*端到端(E2E)已成为普及的技术范式,因此,本文只讨论端到端模型的评测问题。因为法规限制,通常用智能驾驶指代自动驾驶,本文还是统一用自动驾驶,表达相同的含义。
自动驾驶端到端模型出现以后,快速推动了世界模型(这里不纠结是重建、生成、还是二者的结合)的发展,因为端到端模型的仿真需要系统能直接渲染出高质量的传感器数据(传统的游戏引擎、CARLA等均无法完全满足需求)。
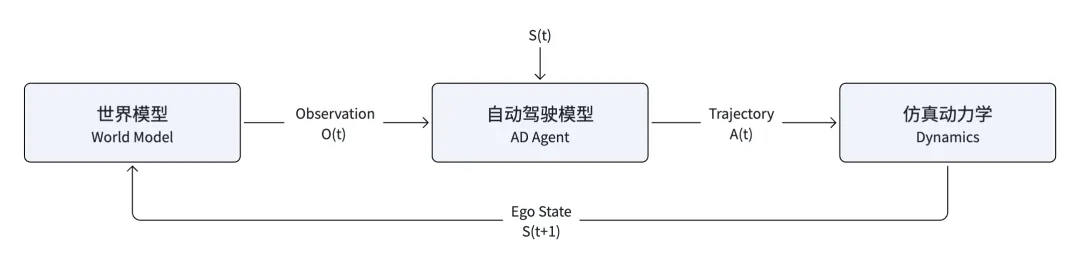
下图展示了基于世界模型的端到端自动驾驶闭环仿真框架。
过去十年,自动驾驶评测的关注点是:接管率(MPI)、安全接管率(MPCI/MPA)、“问题集”等,其本质是工程思维下的“漏洞修补”。但随着端到端的落地和城市NOA的普及,我们却发现:即使一个系统解决了所有已知的Bug,它依然开的和用户的预期有偏差、总会出现新的但又类似的问题。导致此现象的原因是评测方式一直没有质的变化,评测结果直接影响自动驾驶能力迭代的方向,没有好的评测体系,就很难有好的自动驾驶能力。
本文的核心观点:过去验证问题(Verification)评测的是系统的“下限”,未来需要的是评价能力(Evaluation),其定义的则是产品的“上限”。
面向端到端自动驾驶的仿真评测系统需要具备的几个关键特性:
1.仿真到现实(sim2real)差异足够小,这是仿真评测准确性的基础。
2.能够进行长时序(long-horizon)仿真,这是评测长程规划和决策能力的基础(比如导航和效率类问题的起因往往发生在更早的时刻)。
3.不仅能复现已知问题,还能构造新考题(scalable),这是评价自动驾驶场景泛化能力的核心。
神经辐射场(NeRF,2020年)和高斯溅射(3DGS,2023年)技术的出现在 80%(当前行业基于3DGS闭环仿真的问题复现率的平均水平)的场景下满足了第 1 个特性要求。但基于NeRF或3DGS重建的仿真评测方式也存在下列局限性:
新视角问题,即仿真时轨迹偏离原始数据轨迹太大导致渲染图像质量急速下降,针对此问题,一系列重建+生成结合的工作被提出,但这些工作主要是针对横向新视角问题的,且会增加训练耗时,对于自车加/减速后出现的他车纵向新视角问题,目前暂无可落地的解决方案。
非反应式的仿真环境,主要体现在两个方面,一、他车行为不会受自车行为变化的影响,二、原始数据里,如果自车和静态环境发生了接触或碰撞(如锥桶、施工牌等),仿真时只能replay,环境不会因为自车行为变化而自适应变化。
逐场景训练的方式,在评测集数据规模变大后,模型版本重刷的成本也成倍增加,除开经济成本,时间成本也基本限制了评测规模,除非不断增加GPU。
为了解决第 2 个问题,区域重建(large-scale recon)应运而生,但结果却发现区域重建对于仿真评测毫无价值,核心原因是:
原始数据获取困难,无论是多趟众包(车企的优势)或者真值车专门采集,都导致成本大幅增加却收益有限。如果采用众包的方案,还引入了两个新的技术问题:多趟数据的风格不一致影响重建质量、多趟数据中动态目标及其行为完全不一样;如果是真值车采集,采集范围将大幅受限且效率太低。
上述问题决定了区域重建只能实现静态多趟,前景动态目标及其行为还需要单独处理。有两种方法:一、对相同路段选择其中一条数据的动态目标重建,此方案需要解决目标车辆行驶超出原始数据范围后的新视角问题;二、通过场景内的图片直接生成3D资产或插入场景外的3D资产车辆,此方案需要解决和原始场景光影的一致性问题以及车尾灯刹车灯的时序建模和控制问题。
上述两个问题当前都没有很好的解决方案,即使解决了上面的两个问题,区域重建本质上还是逐场景的重建,限制了仿真时的轨迹和原始数据轨迹偏差不能太大,比如:在一个路口,原始数据自车右转,仿真时如果直行,新视角渲染的质量将大幅降低。为了解决这个问题,一些工作将多趟轨迹的数据构建为一个single-model的3DGS模型(基于多机多卡的训练),这使得在场景内任意位置可实现自由的渲染,但是原始数据的范围区域因为GPU显存的限制也无法无限扩大。
以上局限性使得区域重建在自动驾驶真实业务落地过程中并无实际的价值(学术研究发论文除外)。
为了实现上面的要求 2 和 3,生成模型从技术范式上属于最有潜力的方向。这里的生成模型不是特指视频生成模型,而更强调的是其预训练的范式,通过在预训练阶段掌握几何、逻辑、因果等通识能力,并在场景重建或场景生成的过程中隐式的展示出来。
Tesla 在 ICCV 2025上分享了其 Feedforward重建和长时序视频生成的能力,并重点强调了闭环评测的重要性(开环评测不能代表实车闭环性能),Waymo 在2026年2月展示了其基于 Google Genie 3 打造的 Waymo World Model,展示了其在长时序数据生成、可交互控制以及新视角合成方面的强大实力,两个头部自动驾驶公司宣示了仿真评测的未来发展方向正在向生成式世界模型靠近。
但是,鉴于目前发布的内容看,生成式世界模型直接用于自动驾驶的仿真评测(或训练)还有困难,在下面的几个关键问题上还存在短板:
多次生成的一致性,对于仿真评测,对比两个不同的模型版本,如果多次评测间的仿真环境差异太大,如何评价好坏(用场景数量的规模来抵消差异化的影响?)。
一致性还不够,包括:时序一致性(场景要素的无中生有、无故缺失、形变),多相机视角的一致性,多模态的一致性(视频、点云、鱼眼)、几何的一致性(绝对深度准确且连续)等。
符合物理规律和因果关系(比如交通流符合运动学,加减速符合动力学,交互行为符合因果关系等)。
小目标或复杂要素的生成质量,比如:红绿灯、行人、文字等生成质量不可控。
世界基础模型的训练数据缺失,比如要进行边界场景的仿真评测,但是世界模型也缺少边界场景的训练数据,如何解决“鸡生蛋、蛋生鸡”的问题。
虽然上述技术挑战还有待持续优化和攻克,但不能否定生成式世界模型对于仿真评测范式升维的重要性,考虑到技术的循序演进,实际落地将分成多个阶段。
首先,通过feedforward重建和生成模型拓展目前3DGS优化方法的范围边界和效果边界,对已有场景通过一步前馈推理获得三维场景表示,然后通过生成模型拓展场景的范围,在此过程中,feedforward重建和场景outpaint交替进行。
其次,在同一个静态场景下,生成多样化的动态行为前景来模拟各类仿真场景,只是修改天气、时间、光照等外观的价值非常有限,重点是泛化交通参与者的千变万化的动态行为,即验证相同的位置,不同的交通状况下,自车能否妥善应对。
最后,终局是直接根据文本描述生成想要的场景,并且能够精准的控制生成内容,从外观真实到行为合理,不只是人眼看起来“很好”的视频,而是符合几何、物理、因果等基础规律的三维世界。
自动驾驶评测的未来,不应是一张无限长的“错题集”(验证问题),而应是一场综合素质考核(评价能力)。
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
