(本文整理来自2024 IEEE 32nd International Requirements Engineering Conference (RE)论文:Engineering_Safety_Requirements_for_Autonomous_Driving_with_Large_Language_Models原作者:Ali Nouri,Beatriz Cabrero-Daniel,Fredrik Torner)概览:本研究由沃尔沃等机构团队开展,聚焦自动驾驶(AD) 领域的安全需求工程,以设计科学方法论(DSM) 为基础设计了基于大语言模型(LLM) 的危害分析与风险评估(HARA) 原型系统,通过三轮设计 / 工程迭代(1 个设计周期 + 2 个工程周期),拆解 HARA 任务并优化提示工程,结合规则化脚本与 LLM 搭建自动化流水线,经9 位平均 10 年以上经验的汽车安全专家 评估及企业实际场景验证,发现该原型能将 HARA 完成时间从数月缩短至 1 天内,生成的安全需求可与人工撰写媲美,虽存在幻觉、领域术语理解不足等局限性,但可作为工程师开展 HARA 的有效辅助工具,同时研究明确了 LLM 在 AD 安全需求制定中的限制、HARA 任务拆解方式及提示工程的优化策略三大核心问题,为汽车领域需求工程自动化提供了实践参考。详细总结
本研究是沃尔沃汽车、哥德堡大学等机构合作的成果,发表于2024 年IEEE 第32 届国际需求工程会议,核心围绕大语言模型(LLM)在自动驾驶(AD)领域危害分析与风险评估(HARA)安全需求工程中的应用展开,通过设计科学方法论迭代开发并验证了LLM-based HARA 原型系统,为汽车领域需求工程自动化提供了实践方案与核心洞察。以下为详细内容:
一、研究背景与核心目标
自动驾驶软件系统复杂,其安全验证需遵循ISO 26262(功能安全)和ISO 21448(预期功能安全SOTIF)中的HARA 要求;汽车领域的功能描述、运营环境、法规更新频繁,需反复迭代开展HARA,而HARA 的危险识别环节依赖工程师的想象力与创造力,耗时且成本高。
LLM 具备强大的自然语言理解与生成能力,有望辅助工程师完成 HARA 中的头脑风暴、需求制定、冗余审查等工作。
设计能有效辅助工程师开展AD 领域HARA 安全需求制定的LLM 原型,解答三大问题:
RQ1:LLM 用于AD 安全需求制定的局限性是什么?RQ2:如何拆解 HARA任务以提升LLM的表现?RQ3:如何通过提示工程优化LLM 在AD安全需求制定中的性能?二、研究方法论
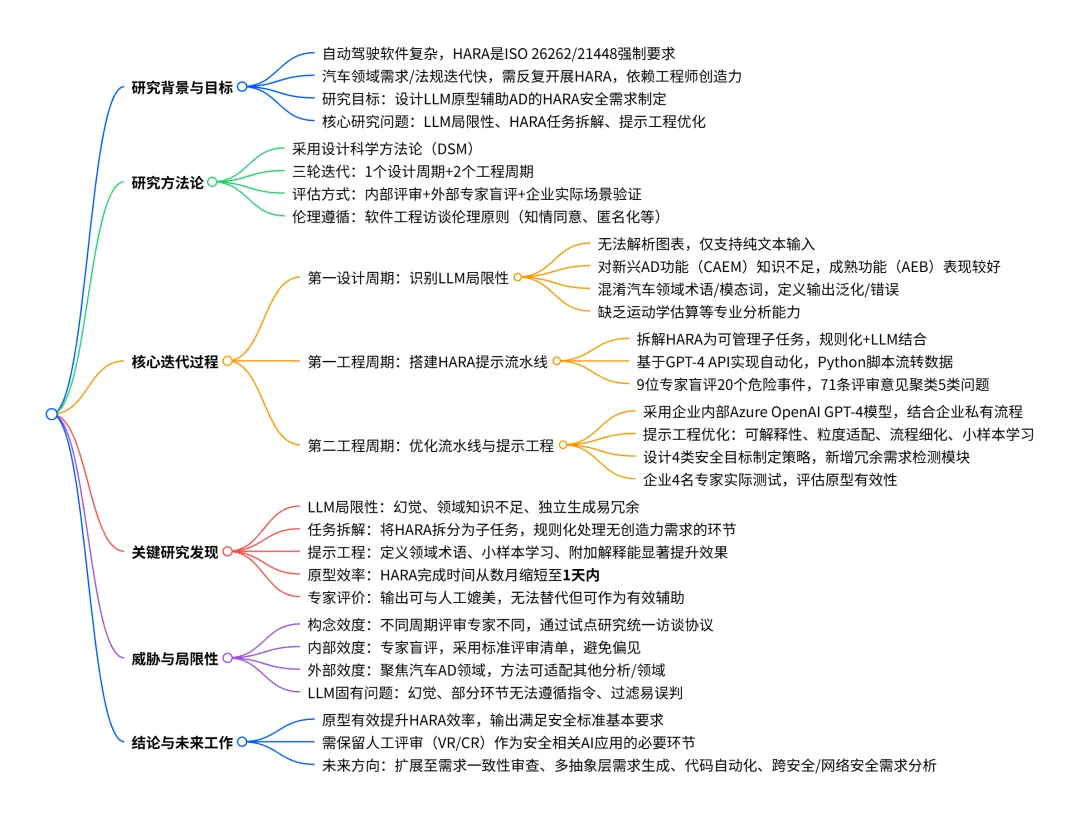
- 核心方法采用设计科学方法论(DSM),分为问题识别、设计、实现、评估四个核心环节。
- 迭代设计共开展3 轮迭代(1 个设计周期 + 2 个工程周期),每轮包含设计、实现、评估,且在周期内进行内部评审以迭代优化。
- 评估体系
- 内部评审:研究团队对 LLM 输出的可读性、领域相关性进行评估;
- 外部专家评审:邀请汽车行业安全专家进行验证评审(VR,技术 / 项目层面)和确认评审(CR,流程层面);
- 企业场景验证:在合作企业中部署原型,结合企业私有 LLM 和实际 AD 功能进行测试。
- 伦理规范遵循软件工程访谈伦理原则,包括知情同意、数据匿名化、保密等,所有步骤通过伦理清单审查。
三、三轮迭代的核心过程与发现
(一)第一设计周期:识别LLM 的核心局限性
本周期以ChatGPT 为基础开展可行性研究,核心目标是验证LLM 能否完成HARA 并识别其固有问题,关键发现如下:
- 输入形式限制LLM 无法正确解析图表 / 密级信息,仅支持纯文本作为输入;
- 领域知识不均衡对成熟 AD 功能(如 AEB 自动紧急制动)的 HARA 表现较好,对新兴功能(如 CAEM 避撞规避机动)知识不足,输出结果错误;
- 术语与表达错误混淆汽车安全工程的模态词(如“should” 为建议、“shall”为强制),对场景、危害、严重度等核心术语的定义泛化或错误;
- 专业分析能力缺失缺乏运动学估算等专业能力,无法完成碰撞位置、冲击速度等风险评估关键计算;
- 输出需精细化引导HARA 子任务的描述需足够详细,否则 LLM 输出不完整,需对任务进行拆解。
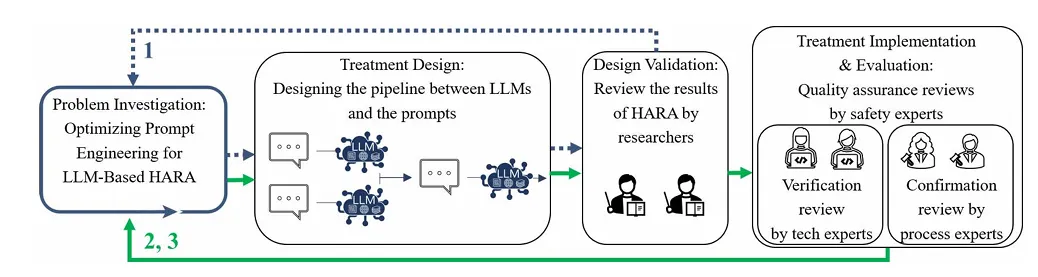
(二)第一工程周期:搭建HARA 自动化提示流水线
基于设计周期的局限性,本周期核心是拆解HARA 任务并搭建自动化流水线,结合GPT-4 API 实现端到端自动化,关键内容:
- 任务拆解与流水线设计
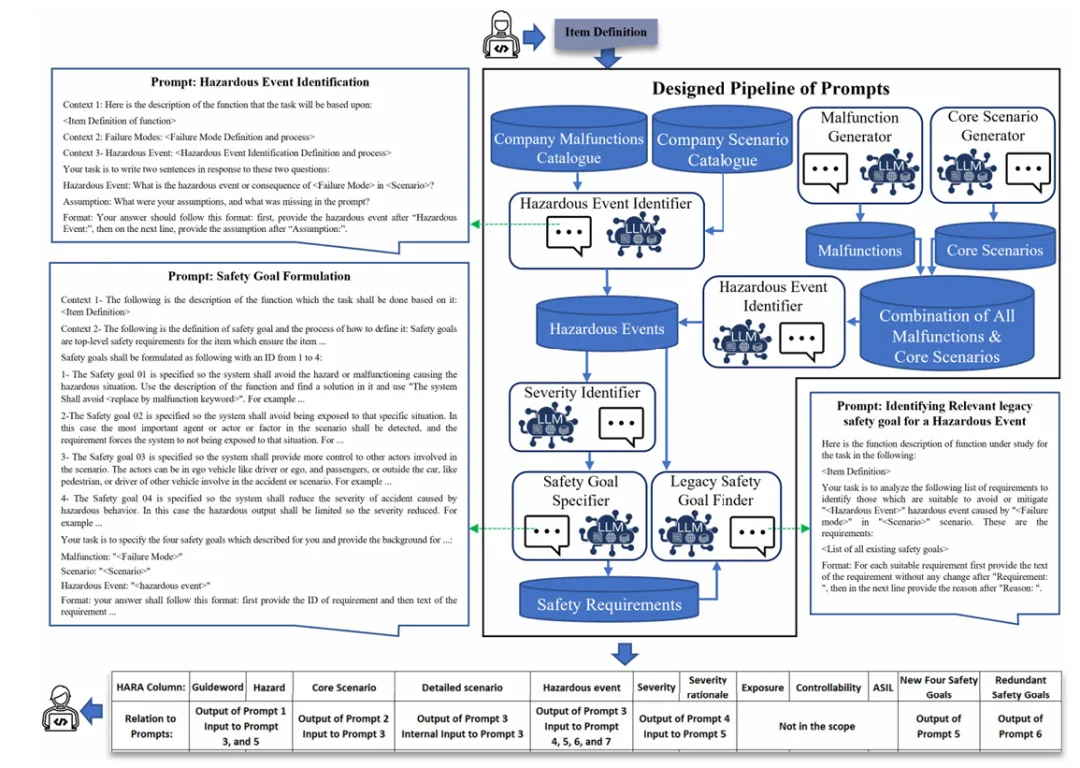
将HARA 拆分为故障生成、核心场景生成、危险事件识别、严重度判定、安全目标制定、遗留安全目标匹配等子任务,搭建自动化流水线;
采用规则化脚本(Python)+LLM结合的方式,无创造力需求的环节(如故障/ 场景组合)用规则化处理,避免LLM 幻觉。
- 实现方式基于OpenAI GPT-4 API 开发,Python 脚本实现子任务输出的存储与流转,最终以人类可读的表格输出完整 HARA 结果。
- 专家评估结果
- 评审团队:9 位汽车安全专家(来自 3 家 AD 开发企业,平均 10 年以上相关经验,最低 5 年);
- 评审对象:20 个危险事件的 LLM-generated HARA 结果;
- 评审结果:收集 71 条评审意见,聚类为5 类核心问题(场景 / 危险事件不一致、场景完整性不足、严重度判定缺乏依据、安全目标制定冗余 / 模糊、其他),具体见下表:
问题类别 | 核心表现 |
场景 / 危险事件不一致 | 场景描述过细 / 模糊、故障与危险事件无关联、术语使用不规范(如未用 VRU 覆盖道路使用者) |
场景完整性不足 | 未覆盖关键场景(如急转弯)、无法判定场景是否系统覆盖 |
严重度判定缺乏依据 | 严重度等级无合理推导、速度等关键参数未定义、安全机制误判 |
安全目标制定冗余 / 模糊 | 安全目标重叠、表述模糊(如 “必要时” 无定义)、包含技术解决方案 / 多余解释 |
其他 | 输出格式不统一、部分环节未遵循 ISO 26262 要求 |
- 专家评分核心结论所有评估标准平均得分不低于 2 分(满分 5 分),安全目标覆盖性(g)和安全机制排除(d)表现最好,危险事件识别(b)和危险事件表述(c)存在专家分歧,核心原因是场景识别的 “工艺性” 和 LLM 独立生成的冗余性。
- 专家定性评价LLM 无法替代人工,但可作为 HARA 的初步引导工具,加速有效版本的开发。
(三)第二工程周期:优化流水线与提示工程,企业场景验证
本周期基于第一工程周期的评审意见,结合企业内部Azure OpenAI GPT-4 模型(保护知识产权)和实际AD 功能进行优化与验证,核心优化与发现:
- 提示工程四大优化策略
- 可解释性要求 LLM 为输出附加背景、假设、推导依据,提升人工评审的可理解性;
- 粒度适配对过细的场景进行聚类,匹配人类 HARA 的常规粒度,同时保留细节以提升 LLM 判断准确性;
- 流程细化结合企业内部详细的 HARA 流程,替代通用标准,解决输出不准确问题;
- 小样本学习
- 安全目标制定的 4 类核心策略
为LLM 定义标准化的安全目标制定方向,每个危险事件生成4 类安全目标,供工程师选择:
- 规避场景:通过运营设计域(ODD)限制,避免暴露在危险场景中;
- 降低严重度:限制车速、加速度等参数,减轻事故后果。
- 流水线新增模块安全需求冗余检测器,解决 LLM 独立生成导致的需求重叠问题,通过检索已生成需求,避免重复制定。
- 企业场景验证
- 测试方式:专家提供故障模式 / 场景,原型生成 HARA 结果,专家进行一对一评审;
- 核心结论:安全目标结构符合标准,可辅助工程师撰写需求;但部分输出未遵循指令、存在无关需求,过滤工作需由人工完成(避免 LLM 误删相关需求)。
四、研究的核心发现与局限性
(一)三大研究问题的核心答案
- LLM 的局限性(RQ1)存在幻觉问题、领域专业知识不足、无法解析非文本输入、独立生成易产生冗余需求、部分环节无法遵循人工指令;
- HARA 任务拆解(RQ2)将 HARA 拆分为独立子任务,对无创造力需求的环节采用规则化处理,仅将创意性 / 自然语言处理环节交给 LLM,通过 Python 脚本实现子任务自动化流转;
- 提示工程优化(RQ3)在提示中定义领域核心术语、加入小样本示例、要求输出可解释性依据、结合企业私有流程,能显著提升 LLM 的输出质量。
(二)原型的效率与效果
- 效率提升LLM 原型完成单个 AD 功能的 HARA 仅需不到 1 天,而人工团队完成需数月;
- 效果生成的安全需求与人工撰写结果媲美,满足 ISO 26262/21448 的基本要求,可作为人工的有效辅助。
(三)研究的威胁到效度
- 构念效度不同周期评审专家不同,通过试点研究统一访谈协议,减少评价偏差;
- 内部效度采用盲评方式,未告知专家输出由 LLM 生成,使用标准 ISO 26262 评审清单,保证结果可靠性;
- 外部效度研究聚焦汽车 AD 领域的 HARA,但任务拆解和提示工程方法可适配质量、网络安全等其他分析领域及其他汽车功能。
五、结论与未来工作
- 核心结论
- 基于 LLM 的 HARA 原型能显著提升自动驾驶安全需求工程的效率,输出满足行业标准基本要求,是工程师的有效辅助工具;
- LLM 存在固有局限性,人工评审(VR/CR)是 LLM 用于安全相关工作的必要环节,无法完全替代;
- 规则化脚本与 LLM 的结合、精细化的提示工程,是解决 LLM 在工业级需求工程中应用问题的关键。
- 未来工作方向
- 扩展原型功能至需求一致性审查,包括安全与网络安全需求的冗余 / 矛盾检测;
- 实现多抽象层的安全需求生成,并探索从需求到代码的自动化生成;
- 结合企业私有数据 / 遗留需求,进一步优化 LLM 的领域适配能力;
- 探索 LLM 在汽车领域其他安全工程活动中的应用。
六、研究资助与声明
- 资助方瑞典创新局(Vinnova)、瓦伦堡人工智能、自主系统和软件计划(WASP);
- 免责声明研究观点仅代表作者,不代表沃尔沃汽车官方立场;原型仅用于研究,未应用于实际生产项目。
问题1(应用层面):基于LLM 的HARA 原型在自动驾驶领域的实际应用价值是什么?与人工开展HARA 相比有哪些核心优势?
答案:该原型的核心应用价值是作为汽车工程师开展HARA 的有效辅助工具,无法替代人工但能显著提升工作效率;与人工相比,核心优势为效率大幅提升(完成HARA 的时间从人工的数月缩短至不到1 天),且生成的安全需求能与人工撰写结果媲美,满足ISO 26262/21448 的基本安全标准;同时原型能辅助工程师完成头脑风暴、需求初稿撰写、冗余需求检测等工作,减少人工重复劳动。
问题2(技术层面):为解决LLM 在自动驾驶HARA 应用中的局限性,研究采用了哪些核心技术策略?
答案:研究采用了三大核心技术策略:1)任务拆解+ 规则化与LLM 结合,将HARA 拆分为可管理的子任务,对无创造力需求的环节(如故障/ 场景组合)用Python 规则化脚本处理,避免LLM 幻觉,仅将创意性环节交给LLM;2)精细化的提示工程,包括在提示中定义汽车领域核心术语、加入小样本学习示例、要求LLM 输出附加推导依据/ 假设、结合企业私有流程替代通用标准;3)流水线优化与新增模块,设计4 类标准化的安全目标制定策略,新增安全需求冗余检测器,解决LLM 独立生成的需求重叠问题。
问题3(行业层面):将LLM 应用于汽车领域的安全需求工程(如HARA),需要遵循哪些核心原则?
答案:需遵循三大核心原则:1)保留人工强制评审,必须通过验证评审(VR)和确认评审(CR)对LLM 输出进行审查,这是LLM 用于安全相关工作的必要环节,因LLM 存在幻觉、领域知识不足等固有局限性;2)领域适配优先,需结合汽车行业的ISO 标准、企业私有流程和领域术语对LLM 进行提示工程优化,避免通用LLM 的泛化输出;3)规则化与LLM 协同,对工业级安全工程中无创造力需求的环节,优先采用规则化方法处理,仅将自然语言理解、创意性头脑风暴等环节交给LLM,平衡自动化与输出准确性。
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
