🐉 龙哥读论文知识星球来了!还在为自动驾驶模型训练数据太多、算力不够而发愁吗?星球里每天都有像MOSAIC这样能帮你“聪明”选数据、省下80%算力的前沿干货!👇扫码加入「龙哥读论文」知识星球,前沿干货、实用资源一站式拿捏~

龙哥推荐理由:
这篇论文解决了一个非常实际且“烧钱”的问题:如何用更少的数据,训练出更好的自动驾驶模型。 它没有在模型结构上搞花活,而是把目光投向了数据本身,提出了一套名为MOSAIC的通用数据选择框架。思路清晰,实验扎实,结果惊艳(数据效率提升高达80%),对于任何面临数据爆炸和算力瓶颈的AI应用(尤其是自动驾驶、机器人等物理AI领域)都有很强的借鉴意义。英伟达出品,必属精品!
原论文信息如下:
论文标题:
Scaling-Aware Data Selection for End-to-End Autonomous Driving Systems
发表日期:
2026年04月
发表单位:
New York University, NVIDIA, University of Ottawa
原文链接:
https://arxiv.org/pdf/2604.08366v1.pdf
数据太多怎么选?自动驾驶训练遇难题
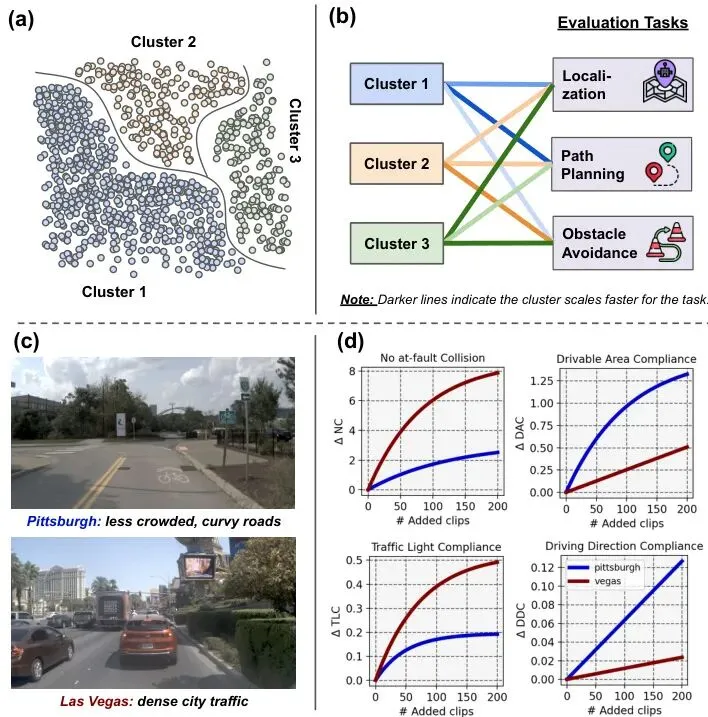
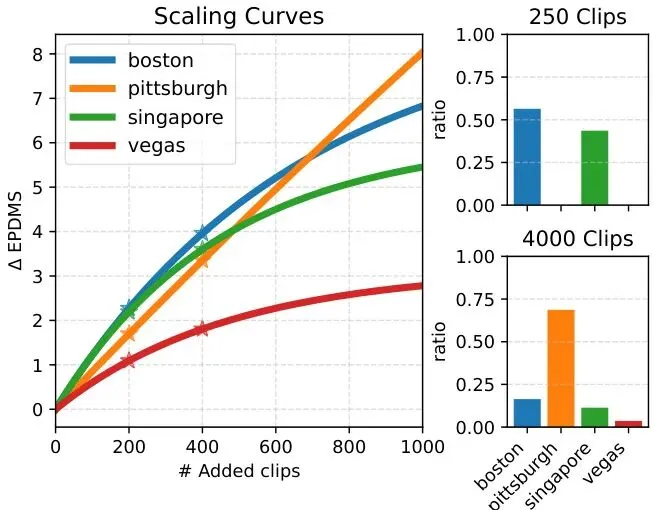
想象一下,你是一家自动驾驶公司的AI负责人。每年,车队在全球各地收集了数百万小时的驾驶录像,涵盖了晴天、雨天、堵车、乡村小道等无数场景。老板给了你一个“简单”的任务:用这些数据训练出最好的自动驾驶模型。但还有一个“小小”的限制:算力预算有限,你不可能把所有数据都喂给模型训练。怎么办?随便挑一部分?那可能错过关键场景。按地点均匀采样?但波士顿的环岛和拉斯维加斯的大直道,对模型提升的价值能一样吗?更头疼的是,评价一个自动驾驶模型的好坏,不是单一分数,而是一篮子指标:不能撞车、要遵守交通灯、得沿着车道线开、乘客坐着还得舒服…… 这些指标有时还会“打架”。一段教你紧急避让的数据,可能提升了“碰撞避免”得分,却拉低了“乘坐舒适度”。图1完美诠释了这个困境。数据混杂在一起,不同类型的数据(好比来自不同城市)对各项驾驶指标的影响速率完全不同。传统的“一刀切”数据选择方法在这里就抓瞎了。这时候,英伟达(NVIDIA)的研究团队出手了。他们带来了一套名为MOSAIC的框架,核心思想就一句话:不仅要选数据,还要“聪明地”混合数据。MOSAIC框架:三步走,智能选数据
MOSAIC,全称是 Mixture Optimization via Scaling-Aware Iterative Collection(通过缩放感知迭代收集进行混合优化)。名字有点长,但拆解开来就三步,像一套精密的组合拳。
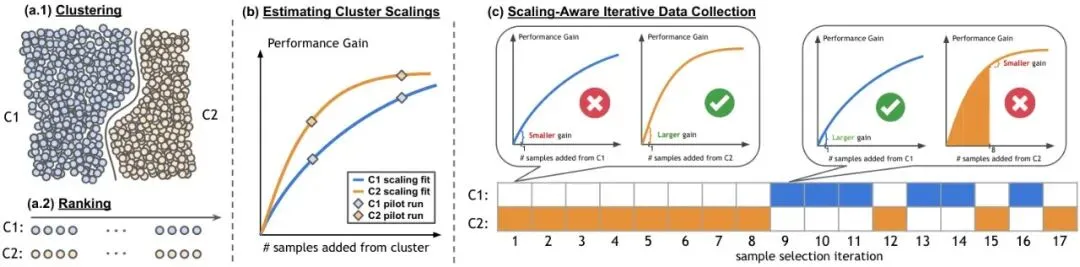
第一步:分门别类,并给数据“贴标签”面对杂乱的数据池,先根据特征(比如地理位置、场景语义描述)把它们聚类成几个“域”(Domain)。例如,把所有在“波士顿复杂环岛”采集的数据放一堆,把“拉斯维加斯夜间高速”的数据放另一堆。同一堆里的数据,被认为对模型性能有相似的影响。
光分类还不够,同一堆数据里也有“优等生”和“普通生”。MOSAIC会给每个数据样本计算一个“重要性”分数,分数高的优先录用。这个分数怎么来?简单粗暴:直接用当前模型在这个样本上跑一下,看它能给综合评分带来多少提升。提升多的,自然更重要。
第二步:预测未来,拟合“缩放定律”这是MOSAIC最精髓的一步。它想知道:如果我从“波士顿环岛”这个数据堆里,不断增加训练数据,模型的综合性能会如何变化? 是飞速提升然后很快饱和,还是缓慢但持久地增长?
为了预测这种变化,MOSAIC引入了缩放定律(Scaling Law)的概念。这个概念在大语言模型(LLM)领域很火,简单说就是模型性能随数据/模型规模增长的一种可预测的数学关系。MOSAIC为每一个数据聚类都拟合一个独立的缩放定律。
具体做法是,先做几次小规模的“试点训练”:比如,从“波士顿环岛”堆里分别取100、200、400个数据加入训练,看模型综合评分提升了多少。然后用这些试点结果,去拟合一个下面这样的饱和指数曲线:
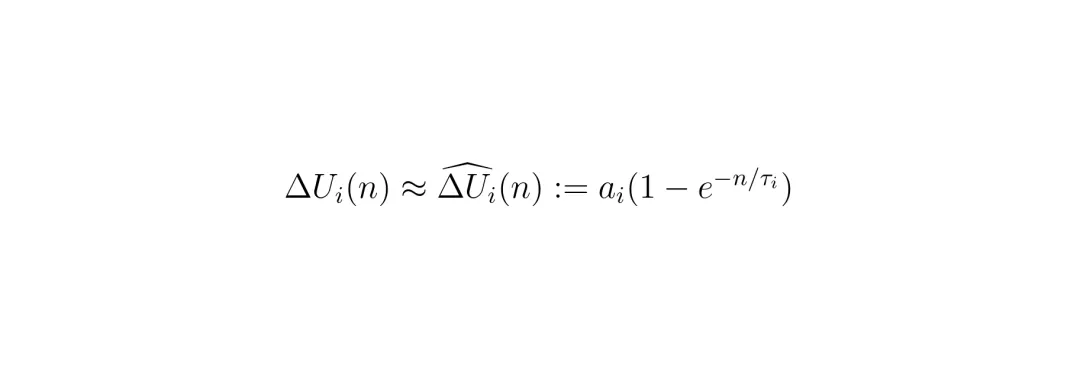 这个公式里,ai 代表这个数据堆能带来的理论最大提升天花板,τi 代表提升速度(饱和速率)。拟合好后,MOSAIC就能像有了水晶球一样,预测从任何一个数据堆里加数据,能带来多少收益。
这个公式里,ai 代表这个数据堆能带来的理论最大提升天花板,τi 代表提升速度(饱和速率)。拟合好后,MOSAIC就能像有了水晶球一样,预测从任何一个数据堆里加数据,能带来多少收益。
第三步:精打细算,迭代式“挖矿”现在,我们有了一堆分好类、排好序的“矿脉”(数据聚类),以及每一条矿脉的“产出预测报告”(缩放定律)。手里还有有限的“挖掘预算”(数据选择预算B)。
MOSAIC采用一种贪心但聪明的迭代策略:每一次,都从当前能带来最大“边际收益”的那个数据堆里,挖走最重要的那一份数据。
“边际收益”是经济学概念,这里指再多加一份数据,能多带来多少性能提升。由于缩放定律是饱和曲线,边际收益会随着从同一个堆里挖的数据增多而递减。当“波士顿环岛”堆的边际收益下降到不如“拉斯维加斯高速”堆时,MOSAIC就会果断切换“矿场”。
就这样,一次挖一份,动态调整,直到预算花光。最终选出的数据,是一个在给定预算下,能最大化模型综合性能的、最优的数据混合物。
实验结果:数据省八成,性能还更高
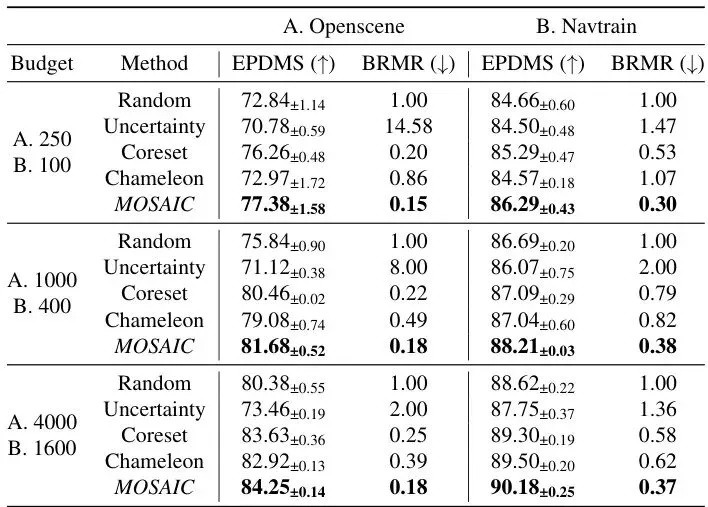
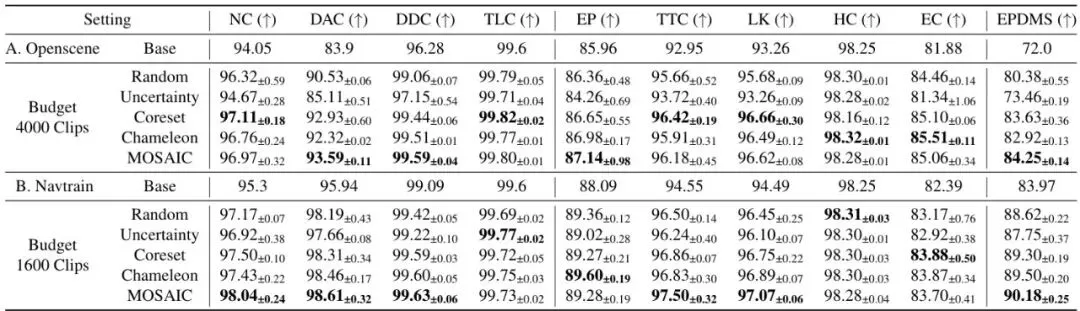
光说不练假把式。论文在两大自动驾驶数据集OpenScene和Navtrain上,用2024年NAVSIM挑战赛的冠军模型Hydra-MDP进行了验证。评价指标是关键:EPDMS(Extended Predictive Driver Model Score,扩展预测驾驶员模型分数)。这不是一个简单的准确率,而是综合了9项驾驶规则遵守指标(如碰撞避免、交通灯遵守、车道保持、舒适度等)的复合分数,被认为与真实闭路驾驶性能强相关。MOSAIC对比了多种基线方法:随机选择、基于预测不确定性的选择、追求特征多样性的Coreset,以及另一种先进的数据混合方法Chameleon。太惊艳了!在OpenScene数据集上,当预算为250个数据片段时,MOSAIC的EPDMS达到了77.38,显著高于其他方法。更厉害的是BRMR(Budget Ratio to Match Random)这个指标,它意思是“要达到随机选择同预算下的性能,本方法需要多少比例的数据”。MOSAIC的BRMR是0.15!这意味着,MOSAIC只用随机选择所需数据量的15%,就能达到后者用100%数据达到的性能,数据效率提升了85%!在Navtrain数据集上,效率提升也高达约70%。从表2可以看出,MOSAIC并非在某一个指标上疯狂“刷分”,而是有策略地实现全面、均衡的提升。它会敏锐地发现模型的短板(例如OpenScene中的DAC-碰撞避免),并优先选择能弥补这些短板的数据,从而实现综合分数(EPDMS)的最大化。深入剖析:聚类和缩放定律缺一不可
MOSAIC为什么这么强?论文通过一系列分析图揭示了其内在逻辑。我们来看OpenScene实验,数据按地理位置分成了四个城市聚类。图3(左)展示了拟合出的四条缩放曲线,差异巨大!波士顿和新加坡的数据在初期“性价比”极高,加一点分就涨很多,但很快就饱和了。匹兹堡的数据则属于“长跑型”,提升稳健持久。拉斯维加斯的数据… 嗯,贡献有限。这张图就像MOSAIC的“决策日记”。在预算很少的初期(前几百次迭代),它几乎只从波士顿和新加坡挖数据,因为这里的边际收益最高。随着这两处“富矿”被开采得差不多,收益下降,匹兹堡稳健的收益曲线变得更有吸引力,成为中期主力。等到后期,所有主要矿脉都接近饱和,它才会去开采之前看不上的拉斯维加斯数据。图3(右)的饼图也印证了这一点。论文还通过消融实验证明,聚类和缩放定律这两大核心组件缺一不可。只用聚类(不拟合缩放定律)或者只用全局缩放定律(不聚类),效果都远不如完整的MOSAIC。这充分说明了“分域预测,动态调配”这一策略的威力。局限与展望:通用框架的潜力与挑战
当然,MOSAIC并非完美无缺。它的效果很大程度上依赖于初始聚类的好坏。如果聚类分得不准,把不同性质的数据混在一起,后续的缩放定律预测和选择就会失准。此外,拟合每个聚类的缩放定律需要进行多次小规模试点训练,这本身也需要额外的计算成本。不过,相比于从头训练大模型的天价成本,这笔“投资”通常是非常划算的。最令人兴奋的是它的通用性。虽然论文聚焦自动驾驶,但MOSAIC的框架(聚类 -> 分域拟合缩放定律 -> 迭代优化混合)可以迁移到任何面临“数据爆炸、评估指标多元、算力有限”困境的物理AI领域,比如机器人操作、医疗影像分析等。未来,如何自动化、低成本地获得更好的数据聚类,如何设计更精准的缩放定律模型,以及如何将这套框架与持续学习、在线学习结合,都是非常有价值的研究方向。龙迷三问
MOSAIC具体指什么?MOSAIC是论文提出框架的名称,全称是 Mixture Optimization via Scaling-Aware Iterative Collection,中文可以理解为“通过缩放感知迭代收集进行混合优化”。它不是一个具体的模型,而是一个通用的数据选择与混合优化流程。
EPDMS包含哪9个指标?EPDMS是自动驾驶领域一个综合性能评分,包含9个子指标:NC(无碰撞)、DAC(驾驶区域合规)、DDC(驾驶员依赖合规)、TLC(交通灯合规)这四个是惩罚项(乘性);EP(自我进度)、TTC(碰撞时间)、LK(车道保持)、HC(舒适度头动)、EC(舒适度眼动)这五个是平均项(加权平均)。具体计算方式见文中公式。
什么是缩放定律(Scaling Law)?简单说,它是描述模型性能(如精度、损失)随训练数据量、模型参数量或计算量增加而变化的一种可预测的数学规律(常表现为幂律或饱和曲线)。在大语言模型领域广为人知。MOSAIC的创新在于,它为每一个数据子集(聚类)独立拟合一个缩放定律,从而预测加该子集的数据能带来多少性能收益。
如果你还有哪些想要了解的,欢迎在评论区留言或者讨论~龙哥点评
论文创新性分数:★★★★☆
将LLM领域的缩放定律思想,创造性地应用于解决物理AI(尤其是自动驾驶)中多指标权衡下的数据选择难题,并提出“分域拟合、迭代优化”的完整框架,思路清晰且有新意。实验合理度:★★★★★
在两大主流数据集、使用冠军模型进行验证,对比了随机、不确定性、多样性、前沿混合方法等多种基线,消融实验充分,结果支撑有力,置信度高。学术研究价值:★★★★☆
为数据-centric的AI优化提供了一个新颖且通用的范式。不仅对自动驾驶,对任何多任务、多指标、数据海量且异质的AI系统(机器人、医学等)都有很高的启发和借鉴价值。稳定性:★★★☆☆
框架性能依赖于初始聚类质量和缩放定律拟合的准确性。聚类若不佳,或试点数据过少导致拟合不准,可能影响最终效果。流程相对复杂。适应性以及泛化能力:★★★★☆
论文展示了框架对不同的聚类方式(地理位置、语义描述)都有效。其方法论是领域无关的,理论上可迁移,但实际在新领域应用需重新设计聚类和评估指标。硬件需求及成本:★★★☆☆
需要额外的计算资源进行试点训练以拟合缩放定律,对于超大模型和数据集,这笔开销不容忽视。但相对于节省的主训练成本,通常是正向收益。复现难度:★★☆☆☆
框架逻辑清晰,但完整复现需要自动驾驶仿真环境、特定模型和数据集,并实现聚类、试点训练、迭代选择等全流程,有一定工程门槛。论文未提供完整代码。产品化成熟度:★★★☆☆
作为一种数据预处理和训练策略优化工具,有明确的落地场景和价值(节省算力/提升性能)。但需集成到现有训练管道中,并解决聚类自动化、试点成本控制等问题,距“开箱即用”有距离。可能的问题:本文是方法论研究,实验充分但未开源代码。框架效果对聚类敏感,而如何获得最优聚类本身是一个开放问题。试点训练的成本-收益平衡需要在实际部署中仔细权衡。
 [1] Tolga Dimlioglu, Nadine Chang, Maying Shen, Rafid Mahmood, Jose M. Alvarez. "Scaling-Aware Data Selection for End-to-End Autonomous Driving Systems." arXiv preprint arXiv:2604.08366v1 (2026).
[1] Tolga Dimlioglu, Nadine Chang, Maying Shen, Rafid Mahmood, Jose M. Alvarez. "Scaling-Aware Data Selection for End-to-End Autonomous Driving Systems." arXiv preprint arXiv:2604.08366v1 (2026).*本文仅代表个人理解及观点,不构成任何论文审核或者项目落地推荐意见,具体以相关组织评审结果为准。欢迎就论文内容交流探讨,理性发言哦~ 想了解更多原文细节的小伙伴,可以点击左下角的“阅读原文”,查看更多原论文细节哦!

还在为自动驾驶模型训练数据太多、算力不够而发愁吗?
MOSAIC教你“聪明”地选数据! 想和更多自动驾驶、机器人领域的小伙伴交流前沿技术、探讨数据优化秘诀吗?
欢迎加入龙哥读论文粉丝群,
扫描下方二维码或者添加龙哥助手微信号加群:kangjinlonghelper。
一定要备注:研究方向+地点+学校/公司+昵称(如 自动驾驶+北京+清华+龙哥),根据格式备注,可更快被通过且邀请进群。