纯视觉自动驾驶标准范式系列二:Occupancy占据网络
- 2026-04-08 12:54:01
纯视觉自动驾驶标准范式系列二:Occupancy占据网络今天是纯视觉自动驾驶的序列二,我们重点讲一下Occupancy占据网络,这是继上次BEV纯视觉自动驾驶标准范式系列一:BEV(Bird's Eye View,鸟瞰视角)之后,最重要的部分。 在纯视觉范式里,BEV和Occupancy更像是一对孪生兄弟,两者需要同时训练,如何判断BEV的表征能力,其实是需要看Occupancy的实际效果的,例如3D检测的效果,图像分割的效果等等。 关于BEV表征的训练过程,我还是再补充一下,这样有利于大家更深入的理解Occupancy占据网络的实现原理。 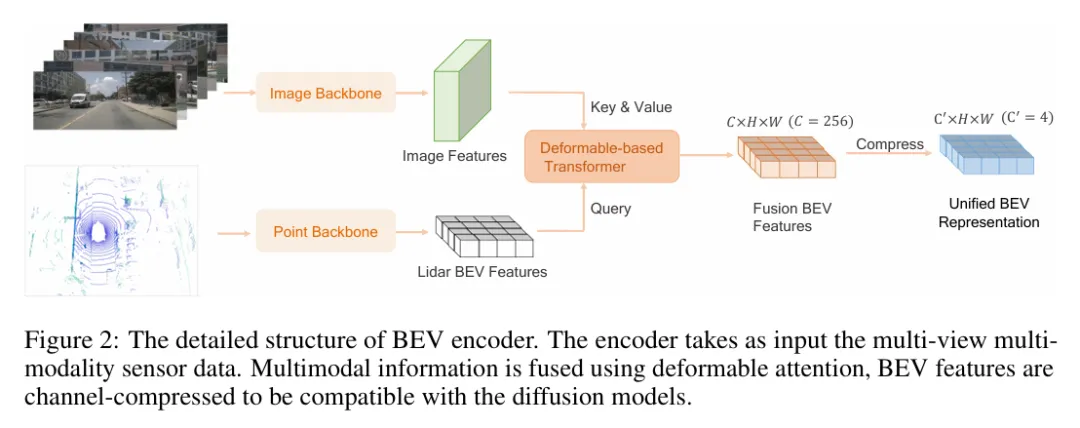
图 1 BEV表征生成过程 我们看图1,实际上这个训练过程和经典的Transformer是非常类似的,只是Transformer处理的是离散的token,而BEV处理的是一个个切分好的网格。 大体流程是把一个图像先分成例如200X200的网格(你注意这里是BEV网格,也就是俯视图,而不是简单的二维图像),然后每个网格对应一个Query,Query要做的事情就是基于自己的网格坐标(x, y),找到对应的特征聚合,也就是要把这个网格图片的特征“吸”过来,融合成这个格子的BEV特征。 那怎么融合呢?其实就还是Transformer的三件套Query、Key和Value。我们看图1就知道Key、Value来自图像本身的像素,那基于QKV做注意力计算就很快能得到BEV向量,是不是很像Hidden states?那就对了! 所以在回过头来看,上一篇BEV里介绍的SCA空间交叉注意力和TSA时间自注意力,不就是干这活的吗(做QKV运算,求注意力,生成BEV向量)。 空间注意力(SCA: Spatial Cross Attention) 每个BEV查询,通过空间交叉注意力cross attention,在当前时刻的多摄像头图像中,查找对应位置的视觉特征,这不就是Key和Value吗。 时间注意力(TSA: Temporal Self Attention) 每个BEV查询,通过时间自注意力self attention,与上一时刻的BEV特征进行交互,融合历史信息。 好,我画了一张简单的架构流程示意图2,BEV表征向量通过类似FFN的前向神经网络(或者其他类似的都可以),把学习到的BEV特征进行推理,去完成下游的多个任务,基于任务结果来计算Loss,进行反向传播,不断地调整BEV这个中间隐变量,这就是大致的训练过程。 当然,这是一个有监督Supervised的训练过程,确实需要人工对格子进行标注,比如格子被占(有车、有人、有障碍物等),格子空闲可以行驶,格子是路面、人行道或者护栏等等。 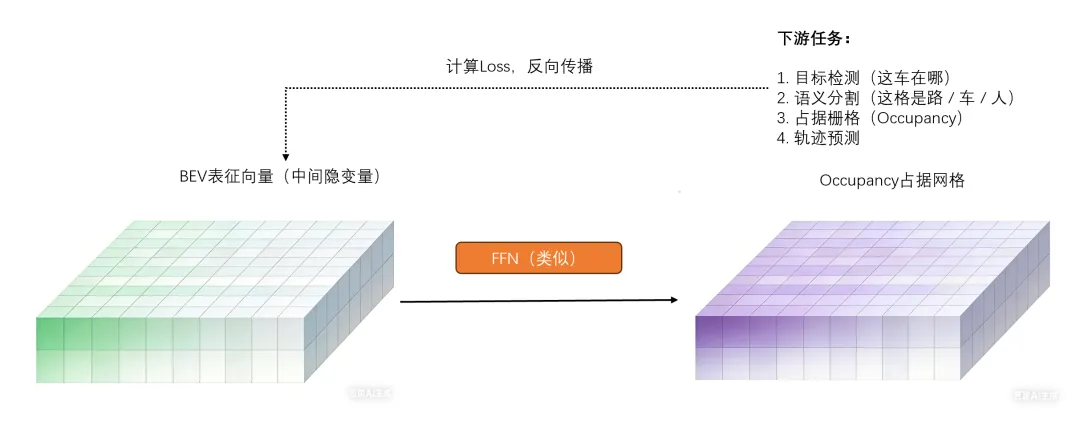
图 2 BEV表征训练过程 接下来我们详细介绍Occupancy占据网格。 Occupancy占据网格 (一)技术思想 在纯视觉自动驾驶的技术演进中,从BEV感知到未来预测,Occupancy占据网格是承上启下的关键一环。它不再满足于只“看到”当前的物体,而是要“预见”未来空间的占用情况,为自动驾驶的安全决策提供更底层的环境理解。 从下图3可以清晰地看到,Occupancy其实也是一个Latent vector,或者说中间向量,类比Transformer大流程,如果说BEV是计算完了Attention的话,那Occupancy就是计算完了FFN,但是还没计算Softmax,所以还是一个中间隐变量,距离最后的结果就差临门一脚。 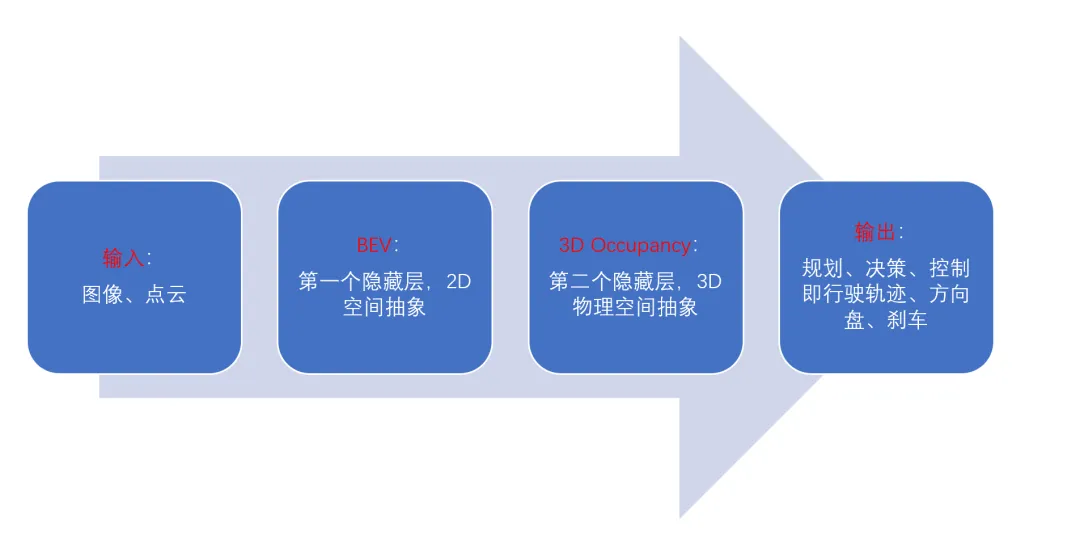
图 3 Occupancy流程:BEV → Occupancy → Planning 好,铺垫了这么多,接下来我们找了一篇最经典的论文来讲解Occupancy。 
图 4 Occupancy介绍 当你在路上行驶时,如何通过视觉描述3D场景?人类驾驶员能轻松描述环境:“我车左侧5英寸处有一辆奔驰”、“前方约50米处有一辆卡车,车尾伸出约5英寸的软管”等。这种描述真实世界的能力,是实现完全自动驾驶(AD)的关键。 目前主流的中心视角自动驾驶系统需应对多样的实体,包括车辆、SUV、施工场景,以及静态障碍物、路障、行人和背景建筑、植被等。将3D场景量化为带语义标签的结构化栅格(即3D Occupancy占据网格),是一种直观的解决方案。 用一句话来说的话,因为汽车真正行驶的是在3D空间中,因此模型也要做3D空间的建模。基于什么来做3D reconstruction?就是之前提到的BEV统一表征,当然现在最新的研究趋势也把Agent智能体加上了,这个不在我们今天的讨论范围内。 我们对比一下图4右上角的几张小图,区分的特别明显;拿c和d举例子,c是固定的边界框,当遇到非规则的障碍物就无能为力了,而d是Occupancy的方式,像素级刻画物体,被占的地方标成不同颜色就好,不会有空间的遗漏。 
为什么特斯拉、蔚来自研的智驾系统都在疯狂押注3D Occupancy?OccNet的这篇论文给出了答案。我们知道3D Occupancy并不是最终输出,它是自动驾驶系统的“3D 物理隐层”,就像神经网络中FFN之后、Softmax之前的高级特征。它承接BEV感知的结果,为检测、分割提供细粒度信息,更直接为规划模块提供 “哪里能走、哪里不能走” 的核心空间约束,最终让运动规划的碰撞率降低15%–58%。这是3D Occupancy成为纯视觉智驾标准范式的根本原因。 (二)技术架构 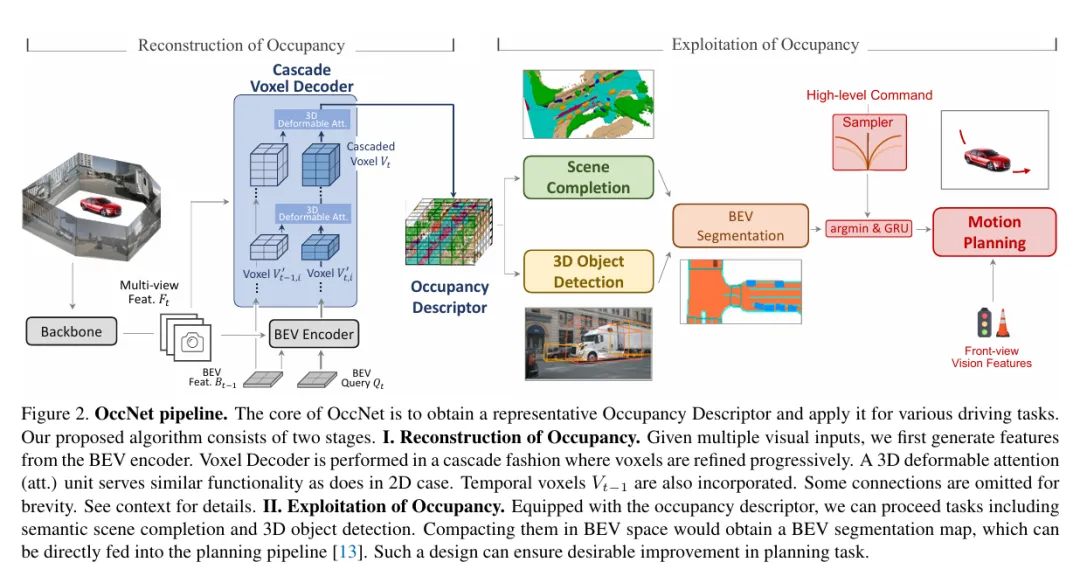
图 5 Occupancy架构 如图5显示,OccNet的pipeline 分为两大核心阶段: 1.) Reconstruction of Occupancy(占据重建) 2.)Exploitation of Occupancy(占据利用):处理各类下游任务 这部分是论文最核心的部分,也是理解起来最难的部分,核心就是解释如何从2D重建成3D。我先打个比方,然后再详细讲解公式。比如你现在拍一张客厅的俯视图,里面有沙发,有茶几,有吊灯等等,就是把原来的三维空间压缩到二维空间,但是里面包含了“高度信息”。而3D重建就是基于BEV这些信息重新生成客厅原来的3D空间,比如把沙发恢复成1米高,茶几恢复成0.5米高,灯恢复成2米高。 
图 6 BEV俯视图 上图我是让豆包生成的客厅图片,实际上当3D变成2D的时候,BEV向量里面包含了隐式的高度信息Latent vector,它并不是记录具体的高度,而是通过这个Latent vector可以推理出实际的高度,这样Occupancy才能做3D还原。 这个过程其实和Transformer的Hidden vector训练也非常类似,由于BEV+Occupancy是一个有监督学习,所以在BEV向量里面包含的高度信息是通过训练学习到的,训练是基于Occupancy下游的任务结果进行Loss计算和反向传播,最终让BEV里面的高维向量蕴含准确的高度信息。比如一开始向量就是随机的,模型很可能把1米高的沙发预测成0.5米,然后通过Loss和反向传播不断的训练迭代就可以了,过程理解起来也比较简单,没错,需要标识好的准确训练数据。 我让豆包又生成了一张Occupancy做3D重建的模拟图,Occupancy它是一层一层来预测的,基于BEV的横坐标(X,Y)预测高度Z,但它不是一下子就预测出沙发是1米,凳子是0.5米;相反,Occupany沿着Z轴是一层一层的做二分类预测,比如0.1米的时候,预测空间是被占据还是空白,依次向上。因为很多物体形状是不规则的,比如你预测吊灯和预测沙发是完全相反的,看下面的图7就非常清楚了。 
图 7 Occupancy做3D重建 总结一下,3D重建本质上是 “从2D BEV的隐式线索中,显式地恢复出3D高度维度”。整个过程分为两步: 第二步:级联体素解码器 “显式重建” 高度 此外,论文里还提到了3D重建非常重要的两个核心公式。 3D Deformable Attention(3D-DA) 3D-DA让每个体素只关注自己周围的3D局部区域,高效地从重复的2D信息中 “读” 出高度差异。具体公式如下图8所示。 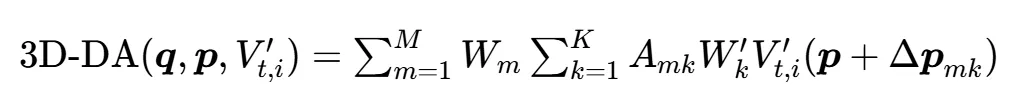
图 8 3D-DA公式 稍微解释一下,在3D-DA里,查询(Query)就是当前这个体素自己的特征向量q,p则是当前查询q对应的那个体素在3D空间里的起点坐标。比如q是“我要找一本关于自动驾驶的书”,而体素特征Vt,i′就对应着每本具体的书,Amk则是注意力权重,意味着你对每本书的喜好程度,也就是相关性。ΔPmk则是模型学到的偏移量,代表“我要往哪个方向、走多远去看别的体素”。 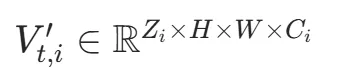
其中,Vt,i′是一个四维张量,Zi代表高度,H和W就是二维的长和宽,Ci是通道数。在一个3D网格里面,每个位置 (z,x,y) 都对应一个Ci维的向量。Ci这个向量编码了“在这个3D位置上,有什么、是什么、状态如何等” 的信息。它的初始值是从2D BEV特征复制而来,经过3D-DA和空间交叉注意力后,逐步分化出高度信息。 所以,3D-DA公式的本质就是加权求和∑(对每个注意力头m,把K个采样点的特征,用注意力权重 Amk 加权求和),把查询q关注的局部信息,聚合到当前体素的特征里,更新这个体素的表示,也就是计算可变注意力。因为3D-DA并不是损失函数,所以不需要求最值的。 简单一句话就是,带着当前体素的“身份”(q),从它的“位置”(p)出发,去周围几个“感兴趣”的位置(p+Δpmk)看看,把看到的信息(Vt,i′)加权融合,更新自己的特征。 此外,关于3D用三线性插值(Trilinear)的方式,在3D空间做扩展,就不在这里细讲了,和2D用双线性插值(Bilinear)的方式类似,感兴趣的同学可以自行研究。Voxel-based Spatial Cross-Attention(体素级空间交叉注意力) 让3D体素特征与多尺度图像特征交互,把图像中的视觉线索(深度、纹理、遮挡)融合到3D体素中,校准高度信息。 简单总结一下,就是3D-DA负责“在3D空间里看”,聚合体素间的上下文;而 Spatial Cross-Attention负责“回看2D图像”,用视觉信息校准3D体素。两者交替工作,逐步把2D BEV特征升级为3D占据描述符。 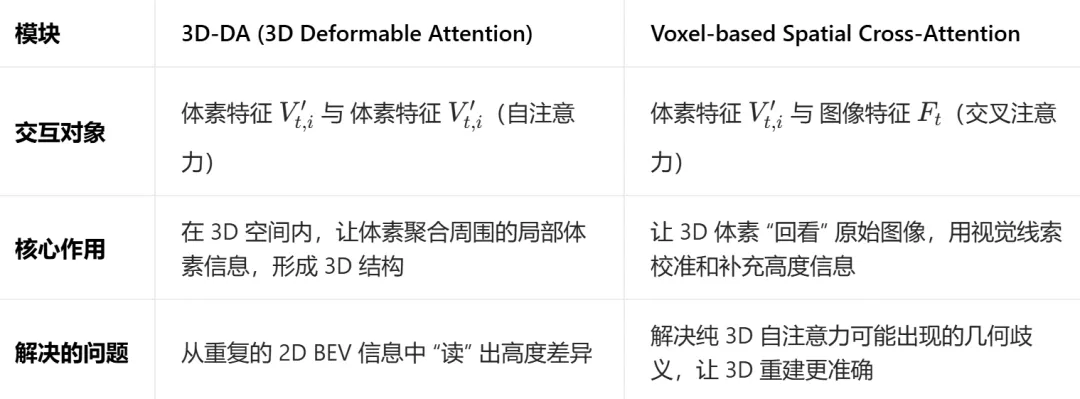
(三)实验数据 论文里的实验数据直接放在这里,供大家参考,总体效果还是非常好的! 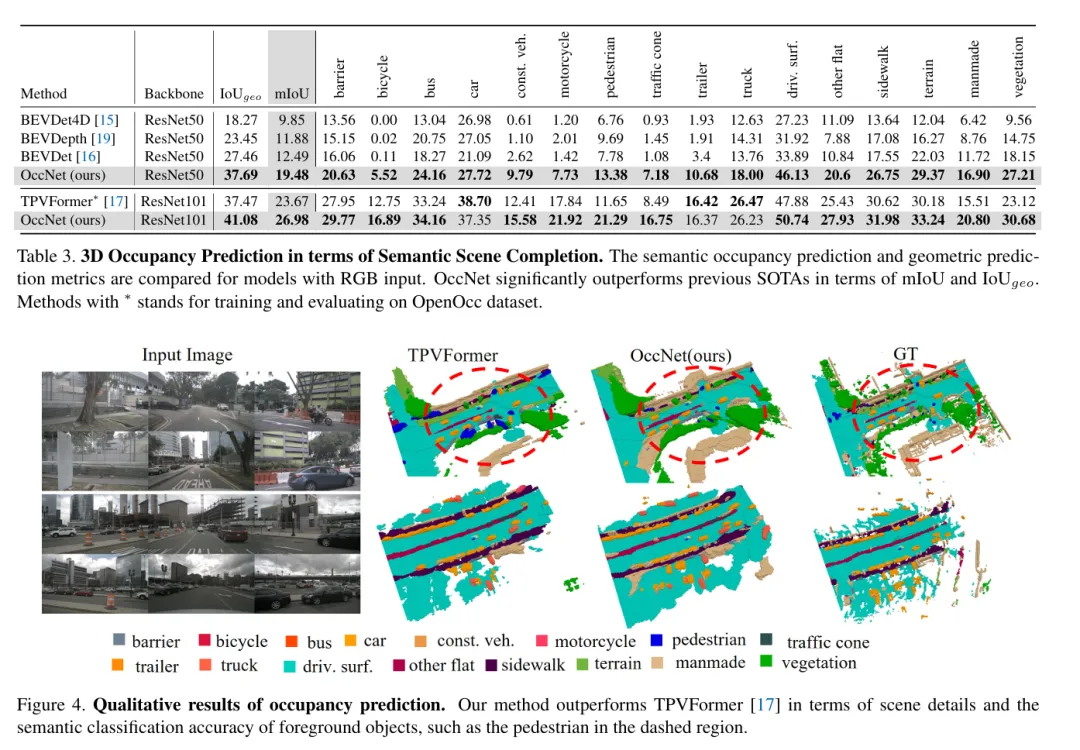
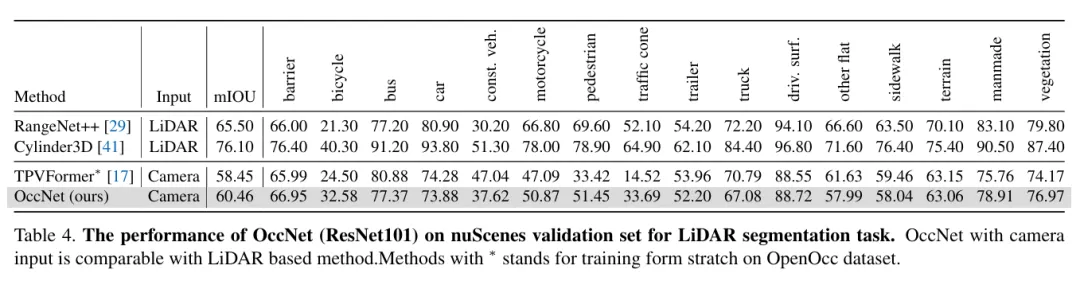
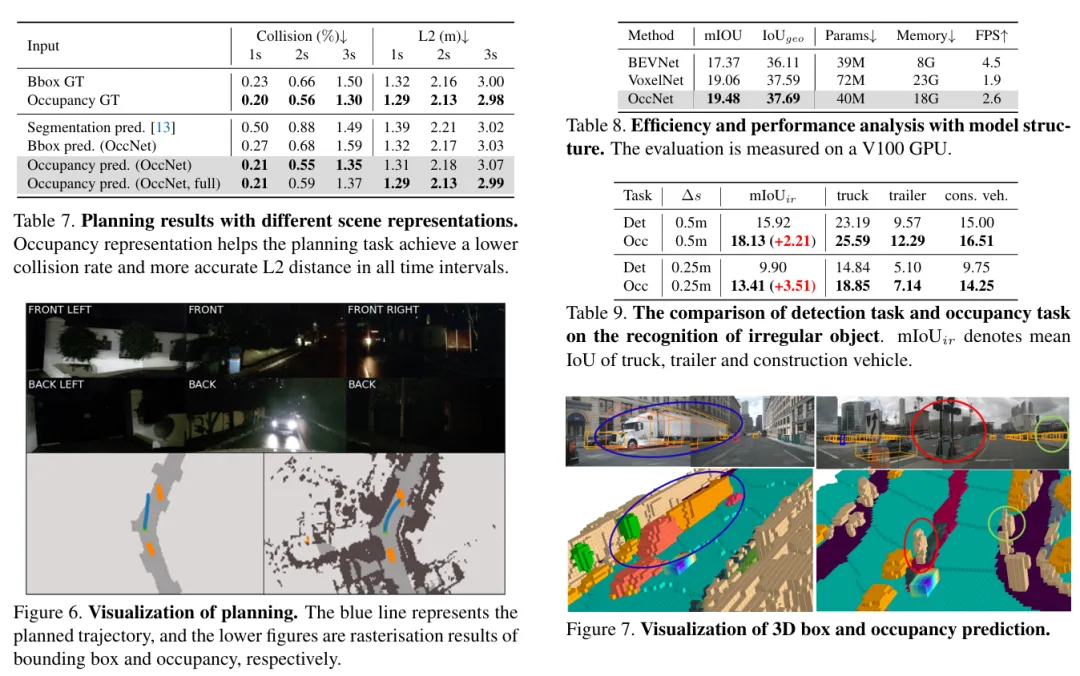
好,Occupancy我们就介绍到这里,接下来的序列三我们将主讲特斯拉FSD,因为FSD从一开始就是纯视觉方案的坚定执行者。 欢迎关注、转发
https://arxiv.org/pdf/2407.05679v1https://arxiv.org/pdf/2306.02851- 输入
多视角图像特征Ft、历史BEV特征Bt−1、当前BEV查询 Qt。 - BEV Encoder
复用BEVFormer的时空Transformer结构,生成当前时刻的统一BEV特征Bt。 - Cascade Voxel Decoder(级联体素解码器)
将BEV特征扩展到3D体素(Voxel: Volume Pixel)空间,通过级联的方式逐步细化体素特征。 引入3D可变形注意力(3D deformable attention),在3D空间中高效聚合局部信息,功能类似2D可变形注意力。 融合历史体素Vt−1,实现时序建模。 - 输出
Occupancy Descriptor(占据描述符),即3D占据栅格,是对驾驶场景的统一物理描述。
- 场景补全(Scene Completion)
补全被遮挡区域的占据信息,形成完整的3D场景。 - 3D 目标检测(3D Object Detection)
基于占据描述符,检测道路上的车辆、行人等目标。 - BEV 分割(BEV Segmentation)
将占据描述符压缩为BEV语义分割图,用于车道线、可行驶区域识别。 - 运动规划(Motion Planning)
直接将BEV分割图或占据描述符送入规划模块,生成安全的行驶轨迹。
第一步:BEV编码器 “埋下” 高度线索
BEVFormer等模型,通过空间交叉注意力,让每个BEV查询去多视角图像里 “找对应位置的像素”。 这些像素的深度、遮挡关系、纹理,都被编码进了BEV特征向量里。 所以,BEV特征向量里,其实已经包含了“这个位置在不同高度上,可能有什么” 的丰富信息,只是这些信息是隐式的、压缩的。
OccNet的Cascade Voxel Decoder,把这些隐式的高度线索 “解压” 出来。 把2D BEV平面上的每个点,在高度方向上“拉成一根柱子”,然后通过3D可变形注意力,去 “读取”BEV特征向量里的高度线索,为每个高度切片填充 “是否被占据” 的置信度。 原来压缩在2D向量里的高度信息,就被显式地重建为3D体素空间。
本文来自网友投稿或网络内容,如有侵犯您的权益请联系我们删除,联系邮箱:wyl860211@qq.com 。

