深度解读地平线对BEVFormer的自动驾驶融合优化方案
- 2026-06-22 00:03:40
点击下方卡片,关注「3DCV」公众号选择星标,干货第一时间送达
来源:地平线开发者
「3D视觉从入门到精通」知识星球(点开有惊喜) !星球内新增20多门3D视觉系统课程、入门环境配置教程、多场顶会直播、顶会论文最新解读、3D视觉算法源码、求职招聘等。想要入门3D视觉、做项目、搞科研,欢迎扫码加入!
在自动驾驶领域,BEV 是一种从上方看对象或场景的视角,通过多个不同视场的传感器融合成 BEV 特征,可以提供车辆周围环境的完整视图,供下游任务使用,例如障碍物检测,路径规划等。
基于 BEV 的环境感知目前主要是有两种技术路线,一种是以 petr 为代表的 sparse bev 方法,它的主要思路是通过 3D 位置编码和 2D 的特征直接生成融合特征,再用基于 transformer 的 decoder 实现环境感知,这个过程不需要显式地生成 Dense Bev 特征; 另一种是以 bevformer 为代表的 dense bev 方法,该方法利用内外参信息将 2D 特征融合到一个 BEV 特征,再用 BEV 特征来进行后续的感知或规划任务。基于 Dense Bev 的方法,可以很方便地实现多传感器融合和多任务预测,因此在自动驾驶领域被广泛应用。

BEVFormer 为参考算法 V1.0 版本,BEVFormer-OPT 为优化后的参考算法 V2.0 版本(地平线 3D 目标检测 Bevformer 参考算法-V2.0);
BEVFormer-OPT 使用了 Dense Bev 的优化方案;
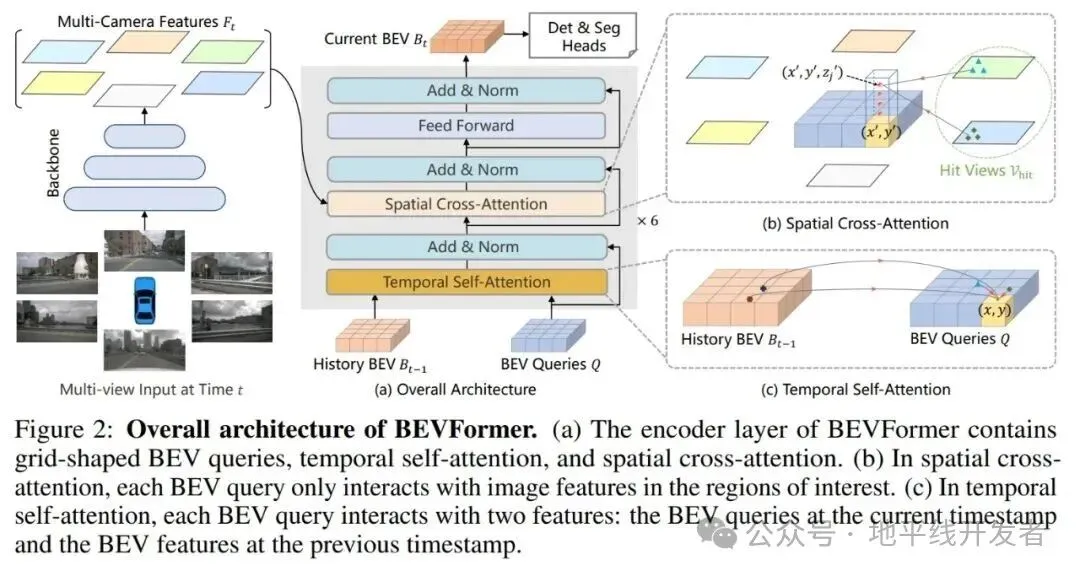
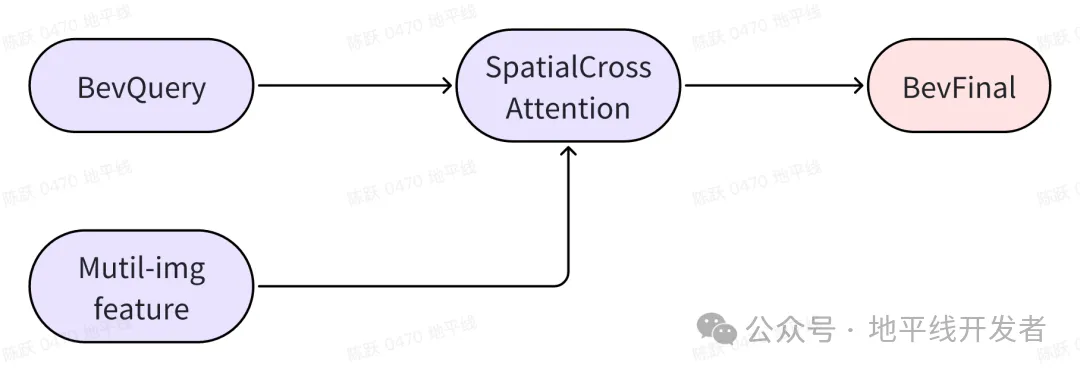
3.2.1 使用 BevMask
在优化方案中,我们对内外参生成 BevMask 的原理做了详细的分析,发现:
当相机传感器位置固定时,内外参转换矩阵即固定,轻微抖动对 BevMask 影响不大。 从 BEV voxel 的角度来看,中心点到 multi camera 的映射是稀疏的,在 BevFormer 开源的代码和模型中,默认利用了这个特性,加速计算而不会带来任何精度损失(也就是上面说的 bev_mask) 从 BEV pillar 的角度来看,通常每个 pillar 只会映射到 1-2 个 camera,如上图右上角所示。
利用到上面的几个特性我们可以减少空间融合模块的复杂度,但需要引入一对 gather/scatter 操作,以及相关的 index 计算。即先通过 gather 将 bev 空间上的有效点取出来,计算完空间特征融合后,再用 scatter 将其还原到 Bev 空间对应的位置,然后根据每个 bevpillar 的有效点数来算 Bev 空间每个点的均值即可。
整体框架如下图所示:
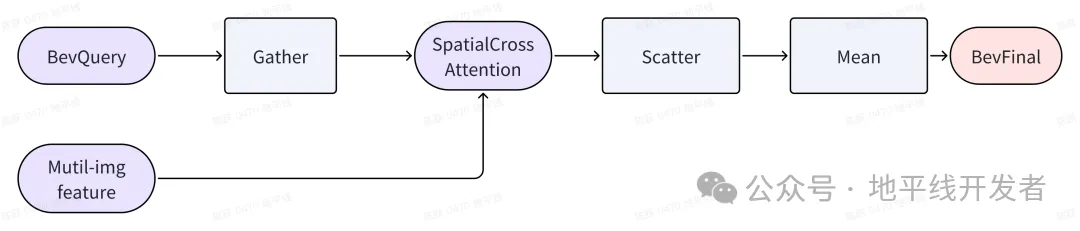
为了能编译成静态模型,有 2 个额外需要关注的设置:
Bev 空间映射到每个 camera 的最大点数。这个可以根据内外参计算得到,但为了应对一些抖动情况,可以适当放开,在 Nuscenes 数据集上,50*50 大小的 Bevsize 下,我们设置为 20*32。 这个数字直观理解就是,最大视场的相机在 Bev 空间覆盖的区域大小。 每个 BEV pillar 映射到的最大的 camera 数。目前是一个静态设置的最大值,可以根据数据统计得到,在 Nuscenes 数据集中,我们设定为 2, 这个数字直观理解就是有视野重叠的最大 camera 数。
代码均在算法包位置:
hat/models/task_modules/bevformer/attention.py
# 对输入的Bevquery和reference_points取出有效点def rebatch_attention_inputs( self, query: Tensor, queries_rebatch_grid: Tensor, reference_points_rebatch: Tensor,) -> Tuple[Tensor, Tensor]: """Rebatch the attention inputs.""" bs = query.shape[0] ... return queries_rebatch, reference_points_rebatch # 将SpatialCrossAttention模块的输出映射会Bevfeat上,并求均值def restore_outputs( self, restore_bev_grid: Tensor, queries_out: Tensor, counts: Tensor, bs: int, queries_rebatch_grid: Tensor,): """Restore outputs to bev feature.""" queries_out = queries_out.reshape( bs, self.num_cams, self.embed_dims, -1 ) ... return slots
3.2.2 使用 Gridsample 高效实现 Gather 和 Scatter
gather/scatter 这一对操作在 BPU 上不是很友好,通过分析这对操作的 index 我们发现可以换成 BPU 更友好的方式,即使用 Gridsample 来实现这一对操作。Index 只受 camera 内外参的影响,而往往内外参的变化是非常低频的,因此,我们可以把 index 生成的逻辑放在前处理,按需触发计算,再把生成好的 index 转换为对应 Gridsample 需要的 grid 作为模型输入给到模型,供 Gridsample 算子直接使用,代码均在算法包位置:
1. 根据 Gather 的 Index 计算 Gridsample 的 Grid:
bev_mask = bev_mask.permute(2, 1, 3, 0, 4).squeeze(-1)max_len = self.virtual_bev_h * self.virtual_bev_wqueries_rebatch_grid = reference_points_cam.new_zeros( [B * self.numcam, self.virtual_bev_h, self.virtual_bev_w, 2])...reference_points_rebatch = ( reference_points_cam.flatten(-2) .permute(1, 0, 3, 2) .flatten(0, 1) .reshape(B * self.numcam, D * 2, self.bev_h, self.bev_w))
bev_mask_ori = bev_mask.clone()bev_mask = bev_mask.permute(1, 0, 2, 3)restore_bev_grid = ( reference_points_cam.new_zeros( B, self.max_camoverlap_num * self.bev_h, self.bev_w, 2 ) - 1.5)...restore_bev_grid = restore_bev_grid * 2 - 1bev_pillar_counts = bev_mask_ori.sum(-1) > 0bev_pillar_counts = bev_pillar_counts.permute(1, 2, 0).sum(-1)bev_pillar_counts = torch.clamp(bev_pillar_counts, min=1.0)
引入 BevMask, 可以大幅度降低空间融合模块的计算量和 IO; 根据模型特征,使用 BPU 友好的 OP。
3D视觉方向论文辅导来啦!可辅导SCI期刊、CCF会议、本硕博毕设、核心期刊等
3D视觉硬件

3D视觉学习圈子
「3D视觉从入门到精通」知识星球(点开有惊喜) !星球内新增20多门3D视觉系统课程、入门环境配置教程、多场顶会直播、顶会论文最新解读、3D视觉算法源码、求职招聘等。想要入门3D视觉、做项目、搞科研,欢迎扫码加入!

3D视觉全栈学习课程:www.3dcver.com

3D视觉交流群成立啦

随机文章
-
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
- 【每日一安全】(电动车安全)凌晨3点多,户外停车棚突然起火
- 中欧电动车谈判创造性“握手”,关税警报解除,全球产业链得救
- 不用换电池!冬天电动车多跑25公里的秘诀,老车主都藏着
- 2026年1月起,电动车有新政策,两轮、三轮、四轮都在内,车主注意
- 电动车事故后被认定为“机动车”,保险拒赔怎么办?
- 绿源电动车
- 加拿大行业协会:卡尼政府调整中国产电动汽车进口政策“正当其时”
- 加拿大总理访华、拿下近5万辆电动车订单!加拿大转投中国、期待扭转加国境内颓势
- 2025年中大型豪华轿车销量排行榜,奔驰E级只第3,小米SU7是真强!
- 30万预算不买轿车买什么?老司机掏心窝子推荐这台“瓦罐”
