📖 导读
这篇聚焦端到端自动驾驶评分式规划的突破性研究,直击现有规划方法的核心矛盾——端到端自动驾驶需通过多模态候选轨迹评分实现不确定性建模,但传统方案陷入“静态词汇覆盖不足”与“动态生成复杂度高”的两难:静态轨迹词汇受限于计算资源,离散化粗导致复杂场景适配性差;动态生成虽能提供细粒度候选,但需额外网络组件或迭代去噪,模型复杂度与推理成本激增。
清华大学、地平线等机构的Wenchao Sun、Xuewu Lin等研究者,通过系统性规模化研究证实:静态词汇的性能瓶颈源于“覆盖不足”而非固有缺陷。据此创新性提出SparseDriveV2,通过“轨迹分解表示+分层评分策略”双创新,将静态轨迹词汇密度提升至传统方法的32倍(262,144个候选),同时实现高效评分。其核心价值在于:将轨迹解耦为几何路径与速度轮廓,通过组合式覆盖扩大动作空间;采用“粗粒度因子化评分+细粒度轨迹评分”的两阶段策略,在超密集词汇下保持推理效率。该方案以轻量ResNet-34为骨干,在NAVSIM达成92.0 PDMS、90.1 EPDMS,在Bench2Drive实现89.15驾驶评分与70.00%成功率,超越主流动态生成方法,为端到端自动驾驶提供了“简单高效且高性能”的纯评分式规划范式。
研究通过多基准验证与消融实验,证实了静态词汇在充分覆盖与高效评分下的性能潜力,推动端到端规划从“动态生成依赖”向“静态词汇优化”转型。
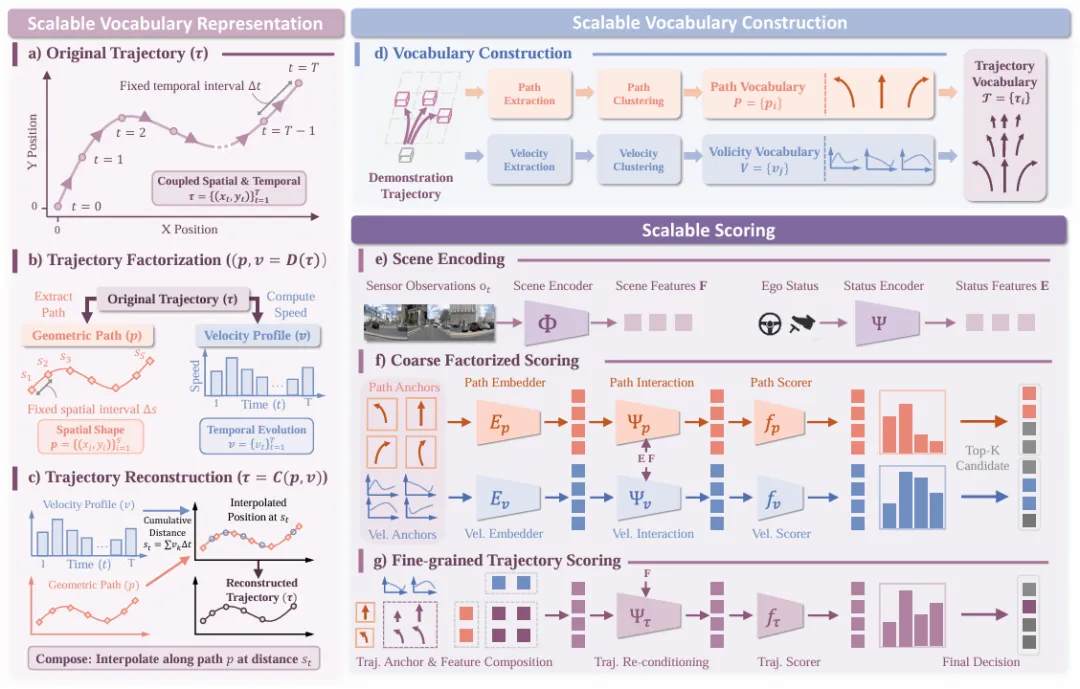
📷图1:Sparse DriveV2框架总览。Sparse DriveV2将(a)时空轨迹分解为(b)几何路径与速度曲线,并通过(c)组合这两个分量来重构轨迹。该表示方法可实现(d)由精简的路径集与速度曲线集构建而成的超密集轨迹词典。在(e)场景特征的约束下,该可扩展评分策略先对路径与速度曲线执行(f)粗粒度分解评分,以筛选出前k个候选结果,随后对组合后的轨迹进行(g)细粒度评分,最终生成规划决策。
论文核心信息
- 论文题目:SparseDriveV2: Scoring is All You Need for End-to-End Autonomous Driving(《评分即核心:端到端自动驾驶的超密集静态词汇规划方案》)
- 作者:Wenchao Sun、Xuewu Lin、Keyu Chen等(清华大学、地平线机器人有限公司等机构)
- 开源链接:https://github.com/swc-17/SparseDriveV2
- NAVSIM v1性能:PDMS达92.0,超越DiffusionDriveV2(88.1)、ipad(91.7)等动态生成方法;
- NAVSIM v2性能:EPDMS达90.1,较DiffusionDriveV2(87.5)提升2.6,核心指标EP( ego progress)达91.1;
- Bench2Drive性能:驾驶评分89.15、成功率70.00%、多能力均值67.67%,全面领先现有方案;
- 词汇规模:1024个路径锚点×256个速度锚点,组合形成262,144个轨迹候选,密度为传统方法(8192个)的32倍;
- 模型轻量化:采用ResNet-34骨干网络(21.8M参数),无需复杂生成模块,推理高效;
- 静态轨迹词汇的性能随密度增加持续提升,未出现饱和趋势,覆盖不足是其核心瓶颈;
- 轨迹的空间几何与时间速度可解耦表示,组合式词汇能以紧凑结构实现动作空间的超密集覆盖;
- 分层评分策略(粗粒度因子化筛选→细粒度轨迹评分)可在超密集词汇下控制计算成本,兼顾效率与性能;
- 纯评分式规划在充分覆盖与高效评分支撑下,性能可超越依赖动态生成的复杂方案;
- 路径-场景交互采用可变形聚合(DFA)比多头交叉注意力(MHA)更易捕捉空间线索,轨迹重条件化能建模路径与速度的时空依赖;
- 提出因子化轨迹表示,将轨迹解耦为几何路径与速度轮廓,通过组合式构建实现超密集词汇(32×密度提升),突破传统静态词汇的覆盖局限;
- 设计分层可扩展评分策略,先独立评分路径与速度以筛选高价值候选,再对组合轨迹进行细粒度评分,解决超密集词汇的评分效率问题;
- 验证静态词汇的规模化潜力,通过系统性实验证实“密度提升→性能增长”的线性关系,打破“动态生成更优”的固有认知;
- 引入轨迹重条件化机制,建模路径与速度的时空依赖,修正独立评分的假设偏差,提升复杂场景适配性;
- 核心主题:端到端自动驾驶、评分式规划、静态轨迹词汇、因子化表示、分层评分、超密集候选、轻量模型;
- 核心受众:自动驾驶算法工程师、端到端规划研究者、计算机视觉与机器人交叉领域学者、高校车辆工程/人工智能专业师生、车企研发人员。
❓ 现有端到端规划方法的四大“核心痛点”
- 静态词汇覆盖不足:传统静态轨迹词汇受计算资源限制,规模仅数千个,动作空间离散化粗,难以适配复杂驾驶场景(如急转弯、拥堵跟车);
- 动态生成复杂度高:动态生成方法(回归/扩散式)需额外网络组件或迭代去噪,模型参数与推理成本激增,不利于部署;
- 评分效率与覆盖矛盾:静态词汇密度提升会导致评分计算量线性增长,超密集词汇下传统单阶段评分策略不可行;
- 时空依赖建模缺失:轨迹的空间路径与时间速度存在固有依赖(如急弯需低速),独立设计候选或评分易导致不合理组合,影响规划安全性。
🔧 核心真相:论文多维度拆解“SparseDriveV2的突破机制”
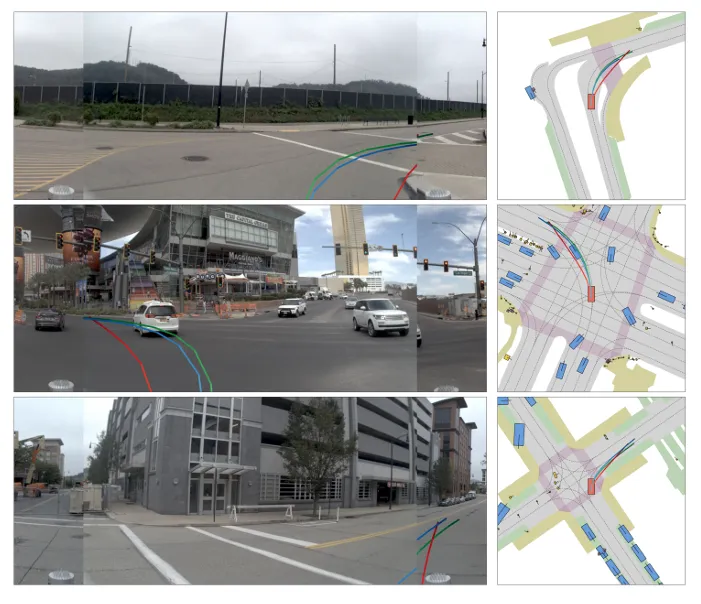
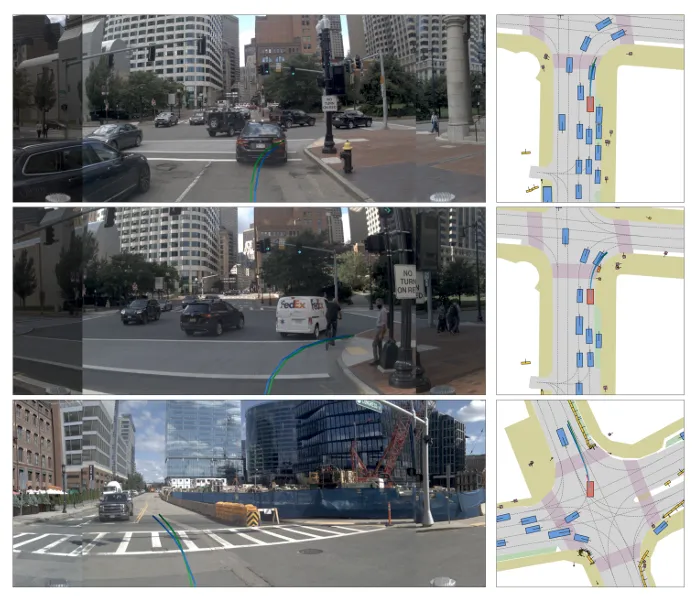
图2:在急转弯场景中,SparseDriveV2生成的轨迹比基线方法更平滑。
图3:SparseDriveV2实现了更高的通行效率,而基准方法则保持静止状态。
1. 词汇构建:因子化表示实现超密集覆盖(真相1)
SparseDriveV2的核心突破始于轨迹表示的解耦,通过“空间-时间分离+组合式构建”,以紧凑结构实现动作空间的超密集覆盖:
(1)轨迹因子化分解
- 几何路径(空间维度):定义为固定空间间隔(1m)采样的waypoint序列 (p={(x_i,y_i)}_{i=1}^S),仅编码运动几何形状,不含时间信息;
- 速度轮廓(时间维度):定义为固定时间间隔(0.5s)的速度序列 (v={v_t}_{t=1}^T),仅指定沿路径的行驶速度,与空间几何独立;
- 分解与重构:给定原始轨迹 (\tau),通过插值重采样提取路径与速度(((p,v)=\mathcal{D}(\tau)));反之,通过累积距离插值实现轨迹重构((\tau=\mathcal{C}(p,v))),公式如下:其中 (s_t) 为t时刻累计行驶距离,(\text{Interp}(p, s_t)) 表示沿路径p在距离 (s_t) 处的插值位置。
(2)组合式词汇构建
- 路径词汇:从人类驾驶数据中提取路径并通过K-Means聚类,得到1024个代表性路径锚点;
- 轨迹词汇:路径与速度的全组合形成 (1024×256=262,144) 个轨迹候选,密度为传统方法(8192个)的32倍,且词汇规模可通过调整路径/速度锚点数量灵活扩展。
2. 评分策略:分层筛选平衡效率与精度(真相2)
针对超密集词汇的评分效率问题,SparseDriveV2设计“粗粒度筛选+细粒度评分”的两阶段策略,仅对高价值候选进行精准评分:
(1)第一阶段:粗粒度因子化评分(筛选高价值候选)
- 路径评分:将路径锚点编码为嵌入,通过可变形聚合(DFA)与场景特征交互,捕捉路径与环境的适配性(如是否偏离车道、是否碰撞),预测粗路径得分 (s_i^p);
- 速度评分:同理,通过交叉注意力将速度锚点嵌入与场景特征融合,评估速度的合理性(如拥堵场景高速度不合理),预测粗速度得分 (s_j^v);
- 候选筛选:选择Top-Kp路径(如128个)与Top-Kv速度(如64个),组合形成 (K_p×K_v) 个高价值候选(如8192个),筛除大量低质量组合,将评分计算量从26万级降至千级。
(2)第二阶段:细粒度轨迹评分(建模时空依赖)
- 轨迹特征融合:将筛选后路径与速度的上下文嵌入相加,得到初始轨迹特征 (e_{i,j}^\tau=\tilde{e}_i^p+\tilde{e}_j^v);
- 轨迹重条件化:通过可变形聚合让轨迹特征与场景特征再次交互,建模路径与速度的时空依赖(如急弯路径匹配低速轮廓),修正独立评分的假设偏差;
- 最终评分:预测细粒度轨迹得分 (s_{i,j}^\tau),选择得分最高的轨迹作为规划输出。
3. 模型训练:多目标监督保障评分可靠性(真相3)
训练过程针对分层评分的不同阶段设计专属损失函数,同时融入规则化监督,确保评分模型的准确性与安全性:
(1)损失函数设计
- 路径损失:以真实路径为目标,计算路径锚点与真实路径的掩码均方距离,采用交叉熵损失监督粗路径评分;
- 速度损失:以真实速度轮廓为目标,计算L1距离,同样用交叉熵损失监督粗速度评分;
- 轨迹损失:计算候选轨迹与真实轨迹的L2距离,通过交叉熵损失监督细粒度评分;
- 规则化损失:引入基于规则的教师系统,对候选轨迹的安全性、舒适性、交通规则符合性进行评分,采用二元交叉熵损失监督模型预测这些子指标。
(2)训练流程
- 数据:采用NAVSIM的navtrain数据集(1192个训练场景)与大规模人类驾驶演示数据;
- 硬件:8张NVIDIA L20 GPU,批大小128,训练10个epoch,学习率1e-4;
- 优化:对NAVSIM v2场景,调整第二阶段速度锚点筛选数量至10个,加速指标真值计算。
4. 关键优化:交互机制与依赖建模(真相4)
(1)路径-场景交互:可变形聚合更优
- 对比实验显示,路径-场景交互采用可变形聚合(DFA)比多头交叉注意力(MHA)更有效:DFA能沿路径几何采样场景特征,捕捉更精准的空间线索(如车道线、障碍物位置),使EPDMS从87.7提升至89.9。
(2)轨迹重条件化的必要性
- 消融实验证实,轨迹重条件化能显著提升性能:无重条件化时EPDMS为89.9,加入后提升至90.1,尤其在急弯、拥堵等需要时空协同的场景中效果明显,避免“急弯+高速”等不合理组合。
关键内容
1. 主流规划方法在NAVSIM的性能对比(ResNet-34骨干)
2. Bench2Drive核心性能对比
3. 消融实验关键结果(NAVSIM v2)
💬 Q&A
Q1:SparseDriveV2为何将轨迹分解为路径与速度?这种因子化表示的核心优势是什么? A:轨迹分解的核心逻辑是“空间与时间维度的解耦优化”,优势体现在三个方面:① 覆盖效率高,路径与速度的组合式构建能以紧凑词汇规模实现超密集覆盖——1024个路径锚点+256个速度锚点即可形成26万+轨迹候选,密度是传统单一体词汇的32倍,无需盲目增加锚点数量;② 适配不同场景需求,路径聚焦空间几何(如车道保持、转弯),速度聚焦时间动态(如加速、减速),可分别针对复杂路况与交通流优化;③ 评分效率优化,因子化表示支持独立的粗粒度评分,能快速筛除低质量组合(如拥堵场景的高速度、直道的急转路径),大幅降低后续细粒度评分的计算量,解决超密集词汇的效率难题。
Q2:分层评分策略与传统单阶段评分相比,优势在哪里?如何平衡效率与精度? A:分层评分的核心优势是“以粗筛细,兼顾效率与精度”,具体平衡逻辑:① 效率提升,传统单阶段评分需遍历所有26万+候选,计算量巨大;分层策略先筛选出8192个高价值候选(128路径×64速度),再进行细粒度评分,计算量仅为传统方法的3.125%,推理效率大幅提升;② 精度保障,粗粒度评分已通过场景特征交互筛选出适配当前环境的路径与速度,细粒度评分仅需聚焦少量高潜力组合,且通过轨迹重条件化建模时空依赖,修正独立评分的偏差,精度未受损失;③ 灵活性强,Top-K筛选的K值可根据硬件资源动态调整,资源充足时增大K值提升精度,资源有限时减小K值保障效率,适配不同部署场景。
Q3:SparseDriveV2作为纯评分式方法,为何能超越动态生成方法?其性能提升的核心来源是什么? A:核心原因是“超密集覆盖+高效评分”的双重优势,性能提升来源明确:① 覆盖更充分,32倍密度的静态词汇能更精细地覆盖动作空间,避免动态生成可能的候选缺失问题,尤其在复杂场景中能提供更多合理轨迹选项;② 模型更高效,无需动态生成的额外网络(如扩散去噪模块、迭代优化器),轻量ResNet-34骨干的推理速度更快,且避免了生成过程中的不确定性(如生成不合理轨迹);③ 评分更精准,分层评分结合轨迹重条件化,既能筛选高价值候选,又能建模时空依赖,评分模型的监督信号更充分,决策可靠性更高;④ 数据利用更高效,基于人类驾驶数据的聚类锚点能更好地对齐真实驾驶分布,避免动态生成的模式崩塌问题。
Q4:轨迹重条件化机制的作用是什么?为何路径与速度的独立评分不足以支撑高质量规划? A:轨迹重条件化的核心作用是“建模路径与速度的时空依赖”,修正独立评分的假设偏差:① 独立评分假设路径与速度相互独立,但真实驾驶中二者存在强依赖(如急弯路径需匹配低速,直道路径可适配高速),独立评分可能筛选出“急弯+高速”等不合理组合,导致规划风险;② 重条件化通过让组合后的轨迹特征与场景特征再次交互,能识别并修正这类不合理组合,例如在急弯场景中,即使路径和速度单独评分较高,重条件化也会降低“急弯+高速”组合的最终得分;③ 消融实验证实,加入重条件化后EPDMS从89.9提升至90.1,尤其在复杂场景中效果更显著,是保障规划安全性与合理性的关键。
Q5:SparseDriveV2的工程化部署潜力如何?面临哪些实际挑战? A:部署潜力突出,但需解决三大挑战:① 部署优势,模型轻量(ResNet-34骨干仅21.8M参数),推理效率高(分层评分筛除大量候选),无需复杂生成模块,硬件适配性强;② 核心挑战:一是词汇存储,26万+轨迹锚点的存储需优化,可通过量化压缩或动态生成锚点减少存储开销;二是场景泛化,聚类锚点基于训练数据,未见过的极端场景(如特殊道路标识、突发障碍物)可能存在覆盖不足;三是实时性优化,虽分层评分已降低计算量,但在高帧率需求场景(如10Hz以上),仍需进一步优化筛选策略与模型推理速度;③ 解决路径:通过模型量化、锚点动态裁剪、硬件加速(如TensorRT)进一步提升实时性;引入在线自适应锚点生成,补充极端场景的候选覆盖;结合高精地图信息,优化路径锚点的合理性。
🎯 点评
- 核心贡献:首次通过因子化表示与分层评分,将静态轨迹词汇密度提升至传统方法的32倍,证实纯评分式规划可超越动态生成方法;提出“轨迹分解-组合构建-分层评分”的完整范式,解决静态词汇“覆盖不足”与“效率低下”的核心矛盾;系统性验证静态词汇的规模化潜力,打破“动态生成更优”的固有认知,为端到端规划提供更简洁高效的技术路径。
- 亮点:① 覆盖与效率兼得,超密集词汇保障场景适配性,分层评分控制计算成本,平衡性能与部署需求;② 模型轻量高效,无需复杂生成模块,ResNet-34骨干即可实现SOTA性能,工程化潜力突出;③ 实验扎实全面,通过规模化研究、多基准验证、 ablation实验,充分论证各创新点的有效性;④ 认知突破,证实静态词汇的性能瓶颈源于覆盖不足而非固有缺陷,为端到端规划提供新的优化方向。
- 不足:① 极端场景覆盖仍有局限,聚类锚点依赖训练数据,未见过的特殊场景可能存在候选缺失;② 词汇存储开销较大,26万+轨迹锚点的存储需进一步优化;③ 未充分探索多传感器融合(如LiDAR+相机)对评分模型的提升;④ 闭环测试场景有限,复杂交互场景(如多车博弈、道路施工绕行)的鲁棒性需进一步验证。
🌟 总结金句
端到端自动驾驶规划的核心,不在于“动态生成的复杂精巧”,而在于“静态词汇的充分覆盖与高效评分”——SparseDriveV2以轨迹因子化打破覆盖局限,以分层评分平衡效率成本,用轻量模型实现超越动态生成的性能,证明“评分即核心”的纯静态规划范式,为自动驾驶的高效部署提供了更简洁、更可靠的技术路径。
📌 互动引导
你认为SparseDriveV2实现工程化部署最需要优先突破的瓶颈是什么?
● ✅ 词汇存储优化(降低26万+锚点的存储开销);
● ✅ 极端场景泛化(补充未见过场景的候选覆盖);
● ✅ 实时性提升(进一步优化筛选策略与模型推理速度);
● ✅ 多传感器融合(结合LiDAR等提升评分模型精度);
● ✅ 复杂交互鲁棒性(增强多车博弈、突发场景的适配性);
欢迎在评论区分享观点,一起探讨纯评分式规划的工程落地路径 👇
🧩 思考/研究 Idea 彩蛋(可操作方向)
- 动态锚点生成:结合场景特征动态生成路径与速度锚点,而非固定聚类,提升极端场景覆盖,适合投稿《IEEE Transactions on Intelligent Transportation Systems》;
- 多传感器融合评分:引入LiDAR点云特征,优化路径与速度的评分模型,提升恶劣天气下的鲁棒性,适合投稿《ICRA》;
- 词汇压缩与量化:采用量化、稀疏编码等技术优化锚点存储,降低部署开销,适合投稿《Neural Computing and Applications》;
- 多智能体博弈适配:扩展分层评分策略,考虑其他车辆的交互行为,优化轨迹候选的安全性,适合投稿《ECCV》;
- 在线自适应筛选:基于实时场景复杂度动态调整Top-K值,平衡精度与实时性,适合投稿《IEEE Robotics and Automation Letters》;
- 轻量化骨干设计:采用MobileNet、EfficientNet等轻量骨干,进一步降低模型参数与推理延迟,适合投稿《Journal of Systems Architecture》;
- 强化学习优化评分:用强化学习替代监督学习优化评分模型,提升闭环驾驶的长期收益(如通行效率、舒适性),适合投稿《NeurIPS》。

 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
