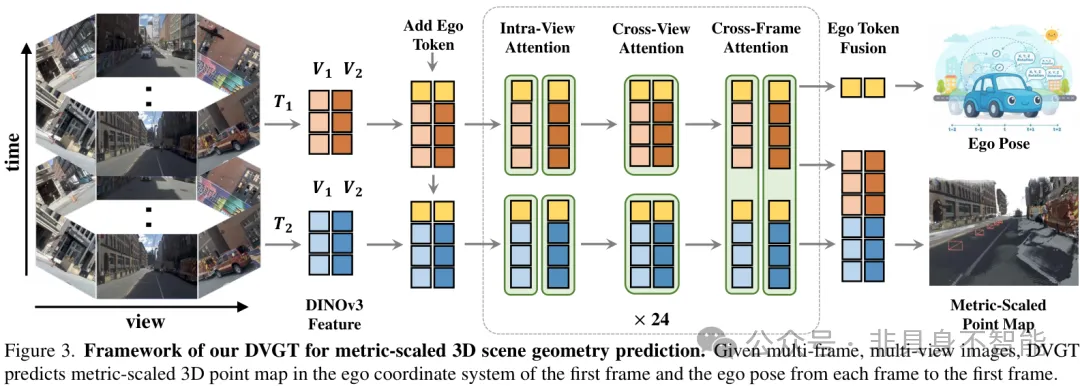
如上图所示,DVGT的流程可以概括为:
- 输入:一个连续时间段内,车辆周围多个摄像头拍摄的图像序列(例如,16帧 x 8视角)。重要的是,这些图像不需要提供精确的相机位姿和内外参数。
- 特征提取(大模型赋能):使用强大的预训练视觉基础模型(如 DINOv3)作为骨干网络。正是得益于Foundation Model强大的语义理解和密集特征表达能力,模型才有可能在缺乏几何约束的情况下“隐式”学会3D结构。
- 核心处理(几何Transformer):这是DVGT的“大脑”。它由一系列精心设计的注意力模块堆叠而成,负责理解时空几何关系。
- 全局3D点图:注意,这里的“全局”指的是以输入序列第一帧为中心的局部统一坐标系(Ego-coordinate of the first frame),而非绝对地理坐标。
- 自车位姿(Ego-Pose):每一帧相对于第一帧的车辆运动轨迹。
独创的分解式时空注意力
完全抛弃几何先验,意味着模型必须拥有更强的从数据中自主学习空间关系的能力。如果让所有图像的所有特征 Token 之间都进行全局注意力计算,计算量将是天文数字。
为此,DVGT提出了一种高效的分解式时空注意力(Factorized Spatial-Temporal Attention)机制。它将原本复杂的全局信息交互,拆解为三个目标明确的步骤:
- 跨视空间注意力:理解同一时刻不同摄像头(前、后、侧)的空间一致性。
这种分解设计显著降低了计算复杂度,使得在有限显存下处理长序列视频成为可能。
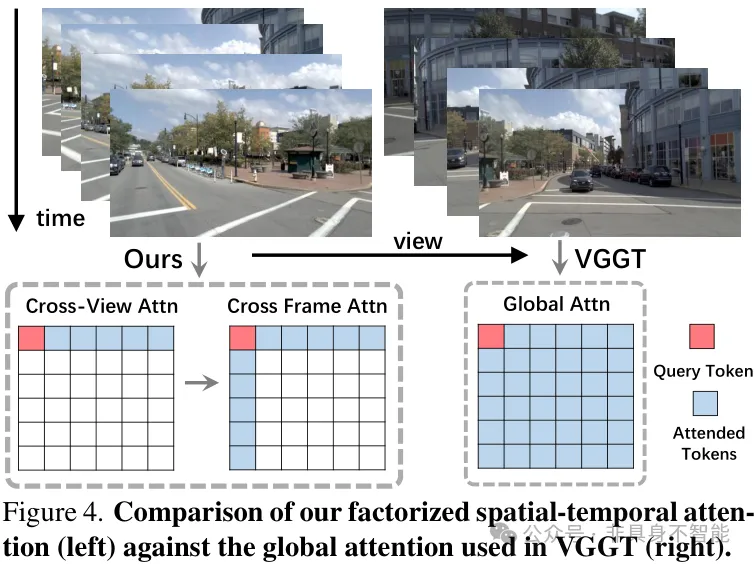
如上图所示,这种分解方式(左)相比于全局注意力(右),大幅降低了计算复杂度,使得模型在保持强大感知能力的同时,也兼顾了效率。
实验效果:精度与效率的权衡
为了训练DVGT,研究团队构建了一个超大规模的混合驾驶数据集,整合了nuScenes, OpenScene, Waymo, KITTI, 和DDAD五大公开数据集。
3D重建:精度大幅领先,免去后处理
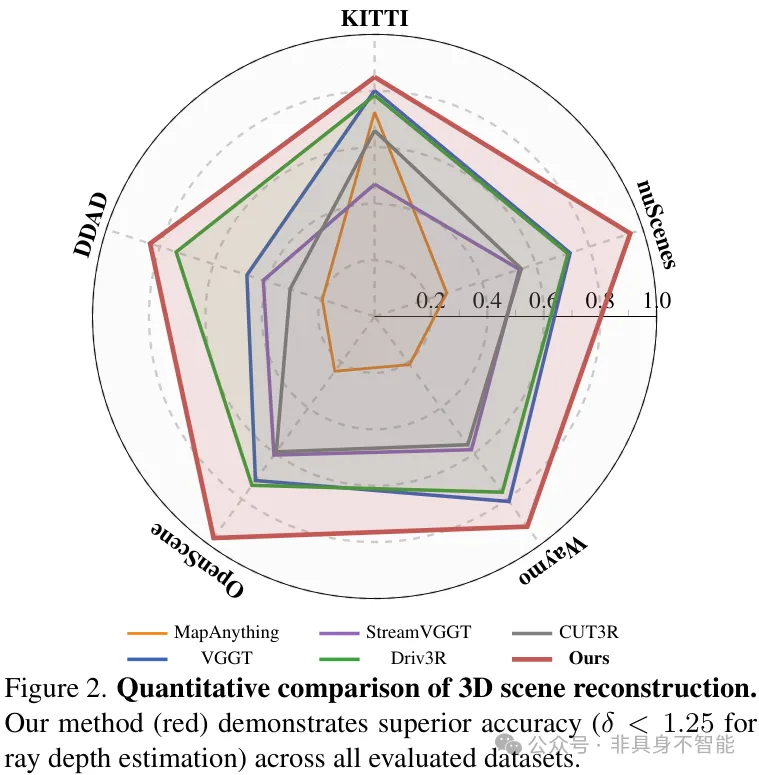
在3D场景重建精度上(上图雷达图),DVGT(红色区域)在所有五个测试数据集上均全面包围并超越了其他主流方法(如VGGT, CUT3R)。
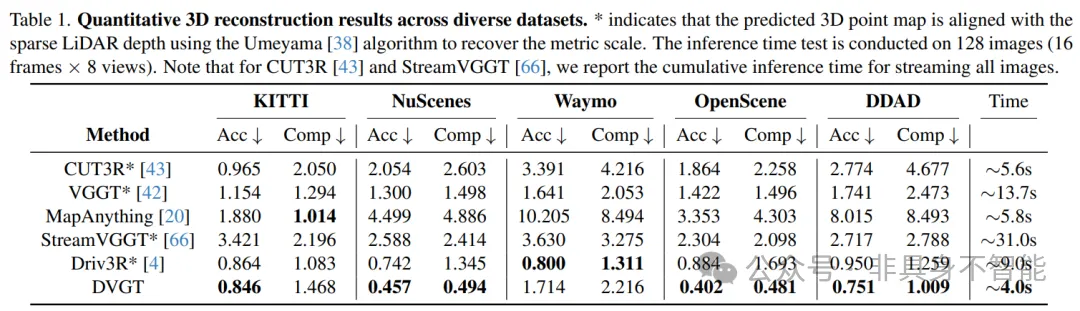
关键突破在于:表格中带有 * 号的模型(如VGGT),其输出结果通常是无尺度的,必须经过一个“后处理”步骤——与稀疏的激光雷达点云进行对齐(Scale Alignment)才能使用。而DVGT直接输出带有真实物理尺度(米)的点云,完全省去了对齐外部传感器的步骤。
关于“速度”的客观解读
论文数据显示,DVGT处理128张图片(16帧 x 8视角)的推理时间约为 4.0秒。
- 对于车载端:这个速度(约0.25FPS)距离实时在线感知(通常要求10Hz以上,即<0.1s)仍有较大距离。
- 对于离线端:这却是一个巨大的胜利。相比于基于NeRF或3D Gaussian Splatting的传统重建优化方法(往往需要数分钟甚至数小时),DVGT将重建速度提升了几个数量级。这意味着它非常适合用于离线高精地图构建、Corner Case自动挖掘以及大规模数据的自动标注。

自车位姿估计
除了场景重建,DVGT还能同时精准地估计车辆自身的运动轨迹。
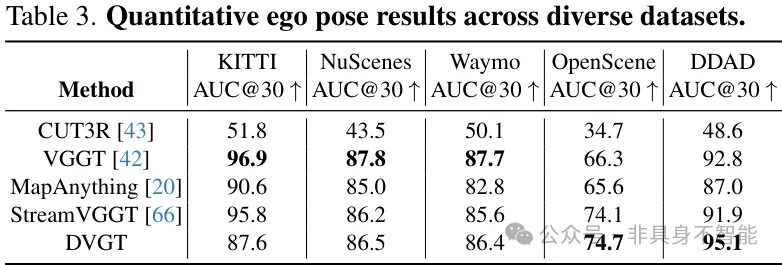
结果显示,DVGT在OpenScene和DDAD数据集上的位姿估计性能最优,在nuScenes和Waymo上也达到了与SOTA方法相当的水平,证明了其作为一个综合视觉几何模型的强大实力。
写在最后
DVGT的提出,为自动驾驶的纯视觉感知路线提供了一个非常有力的新思路。
目前该工作的代码已经开源,对于从事3D重建、SLAM以及自动驾驶数据闭环的朋友来说,值得一试。
- https://github.com/wzzheng/DVGT




