——74——
3月17日,英伟达GTC 2026大会上,理想汽车发布了下一代自动驾驶基础模型MindVLA-o1。
这类发布会每年都有,各家都在喊“突破”“领先”。
但这次值得单独拿出来聊一聊,不是因为理想说了什么,而是它正在做的事可能改变了自动驾驶技术演进的路径。
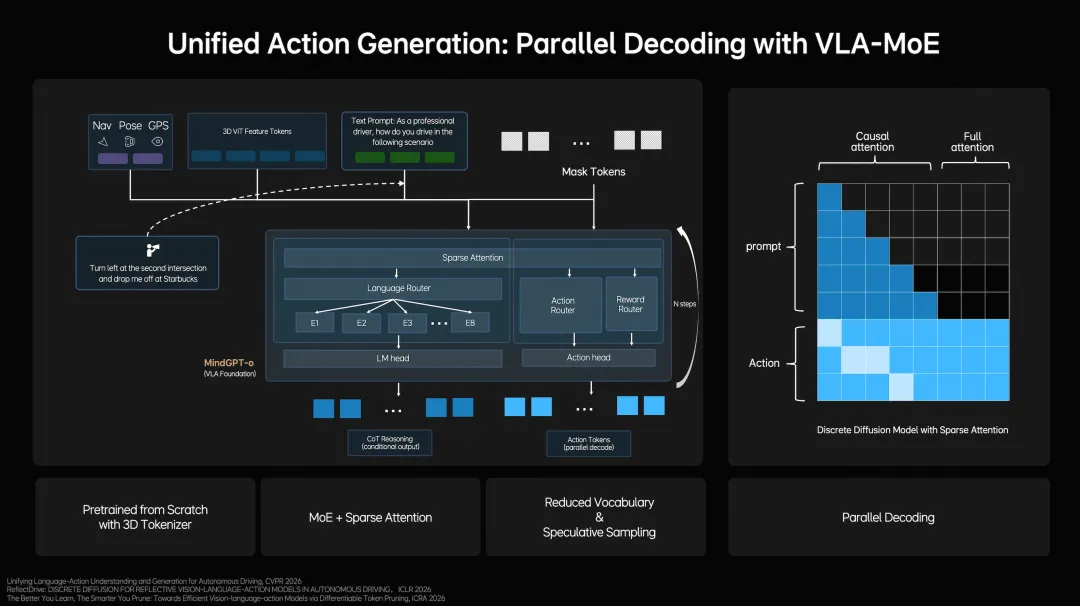
简单说,MindVLA-o1不是简单功能升级,而是把车的“眼睛”(视觉)、“脑子”(语言理解)和“手脚”(驾驶动作)全部打通,装进了同一个模型里。
用行业术语叫“原生多模态VLA架构”——在模型设计之初就把这三件事统一训练,而不是像以前那样分别训练再拼凑。
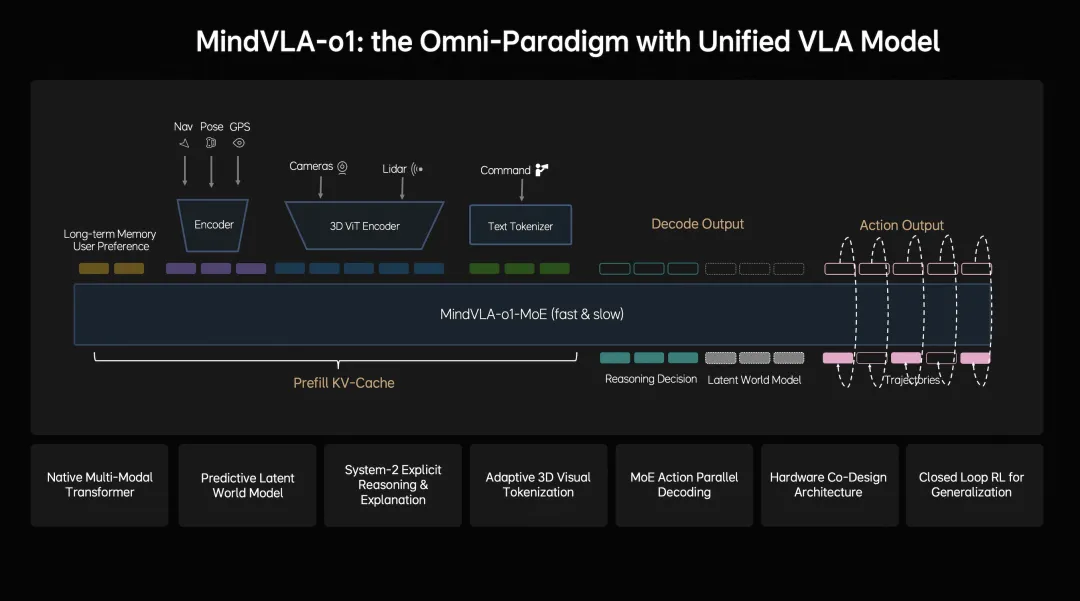
五个技术亮点,分别意味着什么?
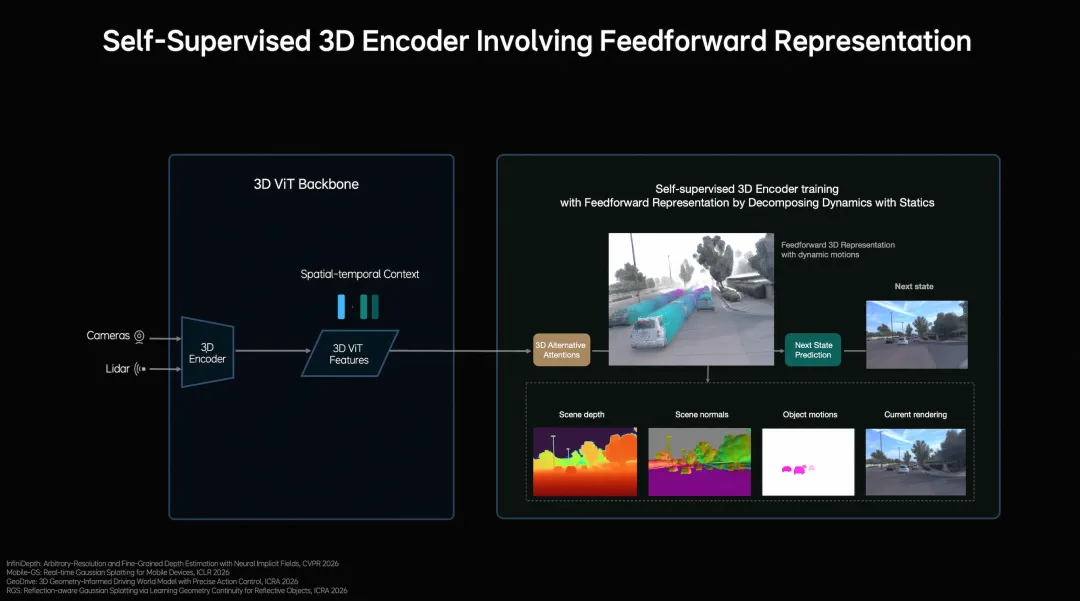
1. 看得更远:从“识别物体”到“理解运动”
传统自动驾驶感知系统处理的是空间问题:这里有什么,那里有什么,位置关系是什么。它会把三维世界压平成二维鸟瞰图,标注出障碍物和车道线。
这套方法够用,但它丢失了时间维度。
MindVLA-o1引入了“下一帧预测”的训练方式:模型不光学“当前是什么样”,还学习“接下来会怎么变”。同时感知升级到三维结构,融合摄像头和激光雷达,保留了高度和动态信息——这些在鸟瞰图里会被压平。
可以想象一个场景:路边站着一个人。传统系统识别出“静止物体”,等他突然走出来才反应。如果模型能预判“他车头偏左,眼神在看马路对面,大概率要斜插过马路”,就能提前做好准备。这不是感知精度的问题,而是对物理世界因果结构的理解。
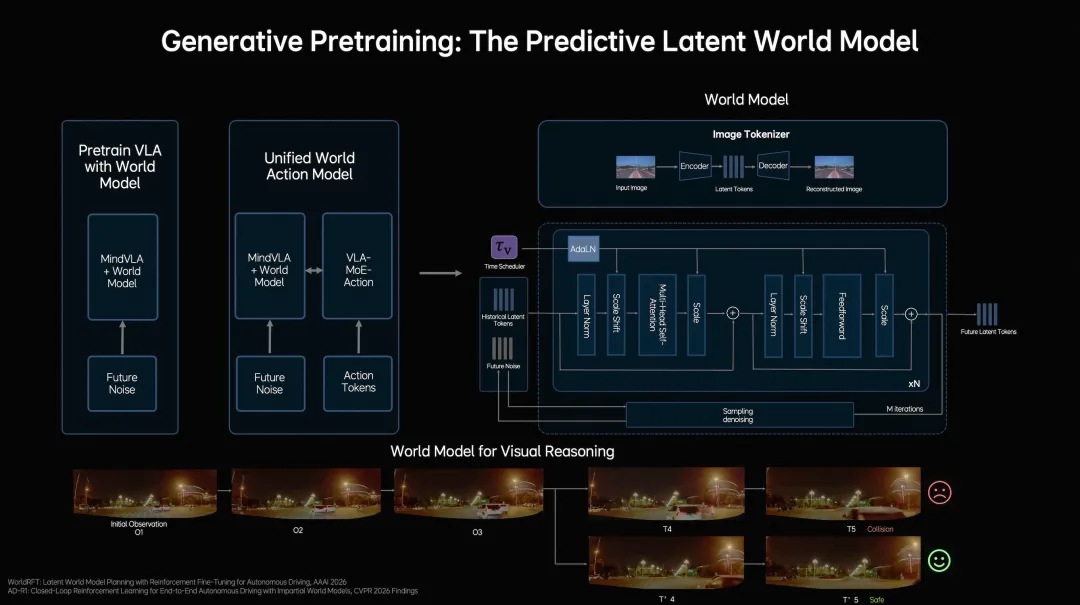
2. 想得更深:把“想象未来”的成本压下来
理解了世界动态,下一步是在车上实时使用这种理解。但世界模型计算代价很高,直接在车端运行几乎不可能。
理想的解法是把预测过程压缩到“隐空间”里进行——不是用真实图像推演,而是在模型内部的抽象向量空间里模拟未来。训练分三阶段:先用海量视频数据学会压缩和解压缩,再在隐空间建立预测能力,最后把预测能力和驾驶决策联合训练。
结果是:系统获得了“想象未来”的能力,但计算成本被压缩到可以在车端实时运行。遇到复杂路口,它能在脑子里快速推演好几条路径,而不是只盯着眼前。
3. 行得更稳:从“预测轨迹”到“生成轨迹”
传统自动驾驶规划做的是“预测问题”:给定当前状态,预测出未来最可能的路径点。MindVLA-o1把它改成了“生成问题”——用类似大语言模型生成文字的方式,生成驾驶轨迹。
这个转变的工程含义是:生成模型可以同时考虑多种可能性,通过多轮迭代收敛到最优解,而传统预测模型更像是沿着一条路走到黑。
具体实现用了三项技术组合:混合专家模型(不同场景交给不同模块处理)、并行解码(所有轨迹点同时生成,避免延迟积累)、扩散优化(多轮迭代让轨迹更平滑)。
最直观的感受可能是:变道不再犹豫,过弯不再顿挫,整个驾驶过程更接近人类老司机的节奏感。
4. 进化更快:从“被教会”到“自己学会”
这是技术上最有意思的一点。
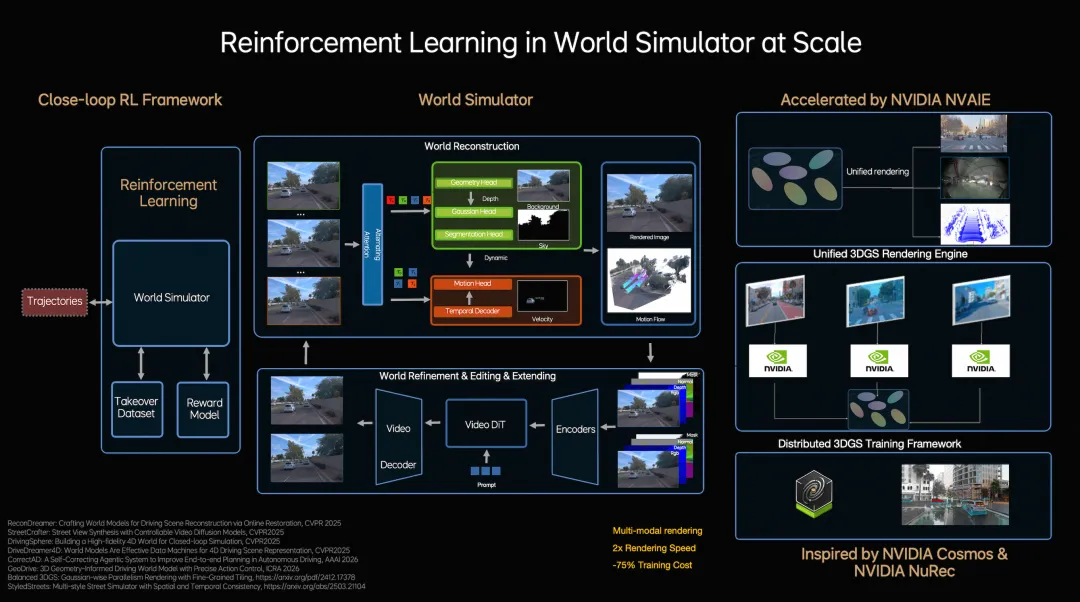
自动驾驶最难搞定的不是常见场景,而是“长尾场景”——那些出现概率很低、一旦出现就很危险的情况。靠真实采集数据来覆盖,成本极高,有些极端情况根本不可能在真实路测中主动制造。
理想的解法是用世界模型生成仿真场景,再用强化学习让模型在这些场景里自己探索最优策略。场景生成从逐步重建改成了前馈生成,渲染速度提升约2倍,训练成本降低约75%。
更关键的是这套机制带来的质变:系统不再被动地从人类标注数据里学习,而是可以主动生成从未见过的情况,然后在其中试错、优化、迭代。换句话说,你的车可以在“梦里”自己练车,而且练得比你想象的快得多。
5. 部署更高效:软硬件协同设计
模型再先进,在车端跑不起来等于白做。
理想引入了一套Roofline分析框架,在模型结构和硬件性能之间建立精确映射,测试了近2000种不同模型配置,找到精度和延迟之间的最优平衡点。
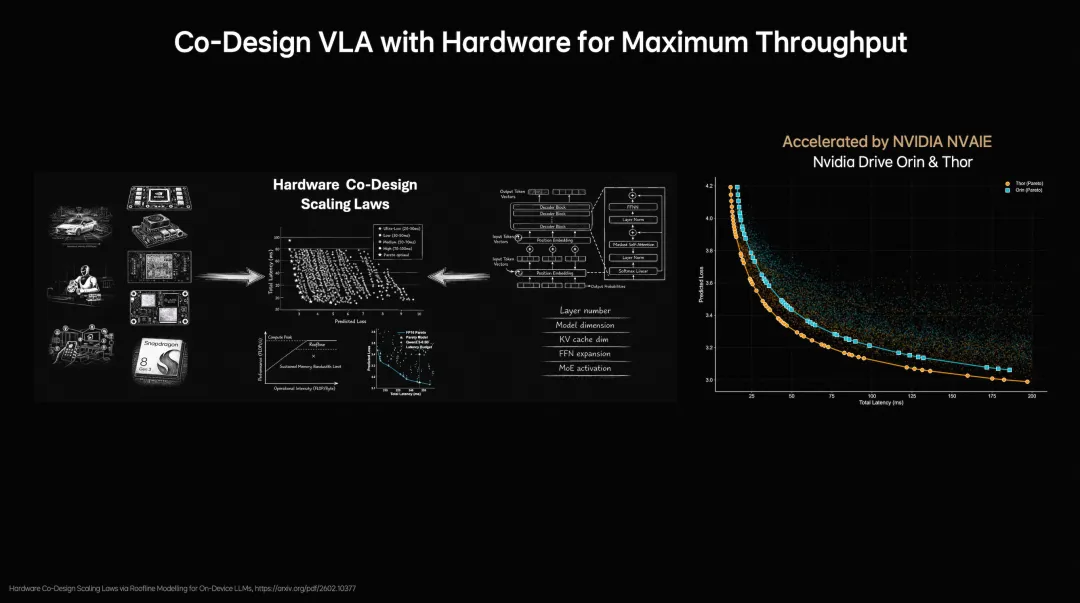
一个有意思的事实:在车端场景里,更“宽但浅”的模型结构优于深层结构。这与大语言模型的经验相反,反映的是车端对实时性的要求比对参数规模更敏感。这套探索过程,过去需要数月,现在压缩到了数天。
对于老车主来说,这可能意味着:如果硬件支持,后续OTA升级的空间更大,而不是被算力卡死。
更深的意义:竞争维度的迁移
MindVLA-o1最值得关注的,可能不是它今天开得有多好,而是它标志着竞争维度的迁移。
过去几年,自动驾驶的比拼主要在两个地方:传感器数量和城市覆盖里程。这两件事正在成为行业基线,不再是真正的差异化来源。
新的竞争维度是:数据闭环能力、仿真能力、强化学习基础设施、系统工程整合能力。这些东西都不是一两年能追上的,依赖长期技术积累和大规模工程投入——本质上是组织能力,而不只是模型能力。
另外值得留意的是,理想明确表示这套VLA模型不只用于驾驶,可以迁移到机器人控制。逻辑是:驾驶和机器人在底层问题上高度相似——都需要感知三维空间,都需要理解物体运动和意图,都需要在实时约束下做决策。区别只在于执行器,一个是方向盘和油门,一个是机械臂和腿。
如果感知和决策的底层模型是通用的,那么迁移成本会大幅降低。这可能意味着,自动驾驶正在成为通用物理AI的入口。
总结
MindVLA-o1不是一个“马上能让你躺平”的产品,而是一次技术架构的底层重构。它想解决的是自动驾驶最核心的难题:如何让系统真正理解物理世界,而不仅仅是识别模式。
对于消费者,这意味着未来的辅助驾驶会更自然、更少惊吓、更像老司机。
对于行业,这可能意味着竞争逻辑正在改变——从“谁的感知更准”到“谁的系统进化更快”。
新的游戏,才刚刚开始。

 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
