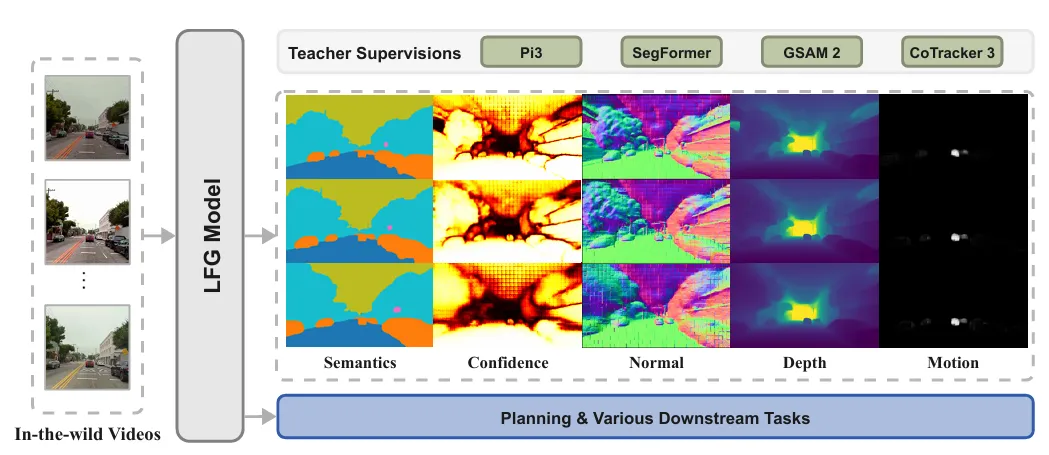
1. 架构设计:伪4D表示的统一建模(真相1)
LFG采用“骨干网络+自回归模块+多任务解码器”架构,实现几何、语义、运动、未来信息的联合学习:
(1)核心组件
- 骨干网络:基于预训练的π³模型(排列等变视觉几何学习),冻结DINOv2编码器与几何解码器(点云、置信度、相机姿态),确保基础几何建模能力;
- 因果自回归Transformer:4层8头结构,接收π³输出的N帧 latent 令牌, autoregressively 预测M帧未来令牌,强制模型学习时间演化规律;
- 几何类:3D点云()、相机姿态(,4×4齐次矩阵)、置信度图();
- 语义类:7类语义分割(道路/车辆/行人/建筑/植被/天空/背景);
- 运动类:动态区域掩码(,区分移动目标与静态环境)。
(2)关键设计逻辑
- 冻结几何解码器:复用π³的强几何建模能力,避免从零学习3D结构,提升训练效率;
- 因果约束:未来令牌仅依赖历史与当前信息,符合驾驶决策的时序依赖性;
- 多任务共享特征:强制模型学习跨模态统一表示,增强特征迁移性。
2. 训练机制:多教师引导的无标注学习(真相2)
LFG通过3类专业教师模型生成伪标签,实现无标注视频的监督训练,解决野生数据缺乏标注的问题:
| | |
|---|
| | 教师输入全序列(N+M帧),学生仅输入N帧,预测N+M帧几何信息,学习未来演化; |
| | 教师对每帧生成软语义伪标签,学生预测当前与未来帧语义,学习语义一致性; |
| Grounded SAM2 + CoTracker3 | | SAM2检测车辆/行人实例,CoTracker3追踪2D轨迹,结合π³点云计算3D位移,生成动态掩码; |
(3)损失函数设计
总损失 = 当前帧损失 + λ_future×未来帧损失(λ_future=10,强化未来预测能力),具体包括:
- 姿态损失:SO(3)旋转测地线距离 + 平移Huber损失;
- 置信度损失:BCE损失(基于点云重建误差的二分类目标)。
(4)训练流程
三阶段端到端训练:
3. 实验验证:单相机超越多传感器的核心证据(真相3)
LFG在多任务上的性能验证,证实无标注预训练的有效性:
(1)核心规划任务(NAVSIM基准)
- 数据效率验证:1%标注数据达PDMS 66.3(领先DINOv3 10+分),10%标注数据达81.4(匹配DINOv3全量数据性能)。
(2)多任务迁移性能
- 语义分割(KITTI-360):mIoU 0.768,超越教师SegFormer(0.680),未来帧预测mIoU 0.751;
- 深度估计(KITTI-360):RMSE 4.38,与π³(4.37)相当,未来帧RMSE 4.38;
- 轨迹预测(KITTI-360):ATE 1.00 m,旋转误差2.30°,仅略逊于π³(ATE 0.43 m)。
4. 优势根源:单相机超越多传感器的关键逻辑(真相4)
LFG打破“多传感器=高性能”的核心原因的在于:
- 时间上下文建模:通过自回归预测未来动态,比静态多模态融合更适配驾驶场景;
- 强几何先验:π³预训练骨干提供高精度3D建模,弥补单相机缺乏深度信息的劣势;
- 多模态伪监督:语义+运动+几何的联合学习,构建比单一模态更丰富的场景理解;
- 海量数据优势:野生视频覆盖更多真实场景(40国244城),泛化性优于标注数据集。
关键内容
1. LFG与主流基线的核心性能对比
2. 组件消融实验(NAVSIM PDMS)
💬 Q&A
Q1:LFG仅用单相机为何能超越多相机+LiDAR的基线模型?
A:核心在于“时间上下文建模”与“强几何先验”的协同:① 单相机的劣势是缺乏直接深度信息,但LFG复用π³的预训练几何能力,通过多帧视觉线索重建3D结构,弥补单相机不足;② 多传感器基线多依赖静态多模态融合,而LFG通过自回归预测未来动态,更贴合驾驶决策的时序需求;③ 野生视频的海量场景覆盖(40国244城)提升了泛化性,优于标注数据集的场景局限;④ 多模态伪监督(语义+运动+几何)构建了更全面的场景理解,比单一模态融合更具决策价值。
Q2:多教师监督相比传统自监督(如帧间一致性)有何优势?
A:传统自监督依赖帧间 photometric一致性,仅能学习低级特征,且难以建模动态场景;而多教师监督的优势在于:① 针对性强,每个教师专注单一专业任务(几何/语义/运动),生成高质量伪标签;② 可学习高级语义与动态信息,直接适配自动驾驶决策需求;③ 避免单一任务偏见,多模态伪标签协同约束,学习统一的任务导向特征;④ 无需依赖场景静态假设,能有效处理动态目标(如车辆变道、行人横穿)。
Q3:LFG的高数据效率源于什么?
A:数据效率的核心是“预训练特征的强任务相关性”:① 预训练目标直接对齐自动驾驶核心需求(几何重建、语义理解、动态建模、未来预测),特征天然适配下游规划任务;② 多模态教师监督确保特征同时具备几何精度、语义辨识度与运动敏感性,无需下游大量标注微调;③ 因果自回归建模捕捉了驾驶场景的时序规律,减少下游任务对标注轨迹的依赖;④ 海量野生视频覆盖了多样化的交通场景与天气条件,预训练特征泛化性强,少量标注即可适配特定场景。
Q4:LFG在工业化部署中还面临哪些挑战?
A:核心挑战集中在推理延迟、长时预测与极端场景适配:① 推理速率(5Hz)虽满足基本需求,但高帧率驾驶场景(如高速)需进一步优化(可通过模型压缩、硬件加速);② 目前仅支持短时域预测(3-6帧),长时规划(如路口决策、变道规划)需扩展自回归 horizon;③ 野生视频中极端场景(暴雨、暴雪、道路施工)占比低,预训练特征在这些场景的鲁棒性需提升;④ 单相机在弱光、遮挡场景的几何建模精度可能下降,需结合多帧融合或轻量化传感器互补。
Q5:LFG的自回归模块与传统世界模型(如Grounded SAM2)有何区别? A:核心区别在“任务导向”与“模型设计”:① 任务导向,LFG聚焦自动驾驶决策所需的伪4D表示(几何+语义+运动),世界模型更侧重通用场景生成;② 模型设计,LFG采用轻量自回归Transformer,仅预测 latent 令牌而非像素级图像,推理效率更高;③ 监督方式,LFG依赖多教师伪监督,世界模型多为无监督或弱监督,特征与驾驶任务的对齐度更低;④ 部署适配,LFG输出直接可用于规划(点云、姿态、运动掩码),世界模型需额外解码与决策适配。
🎯 点评
- 核心贡献:首次提出“无标注、单相机、视频-centric”的自动驾驶预训练框架,打破多传感器依赖,证实野生视频可作为自动驾驶的核心数据来源;通过多教师监督与因果自回归建模,学习统一伪4D表示,实现规划、语义、几何多任务的高效迁移;极致的数据效率为行业解决标注瓶颈提供了可行路径,推动自动驾驶向低成本、规模化部署迈进。
- 亮点:① 架构设计巧妙,复用π³几何先验+轻量自回归,平衡性能与效率;② 多教师监督策略创新,解决无标注数据的监督难题,为其他无标注视觉任务提供参考;③ 实验验证全面,覆盖规划、语义、深度、轨迹多任务,结果可信度高;④ 工程实用性强,单相机部署成本低,数据效率高,适配工业化需求。
- 不足:① 推理速率(5Hz)需进一步优化以适配高动态场景;② 长时预测能力有限,仅支持短时域演化;③ 极端场景(弱光、遮挡、恶劣天气)的鲁棒性未充分验证;④ 运动掩码仅区分动态/静态,未建模目标运动方向与速度,对高速场景决策支持不足。
🌟 总结金句
自动驾驶的规模化落地,关键在于摆脱对“昂贵标注”与“多传感器”的双重依赖——LFG以野生视频为数据源泉,用多教师监督挖掘场景本质,以伪4D表示统一几何、语义与动态,让单相机具备超越多模态系统的决策能力,为自动驾驶的“低成本、高泛化”提供了核心技术支撑。
📌 互动引导
你认为LFG最需要优先突破的工业化落地瓶颈是什么?
● ✅ 推理速率优化(提升至10Hz以上,适配高速场景);
● ✅ 长时预测扩展(延长自回归 horizon,支持长时规划);
● ✅ 极端场景增强(补充极端天气/遮挡场景数据,提升鲁棒性);
● ✅ 运动信息深化(建模目标运动速度/方向,支撑复杂决策);
● ✅ 多相机扩展(兼容多视角输入,进一步提升几何精度);
欢迎在评论区分享观点,一起探讨自动驾驶低成本部署的技术路径 👇
🧩 思考/研究 Idea 彩蛋(可操作方向)
- 推理加速:采用模型剪枝与量化,将LFG推理速率提升至10Hz以上,适合投稿《IEEE Transactions on Intelligent Transportation Systems》;
- 长时规划:扩展自回归模块至10+帧,结合强化学习优化长时轨迹预测,适合投稿《NeurIPS》;
- 极端场景增强:用生成式AI(如Sora)生成极端场景数据,微调预训练模型,适合投稿《CVPR》;
- 运动建模深化:在运动掩码基础上预测目标运动向量,提升高速场景决策精度,适合投稿《ICRA》;
- 多相机兼容:扩展架构支持多视角输入,融合单相机几何与多视角冗余,提升遮挡场景鲁棒性,适合投稿《ECCV》;
- 端到端规划:将LFG特征与强化学习规划器直接结合,实现无标注端到端驾驶,适合投稿《Nature Communications》;
- 轻量化部署:设计小参数量版本(<5亿参数),适配车载边缘计算平台,适合投稿《IEEE Micro》。