在自动驾驶、AR/VR这些前沿领域,360°全景场景理解是绕不开的核心难题。现有的视觉-语言模型(VLMs)大多为窄视野的针孔图像设计,面对全景场景时,只能靠拼接多张局部图来拼凑理解。这种方式不仅割裂了场景的整体空间关系,还没法应对全景图的几何畸变问题。近期,一篇聚焦全景-语言建模的研究成果给出了全新解决方案。该研究提出了首个大规模全景视觉问答基准PanoVQA,设计了适配全景图的稀疏注意力机制,构建了全景语言模型(PLM)框架,让模型真正实现了超越多视角拼接的360°全场景理解能力。
论文信息
题目: More than the Sum: Panorama-Language Models for Adverse Omni-Scenes
全景语言模型:面向复杂全场景的超越性理解
作者: Weijia Fan, Ruiping Liu, Jiale Wei, Yufan Chen, Junwei Zheng, Zichao Zeng, Jiaming Zhang, Qiufu Li, Linlin Shen, Rainer Stiefelhagen
一、全景理解的核心痛点:数据与架构双重卡壳
现有VLMs在全景场景应用中,主要面临两大挑战:
- 缺乏适配的大规模数据集。现有数据集要么是多视角针孔图像的VQA数据,要么只有全景图却无对应的问答配对,更缺少遮挡、事故这类复杂场景的测试数据,没法验证模型的真实推理能力。
- 模型架构不兼容。全景图常用的等距柱状投影(ERP)格式,会带来严重的几何畸变,且分辨率远高于普通针孔图像。传统VLMs的密集注意力机制计算复杂度高,既处理不了畸变问题,也没法建模全景图左右边缘相连的拓扑特性。
二、PLM全景语言模型:重构360°场景理解范式
研究提出的全景语言模型(PLM),从根本上改变了全景场景的处理思路——不再拼接局部图,而是直接将单张360°全景图作为统一输入,完整保留场景的整体空间和上下文关联。
PLM的整体架构如图4所示,核心由三部分构成:全景增强的ViT、基于MLP的融合器、大语言模型(LLM)。为了兼顾局部细节和全局依赖,研究对标准ViT做了关键修改,并行加入滑动窗口注意力(SWA)和全景稀疏注意力(PSA),形成全景混合注意力(PHA)。
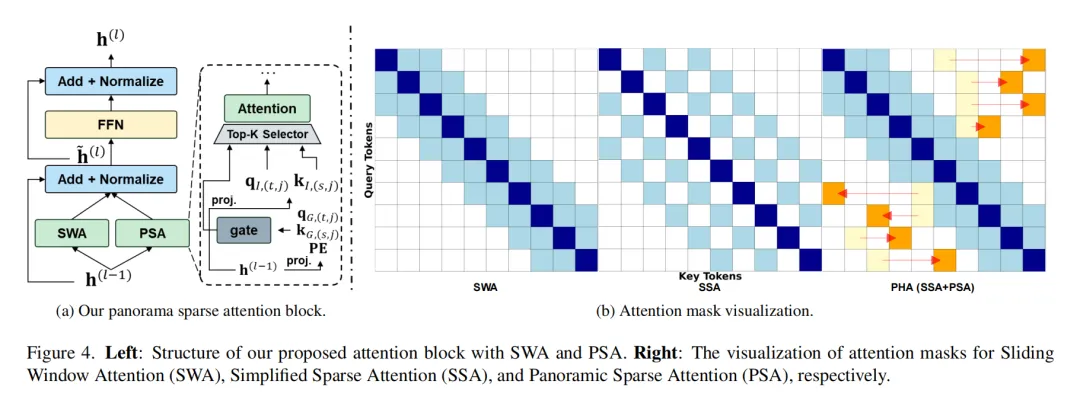 图4:PLM全景语言模型整体架构图
图4:PLM全景语言模型整体架构图
先来看滑动窗口注意力(SWA)。它负责捕捉细粒度的局部模式,把输入序列分成多个非重叠窗口,在每个窗口内独立计算自注意力。这种方式把计算复杂度从O(L²)降到O(L·Lw),但缺点是不同窗口间的令牌无法交互,没法建模全局上下文。
而全景稀疏注意力(PSA)则解决了全局依赖的问题。它会为每个查询令牌动态选择Top-K个最相关的键令牌,只在这些关键令牌对之间计算注意力。为了让选择过程更精准,PSA还引入了门控网络,结合可学习的位置嵌入,让模型能感知令牌的位置信息,同时过滤掉无信息的区域,适配全景图的畸变特性。
三种注意力掩码的对比如图4b所示:SWA只能捕捉局部细节(蓝色对角线带),简化稀疏注意力(SSA)虽能建模长距离依赖,但模式固定,没法适配全景结构;而PHA(全景混合注意力)既保留了SWA的局部窗口优势,又能通过PSA动态连接远处的令牌(黄到橙色点),比如全景图前后、左右两侧的关联,完美适配360°场景的特性。
三、PanoVQA基准:首个大规模全景视觉问答数据集
要验证模型的效果,得有匹配的数据集支撑。研究构建的PanoVQA,是首个专门针对全景输入设计的大规模VQA数据集,包含超65万组QA对,覆盖正常驾驶、遮挡、事故三大类复杂场景。
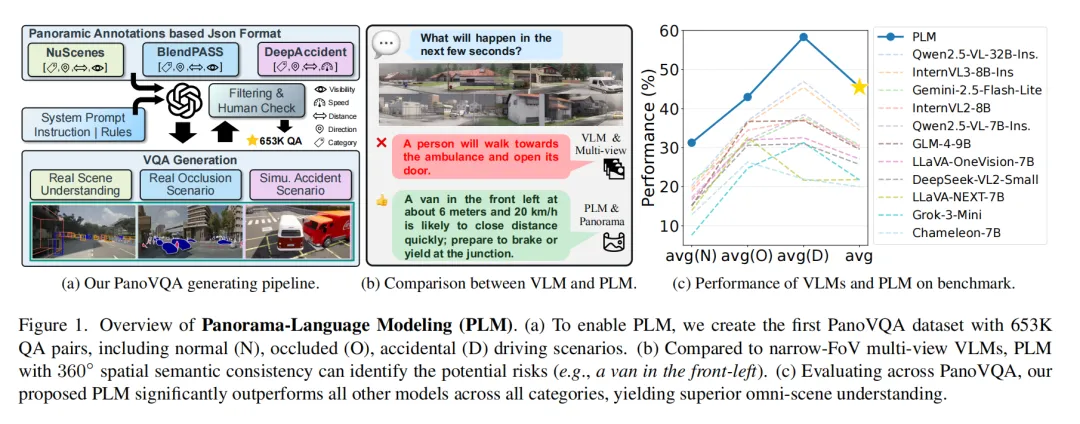 图1:PanoVQA数据集构建流程与示例
图1:PanoVQA数据集构建流程与示例
PanoVQA的类别设计针对性极强:
- PanoVQA-N:聚焦正常驾驶场景,考察模型识别物体、理解物体间及物体与自车空间关系的能力,包含场景描述、物体识别等任务。
- PanoVQA-O:专门针对遮挡场景,测试模型对不可见元素的推理能力,比如判断遮挡关系、推断被遮挡物体动作等。
- PanoVQA-D:围绕碰撞事故场景构建,用于风险分析,涵盖环境评估、碰撞风险判断、规避动作规划等任务。
数据集的构建过程也十分严谨(图1a):研究整合了NuScenes、BlendPASS、DeepAccident三个现有数据集,先生成或处理全景图像(图3展示了NuScenes和DeepAccident的全景图生成流程),再格式化标注信息,用四元组(类别、方向、距离、可见性/速度等)统一表示物体属性,最后通过GPT-5-mini生成QA对,并经过自动过滤和人工评估确保质量。
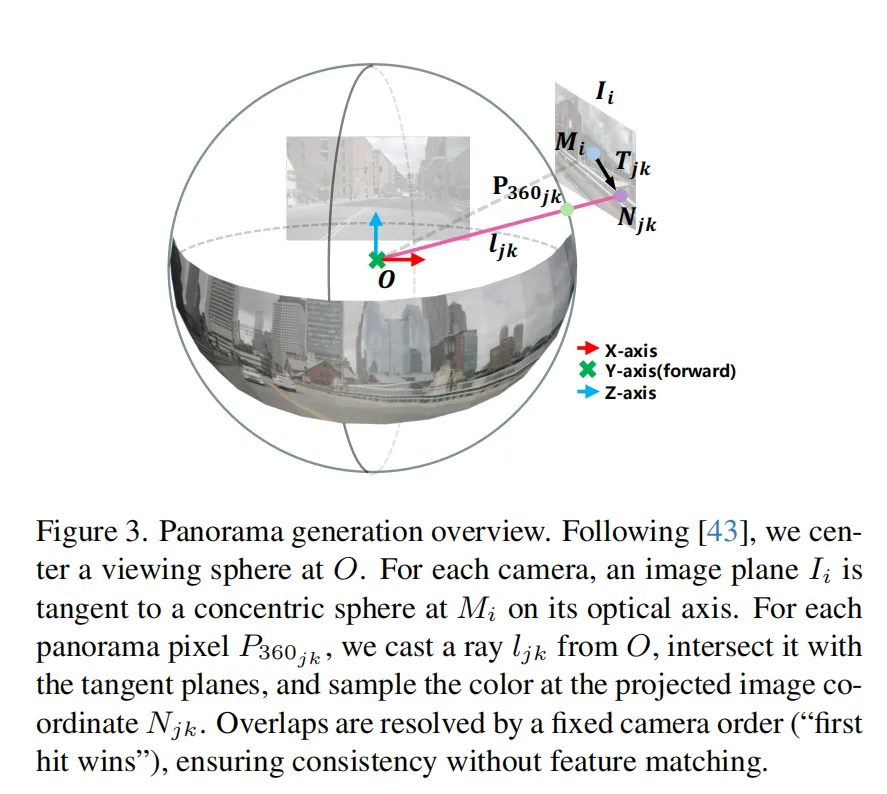 图3:NuScenes和DeepAccident全景图生成流程
图3:NuScenes和DeepAccident全景图生成流程
最终的PanoVQA包含53.8万训练集、11.5万验证集,还推出了2.5万规模的精简版PanoVQA-mini,方便高效评估。人工评估结果也证实,数据集标注质量达到了较高水准。
四、实验验证:PLM性能全面超越现有模型
研究以Qwen2.5-VL系列为基础架构,集成PSA模块后开展了大量实验,结果充分验证了PLM的优越性。
在PanoVQA测试集的零样本评估中,现有开源VLMs的表现普遍不佳,即使是性能最好的Qwen2.5-VL-32B-Ins.,平均得分也仅35.56%;专有模型如Gemini-2.5-Flash-Lite得分30.74%,Grok-3-Mini更是只有21.74%。这充分说明现有模型在全景任务上的局限性。
而经过全景微调的PLM-7B,平均得分达到45.91%,远超基础模型Qwen2.5-VL-7B的45.21%,也超越了所有对比的开源和专有模型。
消融实验进一步验证了PSA的有效性:在Qwen-2.5-3B模型上,冻结LLM仅训练视觉组件时,PSA模型得分32.14%,显著优于LoRA基线(28.55%)和标准SFT方法(29.34%),且可训练参数更少;解冻LLM后,PSA模型性能跃升至41.49%,与完全微调的3B模型相当,甚至略有超越。
参数研究还确定了最优配置:瓶颈维度设为196、Top-K值设为512时,模型性能达到峰值。此外,缩放定律研究表明,PanoVQA-mini这类小而有代表性的子集,足以支撑可靠的模型比较和快速迭代。
五、总结:重新定义全景-语言理解
这篇研究的核心价值,在于打破了传统多视角拼接的局限,提出了全景-语言建模的全新范式。PLM框架通过全景稀疏注意力模块,既解决了全景图畸变和计算复杂度的问题,又完整保留了360°场景的空间连续性;而PanoVQA数据集的推出,也填补了大规模全景VQA基准的空白。
从实际应用来看,这项研究为自动驾驶的全场景感知、AR/VR的沉浸式理解等领域提供了新的技术路径。未来,随着全景数据的进一步丰富和模型架构的持续优化,全景-语言模型有望在更多复杂场景中发挥更大作用,让AI真正看懂360°的世界。
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
