长安汽车与中科院合作,世界模型自动驾驶第一
- 2026-04-20 14:36:36
2026年3月底,长安汽车与中科院自动化研究所联合发表两篇论文,刷新世界模型自动驾驶成绩纪录,EPDMS得分达89.3。一篇论文是DreamerAD: Efficient Reinforcement Learning via Latent World Model for Autonomous Driving,项目leader是Yupeng Zheng,3月底同样是Yupeng Zheng做项目leader发表了名字非常近似的另一篇论文Latent-WAM: Latent World Action Modeling for End-to-End Autonomous Driving,EPDMS得分达89.3,是目前EPDMS得分最高的世界模型自动驾驶算法,能超越Laten-WAM的只有华为的WAM-Diff: A Masked Diffusion VLA Framework with MoE and Online Reinforcement Learning for Autonomous Driving,目前EPDMS得分89.7,采用非常冷门的LLADA-V-8B做VLM,是目前所有端到端算法EPDMS得分第一名。
DreamerAD的原创性不高,其核心世界模型是用的地平线的Epona做骨干,参数有25亿,仅仅是用强化学习增强,Latent-WAM则原创性比较高,且模型极小,参数只有1.04亿,训练时间也只有25小时,训练数据完全使用零成本的网络非标注数据,无论是训练成本还是实际上车的推理硬件成本,都大幅降低了90%以上。
2025年下半年以来,有关世界模型自动驾驶的论文大幅度增加,测试成绩也越来越好,大有超越VLA的趋势,不过世界模型自动驾驶的测试基准平台基本上都选择NAVSIM v2版的EPDMS,VLA则喜欢选择开环测试的nuScenes,非VLA也非世界模型的喜欢选择NAVSIM v1版的PDMS,很难说这是不是刻意而为,毕竟目前很少论文提及开环测试的nuScenes了,不过早期世界模型在开环测试的nuScenes上得分很低,完全被VLA碾压。
当然,NuScenes,是为感知专门设计的,优先考虑的是感知场景的多样性和标注准确性,并不适用于规划任务。事实上,大约 75% 的 nuScenes 场景涉及简单的直线驾驶,其中仅基于运动自我状态(忽略感知)的 MLP多层感知机就可以实现最好的 ADE(平均位移误差)指标。NuScenes 仅支持开环评测(open-loop evaluation),常常用 ADE/FDE 等简单的指标,无法评测安全性(safety)、舒适性(comfort)和驾驶完成度(progress)等更重要的指标。
有必要来了解一下目前端到端自动驾驶的最常用评价体系,NAVSIM。
NAVSIM 是介于开环和闭环评测之间一种新的评测方案,旨在同时获得 NuScenes 这种开环评测集的数据丰富度,以及 NuPlan 这种数据闭环评测集的指标丰富度。这是一种数据驱动的非反应式的自动驾驶仿真&基准测试方案(Data-Driven Non-Reactive Autonomous Vehicle Simulation & Benchmarking)。
NAVSIM 框架本身和数据集无关。任何包含已标注的高清地图(annotated HD maps)、物体边界框(object bounding boxes)和传感器数据(sensor data)的数据集都可以转成 NAVSIM 格式,用来评测。NAVSIM 选择基于 OpenScenes 数据集制作标注数据集。这是一个 NuPlan 的子集,包含 120 小时的驾驶数据,以 2Hz 的频率进行采样。原始数据包含 8 个相机的原始图像(1920x1080)和从 5 个 LiDAR 传感器拼接得到的点云数据。
具体来说:输入第一帧的感知输入和历史轨迹,Planning 轨迹规划算法给出未来一段时间(这里取 h=4s)的轨迹,然后假设未来 4s 这个轨迹固定,自车不会再接受其他环境输入,其他 agent 的行为也不会因为这个轨迹而变化。因为 NAVSIM 的评测完全基于初始帧的输入,评测的轨迹不能太长,否则误差会累积得越来越大。所以,NAVSIM 只评测 4秒 的轨迹输出。这个时长对于闭环评测已经足够( 在NuPlan 的论文里已经论证)。仿真评测 planning 轨迹,需要模拟车辆真的按轨迹行进。在每个仿真迭代里,NAVSIM 用LQR controller 来计算车辆的转角和加速度值,用一个 kinematic bicycle mode两轮自行车动力学模型来计算车辆在仿真模式下的位置。
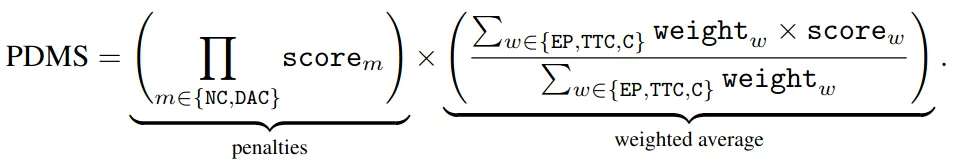
PDMS分为得分项和惩罚项,惩罚项是NC和DAC,对于和交通参与者发生碰撞,或者驶出可行驶区域,与护栏等障碍物碰撞的行为:NC(no collision),DAC (drivable area compliance), 这两项得分分别为 0,这会直接导致这一帧的 PDMS=0。与静态目标碰撞的得分0.5,得分项包括TTC(碰撞时间)、Comf(舒适度)和EP,其中TTC 用来保证自车和他车的安全距离,默认为1。Comfort:就是比较轨迹里的 acceleration 和 jerk 是否在一个提前设置的阈值范围内。EgoProgress(EP):指的是预测轨迹沿着 route center line 路由中心线行进,EP被计算后会归一化到。
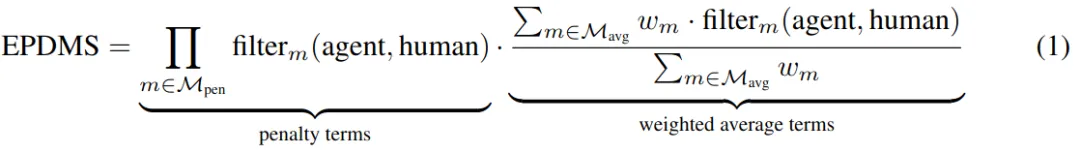
EPDMS进一步细分为9个小类。
图片来源:网络
EPDMS增加了交通信号灯、驾驶方向、车道保持,细化了舒适性,同时引入过滤机制,如果在同一场景中人类专家驾驶员也实施了违反规则的行为,则忽略该惩罚。这避免了因标签噪声或有效行为而受到惩罚的违规行为,例如短暂地进入对向车道以绕过静态障碍物。
目前来看,非世界模型的传统分段式端到端算法的EPDMS得分普遍比PDMS要低一点,VLA也是如此,世界模型则相反,推测是过滤机制对世界模型有加分。
回到这篇Latent-WAM: Latent World Action Modeling for End-to-End Autonomous Driving论文,共有16位作者,其中7位来自长安汽车,项目领头人Yupeng Zheng即郑宇鹏发表过多篇有关世界模型自动驾驶的论文,郑宇鹏曾经是理想汽车实习研究员,中科院自动化所在读博士。
Latent-WAM基础主要来自三篇论文:
第一篇是Enhancing End-To-End Autonomous Driving with Latent World Model,发表于2024年6月,是中科院自动化研究所世界模型的开山之作,
第二篇是World4Drive: End-to-End Autonomous Driving via Intention-aware Physical Latent World Model,
第三篇是WorldRFT: Latent World Model Planning with Reinforcement Fine-Tuning for Autonomous Driving。后两篇是自动化研究所和理想汽车合作发表的论文。
世界模型与传统端到端自动驾驶区别
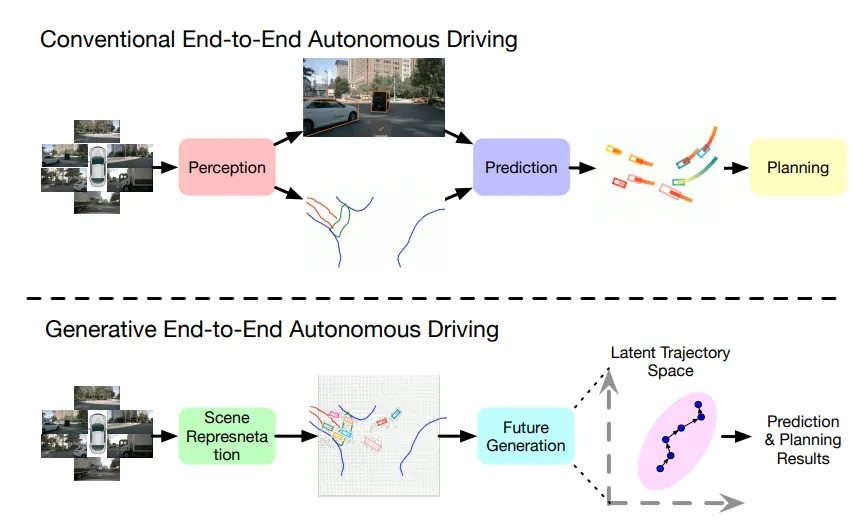
图片来源:GenAD论文
世界模型自动驾驶与传统端到端自动驾驶实际差异不大,两者核心都是对生成下一帧的预测,传统端到端是模仿学习,世界模型是使用非标注数据的强化学习。两者的前半段基本是完全相同,主要差别在轨迹解码阶段。
传统的E2E做法是多个模块连接起来的形式,用历史的feature进行交互,完成预测后再进行规划(这是单向的交互)。无法很好地处理agent未来意图和ego规划的轨迹之间的双向交互。世界模型做法是预测了未来的场景变化后再进行每个agent的预测。采用了变分自编码器(VAE)的建模方式,建立每个agent的行为模式,用以生成未来场景的分布。然后用一步一步预测的形式来实现ego和周围agent的特征融合,以此更好地生成ego的轨迹。
VAE是一种结合了自编码器和变分推断的生成模型,是世界模型的核心组件,出现在2018年,即将高维的图像帧(如来自游戏环境的2D图像)压缩成低维的 latent 表示。它通过神经网络(编码器和解码器)学习数据的潜在分布,将输入数据映射到低维隐空间(潜在变量),然后从该空间中采样生成新数据。VAE的核心在于通过变分推断近似后验分布,并引入重参数化技巧解决采样的不可导问题,从而实现高效的反向传播训练。
LAW世界模型自动驾驶
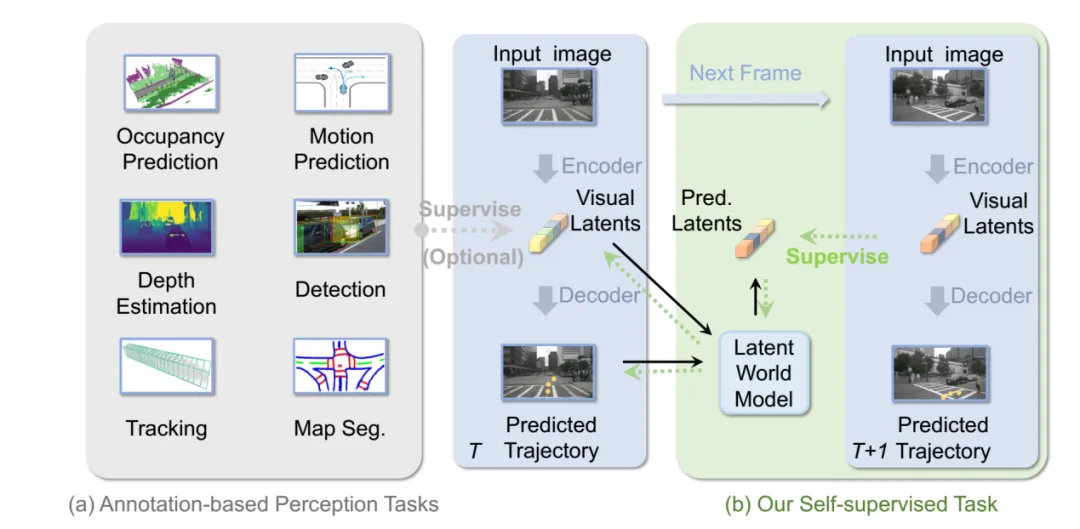
图片来源:论文《Enhancing End-To-End Autonomous Driving with Latent World Model》
监督信号V_{t+1}来自编码器对真实未来帧的自动提取,无需人工标注。这实现了数据自举——用模型自身提取的特征监督另一分支的预测能力。驾驶规划的本质是未来状态的概率推理,而非像素完美重构。基于此,论文Enhancing End-To-End Autonomous Driving with Latent World Model提出LAtent World model (LAW),在潜空间直接预测未来特征,将自监督信号从像素域提升到语义域。这一范式的数学优雅性体现在其规避了高维图像分布建模,转而学习紧凑、动作条件化的潜动态。不生成未来图像,而是直接在潜空间预测未来特征!这消除了扩散模型那种秒级延迟的噩梦。
LAW模型框架
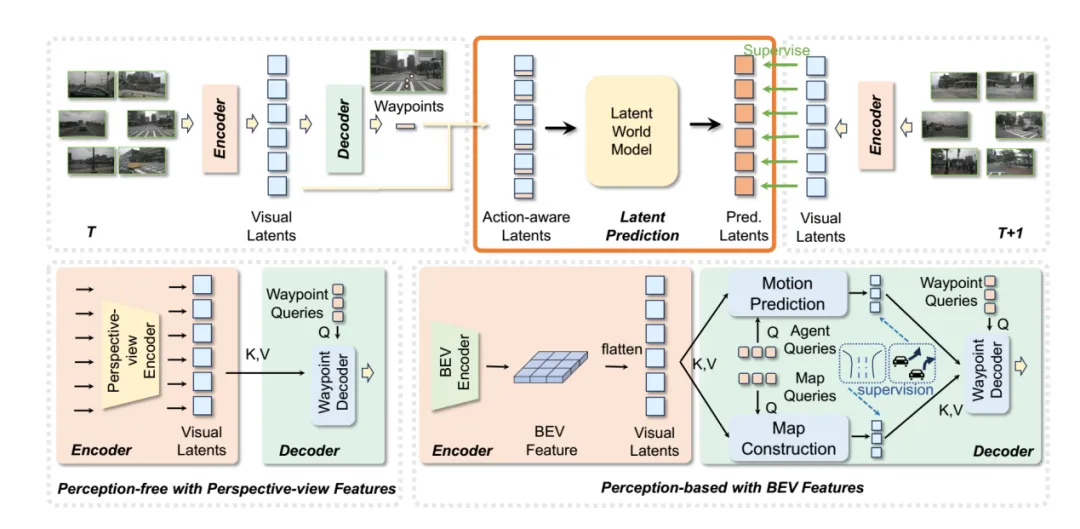
图片来源:论文《Enhancing End-To-End Autonomous Driving with Latent World Model》
核心思路:在 latent 空间(而非像素空间)构建一个生成预测的世界模型,把这个预测和真实未来 latent 对齐,作为一个自监督任务,与轨迹监督联合训练。该任务能无缝插入两类主流端到端框架:Perception-free:直接从图像到轨迹;Perception-based:在 BEV 表示上做 detection / map segmentation / motion prediction 多任务学习。后来世界模型自动驾驶都遵循这种思路,并且研究表明免感知任务的效果远不如加入感知的,而这个感知也逐渐进化,论文World4Drive:End-to-End Autonomous Driving via Intention-aware Physical Latent World Model,感知包含了深度信息、语义信息和3D位置信息。论文WorldRDT进化为VGGT,Latent-WAM再进化为WorldMirror。
Latent-WAM框架
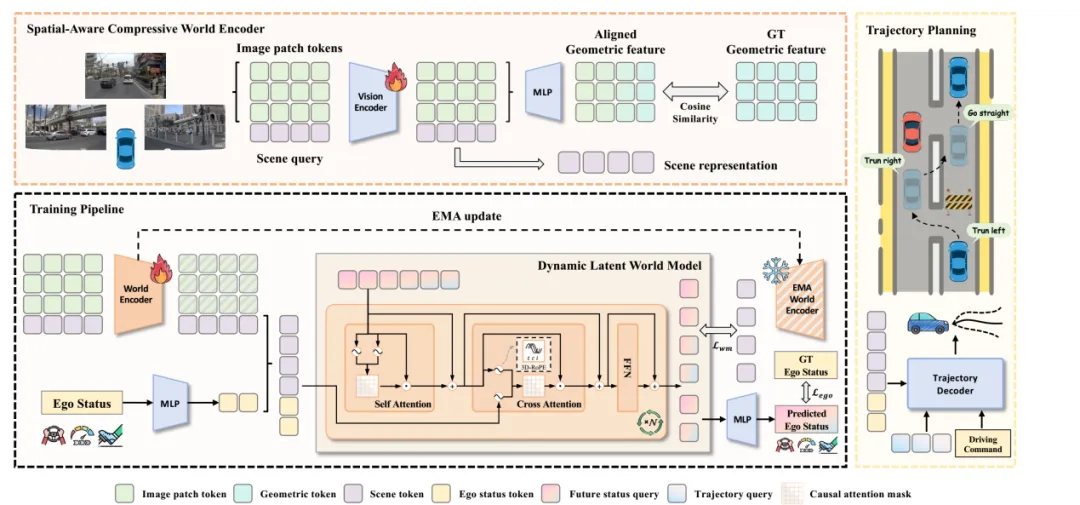
图片来源:论文《Latent-WAM: Latent World Action Modeling for End-to-End Autonomous Driving》
Latent-WAM两大核心模块(上图):空间感知压缩世界编码器(Spatial-Aware Compressive World Encoder, SCWE) 和 动态隐世界模型(Dynamic Latent World Model, DLWM)。
WorldMirror框架
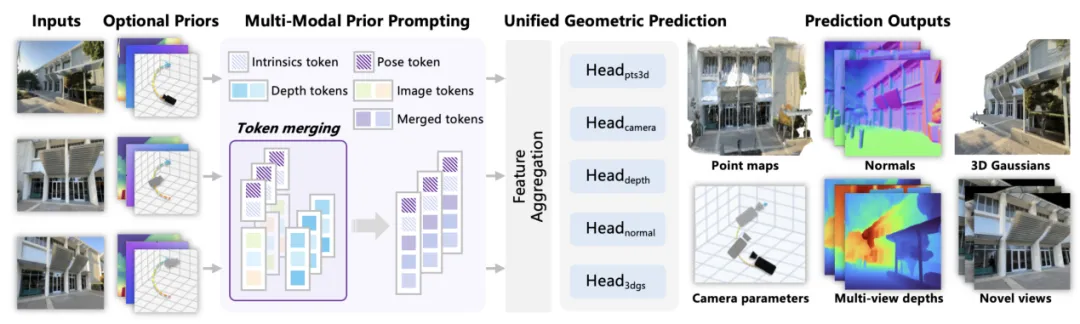
图片来源:腾讯混元
所谓空间感知压缩世界编码器(SCWE)实际是利用腾讯混元和浙江大学的WorldMirror基石空间模型,将其蒸馏,通过计算余弦相似度损失,让潜在空间世界表征与显性的空间几何对齐,这点和小米汽车的LaST-VLA异曲同工,小米是通过蒸馏,为潜在空间世界提供显性的空间几何约束。
动态隐世界模型(DLWM)实际就是一个视频生成模型,Latent-WAM吸取了香港科技大学与阶跃星辰团队的自回归视频生成框架——MAGI(掩码自回归视频生成模型)。
Latent-WAM 引入 3D-RoPE 将时空位置信息注入多头注意力。将head维度切分成三部分,分别编码:时间坐标,camera index和 token index。使用绝对位置索引编码三个坐标,使模型能够区分长序列中不同时间帧(50Hz)、不同相机视角(10Hz)和不同位置的 token(100Hz)。三维旋转位置编码(3D Rotary Position Encoding, 3D-RoPE):3D-RoPE 受量子力学的 Bloch 球的启发,将旋转位置编码应用于三维球面。旋转位置编码为一种新颖的Transformer架构中相对位置编码技术,因其能将位置信息以旋转变换的方式融入嵌入向量,并自然地在自注意力机制中体现相对位置关系,比绝对位置编码更有效,在VLM领域使用得比较频繁。
准确预测自车状态对建模世界动态至关重要。从预测的未来世界状态中提取自车状态嵌入 ,通过三个独立 MLP 解码,分别预测驾驶指令 、速度 和加速度 ,提供精确的世界状态转移引导。可学习的轨迹查询 τ 与当前世界状态表示 一同送入解码器,经轻量 MLP 解码为多条候选轨迹,根据当前驾驶指令 选择对应轨迹作为最终输出。
Latent-WAM训练方法源自RNN的“教师强制 (Teacher Forcing)”的技术,在标准的 RNN 前向传播过程中,模型在时间步 t 的输入通常是时间步 t-1 的输出。 然而,在教师强制中,我们强制模型在时间步 t 的输入为时间步 t-1 的真实目标值,而不是模型在时间步 t-1 的预测输出。就好比在学习过程中,老师直接给出正确的答案,让学生根据正确答案进行下一步的学习,而不是让学生根据自己可能错误的答案继续学习。
Latent-WAM推理时仅需空间感知压缩编码器和轨迹解码器,无需任何额外模块,也不需要「先想象,后行动」的 WAM (World Action Module)范式,便能够实现高效的轨迹规划。

Latent-WAM只是在训练时使用世界模型,训练完成后,完全看不到世界模型的痕迹,与传统的端到端自动驾驶完全相同,因此参数规模很小,只有1.04亿,使用单张英伟达A100显卡,延迟只有107毫秒,不过A100的性能可不弱,稀疏8位精度下AI算力达1248TOPS,仍然远超英伟达Thor-U的700TOPS,最重要的是A100使用的是HBM内存,存储带宽高达1935GB/s,是英伟达Thor-U的7倍。如果用Thor-U取代A100,延迟估计至少是200毫秒以上,虽然Latent-WAM的参数量很小,但其模型设计异常复杂,有很多非线性运算或矩阵旋转行为,世界模型轨迹解码器是一步步推算,近似RNN串行算法,GPU无法加速。
英伟达Jetson Thor运行VLM的延迟分析
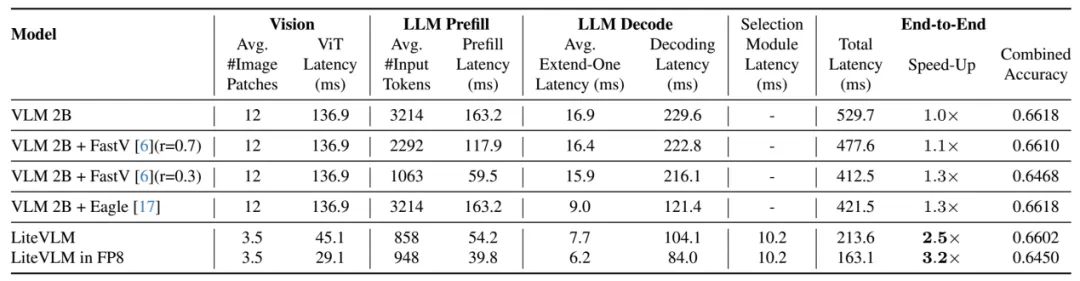
数据来源:论文《LiteVLM: A Low-Latency Vision-Language Model Inference Pipeline for Resource-Constrained Environments》
这是使用英伟达Jetson Thor运行VLM的延迟分析,
如果是VLA,即使参数有20亿,是Latent-WAM的19倍,但因为模型架构简洁,即使使用性能远低于A100的Jetson Thor,不做任何优化也能做到530毫秒,若换成A100,估计可以做到300毫秒。
世界模型性能提升很快,参数也远低于VLA,但计算延迟依然做不到能够实际落地的10Hz,同时世界模型也面临完全黑盒化的问题,缺乏可解释性。
Latent-WAM的出现说明自动驾驶算法没有护城河,算法的核心都是超级科技巨头谷歌或阿里这样的企业所掌控,汽车行业是站在巨人的肩上进行竞争,自然没有人能绝对领先,长安汽车这种传统厂家只要拉上中科院在读博士也可以轻易打造顶尖的世界模型。
免责说明:本文观点和数据仅供参考,和实际情况可能存在偏差。本文不构成投资建议,文中所有观点、数据仅代表笔者立场,不具有任何指导、投资和决策意见。
更多报告
| AI机器人 | ||
AI机器人 | ||
| 云端和AI | ||
| 车云 | ||
| 动力层 | ||
| 动力 | 混合动力报告 | |
| 800-1000V高压平台 | 电驱动与动力域研究 | |
热管理 | ||
其他 |
| 电子电气架构层 | ||
| E/E架构框架 | E/E架构 | 汽车电子代工 |
| 48V低压供电网络 | ||
| 智驾域 | 自动驾驶SoC | |
| 座舱域 | 座舱域控 | |
| 车控域 | 车身(区)域控研究 | |
| 通信/网络域 | ||
| 跨域融合 | ||
| 其他芯片 | ||
| 车载存储芯片 |
| 智舱系统集成和应用层 | ||
智能座舱应用框架 | 座舱设计趋势 | |
自动驾驶算法和系统 |
| OS和支撑层 | ||
| SDV框架 | SDV:软件定义汽车 | |
信息安全/功能安全 |
| 其他宏观 | ||
| 车型平台 | 车企模块化平台 | |
| 政策、标准、准入 | 智能辅助驾驶法规和汽车出海 |
「AI与机器人月报」

「联系方式」
手机号同微信号

产业研究部丨赵先生 18702148304
推广传播部|杜先生 13910162318

