辞旧迎新,知识续航!「龙哥读论文」陪你跨年,知识星球会员优惠券限时限量放送!🐉 「龙哥读论文」知识星球:让你看论文像刷视频一样简单!公众号每日8篇拆解不够看?星球无上限更AI领域论文、资讯、招聘、招博、开源代码,一站式干货,每日2分钟刷完即赚!👇扫码加入「龙哥读论文」知识星球,领取优惠,前沿干货、实用资源一站式拿捏~

龙哥推荐理由:
自动驾驶仿真一直是个“老大难”:相机和激光雷达(LiDAR)的渲染模型各玩各的,逼真度和效率难以兼得。这篇来自莫斯科大学的新作XSIM,直接来了个“大一统”!它巧妙解决了球形卷帘快门LiDAR的渲染顽疾,还让相机和LiDAR共享一个高质量的场景表示。实验数据全面领先,代码也已开源,对于自动驾驶仿真和3D重建领域的研究者和工程师来说,实用性和启发性都拉满了!
原论文信息如下:
论文标题:
Unified Sensor Simulation for Autonomous Driving
发表日期:
2026年02月
发表单位:
Lomonosov Moscow State University (莫斯科罗蒙诺索夫国立大学)
原文链接:
https://arxiv.org/pdf/2602.05617v1.pdf
开源代码链接:
https://github.com/whesense/XSIM
试想一下,你正在研发自动驾驶系统,需要在虚拟世界里让汽车“预演”无数次车祸边缘的惊险操作。这个虚拟世界的基石,就是传感器仿真——你得精准模拟出车上的摄像头拍到的画面,以及激光雷达(LiDAR)扫描出的3D点云。问题来了:相机仿真要的是“逼真”,讲究光影、反射;雷达仿真要的是“精确”,一毫米的误差可能就让车撞上。以前,这俩“兄弟”的仿真模型基本是各玩各的,用一个模型就难以兼顾对方的需求。
这篇来自莫斯科大学团队的论文《Unified Sensor Simulation for Autonomous Driving》提出的XSIM框架,就像一位“全能翻译官”,它用一套统一的“语言”(基于3DGUT的高斯泼溅),让相机和激光雷达的仿真首次在高质量层面实现了和谐统一。更酷的是,它还解决了一个困扰业界许久的“球形卷帘快门”渲染顽疾。打破仿真壁垒:XSIM如何统一自动驾驶的“眼睛”和“雷达”?
在深入XSIM的黑科技之前,我们先聊聊它立足的基石——3D高斯泼溅(3D Gaussian Splatting, 3DGS)。你可以把3DGS想象成用一堆“有弹性的彩色小棉花糖”来填充和表示整个3D场景。每个“棉花糖”(高斯粒子)在3D空间中有自己的位置、大小、旋转、颜色和不透明度。渲染时,把这些“棉花糖”按照一定规则投影到2D屏幕上并混合起来,就能得到一张图片。
传统3DGS在投影这些粒子时,用的是线性近似,这对于普通针孔相机还好,但遇到复杂的相机畸变或者卷帘快门(Rolling Shutter)时就捉襟见肘了。卷帘快门是啥?简单说,就是传感器不是瞬间拍完整张照片,而是一行一行从上到下或从左到右扫描。在高速运动的自动驾驶场景中,这种时间差会导致图像扭曲(比如垂直的楼拍歪了)。
这时候,XSIM选择的底层技术——3DGUT(3D Gaussian Unscented Transform, 3D高斯无迹变换泼溅)就登场了。3DGUT的核心是用无迹变换(Unscented Transform, UT)来投影高斯粒子。UT可以理解为一种更聪明的采样方式:它从一个高斯分布(3D“棉花糖”)中选取几个有代表性的点(Sigma点),分别用复杂的相机模型去投影,然后用这些投影后的点来反推出一个2D高斯形状。这就像你想知道一个气球投在扭曲哈哈镜上的样子,与其猜,不如在气球表面选几个点,分别去照镜子,再把这些点的位置连起来,就能更准确地知道气球的投影形状了。
因此,3DGUT天生就擅长处理非线性的相机模型,包括带畸变和卷帘快门的相机。XSIM正是站在3DGUT的肩膀上,提出了一个统一的、广义的卷帘快门建模框架。它不再为相机和LiDAR分别写两套渲染代码,而是用同一套数学语言来描述两者在扫描成像过程中的时间演变。这使得用一套模型同时高质量地渲染RGB图像和LiDAR点云成为可能。
核心难题:当高斯泼溅遇上球形卷帘快门
虽然3DGUT很强,但把它用在自动驾驶最关键的传感器之一——旋转式激光雷达(LiDAR)上时,一个隐藏的“魔鬼细节”就暴露了。
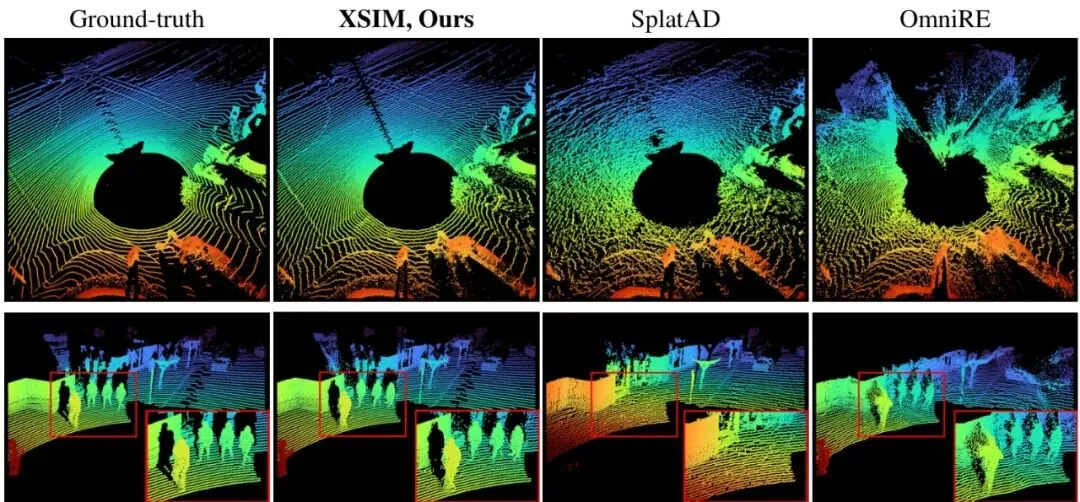
LiDAR可以看作一个球形卷帘快门相机。它一边旋转,一边发射激光束,记录返回的时间和角度,生成一幅360度的“距离图像”。这里的“方位角(Azimuth)”是一个从-π到π(或0到2π)周期性变化的值。问题就出在这个周期性和卷帘快门的时间不连续性上。图4:发生在方位角边界附近的LiDAR不连续性。 a) 即使传感器静止并恰好覆盖360度,由于卷帘快门造成的时间不连续性也可能导致物体被观测两次。 b) 自车运动与卷帘快门结合导致空间不连续性。
想象一个场景(对应图4a):一辆车停在旋转的LiDAR旁边。LiDAR扫描一周,车头部分在扫描快结束时被看到,车尾部分在扫描刚开始时被看到。由于卷帘快门,扫描开始和结束的“时间”相差了整整一个扫描周期,导致同一辆车在距离图像上被记录了两次!如果车在移动(图4b),情况就更复杂了,会产生空间上的不连续。
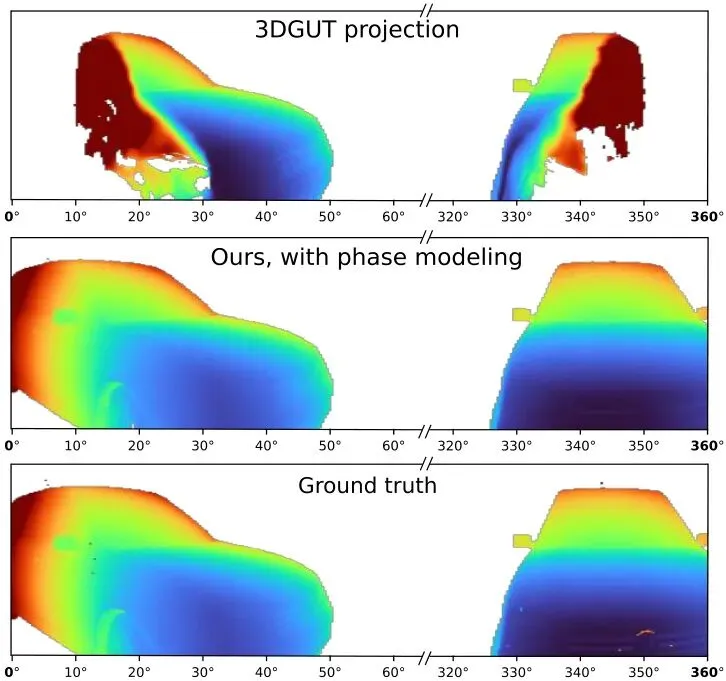
现在,一个横跨方位角边界(比如-π/π附近)的3D高斯“棉花糖”要被投影了。它的Sigma点可能会落在不同的方位角周期里(比如有的点在周期k=0,有的在k=+1)。标准的UT会假设投影结果是一个单峰的2D高斯(一个“团”)。但实际上,由于上述的时间/空间不连续性,这个3D粒子可能被投影成两个完全分离的、形状不同的2D高斯(两个“团”)。图1:LiDAR渲染的合成示例。在靠近方位角不连续边界的区域,标准的3DGUT投影导致部分缺失和扭曲的距离图像渲染。我们的相位建模方法缓解了这个问题,并有效处理了因卷帘快门而被观测两次的表面。
图1这个合成例子清晰地展示了问题:标准3DGUT投影在边界处产生了缺失和严重的形状扭曲。而UT强行用单峰高斯去拟合一个双峰分布,就会产生一个又大又歪、完全失真的投影,导致后续的渲染(如深度排序、像素着色)全部出错。解题密钥:相位建模与双不透明度设计
面对这个“单峰”假设在多模态现实面前的崩溃,XSIM给出了两个优雅而关键的解决方案。
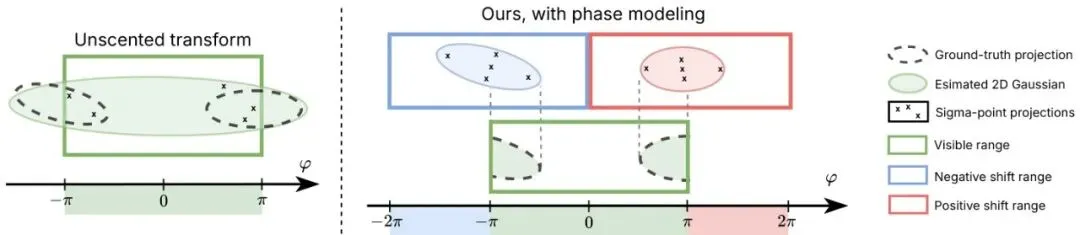
既然问题源于方位角的周期性和UT的单峰假设,那就主动拥抱多峰可能性。XSIM提出的相位建模(Phase Modeling)机制,核心思想是:显式地考虑高斯粒子可能出现在多个方位角周期(相位)的情况。图6:单个高斯粒子横跨滚动快门球形相机的方位角边界 φ=±π 时,会投影成两个独立的具有不同2D协方差矩阵的2D高斯。无迹变换提供了粒子投影的单峰后验近似,导致过大且形状错误的投影。我们的相位建模机制通过考虑从可见范围偏移 ±π 的两次额外投影,实现了双峰2D高斯投影。通过执行偏移半个周期的投影,我们处理了其Sigma点落入多个方位角周期的粒子。
具体怎么做呢?如图6所示,对于一个正在渲染的方位角区间(例如从-π到π),XSIM不仅计算粒子在“当前相位”(k=0)的投影,还会主动计算它在“相邻相位”(k=-1和k=+1)的投影。相当于问:“这个‘棉花糖’有没有可能因为时间不连续,在上一个扫描周期或下一个扫描周期也被看到?”
对于每一个相位,都独立地使用UT计算一组2D高斯锥形(用于后续光栅化分块)和深度值。最后,所有有效的投影(即确实有Sigma点落入该区间的投影)都会被传递到下一个渲染阶段。这样一来,一个3D高斯粒子在边界处就可能产生两个独立的、形状正确的2D投影,完美匹配了物理现实。这从根本上解决了边界处的投影错误,从而得到图1中右边那样完整、准确的LiDAR距离图像。
解决了投影的几何难题,还有一个“材质”层面的冲突需要调和。相机和LiDAR对世界的“看法”本质不同:
对于LiDAR(几何传感器):它测量的是精确的表面距离。理想情况下,一个表面应该由一个完全不透明(opaque)的高斯粒子来表示,这样射线一碰到它就停止,测得的深度才准确。
对于相机(外观传感器):要渲染出逼真的效果,如车窗玻璃的透射、车漆的高光反射,往往需要沿着一条视线排列多个半透明(semi-transparent)的高斯粒子来模拟复杂的光路和材质交互。
如果强迫所有高斯粒子在两种传感器下共享同一个不透明度,就会导致妥协:要么为了外观牺牲几何精度,要么为了几何牺牲外观质量。
XSIM的解决方案简单又直接:给每个3D高斯粒子配备两个独立的不透明度参数!一个是 σ_c 用于相机渲染,另一个是 σ_L 用于LiDAR渲染。在训练时,这两个参数被联合优化,同时用一个正则化损失 ℒ_opacity 让它们不至于相差太远,保持基本的物理一致性。图5:单独建模LiDAR不透明度(LO)解决了几何与颜色分布的失配,并提高了对于半透明表面和镜面反射的外观建模质量。
如图5所示,这个设计带来了显著的好处。对于车窗(半透明)和车漆(高光)区域,LiDAR可以“看到”一个坚实的不透明表面,获得准确的几何;而相机则可以利用多个半透明粒子渲染出丰富的反射和透射效果,画面更逼真。鱼与熊掌,终于可以兼得。
实验验证:多项指标全面领先,几何精度大幅提升
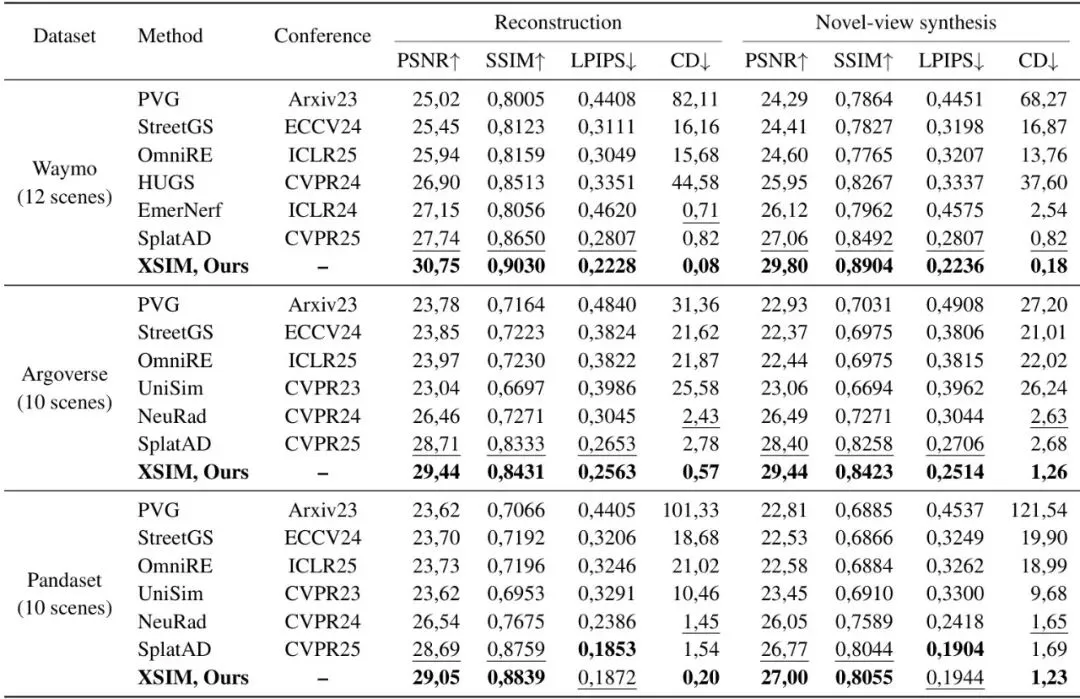
光说不练假把式。XSIM在Waymo、Argoverse 2和PandaSet这三个主流自动驾驶数据集上进行了全面测试,对比了包括SplatAD、OmniRE、NeuRAD等在内的多个近期SOTA方法。结果相当有说服力。表1:三个数据集上场景重建和新视角合成场景的定量结果。我们报告了RGB图像质量指标(PSNR, SSIM, LPIPS)和通过倒角距离(CD)测量的LiDAR重建精度。我们的框架在所有数据集和场景中都达到了最先进的性能,特别是在LiDAR渲染方面实现了误差的大幅降低。
图像质量(重建任务):PSNR高达30.75,比之前的SOTA(SplatAD)提升了近3个点;SSIM达到0.903,提升了约3.8%;衡量感知相似度的LPIPS也降低了20.6%。这是全面提升。
几何精度(LiDAR CD指标):这更是XSIM的杀手锏。在Waymo重建任务中,倒角距离(CD)低至0.08,比SplatAD(0.82)降低了约90%(提升了一个数量级)!在新视角合成任务中也有4.5倍的误差降低。这说明其模拟的LiDAR点云与真实数据在几何上几乎完全一致。图7:LiDAR渲染。不同方法渲染的LiDAR点云对比。先前的方法表现出扭曲的扫描线模式和不完整的几何结构,包括行人等易受伤害的道路使用者。
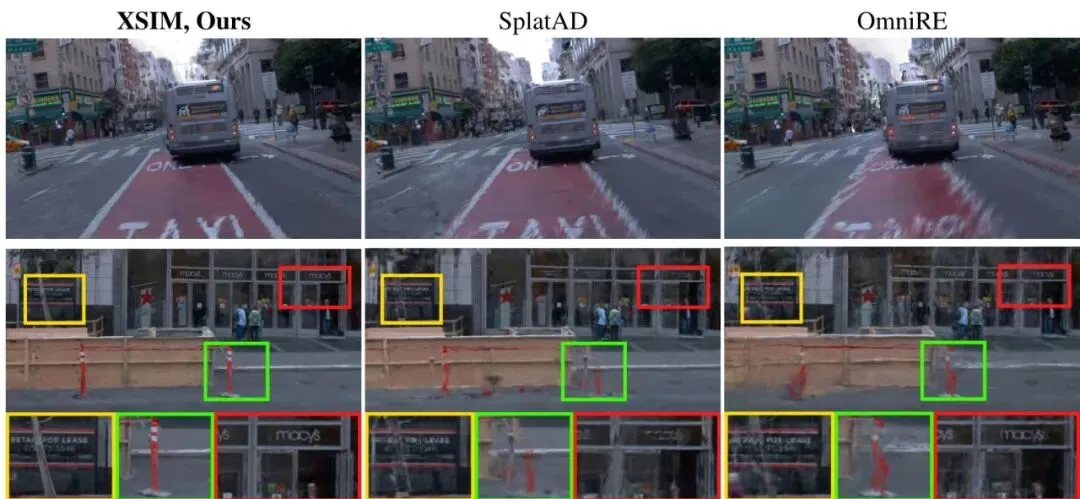
定性的LiDAR渲染结果(图7)一目了然。对比方法渲染的点云出现了明显的扫描线扭曲、断裂,甚至把行人这样的关键目标都“弄丢”了。而XSIM渲染的点云不仅环状结构清晰完整,而且几何细节(如行人、车辆轮廓)高度保真。图2:新视角合成(车道偏移3米)。Waymo开放数据集上的定性比较表明,XSIM提供的场景表示可以从新的自车轨迹中一致地渲染出来。
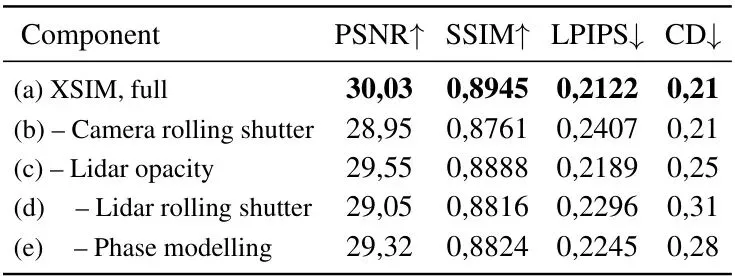
在新视角合成的极端测试中(图2),让自车在训练轨迹的基础上横向偏移3米进行渲染。XSIM依然能生成高度一致且清晰的画面,而对比方法则出现了模糊、鬼影和伪影。这说明XSIM学习到的场景表示具有极强的几何一致性和稳定性。表2:在Waymo数据集(一半分割)上新视角合成的消融研究。每一行对应于相对于父配置禁用一个组件。
消融实验(表2)也扎实地证明了每个组件的有效性。移除相机卷帘快门建模、LiDAR不透明度分离、LiDAR卷帘快门建模或相位建模机制,都会导致图像质量(PSNR, SSIM)和/或几何精度(CD)的明显下降。这验证了XSIM的设计不是花架子,每一个模块都贡献了实实在在的性能增益。未来展望:更逼真、更高效的仿真之路
XSIM在统一相机与LiDAR仿真的道路上迈出了坚实的一步,但自动驾驶仿真这座大厦的建造远未完工。基于它的成功,我们可以预见几个充满潜力的方向:
更多传感器的“大一统”:毫米波雷达、超声波雷达、事件相机等传感器的仿真能否也纳入这个统一框架?特别是雷达的复杂电磁波反射特性,对场景的材质属性提出了更高要求。
极端天气与光照模拟:雨、雪、雾、夜间、强逆光……这些才是自动驾驶的“魔鬼考场”。未来的仿真框架需要集成物理级的光线传输和天气粒子模型,在XSIM提供的精确几何与外观基础上,生成极具挑战性的测试场景。
实时性与闭环仿真:目前这类方法主要还是“开环”的,即先重建,再渲染。未来的方向可能是与游戏引擎或专用仿真器结合,实现“感知-决策-控制-世界状态更新”的实时闭环仿真,让AI司机在无限循环的虚拟世界中真正学会驾驶。
龙迷三问
这篇论文解决的核心问题是什么?解决自动驾驶仿真中,相机和激光雷达(LiDAR)渲染模型不统一、难以同时保证高逼真外观和高精度几何的问题。特别是解决了基于3D高斯泼溅的方法在模拟旋转式LiDAR(球形卷帘快门相机)时,在方位角边界处产生的严重投影失真和缺失问题。
“相位建模”具体是什么意思?这是XSIM的核心创新之一。由于LiDAR的方位角是周期性的(-π到π循环),且卷帘快门导致时间不连续,一个物体可能在相邻扫描周期被看到两次。相位建模就是主动考虑一个3D高斯粒子可能出现在当前、前一个或后一个方位角周期(即不同“相位”)的情况。它通过为每个可能的相位独立计算投影,来正确处理那些横跨边界、本应产生多个分离投影的粒子,从而避免标准方法产生的巨大单峰投影错误。
3DGUT和传统3DGS的EWA Splatting有什么区别?核心区别在于如何将3D高斯粒子投影到2D图像平面。传统EWA Splatting使用基于单个点的线性近似,对于复杂的相机模型(如带畸变、卷帘快门)误差大。而3DGUT使用无迹变换(UT),从3D高斯中采样多个点分别进行非线性投影,然后用这些点拟合2D高斯,这种方式能更准确地模拟复杂相机模型的投影效果,为统一仿真各种传感器奠定了基础。
如果你还有哪些想要了解的,欢迎在评论区留言或者讨论~龙哥点评
论文创新性分数:★★★★★
在统一的传感器仿真框架下,精准识别并解决了3DGUT在球形卷帘快门LiDAR上的根本性缺陷(方位角边界多峰投影问题),提出的“相位建模”机制构思巧妙且有效。“双不透明度”设计则从物理感知差异出发,干净利落地解决了外观与几何建模的固有矛盾。这两点都是具有高度原创性的贡献。
实验合理度:★★★★★
在Waymo、Argoverse2、PandaSet三大权威数据集上进行了全面测试,覆盖场景重建和新视角合成两大任务。对比基线选取广泛且均为近期顶会SOTA,包括NeRF和3DGS两大流派。指标涵盖图像质量(PSNR/SSIM/LPIPS)和几何精度(倒角距离),消融实验扎实,充分证明了每个组件的必要性。实验设计无可挑剔。
学术研究价值:★★★★★
为自动驾驶仿真领域提供了一个强大、统一的新范式。其“相位建模”思想对任何涉及周期性参数或边界不连续的渲染问题都有启发意义。“传感器特性解耦”的设计思路(如双不透明度)也可推广到更多多模态融合任务中。论文代码已开源,必将推动整个领域在高质量传感器仿真方向的发展。
稳定性:★★★★☆
在论文设定的自动驾驶场景重建和新视角合成任务上,表现出极高的稳定性和渲染质量,远优于对比方法。但由于其基于3DGS,对于极端新颖视角(如从未观察过的区域)或场景的大规模外推,其稳定性仍受限于基础表示方法,可能会产生伪影或崩溃。在已知观测范围内非常稳定。
适应性以及泛化能力:★★★★☆
框架本身设计为支持任意相机模型,理论上可适应各种相机和LiDAR。但当前实验集中在车载传感器和城市道路场景。对于室内、非结构化环境、或者其他类型的深度传感器,其泛化能力有待验证。不过其核心原理并不局限于特定场景,泛化潜力良好。
硬件需求及成本:★★★☆☆
基于3D高斯泼溅的方法在渲染时效率很高,可以达到实时或准实时。但训练过程仍需要大量的GPU内存和计算时间,特别是对于长序列、多动态目标的自动驾驶场景。相位建模等操作也会增加一定的计算开销。需要高端GPU进行训练,推理部署成本相对较低。
复现难度:★★★★★
代码已在GitHub上开源(https://github.com/whesense/XSIM)。论文对方法描述详细,且基于已被广泛研究的3DGS生态,复现路径清晰。具备3DGS和CUDA编程相关经验的团队复现难度中等。
产品化成熟度:★★★☆☆
在自动驾驶仿真流水线中的“场景重建与传感器数据增强”环节,已具备很高的产品化潜力。可用于快速生成高保真的多传感器测试数据。但距离集成进需要实时物理交互、闭环控制、大规模场景并发的全栈仿真平台(如CARLA、SVL等),还有集成和工程化的工作要做。
可能的问题:方法依然依赖于从真实数据中重建场景,而非从无到有的生成。对于模拟传感器噪声(如LiDAR的多次回波、相机噪点)的物理真实性未深入探讨。在极度稀疏的LiDAR观测下,几何重建的稳健性可能面临挑战。
[1] Nikolay Patakin, Arsenii Shirokov, Anton Konushin, Dmitry Senushkin. “Unified Sensor Simulation for Autonomous Driving.” arXiv preprint arXiv:2602.05617 (本论文).[2] Bernhard Kerbl, Georgios Kopanas, Thomas Leimkühler, George Drettakis. “3D Gaussian Splatting for Real-Time Radiance Field Rendering.” ACM Transactions on Graphics (TOG) 42.4 (2023).[3] Wu, Rundi, et al. “3DGUT: 3D Gaussian Unscented Transform for Arbitrary-View Camera Rendering.” arXiv preprint arXiv:2503.00339 (2025).[4] Georg Hess, et al. “SplatAD: 3D Gaussian Splatting for All-Day Autonomous Driving Simulation.” Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). 2025.*本文仅代表个人理解及观点,不构成任何论文审核或者项目落地推荐意见,具体以相关组织评审结果为准。欢迎就论文内容交流探讨,理性发言哦~ 想了解更多原文细节的小伙伴,可以点击左下角的“阅读原文”,查看更多原论文细节哦!

想和更多自动驾驶、机器人领域的小伙伴交流XSIM这样的前沿技术吗?欢迎加入龙哥读论文粉丝群,
扫描下方二维码或者添加龙哥助手微信号加群:kangjinlonghelper。
一定要备注:研究方向+地点+学校/公司+昵称(如 自动驾驶+北京+驭龙机甲),根据格式备注,可更快被通过且邀请进群。