华为自动驾驶最新论文解读,刷新小米汽车VLA纪录
- 2026-03-24 12:38:08
最重磅的是2025年12月的DriveVLA-W0: World Models Amplify Data Scaling Law in Autonomous Driving,主要和中科院自动化研究所合作,关键的VLM有两个:一个是80亿参数的EMU3;另一个是70亿参数的QWEN2.5-VL。
其次是2026年3月的DynVLA: Learning World Dynamics for Action Reasoning in Autonomous Driving,关键的VLM还是80亿参数的EMU3,主要还是和中科院自动化研究所合作。
再次是2025年WAM-Diff: A Masked Diffusion VLA Framework with MoE and Online Reinforcement Learning for Autonomous Driving,关键的VLM是LLADA-V,主要合作单位是复旦大学。
最后是DynamicVGGT: Learning Dynamic Point Maps for 4D Scene Reconstruction in Autonomous Driving,是传统感知算法特别是深度图和点图领域,主要合作单位是复旦大学。
DynVLA与其他VLA对比
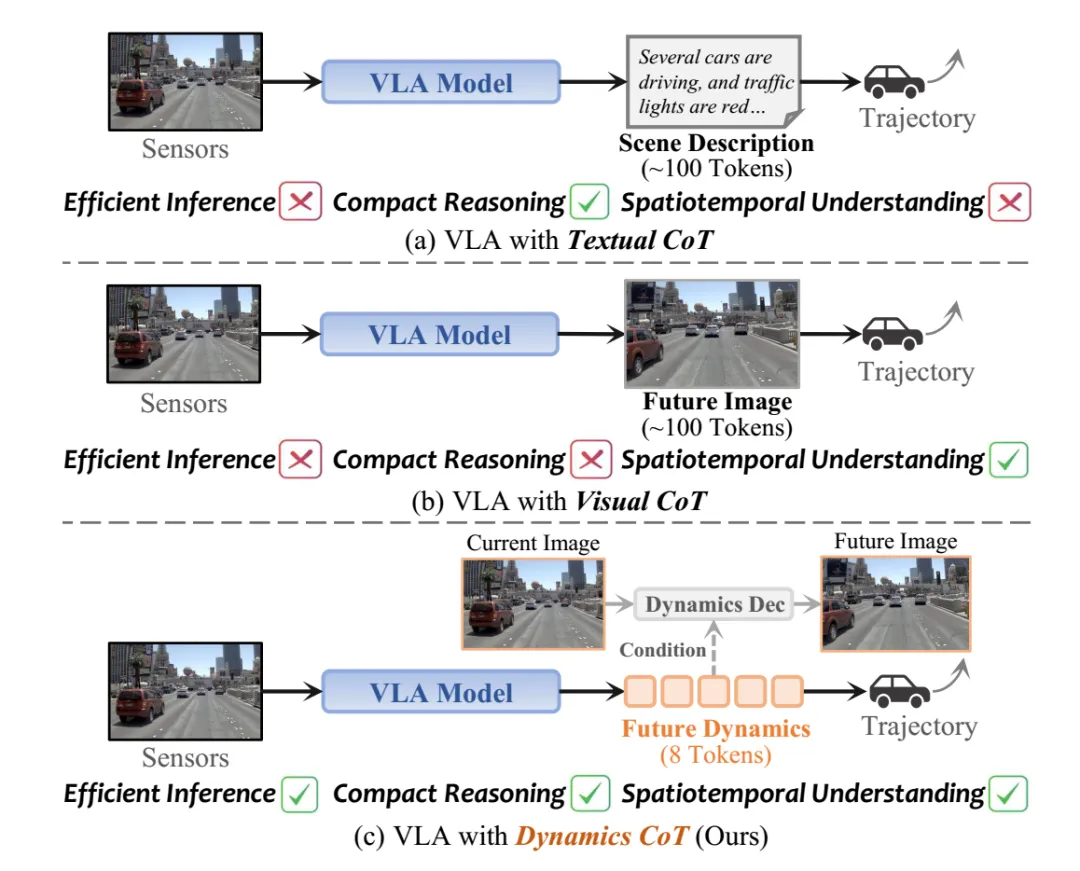
图片来源:引望智能
华为认为现有自动驾驶中的 CoT 设计仍然存在明显瓶颈。目前主流的推理方式主要有两类:
一类是 Textual CoT,即先生成类似前车减速、红灯亮起,因此应减速等待这样的文本 reasoning推理,再输出动作。这种方法虽具备一定可解释性,但语言天然难以表达连续的物理动态和细粒度时空关系,且效率低下,延迟太长。驾驶决策本质上依赖的是连续演化的动态世界,而非离散语言符号。
另一类是Visual CoT,即先预测未来图像,再根据未来图像生成动作。这类方法能够更直接地建模时空变化,但必须同时预测大量背景纹理和像素细节,其中大量信息与决策无关,导致计算开销巨大,推理 latency 很高。小米的解决办法是使用连续的隐变量向量(Latent Vectors)作为“思考”的载体,华为则是动态token化,实际两者差不多。
DynVLA架构
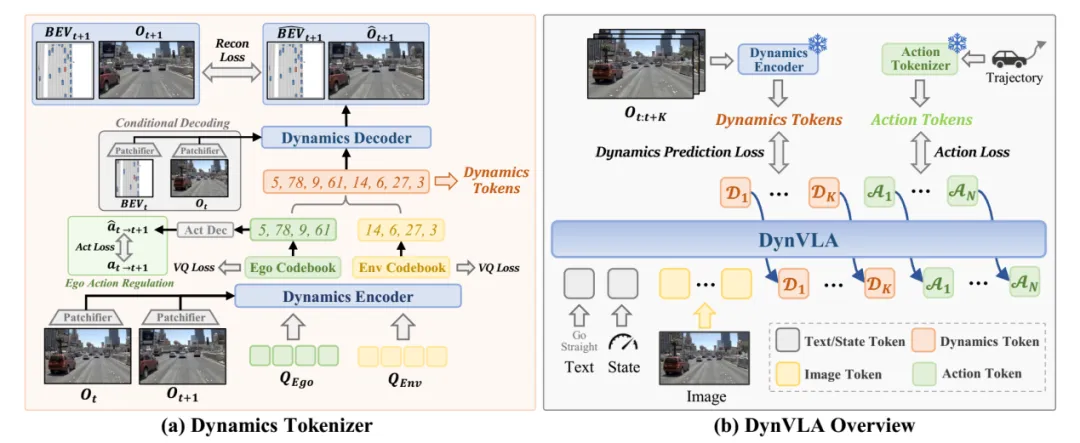
图片来源:引望智能
华为将未来动态压缩成少量离散token。考虑到driving scene场景中存在两类完全不同来源的变化:一类来自 ego 自身运动,例如加速、转向、制动;另一类来自环境中的其他 agent,例如前车减速、行人横穿、旁车cut-in。如果将这两类动态混合建模,会出现严重 ambiguity歧义,也就是没有对齐,例如ego 前进和前车后退在视觉上可能呈现类似 pattern。因此DynVLA显式构建了两个query :一个用于 ego-centric dynamics,一个用于 environment-centric dynamics。小米亦是如此,一个查询序列是负责理解静态的3D空间结构(如车道线、可行驶区域、静态障碍物),另一个是负责预测动态的时空演变(如周围车辆的未来轨迹、行人的意图)。小米多了3D结构。
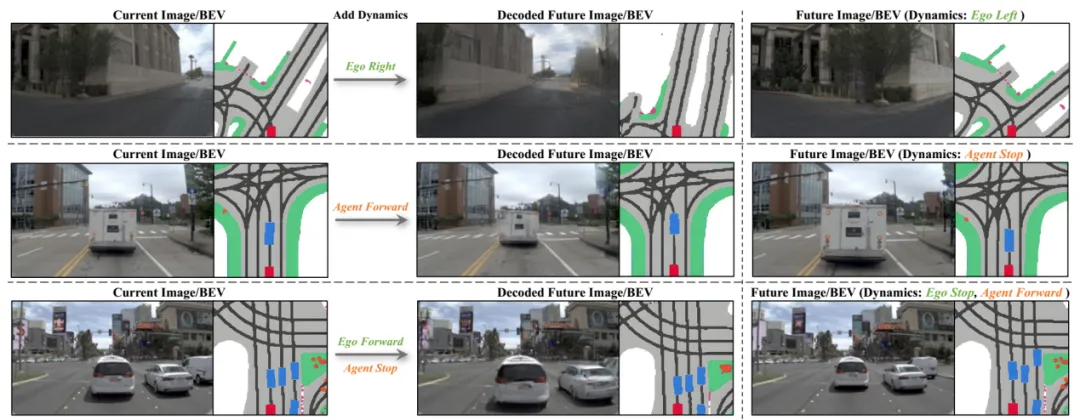
图片来源:引望智能
DynVLA训练环节
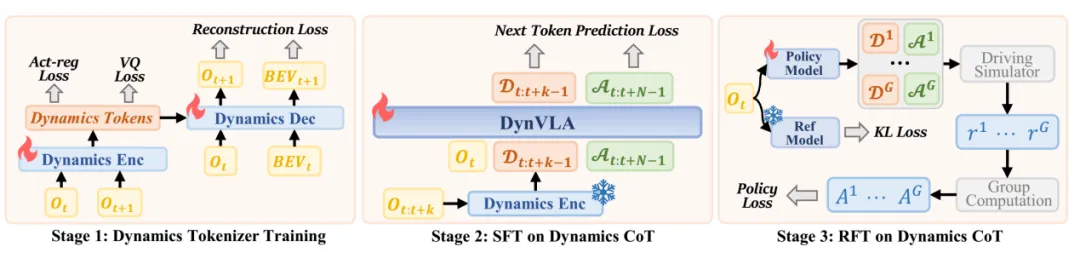
图片来源:引望智能
DynVLA训练环节,RFT就是强化学习微调,SFT+RL是自动驾驶VLA后训练标准流程,华为多了一个动态Token化,动态Token化的训练用了200K Steps,使用了8张英伟达L20显卡,SFT训练用了4k steps,也是8张英伟达L20显卡,RFT则是6k steps,用了6张英伟达H800显卡。小米汽车的LaST-VLA思路更清晰明了,华为的PDMS成绩略好。
DynVLA的核心或者说骨干是北京智源的EMU3,这是2024年10月发布的VLM,基本上是中国VLM的鼻祖,如果华为改用Qwen-VL-3,相信成绩还可以再提升。EMU3参数量为8B(80亿),只基于下一个token(输入数据的基本单位)预测,无需扩散模型或组合式方法,把图像、文本和视频编码为一个离散空间,在多模态混合序列上从头开始联合训练一个Transformer模型。该模型实现了视频、图像、文本三种模态的统一理解与生成,是纯粹的Transformer,不像现在大多都是DiT。
华为去年年底的WAM-Diff也值得一说,其PDMS得分不算太高,有91.0,也已经很不错了,它的EPDMS得分很高,高达89.7,比小米LaST-VLA的87.1还高不少,这里纠正一下以前犯的错误,华为的WAM-Diff是目前EPDMS得分最高的VLA。
WAM-Diff框架
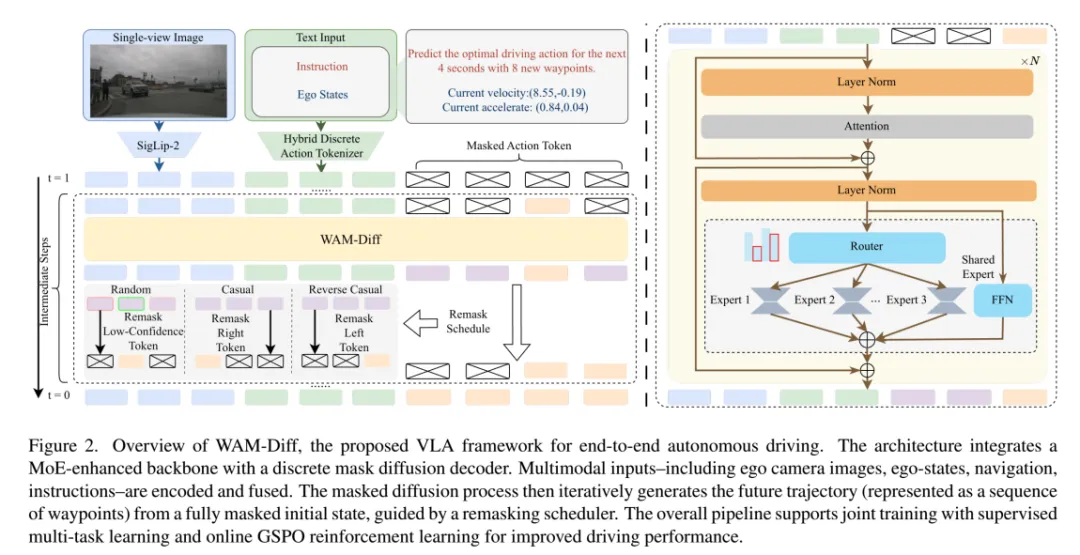
图片来源:引望智能
目前VLA主要分为两大流派:一类是基于自回归的大语言模型,它们像生成文本一样逐个token地生成动作序列;另一类是单独增加一个扩散任务头,连续扩散策略,通过去噪过程迭代优化动作预测,一般叫action expert,具身智能领域也是如此。自回归模型受限于从左到右的因果生成顺序,这在处理需要全局规划的驾驶任务时略显僵化。连续扩散模型虽然能捕捉多模态分布,但在逻辑推理和离散决策上往往不如自回归模型灵活。
掩码扩散的三种方式
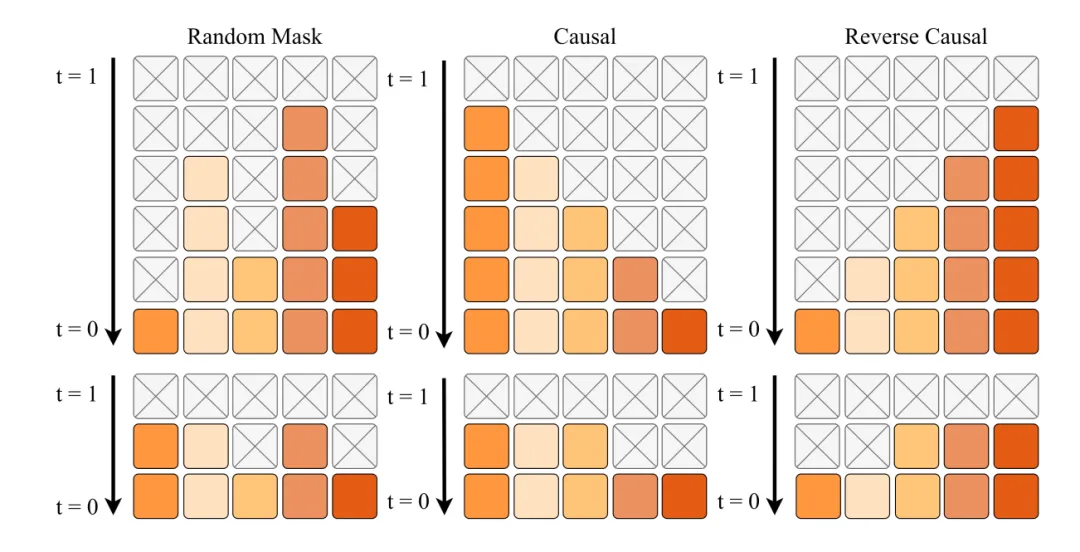
图片来源:引望智能
传统的自回归模型是串行的逐个预测,必须按顺序写;而WAM-Diff 采用 Masked Diffusion 作为生成骨干。与逐个预测下一个 Token 的自回归模型不同,Masked Diffusion 从一个全掩码序列出发,利用双向上下文信息,在每一步迭代中并行预测所有位置的Token。这种机制不仅大幅提升了推理效率,更重要的是赋予了模型全局优化的能力,使其能够同时利用过去和未来的信息来推断当前的最优动作。
掩码扩散模型则像是在做一张全卷的填空题,它可以先填确定的部分,再根据上下文回头修改不确定的部分,甚至可以先确定终点,再反推路径。该框架将未来的车辆轨迹视为一个离散的序列。在训练阶段,模型会随机掩盖掉一部分轨迹点,让网络去预测这些缺失的信息。在推理阶段,模型从一个完全被掩盖(全Mask)的序列开始,通过迭代的方式,逐步将Mask替换为具体的数值或语义token。 这种机制带来了前所未有的灵活性。它支持并行解码,不需要像自回归那样排队等前一个结果,大大提高了生成效率。更重要的是,它打破了时间顺序的枷锁,允许引入非因果的解码策略。
自动驾驶的轨迹是由连续的数值(如坐标、速度)组成的,而语言模型处理的是离散的语义符号。为了让两者在同一个模型里对话,研究团队构建了一个统一的词表。这个应该是学习Auto-VLA。对于连续变量,例如轨迹的路点(Waypoint),模型将其在[-100, 100]的区间内进行均匀量化,分辨率设为0.01。这意味着产生了20,001个不同的数值token。每一个二维路点被表示为一对有序的标量token <x, y>。在解码时,取每个量化区间的中心值,最大绝对误差仅为0.005,这在保证精度的同时实现了离散化。对于语义控制命令(如保持车道、让行)和驾驶理由,直接使用文本token。这20,001个数值token被合并到现有的文本词表中,并在训练过程中端到端地优化它们的嵌入投影。这种混合方式让模型既能理解向左转这样的高层指令,又能精准输出坐标(12.5, 4.3)这样的底层控制信号,实现了双向条件调节。
AutoVLA没有让模型以文本形式输出连续的、且常常在物理上不合理的航点坐标,而是创建了一个离散的动作代码本。AutoVLA从大规模真实驾驶数据(如Waymo Open Motion Dataset)中,通过K-Disk聚类算法,构建一个包含2048个离散“动作基元”的动作代码本 (Action Codebook)。每个动作基元代表一个短时(如0.5秒)的、物理可行的车辆运动(位移+姿态变化)。将连续的驾驶轨迹离散化为一连串的动作Token序列,将这些动作Token(如<action_0>, <action_1>, ...)作为新的词汇加入到VLM的词表中。将连续控制问题转化为了一个下一Token预测问题,而这正是LLM的原生语言。模型不再仅仅是描述要做什么,而是在从它的词汇表中选择一串经过物理验证的动作序列。这也是AutoVLA是目前最强自动驾驶VLA(没有之一)的主要原因。华为的WAM-Diff与之高度类似,但华为的生成骨干是扩散而非自回归,所以效果不如AutoVLA。
几种VLA对比
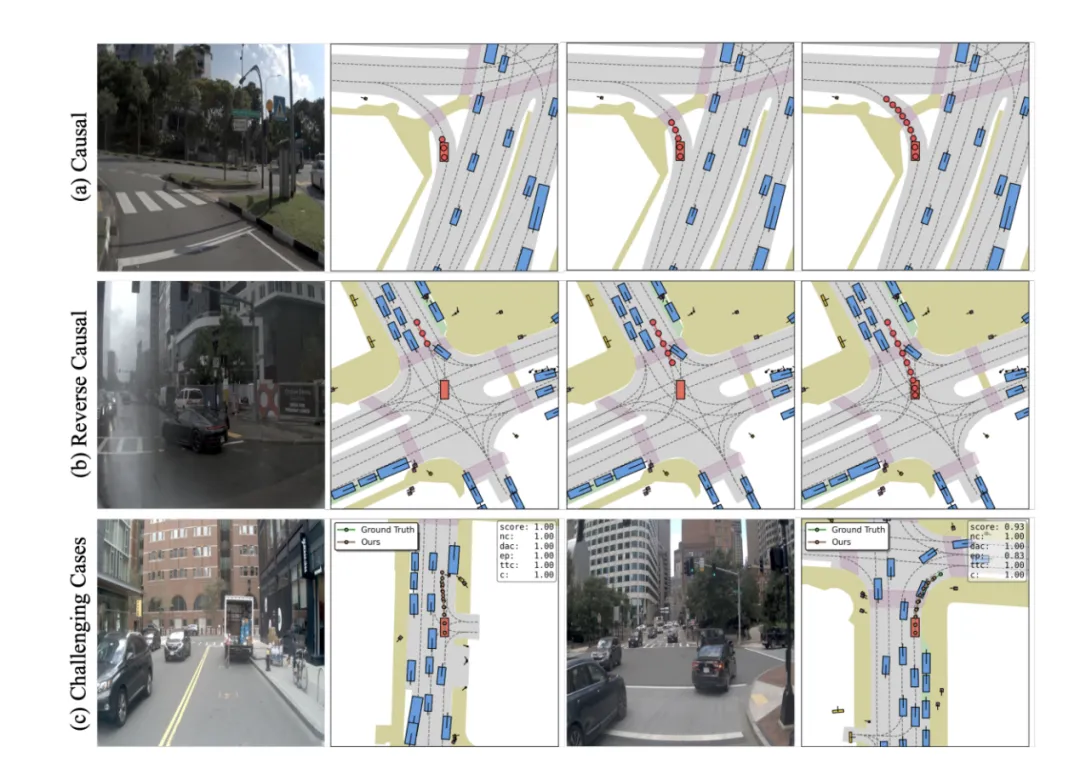
图片来源:引望智能
WAM-Diff 深入探索了因果序(Causal)、反因果序(Reverse-Causal)和随机序(Random)三种解码调度策略。实验结果揭示了一个反直觉但极具价值的现象:反因果序策略在闭环指标上表现最佳。这意味着,先确定远处的终点状态,再倒推近处的轨迹细节,这种「以终为始」的生成逻辑能显著提升规划的一致性与安全性。这一发现从模型层面验证了人类驾驶员在复杂博弈场景下的直觉思维。
不同场景下规划轨迹的 BEV 可视化与专家激活热力图
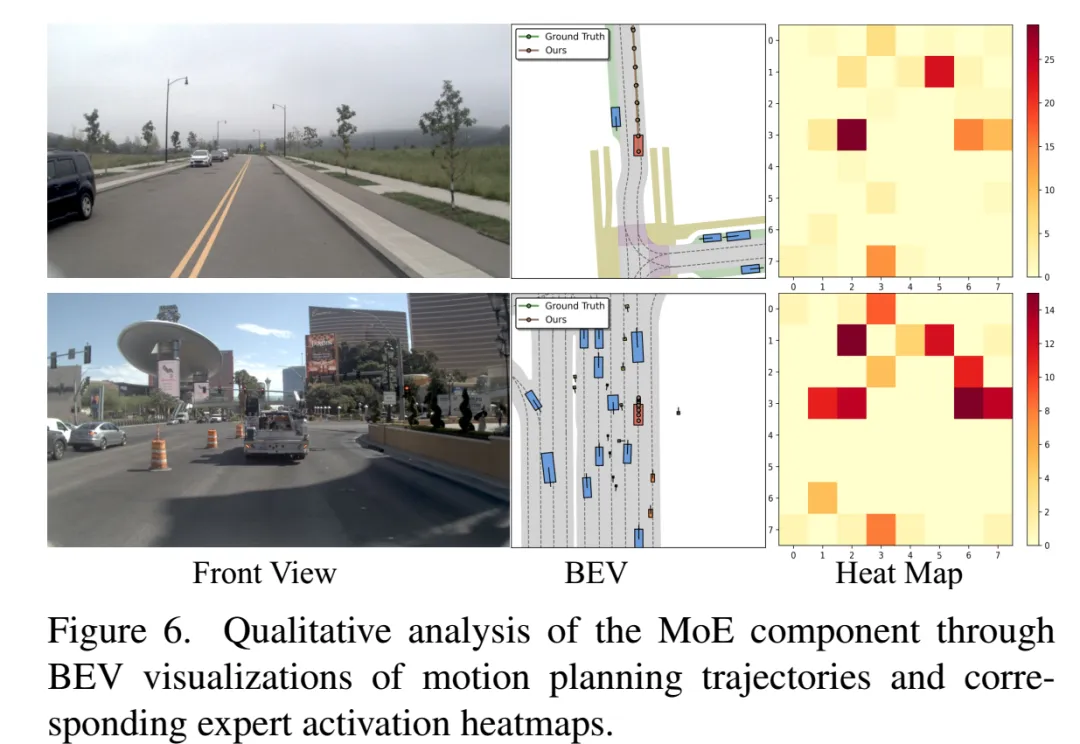
图片来源:引望智能
面对多变的驾驶场景,单一模型往往难以兼顾各种极端情况。WAM-Diff 通过在主干网络中集成 LoRA-MoE(Low-Rank Adaptation Mixture-of-Experts)架构来解决这一难题。模型包含 64 个轻量级专家,通过门控网络实现动态路由与稀疏激活。在推理过程中,模型能够根据当前场景自动激活最匹配的驾驶专家,在控制计算开销的同时显著提升了模型的容量与适应性。此外,团队采用了多任务联合训练策略,使模型在学习轨迹预测的同时,通过驾驶 VQA 任务理解场景语义。这使得专家网络不仅掌握了驾驶技能,更理解了驾驶决策背后的因果逻辑,显著增强了规划的可解释性与泛化能力。
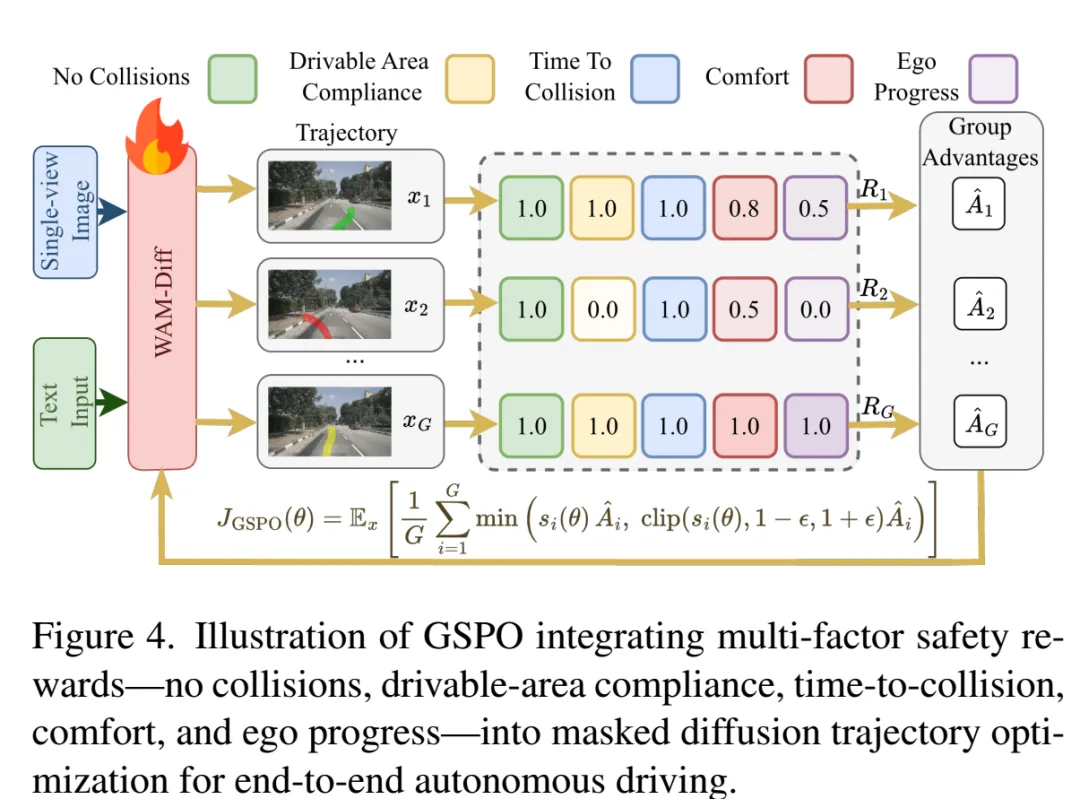
图片来源:引望智能
WAM-Diff 引入了分组序列策略优化(GSPO, Group Sequence Policy Optimization)算法,旨在弥合开环训练与闭环执行之间的鸿沟。GSPO 的核心思想是将优化粒度从「单步 Token」提升至「完整轨迹序列」。系统在仿真环境中采样一组候选轨迹,并依据NAVSIM的成绩得分作为强化学习的奖励,包括了安全性(碰撞检测)、合规性(车道保持)及舒适性(加减速平滑度)。通过计算组内相对优势,模型被显式引导向「高安全、高舒适」的区域更新。这种序列级的价值对齐机制,从根本上确保了规划结果不仅「像人」,而且比人类驾驶数据更安全、更规范。
WAM-Diff的骨干是非常冷门的VLM,即LlaDa-V,由中国人民大学高瓴人工智能学院李崇轩、文继荣教授团队与蚂蚁集团共同完成。主要作者游泽彬和聂燊是中国人民大学高瓴人工智能学院的博士生,导师为李崇轩副教授。研究团队将 LLaDA 作为语言基座,通过引入视觉编码器(SigLIP 2)和 MLP 连接器,将视觉特征投影到语言嵌入空间,实现了有效的多模态对齐。LLaDA-V 在训练和采样阶段均采用离散扩散机制,摆脱了自回归范式。参数为80亿。
自动驾驶的路线已经收敛,VLA+世界模型是大势所趋,VLA与世界模型不冲突,VLA可以吸收世界模型的90%优点,反过来世界模型几乎拿不到VLA的任何优点,但世界模型更容易占据宣传高地。
免责说明:本文观点和数据仅供参考,和实际情况可能存在偏差。本文不构成投资建议,文中所有观点、数据仅代表笔者立场,不具有任何指导、投资和决策意见。
更多报告
| AI机器人 | ||
AI机器人 | ||
| 云端和AI | ||
| 车云 | ||
| 动力层 | ||
| 动力 | 混合动力报告 | |
| 800-1000V高压平台 | 电驱动与动力域研究 | |
热管理 | ||
其他 |
| 电子电气架构层 | ||
| E/E架构框架 | E/E架构 | 汽车电子代工 |
| 48V低压供电网络 | ||
| 智驾域 | 自动驾驶SoC | |
| 座舱域 | 座舱域控 | |
| 车控域 | 车身(区)域控研究 | |
| 通信/网络域 | ||
| 跨域融合 | ||
| 其他芯片 | ||
| 车载存储芯片 |
| 智舱系统集成和应用层 | ||
智能座舱应用框架 | 座舱设计趋势 | |
自动驾驶算法和系统 |
| OS和支撑层 | ||
| SDV框架 | SDV:软件定义汽车 | |
信息安全/功能安全 |
| 其他宏观 | ||
| 车型平台 | 车企模块化平台 | |
| 政策、标准、准入 | 智能辅助驾驶法规和汽车出海 |
「AI与机器人月报」

「联系方式」
手机号同微信号

产业研究部丨赵先生 18702148304
推广传播部|杜先生 13910162318
随机文章
-
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
- 别再当“韭菜”了!马自达纯电SUV仅18万起,550km续航,比奔驰GLC电动版香太多
- 7座Suv出售25款奇瑞瑞虎8准新车原版原漆还
- 26款迈巴赫GLS600陆地行宫超豪华SUV 殿堂级舒适四座
- 问界M6开启预订!26.98万起,家用SUV卷王实锤了?
- 定位紧凑型SUV!吉利博越REV正式开启预售
- 前华为自动驾驶博士,把情绪装进了一台 80cm 的机器人
- #现代汽车设计 #白色SUV颜值 #SsangYongRod
- 智驾小强:自动驾驶强标解读2️⃣
- 马斯克“两手抓”自动驾驶:左手特斯拉FSD引入逻辑推理,右手自建2纳米晶圆厂——年产1000亿至2000亿颗AI及存储芯片
- 《华尔街日报》| 自动驾驶热潮重燃,十年前的愿景能否成真?
