如果把过去两年的金融 AI 进展放在一起看,会发现一个耐人寻味的变化。
最初,大模型进入金融行业,解决的是一些“边缘问题”:写摘要、生成报告、辅助分析。但到了今天,越来越多机构开始尝试一件更激进的事情——让 AI 参与,甚至接管整个投资决策流程。
这个变化背后,有一个很直观的类比:自动驾驶。
既然机器已经可以在复杂环境中完成感知、决策与执行的闭环,那么在信息密集、规则明确的投资领域,是否也存在类似的可能?
近日,前 BlackRock 高管 Andrew Ang 联手 Altbridge 的研究员 Nazym Azimbayev 与 Andrey Kim,发布了一篇研究报告:《The Self-Driving Portfolio: Agentic Architecture for Institutional Asset Management》。

为了验证这一理念,他们构建了一个包含 50 个专业智能体的自动化投资管线,试图让 AI 像人类投资委员会一样协作、争论并最终做出决策。
重点不再是模型有多强,而是流程如何被拆解、重组,并最终实现自动运行。
投资问题的瓶颈在于“人类决策带宽”
很多关于 AI 投资的讨论,都会落在模型能力上:预测是否更准、信号是否更强、回测是否更优。
但这篇论文提供了一个更贴近现实的视角——机构投资的瓶颈,往往并不在这里。
在大型资管机构中,一个 CIO 能够直接管理的投资团队数量是有限的,研究团队能够覆盖的资产类别同样有限。当资产范围扩大、市场环境变得更加复杂时,真正的限制来自于人类决策的带宽。
投资委员会通常按季度召开,信息需要在多个部门之间传递、汇总、讨论,最终形成决策。这个过程天然存在延迟,也容易在规模扩大时出现瓶颈。
也正是在这个背景下,多智能体架构开始显现出价值。它提供了一种新的可能性:将原本串行、依赖人力的流程,转化为并行、可扩展的系统。
投资开始从“分析问题”,转向“组织决策过程”。
这种变化,其实已经在多个金融机构中出现。
在 Capital One,多智能体系统被用于客服通话总结,不同 agent 分别负责理解、推理和校验;在 Daloopa,模型被拆分为几十个高度专用的单元,每个模型只处理一种结构化任务;在 BlackRock,股票筛选流程被拆解为基本面、情绪和估值多个 agent,并通过类似“辩论”的方式形成最终结论。
这些尝试有一个共同点:它们不再追求一个“无所不能”的模型,而是构建一个由多个角色组成的系统。
Ang 等人的工作,将这一思路进一步推向资产配置层面。他们并没有试图优化某一个预测模型,而是将整个投资流程视为一个可以拆分的系统工程。
模型设计
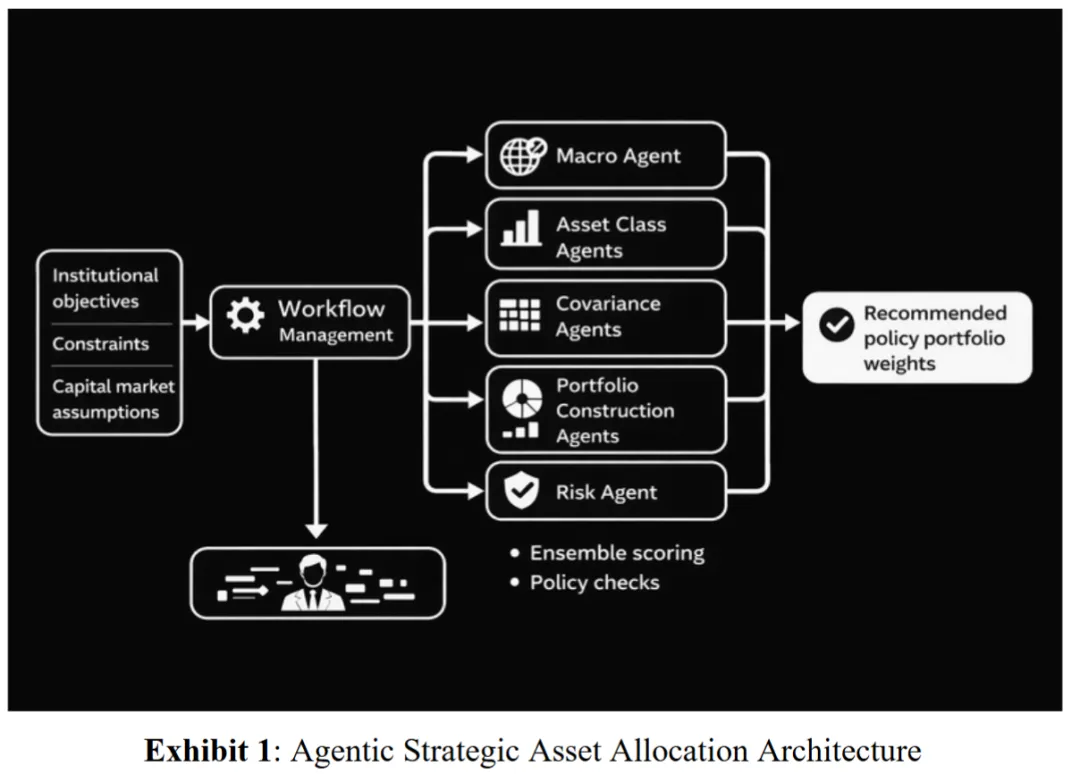
如果把这套系统拆开来看,会发现它比起模型,更像一个“组织”。
架构核心
整个架构围绕一个核心展开:Investment Policy Statement(IPS)。在传统机构中,IPS 用来定义投资目标、风险约束与资产范围,而在这里,它被转化为整个系统的控制层。
所有智能体都需要读取 IPS 并在其约束下运行,风险控制 agent 会持续检查组合是否合规,最终输出必须满足所有约束条件。
IPS 从治理文件,变成了驱动系统运行的规则集合。
多智能体协作
在这一基础上,投资流程被拆解为多个环节,并交由不同的 agent 处理。那么,这个由 50 个智能体组成的协作网是如何协同工作的?
流程从宏观判断开始。宏观 agent 会结合宏观数据、市场指标以及实时信息,对当前经济环境进行分类。在实验中,它将环境定义为后周期,并伴随滞胀风险,这一判断成为后续所有决策的背景。
随后进入资产类别层面。每一个资产类别都有独立的 agent,它们并不会依赖单一模型,而是同时使用多种方法生成收益预测,例如历史风险溢价、估值模型、宏观调整模型等。多个结果会被汇总,再通过一个类似“裁判”的机制选出最终结论,并附带权重与解释。
接下来是组合构建阶段。系统同时运行约二十种不同的组合方法,从简单的等权重,到基于风险结构或尾部风险的优化方法。这些方法并行运行,各自生成候选组合。
与此同时,系统引入了两个关键角色:一个研究型 agent,会持续从学术文献中寻找新的组合方法并补充进系统;另一个则刻意构建一个与其他组合差异最大的方案,为整体提供一个极端参照。
组合生成之后,系统进入一个类似 “投资委员会” 的阶段。每个 agent 会评审其他策略,并给出排序与反馈。这些评审同时进行,最终通过投票机制筛选出候选方案。
最后,由 CIO agent 汇总结果,并通过多种集成方法生成最终组合,同时输出一份面向非技术决策者的报告。
Meta Agent 自进化
在整个流程之外,还有一个 meta-agent,负责在每次再平衡后对比预测与实际结果,识别偏差,并调整其他 agent 的策略与规则。
如果说多智能体协作解决的是“如何决策”,那么 meta-agent 关注的则是“如何改进决策”。
在每一次再平衡之后,它都会对比预测与实际结果,识别系统中存在的偏差,并对其他 agent 的策略或指令进行调整。
这一过程不仅仅是参数优化,更像是经验的积累与迁移。
系统开始具备“记忆”和“自我修正”的能力。
这也是整个架构中最接近“自驱动”的部分。
实验结果
为了验证这套架构,研究团队在 2026 年 3 月进行了一次完整运行,设定了投资约束:
- • 覆盖 18 个流动性资产类别(6 股票、8 债券、4 另类资产)
在宏观层面,系统将当前环境识别为后周期,并提示滞胀风险。这一判断在后续决策中产生了明显影响。
在资产收益预测阶段,一个一致的模式逐渐显现:当资产估值越高时,系统对历史收益的依赖越低。例如,美国成长股的预期收益被下调 2.0 个百分点,大盘股下调 1.1 个百分点,而新兴市场几乎没有调整。这种差异反映的是对当前定价的再评估,而非简单的整体悲观。
在组合构建与评审阶段,系统表现出明显的偏好变化。在收益预测不确定性较高的环境中,agent 更倾向于依赖波动率与相关性结构的方法,而不是依赖收益预测本身。其中,Maximum Diversification 在投票中排名第一,而刻意构建的“极端差异组合”则排名最后,这与其设计目标一致。
最终生成的组合呈现出一定的防御性特征:
- • 股票权重:44.9%(低于传统60/40配置)
在 1996–2026 年回测中,该组合的收益表现与 60/40 策略接近,但在风险控制上有所改善:
- • 最大回撤:25.6%(对比60/40的34.3%)
这一结果并不意味着策略已经优于传统方法,但至少说明,这种流程可以生成一个在风险收益特征上合理的组合。
另一个值得注意的现象来自系统内部。在运行过程中,研究型 agent 开始主动提出新的组合方法,用来弥补现有方法的不足。这种行为是在多模型协作中自然产生的,而非预编码的结果。
结语
这套“自驱动投资组合”仍然只是一个原型。它的长期表现,还需要真实市场中的数据来验证。
但它已经提供了一个重要启示:投资并不只是预测问题,它本质上是一个决策流程设计问题。
当流程可以被拆解、并行执行,并且具备持续改进的能力时,投资的形态也随之发生变化。
💬 想深入了解对冲基金策略、顶级研究员的思维框架与实战经验?欢迎加入 LLMQuant知识星球,获取第一手资料与独家内容。