2026自动驾驶风向突变!VLA、世界模型、RL成破局关键,端到端“2.0时代”来了......
- 2026-02-28 01:17:20
「2026的新战局」
刚开年,自动驾驶圈就卷起来了。
我们梳理了2025年底至2026年2月的9篇代表性工作,可以清晰地看到三条交织推进的研究主线:
端到端正与VLA、世界模型深度融合,让车辆从“能开”走向“会思考”;
世界模型本身从“能生成”转向“更高效、更可控”;
场景重建则在真实感与效率上同步突破。
这些研究共同指向一个信号:2026年的自动驾驶,将更关注认知、推理与泛化。
接下来,让我们一同深入解读这些代表性工作,看看它们究竟为自动驾驶的未来描绘了怎样一幅蓝图。
需要特别说明的是,入选并不意味着这些工作在质量上优于同期其他论文——事实上,同一时期涌现出的优秀研究远不止于此。受限于篇幅,大量同样出色甚至更具影响力的工作未能在本文中得到呈现,这是选题取舍的结果,而非价值判断。如有遗漏您认为值得关注的重要工作,欢迎在评论区留言补充,我们也会持续追踪和介绍这一领域的最新进展。
1. GeRo:生成式场景推演赋能端到端驾驶
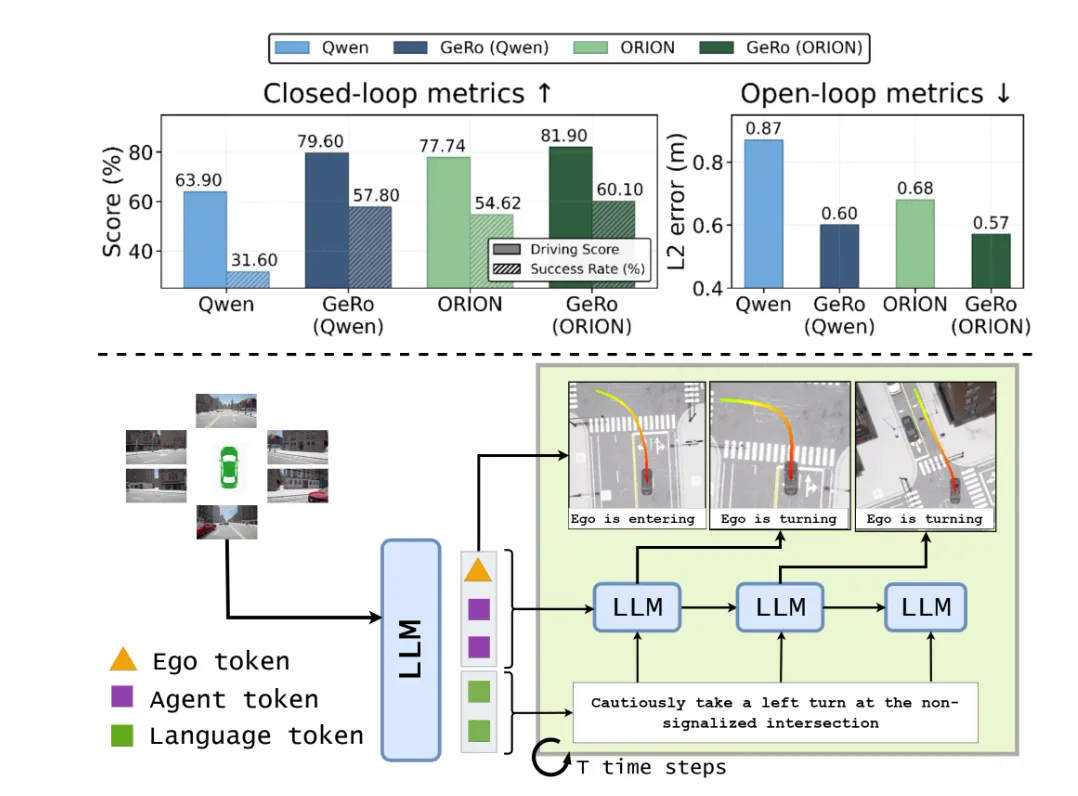
来自高通AI研究院(Qualcomm AI Research) 的GeRo框架,为VLA模型在自动驾驶领域的应用提供了一种全新的思路。
当前VLA模型大多依赖稀疏的轨迹标注进行模仿学习,其强大的生成能力并未得到充分利用。GeRo的核心思想,正是要释放这一潜力。
GeRo框架将规划与生成相结合,通过一种自回归的“推演”(Rollout)策略,让VLA模型不仅能规划自身轨迹,还能生成符合语言描述的未来交通场景。简单来说,模型在接收到多视角图像、场景描述(如“前方有行人,请慢速绕行”)和关于自身行动的“提问”后,会以自回归的方式,一步步生成未来的潜在场景(以潜空间Token的形式表示)和相应的文本回应。这种设计使得GeRo能够进行长时域、多智能体的联合规划,更好地理解语言指令与驾驶行为之间的因果关系。
为了防止在长时域推演过程中出现“想象”与现实的偏差(即“漂移”问题),GeRo引入了一种“推演一致性损失”,利用真实数据或伪标签来稳定预测结果,确保文本-动作对齐。在Bench2Drive驾驶基准上,GeRo将驾驶分数和成功率分别提升了15.7%和26.2%,展现了其强大的零样本泛化能力。
2. DriveWorld-VLA:统一潜空间世界建模与VLA
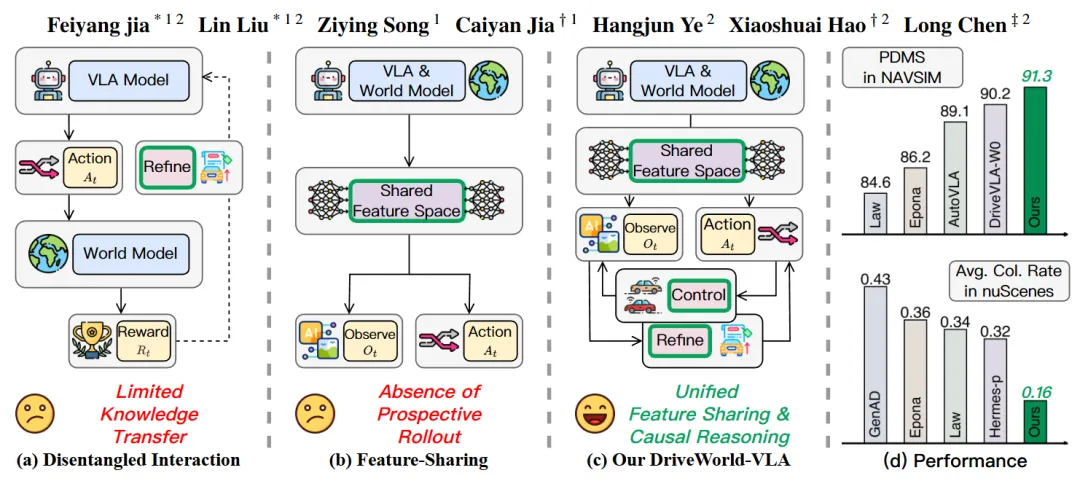
如何将世界模型的“想象力”与VLA规划器的“决策力”更紧密地结合?小米汽车联合北京交通大学提出了DriveWorld-VLA框架,旨在解决现有方法中未来场景演化和动作规划结合不充分的问题。
许多现有工作将世界模型和VLA作为两个相对独立的模块,限制了视觉想象对最终驾驶决策的影响。DriveWorld-VLA的创新之处在于,它在潜空间(Latent Space)层面将两者进行了深度统一。具体来说,框架将世界模型的潜空间状态作为VLA规划器的核心决策依据,使得规划器能够直接评估不同候选动作将如何影响未来的整体场景演化。
更重要的是,这种世界建模完全在潜空间中进行,支持在特征层面进行可控的、以动作为条件的“想象”,而无需进行计算开销昂贵的像素级视频推演。这大大提升了模型的运行效率。
3. Counterfactual VLA:会“反事实推理”的自动驾驶模型
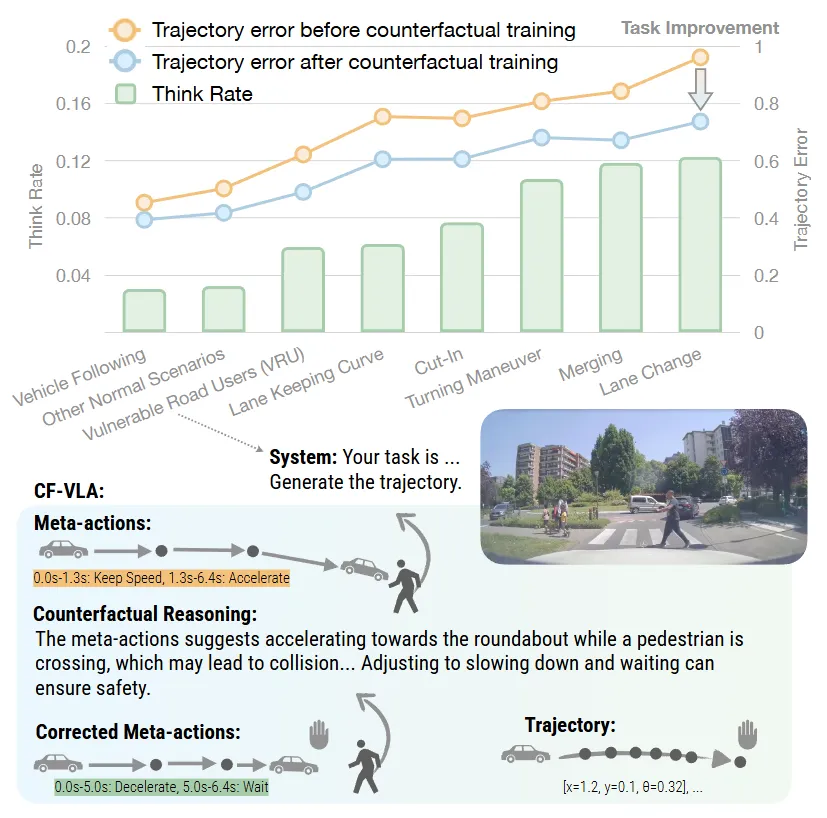
自动驾驶模型通常欠缺人类那种“三思而后行”的直觉,但斯坦福与英伟达的最新成果 CF-VLA正在填补这一空白。这项工作的核心突破,在于让端到端模型具备了因果维度的自我修正能力。
不同于传统模型直接输出动作,CF-VLA 在执行层之前插入了一个“反思环节”。它会先生成初步的 Meta-actions(元动作),利用视觉场景进行反事实推理,预测潜在的危险后果。这就好比给模型装了一个“安全过滤器”,在虚拟空间试错后,再输出最优解。
实验表明,CF-VLA不仅将轨迹精度提升了17.6%,更将安全指标提升了20.5%。有趣的是,它还表现出了“自适应思考”的能力——只在具有挑战性的场景中才会激活反事实推理模块,在简单场景下则保持简洁高效。
4. Astra:通用交互式世界模型

世界模型的目标是学习一个世界的内部表征,并用它来模拟未来的可能性。来自清华大学的Astra,将世界模型的研究推向了更通用、更具交互性的新高度。
Astra是一个通用的交互式世界模型,能够为自动驾驶、机器人抓取等多种不同场景生成高度真实的未来视频,并能精确响应不同的动作输入(如相机运动、机器人动作)。其核心是一种自回归去噪架构(Autoregressive Denoising Architecture),并利用时序因果注意力机制来聚合历史观测信息,支持流式输出。为了在保持时序连贯性的同时,避免模型过度依赖历史帧而导致对新情况反应迟钝,Astra还引入了“噪声增强的历史记忆”机制。
为了实现精准的动作控制,Astra设计了一个“动作感知适配器”,将动作信号直接注入到去噪过程中。更具创新性的是,它还开发了一个“混合动作专家(Mixture of Action Experts)”模块,能够动态地处理来自不同模态的异构动作信号,从而增强了模型在探索、操控、相机控制等多种真实世界任务中的通用性。实验证明,Astra在保真度、长时域预测和动作对齐方面均超越了现有的SOTA世界模型。
5. ResWorld:时序残差世界模型
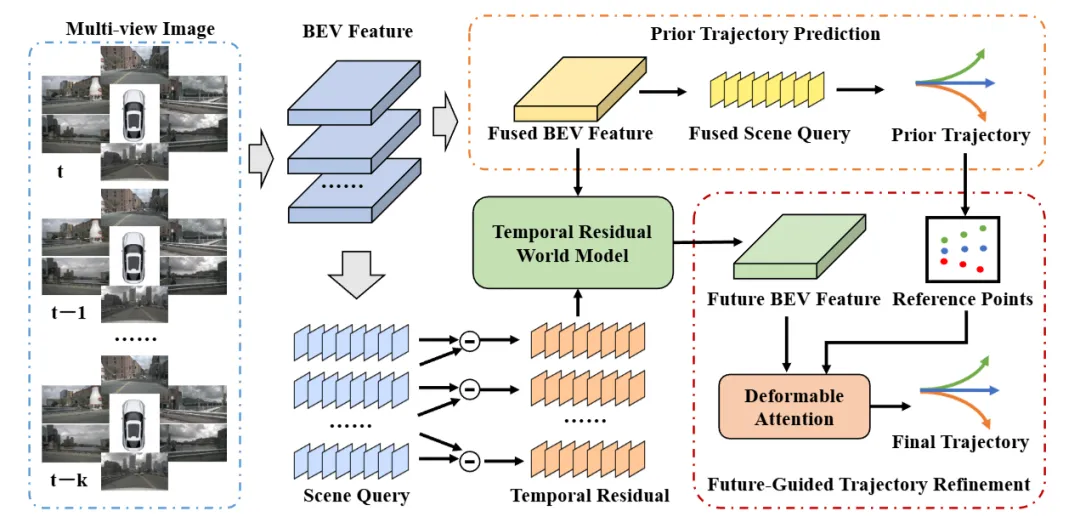
北航国家重点实验室+中关村实验室联合提出ResWorld,通过引入时间残差世界模型(TR-World)和未来引导轨迹优化模块(FGTR),解决了现有端到端自动驾驶中冗余建模静态对象和轨迹-场景交互不足的问题,实现了SOTA的规划性能。
ResWorld的核心思想是,世界模型应该更专注于动态目标的建模。它通过计算场景表征的时序残差(Temporal Residuals),直接提取出动态物体的信息,而无需依赖传统的目标检测和跟踪模块。TR-World(时序残差世界模型)只将这些时序残差作为输入,从而能够更精确地预测未来动态物体的空间分布。将这个预测结果与当前BEV(鸟瞰图)特征中包含的静态信息相结合,就能得到准确的未来BEV特征。
此外,ResWorld还提出了一个“未来引导的轨迹精化(Future-Guided Trajectory Refinement, FGTR)”模块。该模块让从当前场景预测出的先验轨迹,与世界模型预测出的未来BEV特征进行深度交互。这不仅能利用未来的路况信息来精化当前轨迹,还能为世界模型的未来预测提供稀疏的时空监督信号,防止模型在长期预测中出现“模型坍塌”问题。在nuScenes和NAVSIM数据集上的大量实验表明,ResWorld取得了SOTA的规划性能。
6. Drive-JEPA:视频JEPA遇上多模态轨迹蒸馏
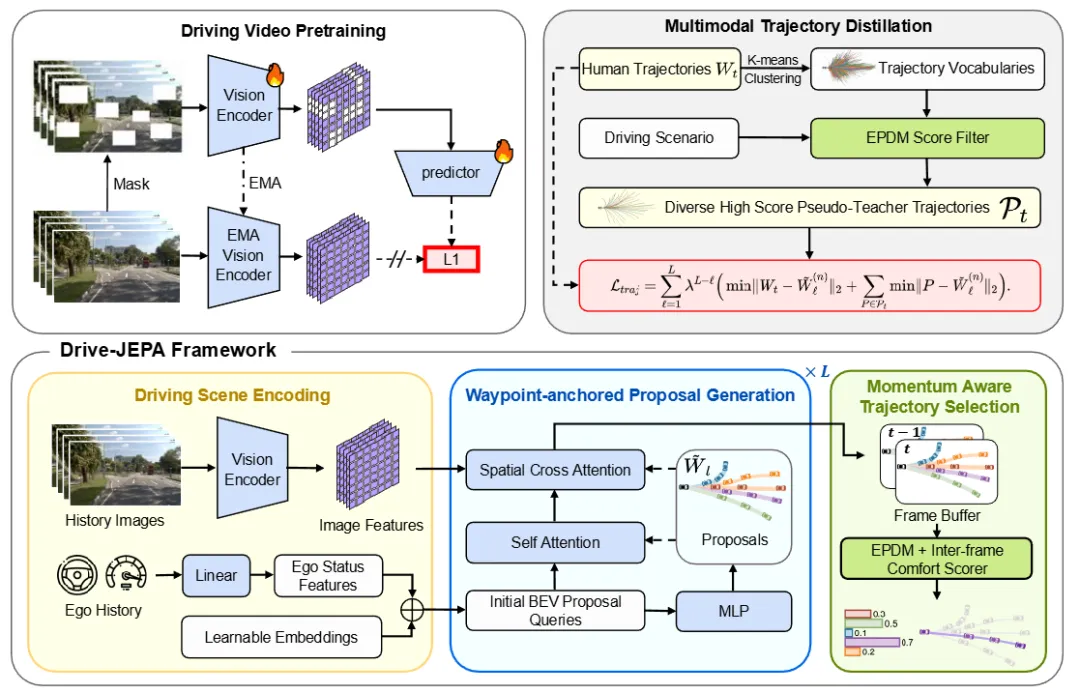
自监督学习,特别是像JEPA(联合嵌入预测架构)这样的方法,为从海量无标注数据中学习通用表征提供了强大工具。小鹏汽车提出Drive-JEPA,成功地将V-JEPA(视频JEPA)引入了端到端自动驾驶领域。
Drive-JEPA首先将V-JEPA应用于大规模驾驶视频的预训练,让ViT编码器学习到与轨迹规划任务高度对齐的、具有预测性的视觉表征。仅仅是这个预训练好的表征,配合一个简单的Transformer解码器,就在NAVSIM基准的“无感知”设定下超越了之前的所有方法。
然而,真实驾驶场景的复杂性在于其“模棱两可”:对于同一个场景,通常只有一个真人驾驶轨迹作为监督信号,但合理的驾驶行为并非只有一种。为了解决这个问题,Drive-JEPA引入了多模态轨迹蒸馏机制。它让一个以“提议”(Proposal)为中心的规划器,同时从仿真器生成的多种不同轨迹和人类驾驶轨迹中进行学习,并设计了一种“动量感知选择机制”来鼓励模型产生稳定且安全的行为。最终,完整的Drive-JEPA框架在NAVSIM v1和v2上均创造了新的SOTA纪录。
拓展阅读:小鹏提出JEPA世界模型:用V-JEPA预训练+多模态蒸馏,刷新端到端自动驾驶SOTA
7. PlannerRFT:扩散规划器的强化微调
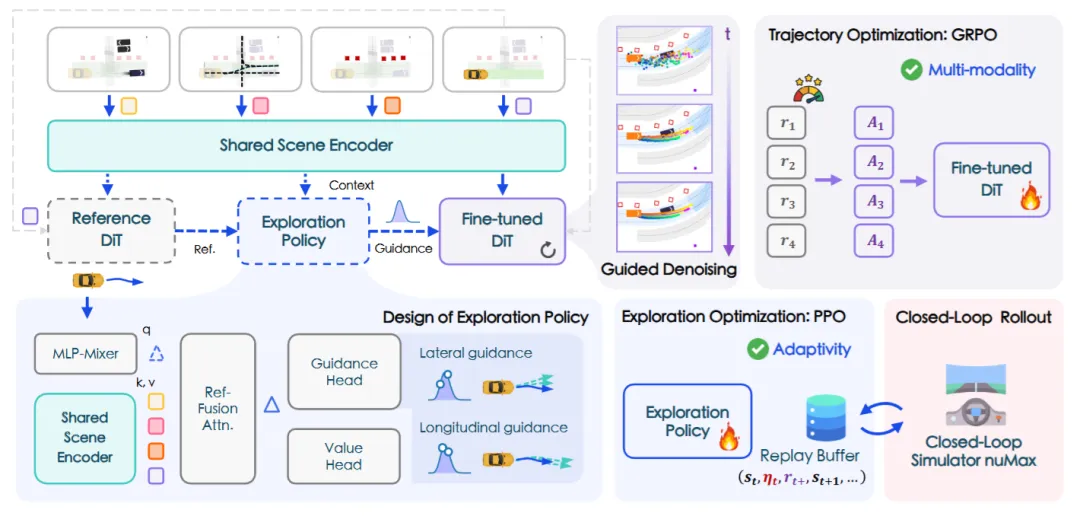
基于扩散模型的规划器因其生成类人轨迹的能力而备受关注。然而,如何通过强化学习对其进行微调,以适应更复杂的闭环驾驶场景,一直是一个挑战。同济大学、香港大学OpenDriveLab等研究团队提出 PlannerRFT 框架,为此提供了一个高效的解决方案。
PlannerRFT是一个为扩散规划器设计的、样本效率极高的强化学习微调框架。其核心是一个双分支优化策略:一个分支负责优化轨迹的整体分布,另一个分支则自适应地引导去噪过程,使其朝向更有希望探索的方向,整个过程无需改变原始的推理流程。这种设计使得模型能够在保持多模态、场景自适应轨迹生成能力的同时,高效地利用奖励信号进行优化。
为了支持大规模的并行学习,团队还专门开发了一个名为nuMax的优化版仿真器,其推演速度是原生nuPlan的10倍。在nuMax的加持下,PlannerRFT在实验中展现出了SOTA的性能,并在学习过程中涌现出许多有趣的、类似人类的驾驶行为。
8. SGDrive:场景-智能体-目标的层级世界认知
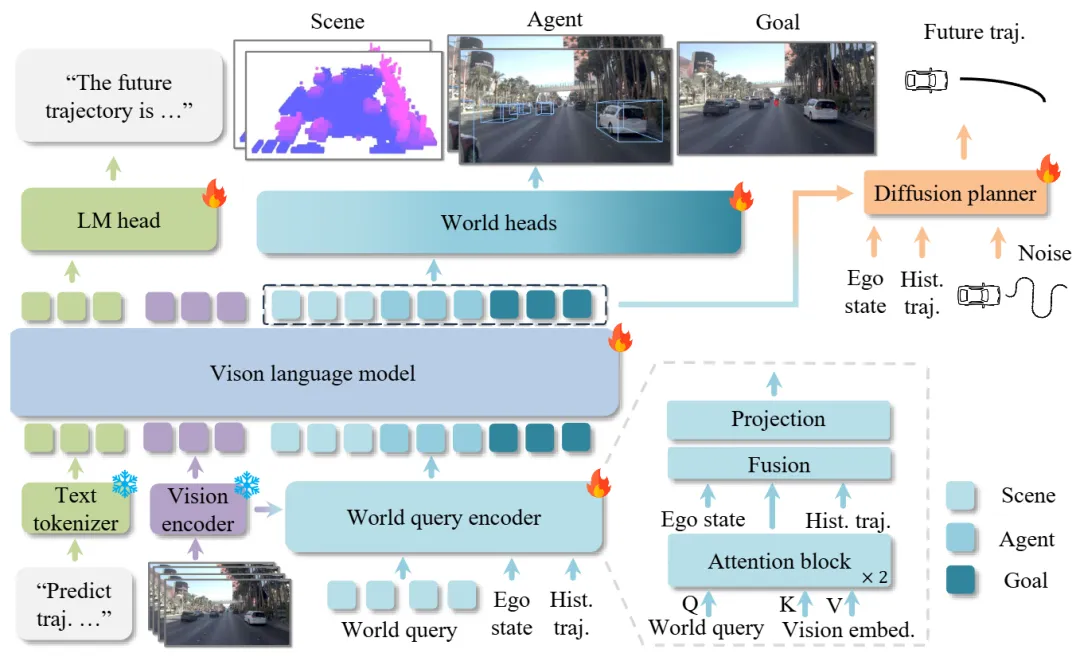
通用VLM虽然强大,但缺乏对驾驶场景中3D时空关系的结构化理解。来自复旦大学的研究团队提出的SGDrive,通过构建一个场景-智能体-目标(Scene-Agent-Goal) 的三层认知层级,来专门解决这个问题。
SGDrive的设计模仿了人类的驾驶认知过程:驾驶员首先感知整体环境(场景上下文),然后重点关注对安全至关重要的其他交通参与者(智能体)及其行为,最后在执行具体动作前形成短期的行驶意图(目标)。
基于一个预训练的VLM骨干网络,SGDrive将驾驶理解分解到这三个层级中,为通用的VLM模型注入了结构化的时空表征能力。这种层级化的分解,将多层次的信息整合成一种紧凑而全面的格式,专用于轨迹规划。在NAVSIM基准测试中,SGDrive在纯相机方案中取得了SOTA性能,验证了这种层级化知识结构在改编通用VLM以适应自动驾驶任务上的有效性。
9. EVolSplat4D:高效体素高斯溅射用于4D城市场景合成
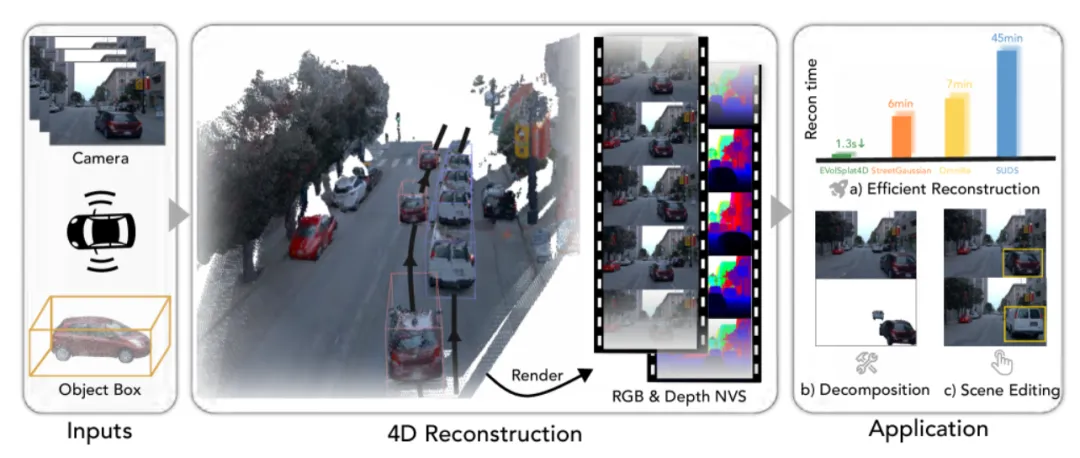
高质量的仿真环境是训练和测试自动驾驶系统的关键。浙江大学、华为等研究团队提出EVolSplat4D,在4D城市场景合成方面取得了重要突破。
当前主流的神经辐射场(NeRF)和3D高斯溅射(3D Gaussian Splatting)方法虽然能实现逼真的渲染效果,但通常需要针对每个场景进行耗时的优化。而一些前馈式(Feed-forward)方法又常常导致3D不一致性。EVolSplat4D通过一个前馈式的三分支框架,巧妙地解决了这个矛盾。
该框架统一了基于体素和基于像素的高斯预测:
对于近距离的静态区域,它直接从3D特征体素中预测3D高斯点的几何信息,并用一个语义增强的图像渲染模块来预测其外观。
对于动态的物体,它利用以物体为中心的标准空间和一个运动调整的渲染模块来聚合时序特征,确保稳定的4D重建。
对于远景,则由一个高效的、基于像素的高斯分支来处理,以保证全场景的覆盖。
实验结果表明,EVolSplat4D在KITTI-360、Waymo等多个数据集上,无论是在静态还是动态环境的重建上,其准确性和一致性都超越了现有的SOTA方法,为自动驾驶仿真提供了更高效、更逼真的数据来源。
这些工作不仅仅是单个算法的突破,更代表着一种范式的转变——从依赖大量人工标注和规则的传统方法,转向依靠大模型自身的学习、推理和泛化能力。我们有理由相信,随着这些研究的不断深入,一个真正能够理解复杂世界、并做出近乎完美决策的通用自动驾驶智能体,正离我们越来越近。
对于2026年的自动驾驶研究,您最期待在哪个方向看到突破性进展?欢迎在评论区分享您的看法!
REF
1.GeRo: Generative Scenario Rollouts for End-to-End Autonomous Driving, https://arxiv.org/abs/2601.11475
2.DriveWorld-VLA: DriveWorld-VLA: Unified Latent-Space World Modeling with Vision-Language-Action for Autonomous Driving, https://arxiv.org/abs/2602.06521
3.Counterfactual VLA: Counterfactual VLA: Self-Reflective Vision-Language-Action Model with Adaptive Reasoning, https://arxiv.org/abs/2512.24426
4.Astra: Astra: General Interactive World Model with Autoregressive Denoising, https://arxiv.org/abs/2512.08931
5.ResWorld: ResWorld: Temporal Residual World Model for End-to-End Autonomous Driving, https://arxiv.org/abs/2602.10884
6.Drive-JEPA: Drive-JEPA: Video JEPA Meets Multimodal Trajectory Distillation for End-to-End Driving, https://arxiv.org/abs/2601.22032
7.PlannerRFT: PlannerRFT: Reinforcing Diffusion Planners through Closed-Loop and Sample-Efficient Fine-Tuning, https://arxiv.org/abs/2601.12901
8.SGDrive: SGDrive: Scene-to-Goal Hierarchical World Cognition for Autonomous Driving, https://arxiv.org/abs/2601.05640
9.EVolSplat4D: EVolSplat4D: Efficient Volume-based Gaussian Splatting for 4D Urban Scene Synthesis, https://arxiv.org/abs/2601.15951
商务推广/稿件投递请添加:xinran199706(备注商务合作)



· 计划周期:深蓝学院将以3个月为一个周期,建立工程师&学术研究者的「同好社群」
· 覆盖方向:自动驾驶、具身智能(人形、四足、轮式、机械臂)、视觉、无人机、大模型、医学人工智能……16个热门领域
扫码添加阿蓝
选择想要加入的交流群即可
(按照提交顺序邀请,请尽早选择)
👇


