小米Xiaomi HAD 超高度自动驾驶系统全栈技术解析
- 2026-04-16 01:40:06

Xiaomi HAD(Hyper Autonomous Driving)是小米汽车面向量产落地的超高度自动驾驶系统,定位为不依赖车端视觉语言大模型(VLM)、具备认知能力的端到端自动驾驶框架,核心路线为云端赋能・车端执行,在700~1000TOPS 车端算力约束下,实现全链路神经网络化感知 - 规划 - 控制与零样本场景自我进化。
Xiaomi HAD 系统历经三阶段迭代,从规则辅助驾驶升级为数据驱动端到端,最终落地世界模型 + 闭环强化学习,完成从行为模仿到因果认知的技术跃迁,适配高速NOA、城市道路、泊车等全场景量产需求。
01#
技术架构三阶段迭代
HAD 系统遵循量产优先、逐步迭代的工程逻辑,分三阶段完成技术架构升级:
1、Pilot 规则辅助驾驶(2024 年初)
•架构:规则主导的模块化架构,完成高速NOA 功能交付
•能力:高速巡航、车道保持、自动变道等基础辅助驾驶
•局限:泛化能力依赖人工设计场景,复杂路况鲁棒性不足
2、数据驱动端到端(2024 年 11 月)
•核心升级:感知→规划→控制全链路神经网络化,数据驱动方案量产部署
•数据规模:半年完成千万公里级实车数据积累,数据飞轮启动
•算力平台:车端搭载英伟达Thor-U/Thor-X 单片域控制器,算力 700~1000TOPS
3、HAD 增强版 + 世界模型(2025 年 11 月)
•架构:引入云端世界模型Genesis + 闭环强化学习,实现感知- 规划联合优化
•核心能力:反事实数据训练、零样本场景泛化、自我进化
•技术目标:突破长尾场景限制,具备类人驾驶的因果推理能力
02#
感知系统:算力高效利用的多模态融合方案
HAD 感知基于11 路高清相机 + 10Hz 毫米波雷达 + 前向激光雷达硬件,核心解决车端算力受限、传感器异步、长时序认知缺失三大行业痛点,五大技术模块协同实现高鲁棒感知。
1、三档动态感知策略(算力感知路由)
摒弃传统传感器统一帧率的算力浪费方案,按驾驶场景优先级动态分配算力,三档算力路由:
实现原理:注意力路由+ 规划意图驱动,上层决策输出意图优先级,实时调整传感器算力分配。
2、多教师跨模态认知蒸馏
车端不部署完整VLM,通过知识蒸馏将云端大模型认知能力注入车端轻量ViT Backbone,教师模型分工:
a.鲁棒特征教师:蒸馏跨光照/ 天气稠密特征,提升泛化性
b.结构先验教师:输出概念边界+ 遮挡关系,强化语义理解
c.4D 占据栅格教师:传递物理空间连通性(Occupancy Flow),学习运动规律
核心价值:突破车端算力上限,实现大模型认知+ 小模型推理的量产平衡。
3、Occupancy Flow 占据栅格流
解决传统Occupancy Network 仅输出静态占据、无法理解运动趋势的问题:
输出维度:每个栅格同步输出占据概率+ 速度矢量,形成(x,y,z,vx,vy,t) 6 维感知
核心能力:隐式学习物理规则(物体不穿墙、沿车道行驶),从外观匹配升级为因果推理,避免误判障碍物运动意图。
4、异步时序融合(Motion Warp + 新鲜度门控)
解决相机30Hz、激光 / 雷达 10Hz 的传感器异步融合延迟问题:
1.Motion Warp 运动补偿:利用自车运动矩阵,将历史BEV 特征扭曲对齐至当前坐标系,消除空间错位
2.新鲜度门控Freshness Gating:为BEV 每个格子分配时间衰减权重,新数据高权重、旧数据自动降权
•效果:无需传感器强制同步,实现多模态数据无缝融合,降低感知延迟。
3.5 持久化认知 Token(Tokenized Resampling)
解决单帧感知无法编码长时序交互意图、盲区风险的问题:
•压缩机制:将数百万维多帧BEV 特征压缩至数千维认知 Token,压缩比1000:1
•编码信息:周围车辆交互意图、行人运动趋势、盲区风险、道路拓扑、历史因果链
•优势:以极低算力实现秒级长时序记忆,替代VLM 完成长时序因果推理。
03#
规划系统:三层生成式可控端到端规划
针对纯端到端规划可解释性差、可控性弱的缺陷,HAD 采用Decision→Meta Action→Control三层生成式规划,平衡拟人驾驶与安全合规:
1、顶层 Decision 宏观意图(5~10s)
•输入:导航拓扑+ 认知 Token 持久记忆
•输出:直行/ 左转 / 变道 / 让行 / 停车等宏观驾驶意图,基于 Attention 输出置信度分布
2、中层 Meta Action 轨迹生成(1~2s)
•技术:扩散模型DiT / 自回归机制,并行生成多条候选轨迹
•表示方式:轨迹结构化编码(曲线类型+ 参数),降低生成空间维度
底层 Control 执行细化(100ms)
•输出:平顺轨迹+ 方向盘角度 / 加速度连续控制指令
•优化:连续空间优化,保证轨迹曲率、加加速度连续,提升舒适性
3、三层协同机制
Top-K 候选轨迹→各层并行推理→代价函数评估→最优轨迹执行
•代价函数:安全性(碰撞风险)+ 舒适性(曲率 / 加加速度)+ 效率(通行速度)+ 法规(车道保持)加权求和。
04#
强化学习体系:ReCogDrive+DIPOLE+DiffGRPO
HAD 通过强化学习实现自主探索、自我纠错,跳出模仿学习的局部最优陷阱:
1、ReCogDrive 强化认知框架
•核心:以认知Token为桥梁,将世界模型隐空间特征注入规划网络
•能力:高风险场景下引导有效探索,避免随机试错;具备决策纠错能力,实现未见过场景的零样本泛化。
2、DIPOLE 扩散策略双目标优化
解决扩散规划探索多样性与利用最优性的对立矛盾:
•架构:策略网络分解为探索分支(生成多样动作)+利用分支(生成最优动作)
•优化:KL 散度正则化 + 双目标函数,实现探索 - 利用的 Pareto 最优平衡
•效果:既学习专家驾驶行为,又保留场景适应能力,不陷入模仿瓶颈。
3、DiffGRPO 扩散策略强化学习
业界首个扩散模型+ GRPO耦合的强化学习算法:
1.采样多条扩散轨迹,通过NAVSIM 仿真器评估
2.以PDMS(预测驾驶模型评分)为奖励,组内标准化优势函数
3.结合RL 损失 + BC(行为克隆)损失,防止策略崩溃
•适用场景:复杂路口、博弈场景的安全决策优化。
4、接管数据的工程化使用
•99% 正常行驶数据:作为模仿先验,学习正确驾驶行为
•<1% 接管数据:作为纠错信号,定义禁止行为的惩罚边界
•动态调度:简单场景依赖模仿学习,复杂场景激活强化学习探索。
05#
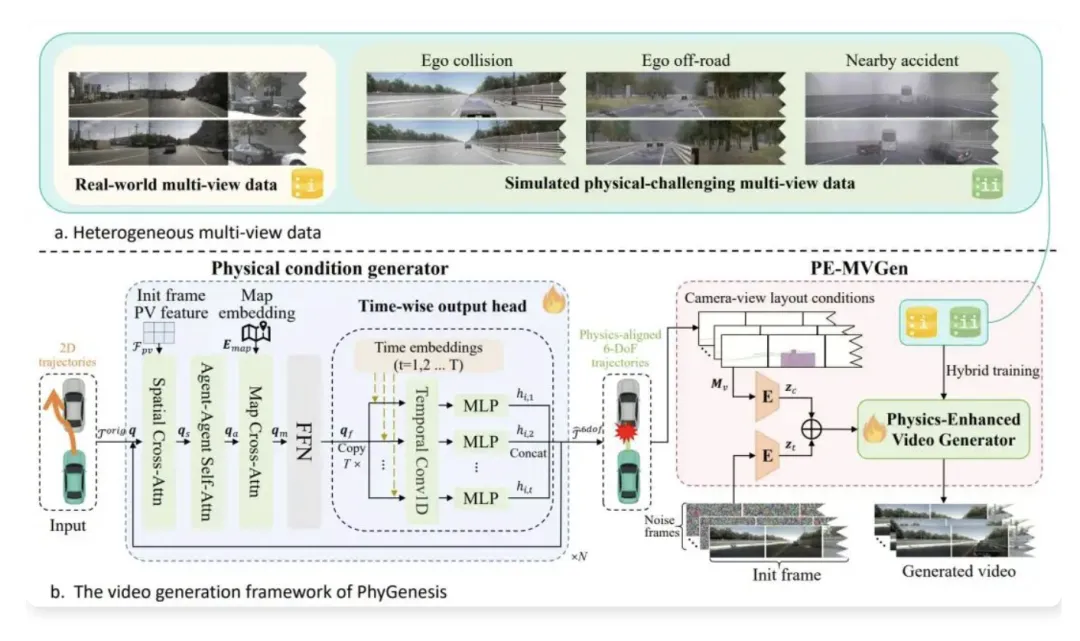
云端Genesis 世界模型:反事实数据生成引擎
Genesis 是小米自研业界首个多视图视频+ 激光雷达点云联合生成框架,仅用于云端训练,不参与车端实时推理:
1、核心技术能力
•多模态同步生成:多视角视频+ 4D 激光点云时间戳精准对齐
•结构化编辑:支持调整天气/ 光照 / 障碍物 / 轨迹,生成反事实数据
•物理一致性:结合PhyGenesis 物理引擎,修正轨迹违规,保证生成数据真实性。
2、反事实数据的核心价值
反事实数据= 单变量扰动、其余变量不变,让模型学习因果逻辑而非表面相关性:
•示例:原场景(行人过街→急刹)→反事实场景(无行人→正常行驶)
•作用:补齐长尾场景训练数据,无需实车事故场景即可优化决策。
3、数据闭环中的定位
Genesis 合成数据→感知多教师蒸馏→车端模型→影子模式采集接管数据→强化学习训练→OTA 策略更新→车端迭代。
08#
核心工程创新与量产价值
1.算力高效利用:不堆算力、不上车端大模型,700TOPS 实现量产端到端天花板性能
2.云端- 车端协同:云端大模型提供认知先验,车端轻量模型高效执行,平衡性能与成本
3.因果感知突破:Occupancy Flow + 认知 Token,从感知物体升级为理解运动与意图
4.可控端到端:三层生成式规划,解决纯端到端的可解释性、安全性痛点
5.量产数据闭环:反事实数据+ 接管数据纠错,高效补齐长尾场景,适配大规模交付
小米HAD 系统的核心工程逻辑,是放弃技术炫技、聚焦量产落地,在有限硬件算力下,通过算法创新实现认知级自动驾驶,为行业提供了可复制的量产端到端智驾方案。
资料来源于网络整理,如有侵权即删,请联系小编
扫描下方二维码,添加智驾派小助理微信,免费领取100份智驾材料: