两年时间的进化,端到端不再是“探索期”的技术,从特斯拉的单点突破到国内车企的集体量产冲刺,端到端已经正式进入“工程化期”。
更关键的是,技术路线开始收敛了。
“从‘能跑通’到‘能落地’,从‘拼算力’到‘拼细节’。”——这大概就是端到端收敛之后,行业对人才的真实诉求。基于行业诉求,深蓝学院开设了《端到端自动驾驶理论与实践》课程。首期200个名额,上线2小时全部售罄!
更有大批没抢到的同学,为此足足等了 3 个月。
为回应众多学员的返场呼声,今天,第二期报名通道,正式开启。
这一次,拼手速的时候到了👇
抢占限量特价名额
第二期课程预计限报200人
这门课程,每一章都直指“量产落地”:
经过这几年的探索与沉淀,自动驾驶的端到端技术路线已经逐渐清晰。
目前主要形成了两种主流范式:
而这两条路线的核心技术底座,也基本沉淀为行业共识。
我们的课程正是围绕“技术收敛”后的核心知识体系展开的,没有冗余内容,每一章都直指 “量产落地”。
主讲人:张巍老师
另外,聘请国内首批将端到端自动驾驶量产落地的团队负责人加盟作为课程顾问。
过去一年,市面上讲端到端的课程并不少。但真正上手跑过的人知道,最大的门槛从来不是理论,而是算力。
以现在最常被参考的DriveTransformer框架为例,官方配置需要8卡GPU集群。对绝大多数个人学习者来说,这就是一道跨不过去的墙。
很多人只能看论文、看PPT,然后想象模型是怎么训出来的。
这也是我们花了一年时间,反复打磨这门课程的原因——不是想赶风口,而是想把那道墙拆掉。
我们把DriveTransformer做了低算力适配和优化,原本需要8卡集群的训练,现在单卡就能跑通。代码开源、环境可复现、在家就能亲手跑完整套流程。
视频|深蓝学院《端到端自动驾驶理论与实践》课程基于DriveTransformer框架的Project可视化展示早鸟优惠:前50名立减100元,前100名立减50元。“开课后7天内,支持无理由全额退款”,体验课程质量后,能再最终决定。
抢占限量特价名额
第二期课程预计限报200人
过去一年,VLA开始和端到端结合,世界模型被用来生成训练数据,强化学习被用来微调规划器。这些新方向正在成为下一代系统的拼图。
如果一门课只讲“今天已经定型的东西”,那你学完的那一刻,可能就已经落后了。
所以我们做了两个层面的设计:
最终,你掌握的是 「数据-模型-训练-评测」全链路,以及看清下一波技术浪潮的能力。
 (点击图片了解课程详情/抢占名额)
(点击图片了解课程详情/抢占名额)
抢占限量特价名额
第二期课程预计限报200人
注:前50名立减100元,前100名立减50元。
抢占限量特价名额
第二期课程预计限报200人
全方位的学习服务:1V1 作业批改(支持多次提交,反复优化)、专属答疑群(讲师、助教、班主任)、班班督学(不怕你拖延)。
7 天无理由退款:开班后 7 天内,觉得课程不符合预期,支持无条件全额退款。
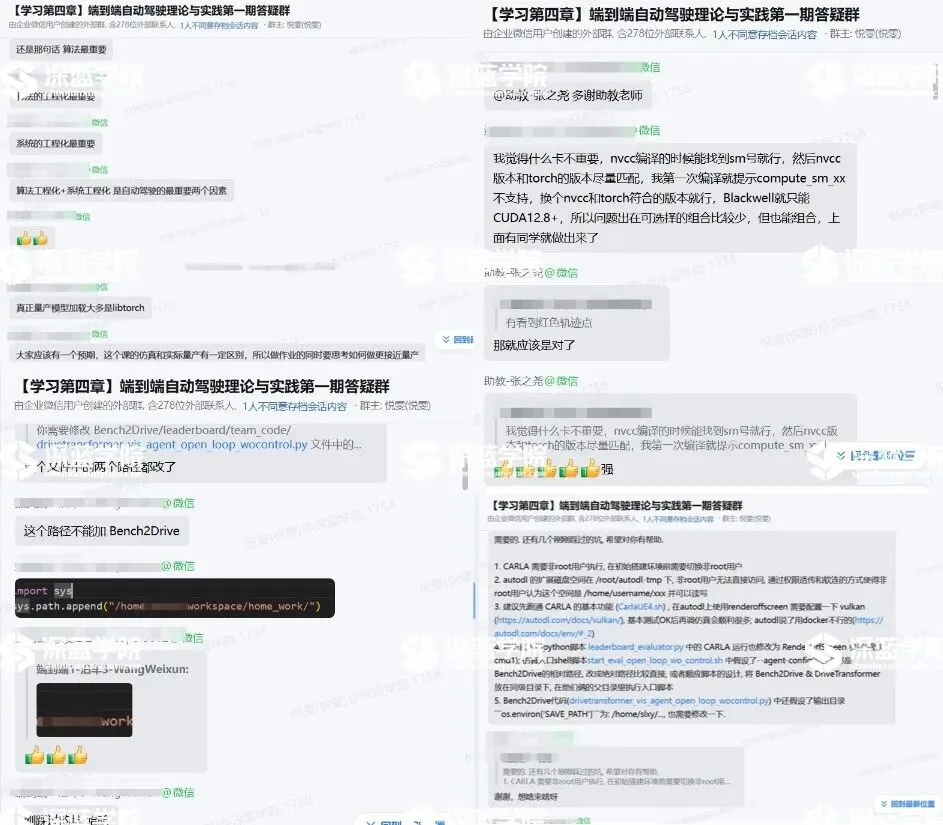
第一期课程学员群交流氛围,真实展示:
限时优惠(名额以实际支付顺序为准):
前50名支付,立减 100元。
第51至100名支付,立减 50元。
欢迎在本文评论区留言,告诉我们你对课程的期待、疑问或任何建议。





 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
