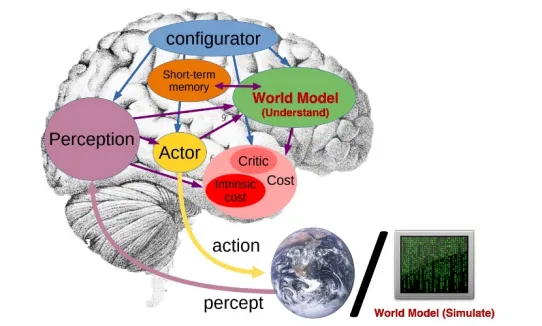
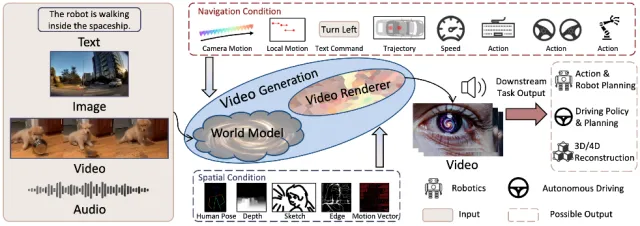
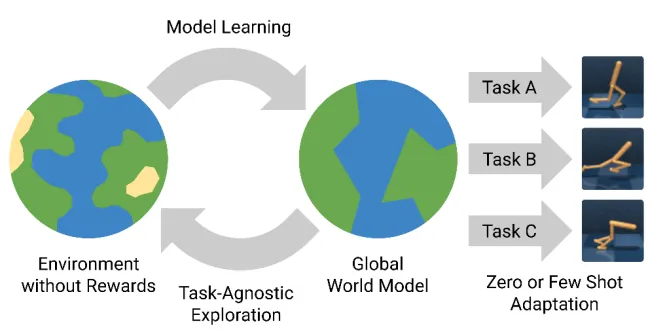
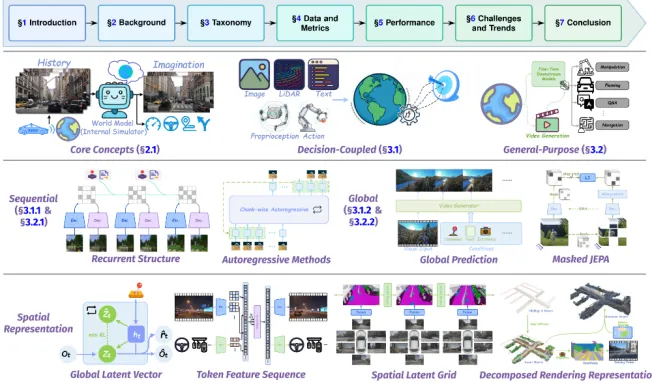
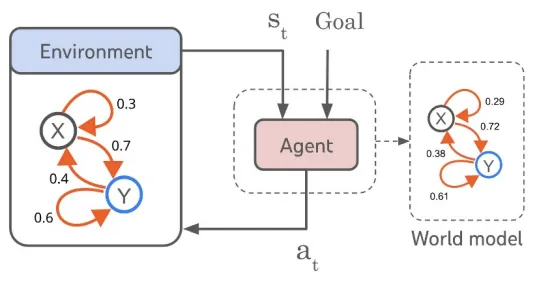
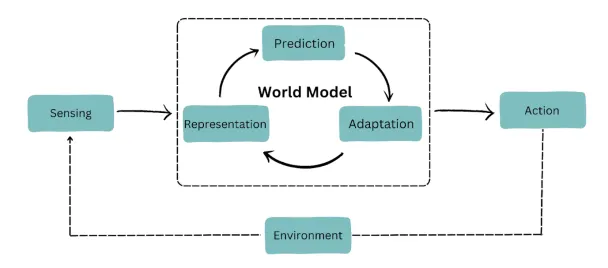
世界模型,是一个在自动驾驶系统“大脑”内部构建的、可学习的、能够模拟现实世界动态变化的“虚拟现实”。系统不是在真实世界中直接做决策,而是在这个内部的、抽象的、运行速度极快的“元宇宙”里进行大量推演,然后才做出最优决策。“世界模型”这个词之所以容易让人产生误解,是因为它听起来像:
但实际上,它不是玄学,而是一个可计算、可训练、可验证的数学结构。世界模型(World Model)本质上是一种:对“世界状态”与“世界演化规律”的联合建模。它包含两个核心能力:
1. 表征世界当前状态
2. 预测世界未来如何变化
换句话说,它回答两个问题:
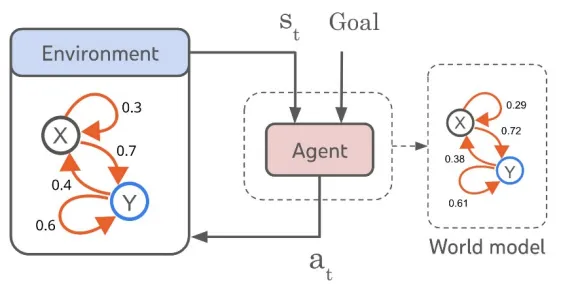
如果我们把自动驾驶系统比作一个智能体(Agent),那世界模型就是这个智能体的“内在宇宙”。它不是摄像头看到的画面本身,而是:
对场景的结构化理解
对物体之间关系的抽象
对物理规律的隐式编码
对行为趋势的概率性预测
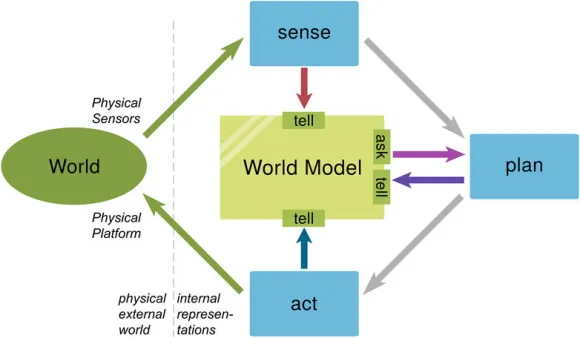
世界模型并不是一个简单模块,而是一个多层结构。
第一层:状态表征(State Representation)这是“我现在看到什么”。
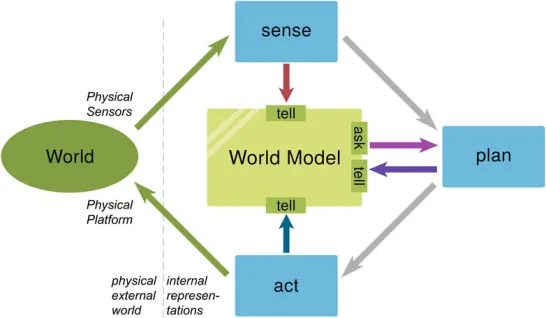
系统通过多传感器融合(摄像头、激光雷达、毫米波雷达等)构建一个统一的世界状态表示。这一层通常包含:
道路拓扑结构(车道线、边界、路口)
动态目标(车辆、行人、自行车)
静态障碍物(路障、护栏、建筑)
交通规则(红绿灯状态、限速标志)
自车状态(速度、加速度、方向盘角度)
但关键在于:世界模型并不是保存“像素”,而是保存“语义”。
比如:
它不是保存一片红色像素。
它保存“前方50米有一辆减速中的卡车”。
这是从感知到语义抽象的跨越。
第二层:动力学建模(Dynamics Modeling)
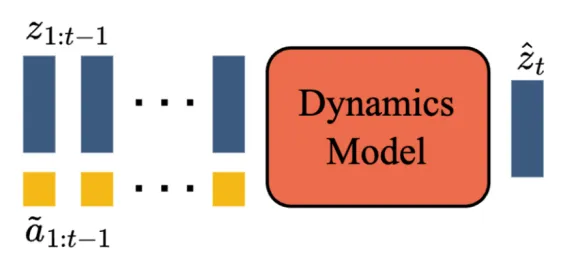
这是世界模型真正的核心。它要回答:如果当前状态是 Sₜ,那么 Sₜ₊₁ 会是什么?
也就是说:世界模型必须学会“时间”。它必须理解:
车辆会沿着车道前进
行人可能突然横穿马路
红灯会变绿
前车刹车后,后车可能也会刹车
这里涉及两种动力学:
世界模型不仅预测“物体会移动”,还预测“物体为什么移动”。
第三层:可模拟性(Imaginative Simulation)
这才是它像“虚拟现实”的地方。一旦有了状态和动力学模型,系统就可以:
在内部构造一个完整场景
让时间加速推进
尝试不同动作
观察未来结果
例如:如果我现在向左变道,会发生什么?
是否会与后车发生冲突?
是否会影响前方车流?
是否违反交通规则?
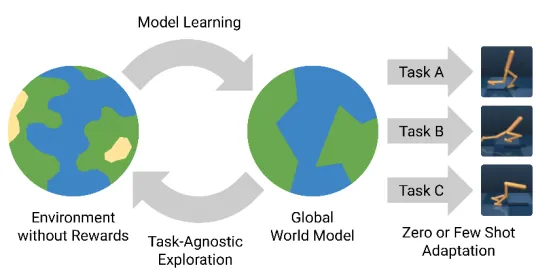
系统可以在内部“模拟”几百种未来路径,然后选择风险最低、收益最高的一条。
现实世界只能经历一次。但世界模型允许系统经历成千上万次“假设未来”。
1.1 它是一个“内部模型”
什么叫“内部”?内部,意味着它存在于神经网络的参数空间中。它不是:
一个3D游戏画面
一个真实渲染的物理引擎
一个对世界的逐像素复制
而是:一个对“世界状态”的压缩表达。
1.2 它不是像素复制
现实世界是连续的、无限复杂的。摄像头看到的是:
如果系统要“逐像素理解世界”,那计算量将是爆炸级的。所以它必须做一件事:
抽象。举例:
1. 现实输入:一片灰色像素 + 两条白线 + 一个红色小方块
2. 内部世界模型理解为:当前车道 + 左侧车道线 + 前方50米一辆减速中的红色轿车
从视觉数据到结构化语义状态,这一步,就是世界模型的“入口”。
1.3 它存在于“潜在空间”
在技术上,这个内部世界通常被表示为:
它的特点:
所以它不是“一个虚拟3D世界”,而是“一个可计算的状态空间”。
1.4 它是可学习的
这是关键。世界模型不是人类程序员手写规则构建的。它不是:
它是通过数据学习得到的统计规律集合。
1.5 它学到的不是“规则文本”,而是“分布”
比如你说:它会学到“物体不会瞬移”。系统并没有一个if语句写着:
if (object.teleport) -> error
而是它在数据中观察到:
连续帧之间,物体位置变化是连续的
速度变化是平滑的
运动满足一定惯性
于是神经网络参数自动编码了:P(下一帧状态 | 当前状态) 的分布
如果某个物体突然瞬移100米,那在它的概率模型里,这个状态的概率接近0。
这就是“学到物理规律”的本质。
1.6 它如何学到“下雨天路会滑”?
假设数据中包含:
系统会自动捕捉到:
并把这些模式与“动力学变化”关联起来。于是它形成了一个隐式映射:
湿滑路面 → 更大的制动距离。
这不是规则写进去的,是统计规律涌现出来的。
1.7 它学到的是“联合分布”
世界模型学的本质是:P(未来状态 | 当前状态, 当前动作)
这包含:
比如:
前车减速 → 后车更可能减速
行人朝马路方向移动 → 过街概率上升
高速路 → 变道行为概率更高
它学到的是“世界如何演化”的统计规律。
1.8 它的核心功能是预测
现在来到最核心的一点:世界模型的存在意义 = 预测未来,没有预测能力,就不需要世界模型。
预测的数学形式,我们可以写成:Sₜ₊₁ = f(Sₜ, Aₜ)或者更准确地说:P(Sₜ₊₁ | Sₜ, Aₜ)这里:
Sₜ 是当前世界状态
Aₜ 是当前动作
Sₜ₊₁ 是下一时刻状态
这就是动力学模型。
1.9 它预测的不只是“物体移动”
它预测的是:
例如:如果我加速:
我与前车距离缩小
后车可能被迫减速
进入路口时间提前
与横向车流冲突概率上升
这是一种“因果级联推演”。
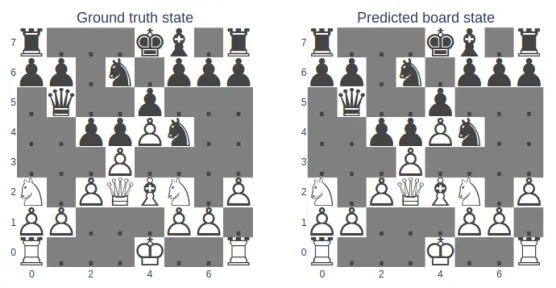
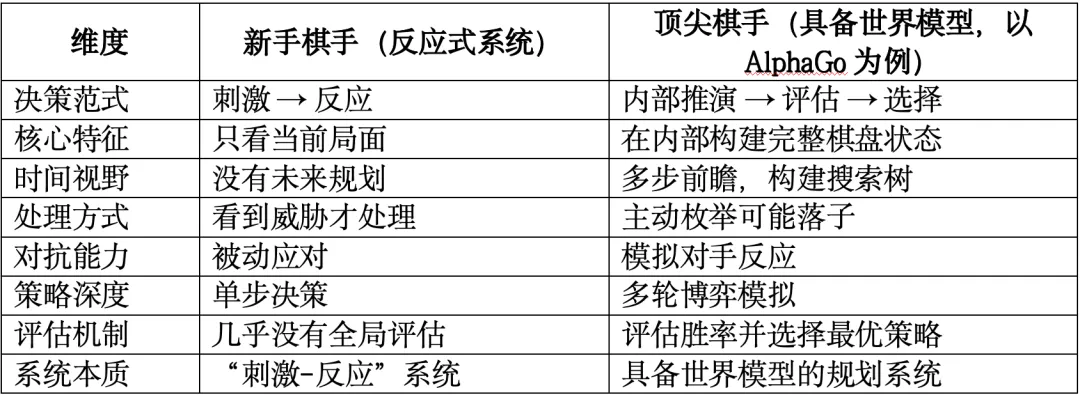
1.10 下棋类比——我们把它彻底讲透
这个类比非常好,我们现在升级它。
关键点:它不是“预测一个未来”,它是“预测很多可能的未来”。
1.11 驾驶中的等价过程
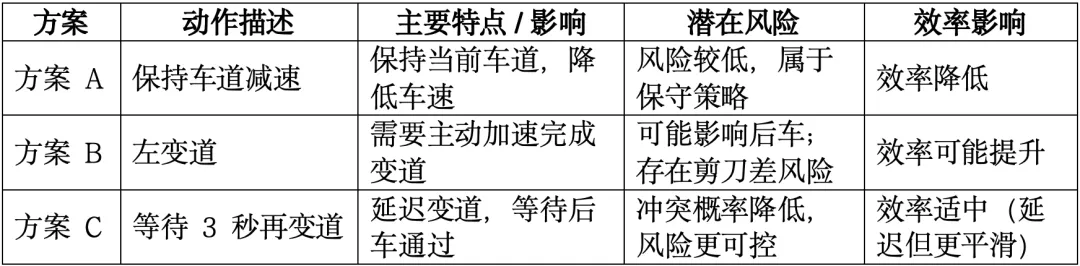
假设当前情况:
没有世界模型的系统:
有世界模型的系统会在脑内模拟:
系统在内部高速演算几百种微小变体,选择综合风险最小的一条轨迹。这就是“驾驶版AlphaGo”。从反应任务 → 前瞻规划任务这是整个范式转变的核心。
没有世界模型:
有世界模型:
时间维度的差异
反应式系统:现在 → 现在 → 现在
预测式系统:现在 → 未来1秒 → 未来3秒 → 未来5秒
这带来的本质改变是:决策开始具有“时间深度”。
1.12 更深一层理解:它让系统拥有“想象力”
现实世界:
世界模型内部:
这使系统具备了:
世界模型不是:一个虚拟3D引擎。它是:一个可学习的、内部抽象的、能够对世界未来演化进行高速概率推演的动力学模型。它让自动驾驶汽车:像顶尖棋手一样,在行动之前,已经“看过”未来。



 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
