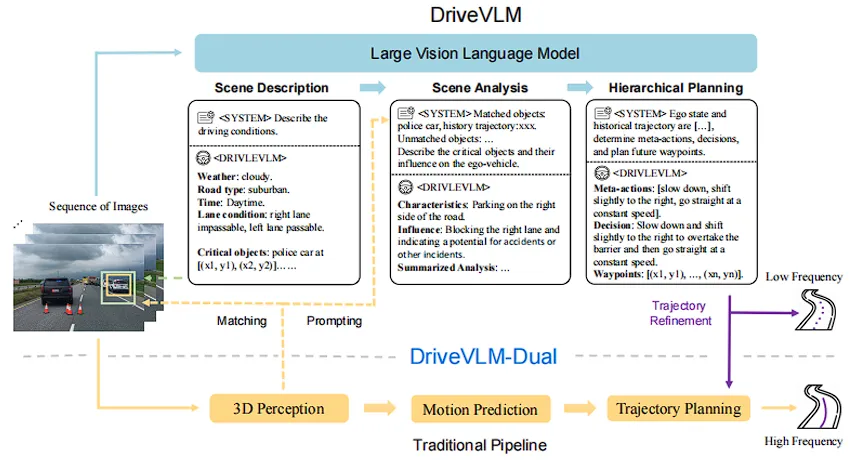
核心层级一:DriveVLM 的慢思考推理链 (Chain-of-Thought)
如图一的上半部分所示,DriveVLM 通过视觉编码器和 LLM,在内部展开了极其细致的三段式逻辑推理:
第一步:场景描述 (Scene Description)
不同于传统感知模块无差别地输出所有检测框,DriveVLM 模仿人类驾驶员的注意力机制,首先对环境进行结构化描述:
环境描述 (Environment Description):系统会输出包含天气、时间、道路类型以及车道条件的结构化语言描述 。
关键对象识别 (Critical Object Identification): 模型专注于识别最有可能影响当前驾驶的“关键对象” 。每个关键对象都会输出类别及其在图像上的 2D 边界框坐标。得益于预训练视觉编码器的优势,它能够识别出传统 3D 检测器极易漏检的长尾对象(如道路散落物、奇形怪状的动物等)。这些坐标和类别随后会被映射为语言模态中的token_id。
第二步:场景分析 (Scene Analysis)
在看清环境后,模型需要像人类一样去“理解”这些关键对象。DriveVLM 会从三个维度对关键对象进行深度剖析:
静态属性:描述对象固有的属性,例如路边广告牌的视觉提示,或者卡车装载了超宽/超限的货物 。
运动状态:描述对象在一段时间内的动力学特征,包括位置、方向和动作 。
特定行为:这是传统网络极难做到的——识别对象的特殊动作或手势(例如交警的指挥手势),这些会直接影响自车的下一步决策 。结合以上分析,模型会预测出每个关键对象对自车的潜在影响。
第三步:分层规划 (Hierarchical Planning)
最终,模型将场景级摘要、自车位姿和速度等信息作为提示词 (Prompt),逐步生成三个层级的驾驶规划:
元动作 (Meta-actions): 输出短期的驾驶策略。原文定义了 17 个具体类别,包括加速、减速、左转、变道、微调位置等 。
决策描述 (Decision Description): 输出更细粒度的策略文本。包含三个核心要素:动作 (Action)、交互主体 (Subject,如特定的行人或交通灯) 以及持续时间 (Duration) 。
轨迹航点 (Trajectory Waypoints):结合自车位姿、速度和路线信息,输出未来设定时间间隔的二维物理航点坐标集合 W = {w_1, w_2, ..., w_n},这些数值坐标同样被映射为语言token进行自回归生成。
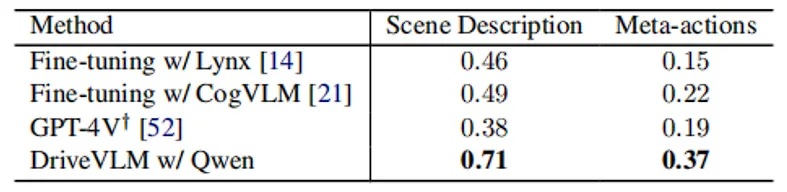
为了让大模型学会上述细粒度的思维链,研究团队针对面向规划的场景理解(SUP)任务,构建了包含场景描述、分析、驾驶规划全维度标注的 SUP-AD (Scene Understanding for Planning) 长尾场景数据集。
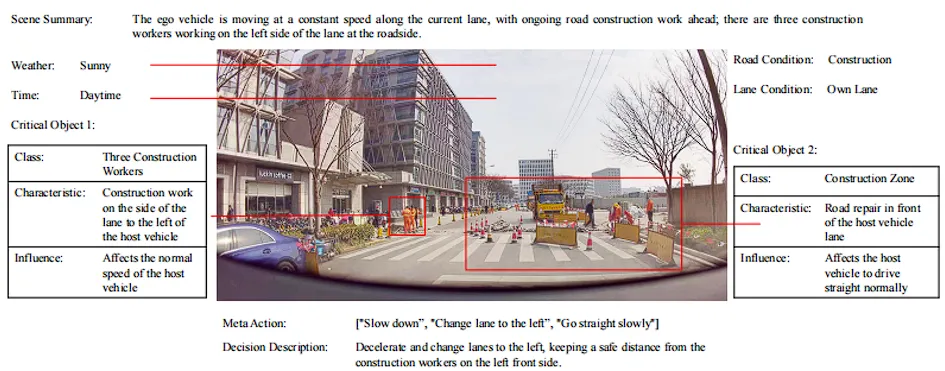
如图2的真实标注样本所示,在面对道路施工场景时,数据集不仅给出了常规的“晴天(Sunny)”和“白天(Daytime)”标注 ,还进行了极其严谨的逻辑推理标注:
识别关键对象与影响:准确标注了“三名施工工人(Three Construction Workers)”和“施工区 (Construction Zone)”,并写明了它们的影响(Influence)是“影响了主车的正常直行 (Affects the host vehicle to drive straight normally)” 。
推导决策: 数据集直接给出了包含三个步骤的元动作序列:["Slow down", "Change lane to the left", "Go straight slowly"] 。并在决策描述中给出了人类级别的原因:“减速并向左变道,与左前侧的施工工人保持安全距离” 。这就从根本上教会了模型“知其然,更知其所以然”。
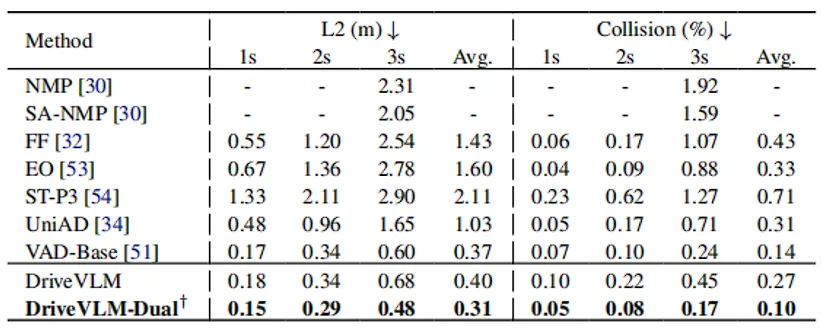
大模型虽然在认知上表现出众,但将3D世界映射为语言token导致其空间坐标精度不足,且庞大的参数量导致推理延迟高(低频)。为了在真实车辆上部署,团队在 Figure 1 下半部分设计了DriveVLM-Dual 混合架构 。
该架构通过两条核心策略将VLM 与传统自动驾驶管线缝合:
1. 融入3D感知(Integrating 3D Perception)
为了让 VLM 拥有精确的空间概念,系统引入了传统的3D检测器。
传统检测器输出 3D 边界框,系统将其反向投影到2D图像空间。
接着,将这些投影框与 VLM 识别出的关键对象 2D 框进行 IoU (交并比) 匹配 。
对于匹配成功的关键对象,系统会将其在 3D 空间中的中心坐标、朝向角、历史运动轨迹及 3D 边界框信息,全部转化为文本提示词 (Language Prompts) 喂给 VLM。这使得大模型瞬间戴上了“3D眼镜”,能够极其精准地理解关键对象的空间位置和运动趋势 。
2. 高频轨迹微调(High-frequency Trajectory Refinement)
这部分模拟了人类大脑的慢思考与快思考 。
异步运行: VLM 作为“慢思考”分支,以较低的频率输出包含高阶语义理解的参考轨迹。
高频求解: 传统的规控器 (Planner) 作为 “快思考” 分支以高频运行,它将 VLM 输出的参考轨迹与实时环境特征结合,作为优化求解器的初始解(或神经网络的输入 Query),结合实时的环境特征,最终解码输出高频且符合车辆物理约束的精准轨迹。
通过这一融合,车辆既保留了对抗长尾场景的高级认知能力,又满足了毫秒级的底层控制安全需求 。