告别“一步慢步步慢”!端到端自动驾驶新范式 | 让模型自己决定推理步数,20Hz实时丝滑变道
- 2026-03-16 07:33:32

深夜的高速公路上,你的自动驾驶系统正在处理前方车辆突然减速的紧急情况。传统的扩散模型需要上百步“思考”才能给出轨迹,而你的车已经多滑行了十几米——这可能是生死攸关的十几米。
深夜的高速公路上,你的自动驾驶系统正在处理前方车辆突然减速的紧急情况。传统的扩散模型需要上百步“思考”才能给出轨迹,而你的车已经多滑行了十几米——这可能是生死攸关的十几米。
为什么99%的自动驾驶规划模型都陷入了“推理速度”与“规划精度”的二选一困局?读完本文,你将掌握一种让模型自己决定思考深度的革命性方法,在RTX 3070上实现20Hz实时更新,同时保持丝滑的轨迹平滑度。
🔥 开源代码已放出:https://flow-matching-selfdriving.github.io/
❓ 核心痛点:为什么自动驾驶规划总是“慢半拍”?
想象一下这个场景:你在城市道路上行驶,前方十字路口有车辆正在左转。传统的基于规则的规划器需要工程师手动编写“如果对方礼让则通过,否则等待”的逻辑。但随着场景复杂度指数级增长,规则集很快变得臃肿不堪,难以维护。
模仿学习应运而生——直接从海量专家驾驶数据中学习。但这里有个致命矛盾:高质量的生成模型往往需要大量计算,而自动驾驶要求的是毫秒级响应。
扩散模型在机器人操作领域大放异彩,但它需要数百个去噪步骤才能生成一条轨迹。在0.1秒的采样间隔下,这意味着你的车可能已经向前行驶了数米,模型还在“思考”第一步该怎么做。
一致性模型试图解决这个问题,通过精心设计的噪声调度减少步数。但每次调整调度都需要重新训练整个模型——在4块H100 GPU上训练5天,成本高得令人望而却步。
更糟糕的是,这些“一刀切”的固定步数策略完全忽略了场景的多样性:在空旷高速上巡航需要多少“思考”?在拥挤十字路口左转又需要多少?为什么不能让模型根据场景复杂度,自己决定该“想”多深?
这个看似简单的直觉,正是本文方法的核心突破。为了帮你快速把握全局脉络,我们先看这张核心架构思维导图——
接下来,我们逐层拆解这张图中的每个关键模块,看看它是如何实现“智能分配计算资源”这一革命性设计的。
🚀 原理拆解:让模型学会“该想多想少”
💡 流匹配:从“逐步去噪”到“直接导航”
传统扩散模型像是在迷雾中摸索:先加满噪声,再一步步去噪还原。流匹配(Flow Matching)则完全不同——它训练一个神经网络直接学习从噪声到数据的“导航路径”。
具体来说,给定一个从标准高斯分布采样的噪声点 和真实轨迹数据点 ,流匹配训练一个速度场网络 ,让它能预测从 到 的“最佳行驶方向”。
在时间 上,我们构建插值状态:
目标速度就是 。网络的任务很简单:给定 、时间 和场景上下文 ,预测这个目标速度。
训练完成后,推理时只需要从 积分到 :
这个设计的精妙之处在于:积分步数可以灵活调整。简单场景可以用大步长快速“跳跃”,复杂场景可以用小步长精细“踱步”。但问题来了——谁来决定什么时候用大步长,什么时候用小步长?
💡 方差估计器:模型的“自信度传感器”
这就是本文最核心的创新:一个轻量级的方差估计器。
这个前馈神经网络只有4层,隐藏维度512,使用SiLU激活函数。它接收U-Net瓶颈层的特征,输出一个标量——模型在当前状态下的预测方差。
方差高意味着什么?意味着模型“心里没底”,可能是遇到了训练数据中罕见的场景组合。方差低则意味着模型“胸有成竹”,类似场景在训练集中大量出现。
训练时,作者采用了一种联合优化策略:
这个损失函数的设计堪称艺术:第一项让速度预测尽可能准确,但除以预测的方差——如果方差大,即使预测误差大,惩罚也会减小;第二项是对数项,防止方差无限增大(正则化作用)。
最终的总损失是编码器损失和流匹配损失的加权组合:
💡 自适应时间步长:动态分配计算资源
推理时的步长选择变得极其简单:
其中 是调节常数, 是最小步长。
这意味着什么? 当模型自信(方差小)时, 小, 大,步长就大——快速通过。当模型不自信(方差大)时,步长自动变小——慢慢思考。
这个设计彻底消除了手动调整噪声调度的需求。在Waymo开放运动数据集上,自适应模型平均只需要4.7步函数评估(NFE),就能达到与固定50步方法相当的性能!
💡 实战思考:你在实际项目中是否也遇到过“简单场景过度计算,复杂场景计算不足”的问题?欢迎在评论区分享你的经历~
💡 场景编码:理解复杂的交通世界
方法的前端是一个强大的场景编码器,基于Motion Transformer架构。它需要处理四类输入:
1. 自车历史:过去1秒(10步)的轨迹 2. 周围Agent:距离自车10米内的最近5个Agent的历史 3. 高精地图:表示为多段线张量 4. 目标位姿:规划结束时的期望位置
每个Agent的状态是4维:。编码器通过MLP和Transformer层融合这些信息,输出一个固定的上下文向量 ,作为流匹配的条件输入。
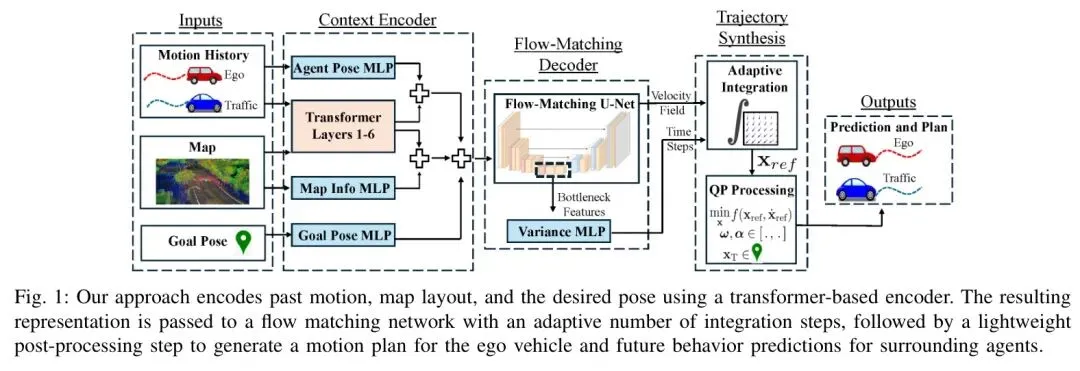
💡 轻量级后处理:1毫秒的“轨迹美容师”
即使是最好的生成模型,输出也可能有微小瑕疵——急转弯、加速度突变、最终位置偏差。这些在仿真中可能只是数字,在真实车辆上就是乘客的晕车体验。
作者引入了一个计算开销几乎为零的后处理步骤,构建为凸二次规划(QP)问题。
首先定义关键的运动学量。给定离散位置 ,线速度和加速度:
横向加速度 和角速度 计算如下:
问题在于这些约束对位置有双线性依赖,是非凸的。作者的技巧是:围绕流匹配输出轨迹线性化,得到仿射近似,然后用松弛变量处理约束违反。
优化目标包含四项:
1. 轨迹跟踪:尽量接近原始流匹配输出 2. 目标达成:最终位置靠近指定目标 3. 运动平滑:相邻点间速度变化平缓 4. 约束惩罚:对违反加速度、角速度、目标约束的行为进行惩罚
使用OSQP求解器,每条轨迹的求解时间仅约1毫秒——相比45毫秒的总推理时间,这个开销几乎可以忽略不计。
📊 实验验证:数据不会说谎
🏆 SOTA对比:全面碾压传统方法
作者在Waymo开放运动数据集(WOMD)上进行了全面评估,对比了Transformer、扩散模型(DDPM、DDIM)、一致性模型以及本文方法的各种变体。
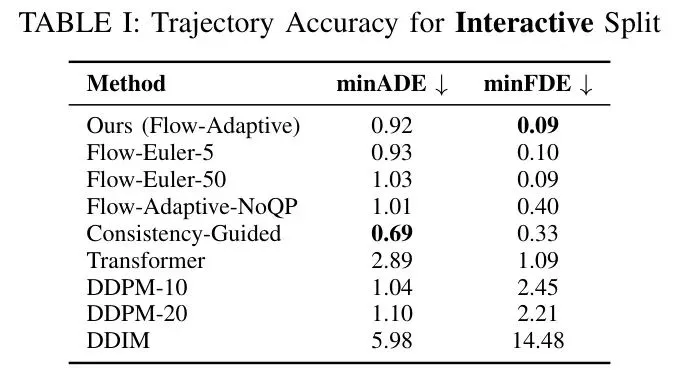
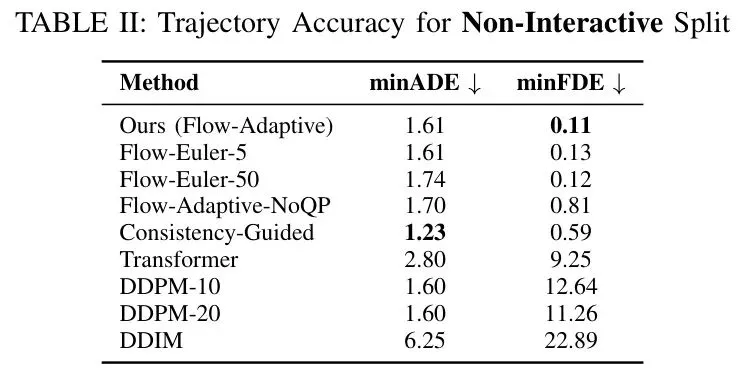
最震撼的结果:在最终位移误差(minFDE)上,本文方法达到0.11米,接近目标容差0.1米——这意味着模型几乎总能精确到达指定位置。
与一致性模型相比,虽然平均位移误差(minADE)略高0.01米,但这反映了一个重要权衡:后处理步骤为了满足约束(如舒适性、目标达成),可能会让轨迹稍微偏离“最像专家”的路径,但换来了更好的乘坐体验和安全性。
🔬 消融实验:每个组件都不可或缺

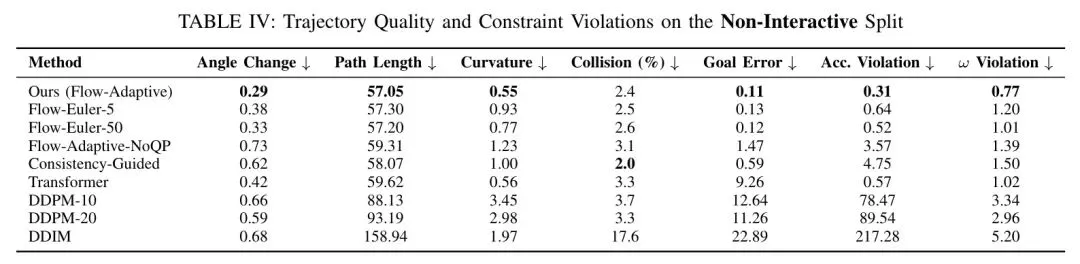
看看这些数据:
• 角度变化:比最佳baseline减少15%——转向更平顺 • 路径长度:更接近最优路径——不走冤枉路 • 平均曲率:降低20%——减少急转弯 • 约束违反:加速度和角速度违反次数大幅减少
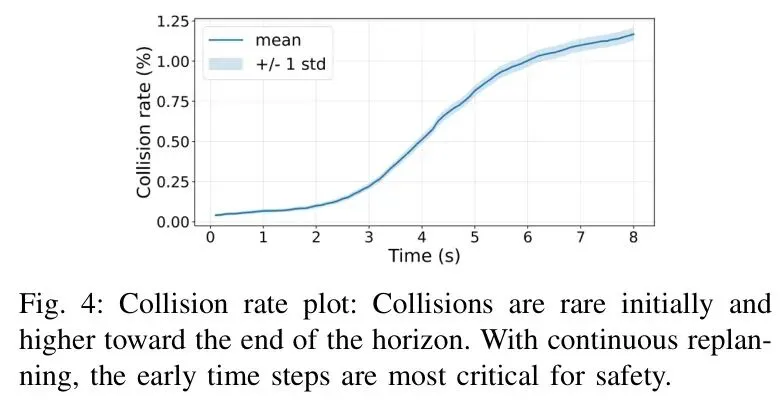
唯一的“短板”是碰撞率,与最佳baseline持平。但仔细分析图4会发现,大多数碰撞发生在规划时域的后期(7-8秒),而实际部署中规划器会持续重新规划,早期安全性才是关键。
⚡ 推理时间:20Hz的实时性能
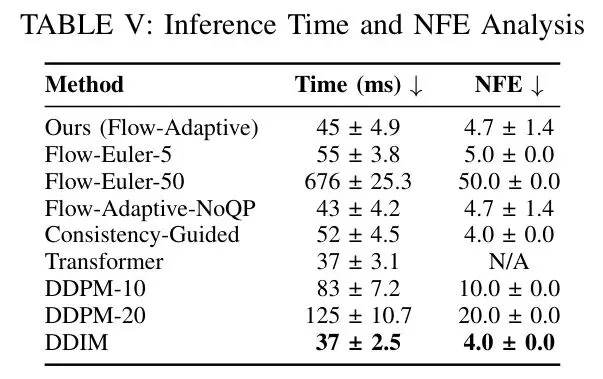
平均45毫秒,对应20Hz更新频率——这在NVIDIA RTX 3070上实现,意味着即使在中端硬件上也能实时部署。
虽然DDIM更快(37毫秒),但它的轨迹质量和约束满足度远不如本文方法。而固定50步的流匹配方法虽然性能相当,但NFE是自适应的10倍以上,计算成本显著更高。
最有趣的是自适应步长的分布分析:
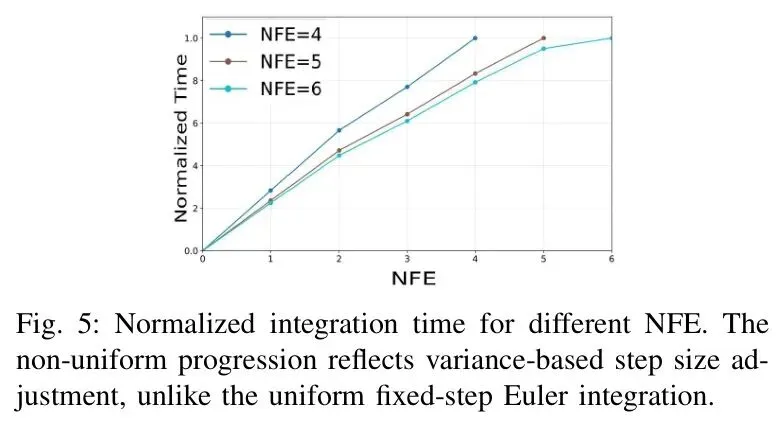
可以看到步长并不均匀——模型在“熟悉”的区域用大步长快速通过,在“陌生”的区域用小步长仔细思考。这种动态资源分配正是智能的体现。
💡 深度思考:如果让你来设计,你会如何进一步优化这个自适应机制?是加入更多先验知识,还是让模型学习更复杂的步长策略?
⚖️ 客观评价:优势与局限并存
🎯 核心优势
1. 实时性能:20Hz更新频率,满足自动驾驶严苛的实时性要求 2. 自适应计算:根据场景复杂度动态分配计算资源,效率最大化 3. 端到端优化:从感知到规划一体化,避免模块间误差累积 4. 轻量后处理:1毫秒的QP优化,显著提升乘坐舒适性
⚠️ 当前局限
1. 地图依赖:仍需高精地图的折线表示,限制了泛化能力 2. 开环评估:实验在开环设置下进行,闭环性能有待验证 3. 避障简化:碰撞避免主要依赖数据驱动,未作为显式约束
🚀 未来方向
作者已经规划了清晰的演进路径:
• 视觉替代:用原始LiDAR/相机数据替代地图编码器 • 闭环测试:在MetaDrive等仿真环境中验证 • 硬件部署:向真实车辆平台迁移
🌟 价值升华:为什么这代表了自动驾驶规划的未来?
这项工作的意义远不止于论文中的几个百分点提升。它代表了一种范式转变:从“固定计算预算”到“按需分配计算”。
在自动驾驶这个对安全性和实时性要求都达到极致的领域,这种自适应能力可能是打破当前瓶颈的关键。想象一下:
• 高速巡航:模型自信满满,大步向前,节省算力 • 复杂路口:模型谨慎小心,小步探索,确保安全 • 突发状况:模型立即调整步长,快速响应
这种“能屈能伸”的智能,正是我们在复杂现实世界中驾驶时所展现的——简单路况下意识驾驶,复杂情况全神贯注。
🤔 深度思考:你认为这项自适应技术最可能率先在哪个自动驾驶场景落地?是城市Robotaxi、高速货运,还是矿区/港口等封闭场景?欢迎在评论区留下你的观点!
💝 支持原创:如果本文帮你理解了这项前沿技术,点赞+在看就是最好的支持!分享给你的技术伙伴,一起探讨自动驾驶的未来!
🔔 关注提醒:设为星标,第一时间获取更多深度技术解读!
#AI技术 #自动驾驶 #运动规划 #流匹配 #实时系统 #技术干货
参考
Adaptive Time Step Flow Matching for Autonomous Driving Motion Planning
随机文章
-
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
- 跳过L3直奔L4:何小鹏戳破了自动驾驶的哪层窗户纸?
- 女市委书记的轿车路上被拦:我是市委书记!纪委办案人员:查的就是你
- 方程豹首款轿车最新谍照曝光或将共享腾势Z三电技术
- 日产全新纯电轿车首次曝光
- SUV和轿车怎么选?看完这5个场景对比不再纠结
- 代号M900,尊界首款SUV正式曝光
- 1月SUV销量榜,小米干到第一,吉利博越L空降第二,油车杀回来了?
- 吉利终于绷不住了,全新方盒子SUV曝光,尺寸比钛7大,配置比钛7高,价格比钛7便宜,比亚迪怕不怕?
- 大众历史最大尺寸SUV,跟理想L9、问界M9一个级别,400公里纯电续航,增程器是摆设?
- 标配巡航+大屏太厚道!7.38万起小型SUV,颜值在线配置拉满
