自动驾驶算法该跳槽具身智能了
- 2026-03-16 23:51:48

自动驾驶面临交通规则、部署成本和政策法规的约束,加上车企的严重内卷,自动驾驶的研发活跃程度无论是高校还是企业都已大幅下滑,远远低于具身智能领域,自动驾驶跳槽具身智能领域根本不需要学习时间,二者高度相通,特别是VLA。
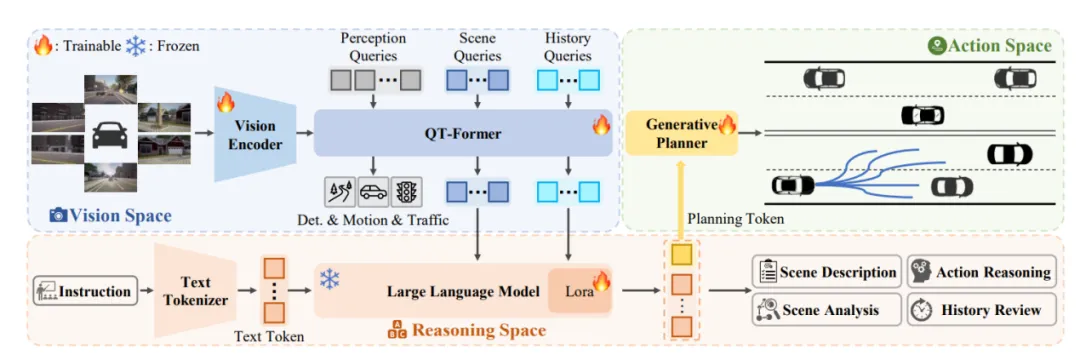
具身智能VLA框架
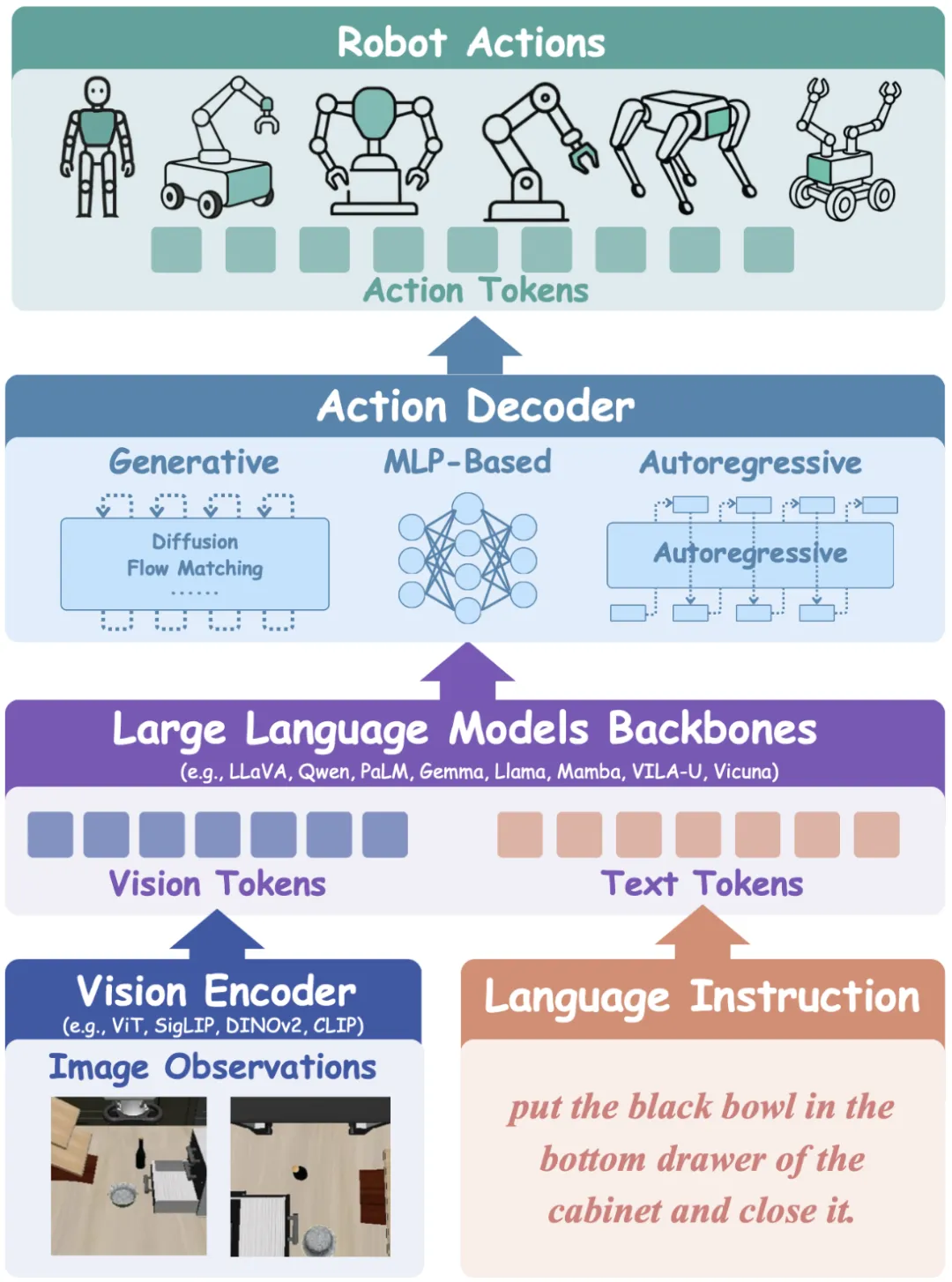
图片来源:论文《A Survey on Efficient Vision-Language-Action Models》
典型自动驾驶VLA之博世DiffVLA框架
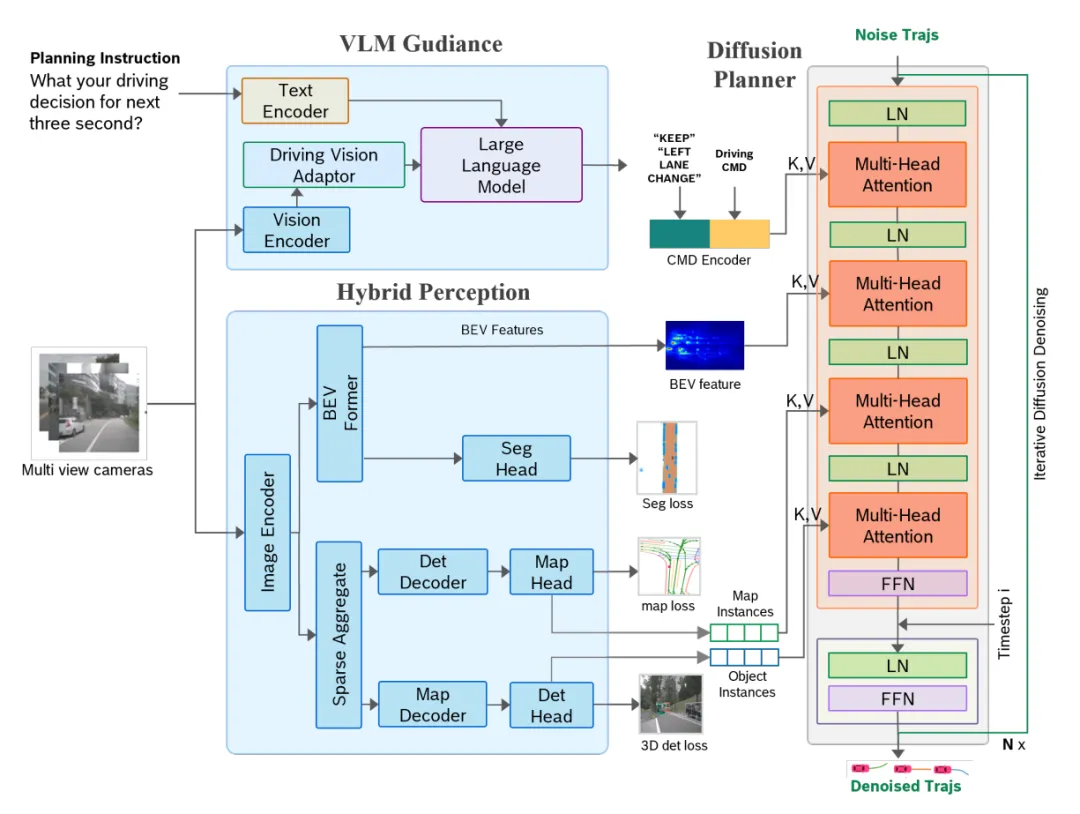
图片来源:论文《DiffVLA: Vision-Language Guided Diffusion Planning for Autonomous Driving》
博世DiffVLA可能是国内最强的一段式VLA,用于奇瑞星纪元ES上。
VLA的基础流程将多模态推理划分为三个协同模块:
① 视觉编码器将场景图像编码为图像块嵌入;
② 增强以支持视觉-语言融合的LLM骨干网络负责高层次推理;
③ 动作解码器生成精确的控制轨迹。通过利用预训练模型,VLA打破任务孤岛,构建可扩展的、擅长长时程操控的智能体。这个智能体可以是机器人也可以是自动驾驶。
自动驾驶VLA相比具身智能VLA要复杂很多,自动驾驶要考虑安全和交通规则,通常自动驾驶是双系统,系统一是响应速度比较快的传统算法,系统二是响应速度比较慢的VLM+ Action Expert,这与具身智能VLA不同,具身智能是VLM+Action Expert,其中VLM是大脑,Action Expert是小脑,但在自动驾驶领域,系统一是小脑,系统二是大脑。
视觉编码器:具身智能VLA在输入阶段,视觉编码器接收RGB观测数据并提取其层次化特征。主流选择包括ViT、SigLIP、DINOv2和CLIP等视觉Transformer,这些模型在大规模语料上进行的对比学习或自监督预训练赋予其零样本泛化能力。抽象来看,该模块将原始图像映射为语义标记。
LLM骨干网络:投影器Project确保无缝对齐并弥合模态差距,多模态序列输入至LLM即语义推理的核心。涵盖LLaVA、Qwen、PaLM、Gemma、Llama、Mamba、VILA-U和Vicuna等预训练LLM处理融合后的嵌入以进行任务规划。
动作解码器:作为流程的最终环节,动作解码器将潜在变量转换为机器人可用的输出,例如末端执行器位姿和夹爪指令。常见实现包括扩散模型/流匹配用于轨迹的随机细化、自回归解码用于序列动作预测,以及基于MLP的轻量级架构。
最强自动驾驶VLA之一:AutoVLA框架图
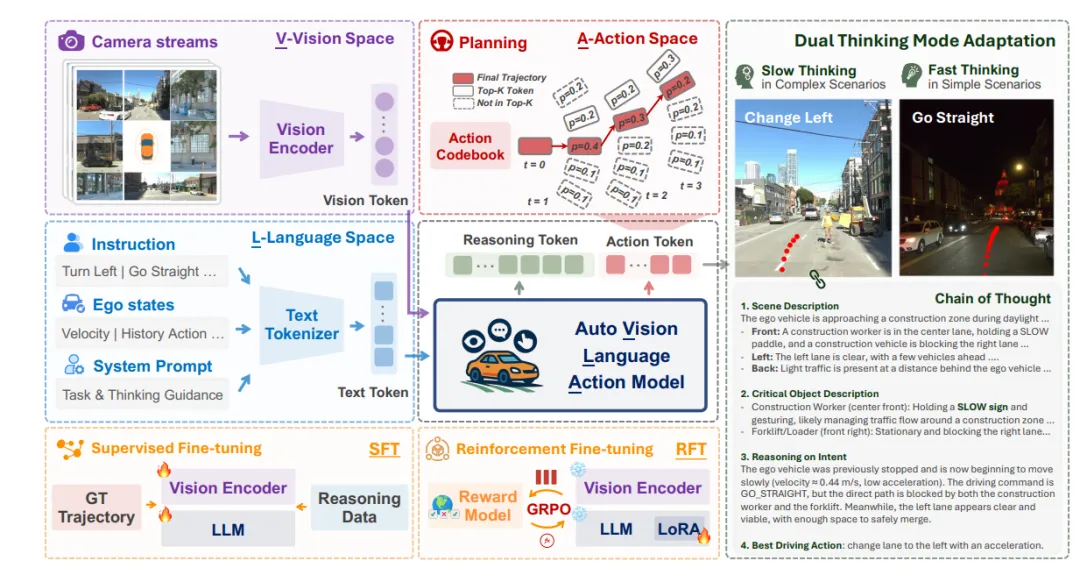
图片来源:论文《AutoVLA: A Vision-Language-Action Model for End-to-End Autonomous Driving with Adaptive Reasoning and Reinforcement Fine-Tuning》
自动驾驶VLA则不同,主流做法是使用传统CNN架构提取2D特征,然后转换为鸟瞰BEV特征的视觉编码,也有少数直接输入图像,将图像转换为嵌入式token。同时自动驾驶VLA还要输入驾驶指令、自身状态和系统Prompt。
最强自动驾驶VLA之一:OpenDriveVLA框架图
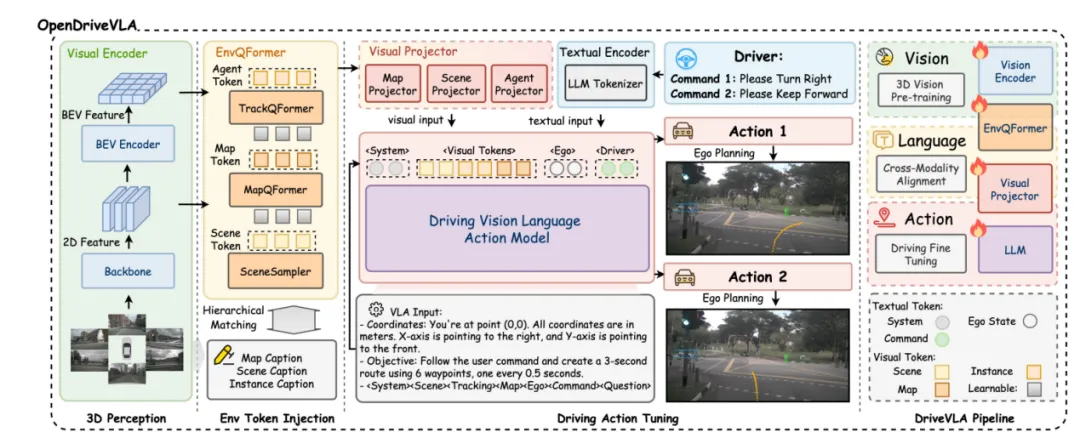
图片来源:论文《OpenDriveVLA: Towards End-to-end Autonomous Driving with Large Vision Language Action Model》
最强自动驾驶VLA之一:ORION框架图
图片来源:论文《ORION: A Holistic End-to-End Autonomous Driving Framework by Vision-Language Instructed Action Generation》
自动驾驶和具身智能不同之处是自动驾驶要考虑历史状态对下一状态的影响,因此要加入历史序列查询Queries,比如小米的ORION就是如此,OpenDriveVLA也是如此,即Scene Token。
自动驾驶另一个重大不同是自动驾驶考虑地图和交通规则,这便需要加入一个Map地图Head,绝大部分交通规则都是基于地图或与地图高度关联,如车道线、红绿灯等,所以地图Head包含了对交通规则的描述,这也是特斯拉FSD最缺的。
机器人领域的VLA开山之作RT-2框架
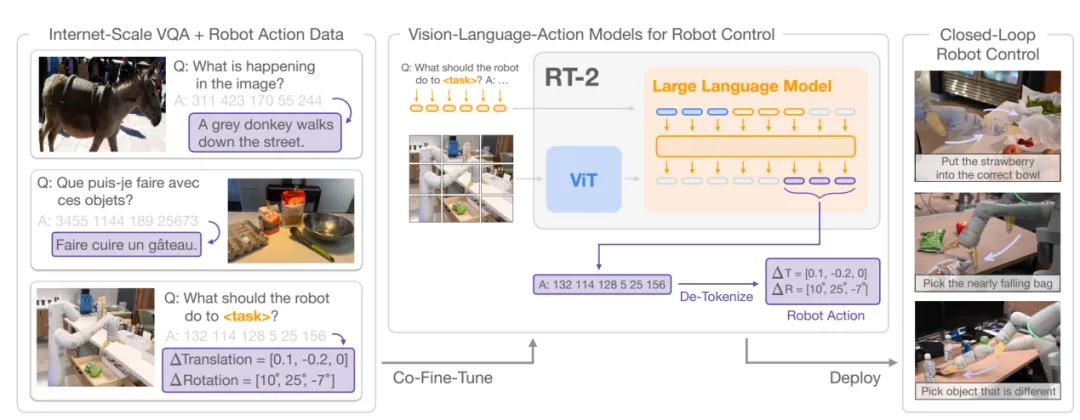
图片来源:论文《RT-2: Vision-Language-Action Models Transfer Web Knowledge to Robotic Control》

自动驾驶的动作解码器与具身智能最大不同之处是自动驾驶是输出一系列waypoint坐标值轨迹,而具身智能输出的是平移坐标和旋转角度。自动驾驶可以输出多条waypoint坐标轨迹供选择,因为这样更接近人类驾驶,具身智能通常则只有一条轨迹值,这也是自动驾驶的难点。具身智能的难点是灵巧手的力矩,针对不同的动作任务,需要的力矩是不同的,如果是个纸杯,不能用太高的力矩,如果是要拿起重物,那就需要很高的力矩。
Hydra-MDP++架构
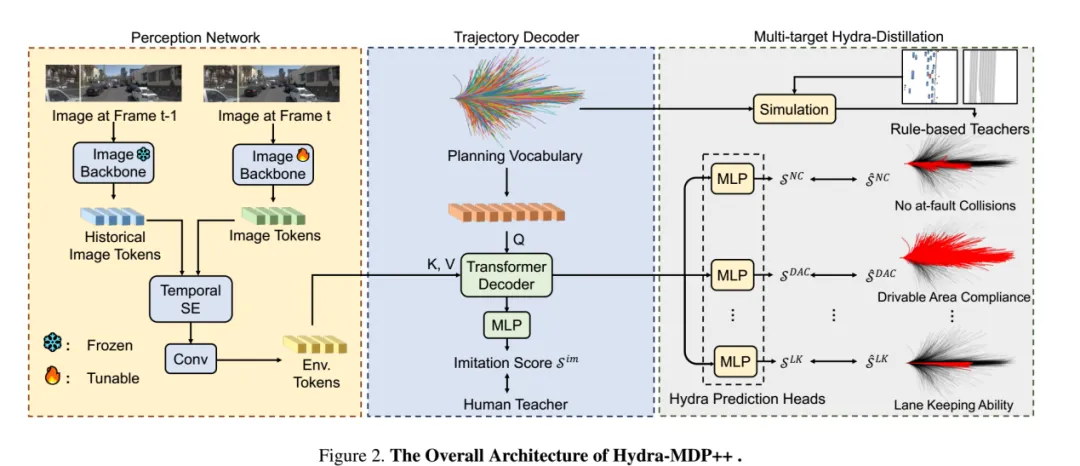
图片来源:英伟达
Hydra-MDP++不是VLA,可以看做传统端到端,核心在于后段的轨迹词汇表,英伟达构建了一个固定的规划词汇表planning vocabulary来离散化连续的动作空间。为了构建词汇表,英伟达首先从原始的nuPlan数据库中随机抽取了700K条轨迹。每条轨迹Ti(i = 1,..., k)由40个时间戳的(x, y, heading)组成,对应于挑战中所需的10Hz频率和4秒的未来时间范围。规划词汇表Vk是通过700K条轨迹的K-means聚类中心形成的,其中k表示词汇表的大小。然后,Vk被嵌入为k个潜在查询,通过多层感知机(MLP)发送到转换器编码器层,并添加到自身状态E中。
自动驾驶的Action Expert多用扩散模型或MLP,MLP参数量很低,消耗运算资源很少,具身智能更喜欢DiT和流匹配。流匹配(FM,Flow Matching))适用于一类通用的高斯概率路径,可实现噪声与数据样本间的转换----这类路径将现有扩散路径纳入其中,作为特殊实例。将流匹配与扩散路径结合使用,能为扩散模型训练提供一种更稳健、更稳定的替代方案。此外,流匹配为采用其他非扩散概率路径训练连续归一流开辟了道路。
一个尤其值得关注的实例是利用最优传输位移插值来定义条件概率路径。这些路径比扩散路径效率更高,能实现更快的训练与采样,并且可带来更优的泛化性能。通过流匹配方法训练条件归一化流,无论是在似然值还是样本质量方面,其性能都持续优于其他基于扩散的方法;借助现有的数值常微分方程求解器,该方法还能实现快速且稳定的样本生成。
扩散模型其实是流模型的一种特例。
具身智能核心
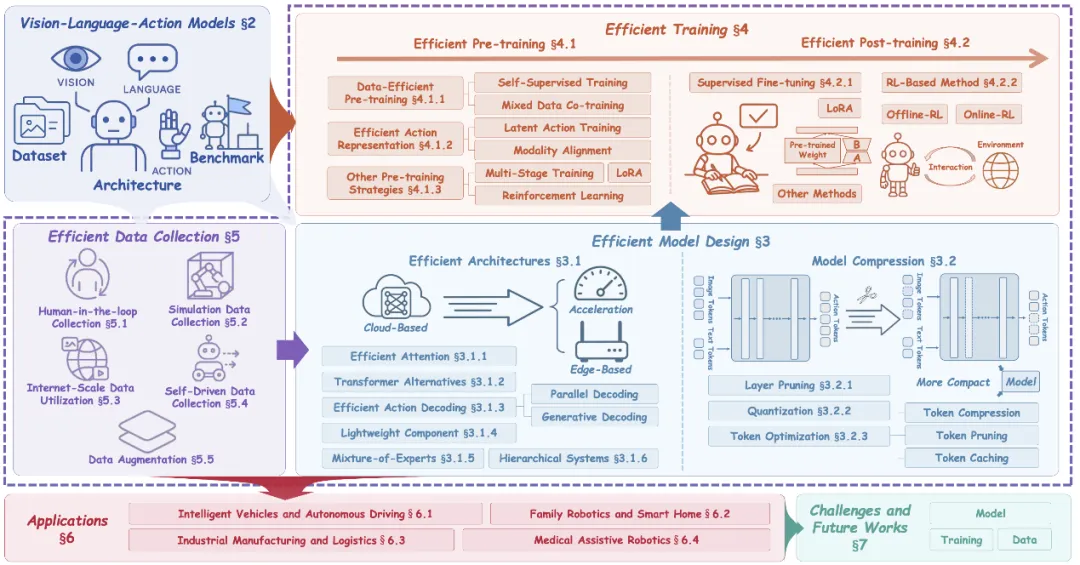
图片来源:论文《A Survey on Efficient Vision-Language-Action Models》
VLM以及BEV骨干网一般都采用成熟的模型,具身智能将重点首先放在预训练Pre-training上,自动驾驶则更着重后训练Post-training上,VLM通常都冻结参数。具身智能更着重训练数据,自动驾驶的车企通常都累积了足够多的训练数据,最后才是模型设计。

图片来源:小米机器人
以小米的Xiaomi-Robotics-0和字节的GR3为例,
两款模型均采用预训练视觉-语言模型(VLM)+ 扩散 Transformer(DiT) 的混合架构设计:以工业级预训练 VLM 为基础处理视觉和语言输入,提取多模态特征;以 DiT 为动作生成模块,通过流匹配(flow-matching)算法生成连续的动作块(action chunk),实现端到端的动作预测。同时,二者均通过联合训练 VLM 数据与机器人轨迹数据,避免模型在动作学习中丢失视觉 - 语言的基础语义能力。
二者均摒弃单一的机器人轨迹数据训练方式,采用多源数据融合的训练策略:同时利用大规模通用视觉-语言数据(保留语义知识)、跨载体机器人轨迹数据(提升动作生成能力),字节GR-3 还进一步融入了人类 VR 轨迹数据(实现少样本快速适配),小米则针对特定任务收集了大规模自研遥操作轨迹数据(提升细分任务性能),均通过数据多样性解决泛化性不足的问题。
自动驾驶则不同,一般是加入世界模型生成数据训练VLA,自动驾驶的动作规划时程一般较长,而具身智能较短,主流VLA 架构中仍然存在一个根本性的局限:它们在长时程动作规划中对短视观测的过于依赖,这一缺陷源于体系结构在设计上偏向于反应式控制,而非前瞻性规划;相反,在大规模视频语料库上训练的基础世界模型已经展示出在预测合理未来状态方面的非凡能力,这类预测先验为赋予VLA 前瞻能力提供了一条途径。所以自动驾驶领域更重视世界模型加入的预训练,而具身智能对世界模型兴趣度比较低。
预训练是在无标签的大规模数据上训练模型,学习语言的通用模式和知识(如语法、语义、常识)。预训练的成果一般是LLM或VLM,具身智能与自动驾驶不同,它需要加入很多机器人真人遥控轨迹视频数据,而自动驾驶基本不怎么干预预训练,自动驾驶VLA的主要工作是后训练,即SFT+RL,SFT(Supervised Fine-Tuning,监督微调)。
IRL-VLA 架构,用强化学习和世界模型来增强VLA
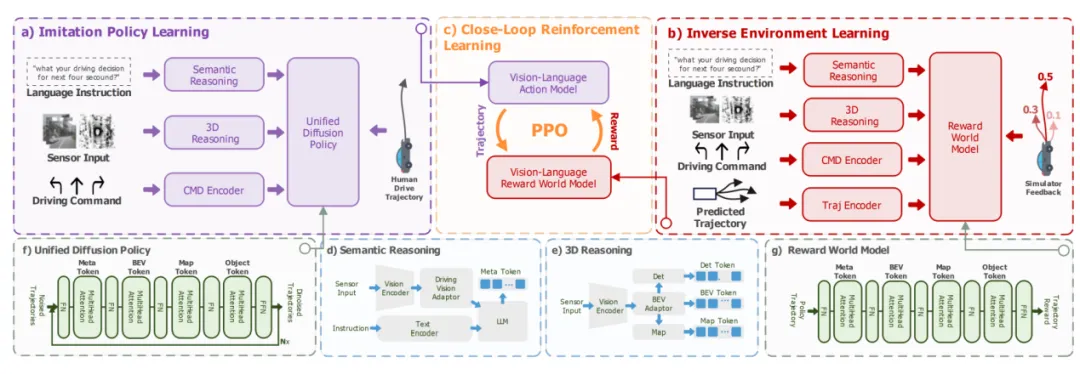
图片来源:论文《IRL-VLA: Training an Vision-Language-Action Policy via Reward World Model for End-to-End Autonomous Driving》
在预训练模型基础上,使用高质量标注数据(指令-答案对)微调模型,使其适应特定任务。对齐人类指令意图,提升任务执行能力。可采用全参数微调或参数高效方法(如LoRA、P-tuning),仅更新部分权重。RL即强化学习,通过奖励机制引导模型优化策略,使其生成更符合人类偏好的输出。核心目标:突破SFT的机械模仿,提升创造性、安全性和价值观对齐。SFT是RL的起点,人类标注员对模型输出排序,训练RM预测回答质量(如安全性、有用性)。模型生成多样回答 → RM打分 → 调整策略以最大化奖励,即PPO (Proximal Policy Optimization)算法。
具身智能领域的后训练比较少,也较少用RL,因为具身智能绝大部分是基于仿真训练的,这种方式的RL很有可能是不够真实。以小米的Xiaomi-Robotics-0。采用两阶段预训练 + 专项后训练的解耦方式:第一阶段训练 VLM,使其具备动作预测能力,同时联合视觉-语言数据训练,避免灾难性遗忘;第二阶段冻结 VLM,仅训练 DiT,以 VLM 的 KV 缓存为条件生成动作,彻底避免 DiT 的训练梯度对 VLM 的视觉-语言特征造成干扰。后训练阶段则针对特定机器人,单独优化DiT的异步执行能力。
具身智能VLA非常依赖数据,特别是真实数据,自动驾驶对数据的敏感度远低于具身智能,网络无标注车辆行驶轨迹视频是海量的,几乎没有成本。世界模型则可以生成长尾视频。
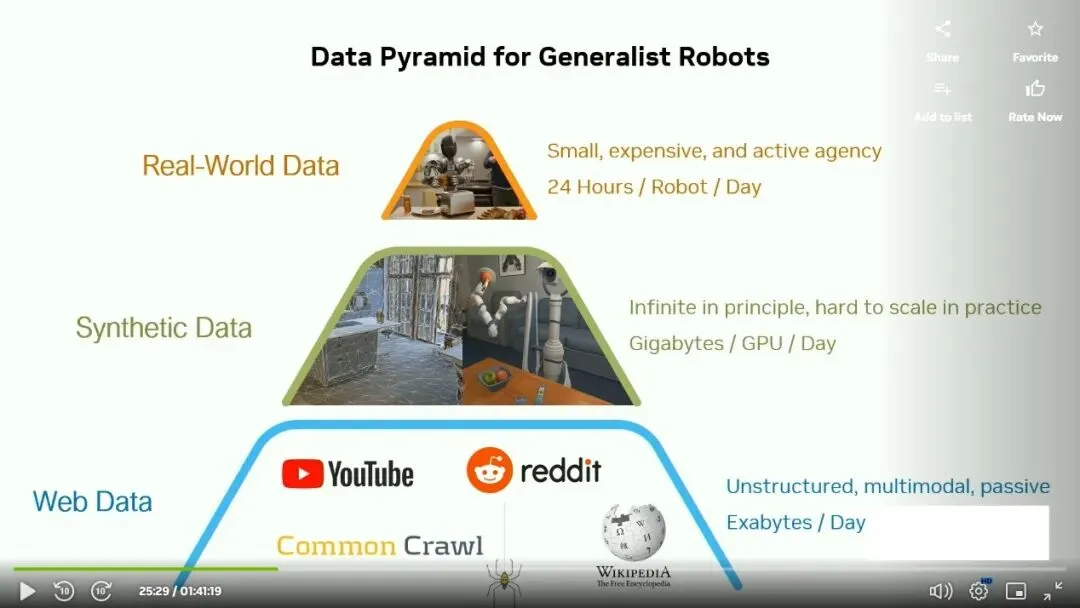
上图是英伟达GTC2025大会An Introduction to Building Humanoid Robots演讲截图,数据分真实世界、合成数据和网络数据三大类。需要指出这里的网络数据主要是用来训练VLM或LLM,具身智能企业都是直接采用大型科技公司的VLM或LLM,如阿里的Qwen或谷歌的Gemma,也有使用人类示范视频数据,但这类数据缺点明显,首先是在重建状态 s 和动作 a 时存在巨大的时间差距,难以建立强关联。其次动作必须完全从原始数据中推断,通常需要借助其他模型进行伪标注(例如人体骨骼追踪、手部追踪),这可能比真实机器人数据成本还要高。最后人类会通过身体前倾、重心转移、伸展身体来完成动作,人类的自由度远超顶级机器人。对具身智能企业来说,真实机器人数据是最有价值的。
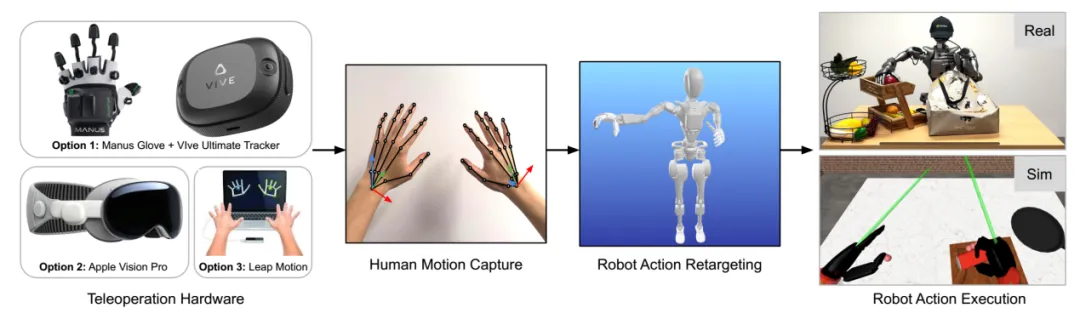
图片来源:英伟达
英伟达GR00T-N1真实数据集搜集使用遥控或VR设备由人工完成,有88小时,成本非常高昂,且缺乏可扩展性。
大名鼎鼎的PI0.5则是直接用移动机械臂在真实家庭中采集的中等规模数据集(约400小时)。
PI0.5的预训练和后训练

图片来源:物理智能
数据包括Diverse Mobile Manipulator data (MM),约400小时的移动机械臂数据,涵盖了约100个不同家庭环境中的家务任务,是最核心数据。Diverse Multi-Environment non-mobile robot data (ME)是非移动机器人的数据,这些机器人可能是单臂或双臂,被固定在桌面或其他平台上。Cross-Embodiment laboratory data (CE)跨形态实验室数据,涵盖多种任务(如收拾餐具、叠衣服等)的数据,环境更为简单,机器人类型多样,包括单臂、双臂、静态和移动底座。有些任务与评测高度相关(如将餐具放入收纳箱),有些则无关(如研磨咖啡豆)。此外还包含了开源 OXE 数据集。Multi-modal Web Data (WD)引入了多样化的网络数据,包括图像描述、问答和目标定位等任务。目标定位部分还扩展了标准数据集,补充了更多室内场景和家庭物体的边界框标注。
目前,具身智能主流是给大模型加上动作模块,然后疯狂投喂机器人拟合真机或者仿真得到的末端轨迹数据,让模型去拟合「观测→动作」的映射。最大缺点是单纯的动作拟合不仅无法产生对物理规律的直觉,还会破坏大模型本身强大的通用理解能力,导致严重的灾难性遗忘。目前的AI有个致命缺陷,那就是文字、语言和视频很容易token化,但密度、刚度、触感、嗅觉、听觉等等物理信息难以token化,或者不适合目前的token化,这让具身智能很难具备物理直觉。
自动驾驶领域的VLA在模型设计、监督微调和强化学习领域比具身智能要高一个层次,具身智能的VLA则面临如何获得物理直觉的能力,其泛化能力和长时程规划能力欠缺。
免责说明:本文观点和数据仅供参考,和实际情况可能存在偏差。本文不构成投资建议,文中所有观点、数据仅代表笔者立场,不具有任何指导、投资和决策意见。
更多报告
| AI机器人 | ||
AI机器人 | ||
| 云端和AI | ||
| 车云 | ||
| 动力层 | ||
| 动力 | 混合动力报告 | |
| 800-1000V高压平台 | 电驱动与动力域研究 | |
热管理 | ||
其他 |
| 电子电气架构层 | ||
| E/E架构框架 | E/E架构 | 汽车电子代工 |
| 48V低压供电网络 | ||
| 智驾域 | 自动驾驶SoC | |
| 座舱域 | 座舱域控 | |
| 车控域 | 车身(区)域控研究 | |
| 通信/网络域 | ||
| 跨域融合 | ||
| 其他芯片 | ||
| 车载存储芯片 |
| 智舱系统集成和应用层 | ||
智能座舱应用框架 | 座舱设计趋势 | |
自动驾驶算法和系统 |
| OS和支撑层 | ||
| SDV框架 | SDV:软件定义汽车 | |
信息安全/功能安全 |
| 其他宏观 | ||
| 车型平台 | 车企模块化平台 | |
| 政策、标准、准入 | 智能辅助驾驶法规和汽车出海 |
「AI与机器人月报」

「联系方式」
手机号同微信号

产业研究部丨赵先生 18702148304
推广传播部|杜先生 13910162318
随机文章
-
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
- 7.98万,一汽纯电SUV,正式上市
- 丰田造了一辆家用全能 SUV!250 马力混动、油耗 4.7L、标配 L2 智驾,却只卖 15.28W
- 谁还买本田缤智!丰田小型家用 SUV 来了!混动性能配置拉满,终端低至 13.58W 起
- 丰田降维打击了!硬派越野 SUV 3.5T+650 牛米、标配全时四驱、三把锁,可加 92 油仅售 82.98W 起
- 自动驾驶泡沫最后的赢家,小马智行用利润血洗同行
- 丰田又成功了!全尺寸硬派 SUV 只售 98.8W 起,31 天北美狂卖 12600 辆,3.4T 混动 + 全地形适配家用越野两不误
- 近2亿!欧卡智舶刷新中国民用水面自动驾驶最大单笔融资纪录
- 自动驾驶强标征意见、固态电池密集上车,2026汽车科技双线爆破
- 谁还买大众途昂!丰田 7 座家用 SUV 来了,248kW 混动、油耗 5.5L,终端低至 22.08W
- 谁还买本田 CR-V!领克运动 SUV 来了!254 马力 + 8AT 变速箱配置拉满,终端低至 21.98W
