NVIDIA一篇面向端到端自动驾驶的数据选择工作,很有工程借鉴意义(CVPR'26)
- 2026-04-16 01:37:01

点击下方卡片,关注“自动驾驶之心”公众号
作者 | Tolga Dimlioglu等
编辑 | 自动驾驶之心
本文只做学术分享,如有侵权,联系删文
>>自动驾驶前沿信息获取→自动驾驶之心知识星球
这两年,自动驾驶有一个很明显的变化:大家讨论端到端,不再纠结“要不要做”,目前已经进入第二阶段 —— 怎么把车端模型真的训稳、可量产。
这件事一旦进入量产阶段,问题就会立刻变得很具体。数据到底怎么进来、怎么回流、怎么配比、怎么决定下一轮该补什么数据。
Waymo 在去年关于运动预测与规划 scaling law 的研究里,用 50 万小时数据说明一件事:在自动驾驶里,模型性能确实会随着数据、参数和算力继续按规律提升,而且闭环指标也会随之改善。换句话说,规模化这条路是成立的。
到现在,业内目前可以对标的量产模型训练数据已经到了千万Clip量级。
但另一个现实的状况是:不是所有数据都一样值钱。正常行驶的数据容易采集,工业界已经进入到困难场景的优化阶段。也正是在这个背景下,纽约大学和 NVIDIA 中稿CVPR'26的 MOSAIC 工作变得很有意思。它瞄准的是一个更底层的问题:
当数据池已经大到不可能全吃、而评测目标又不是单一分数时,我们到底该优先把哪些 clip 加进下一轮训练里?
MOSAIC给出的答案如下:随机采样或者按照不确定性挑选数据都不可靠,单纯的追求数据多样性亦非正确的途径。要做一件更像“数据经营”的事 ——先把数据按影响模式分群,再估计不同数据群对各项驾驶指标的收益曲线,最后按边际收益一条一条地往训练集里加。
这就是 MOSAIC 的核心,推荐工业界的小伙伴仔细看一看~
论文标题:Scaling-Aware Data Selection for End-to-End Autonomous Driving Systems 论文链接:https://arxiv.org/abs/2604.08366
一、端到端自动驾驶,已经进入“数据闭环比拼精细化运营”的阶段
把时间稍微拉长一点看,端到端自动驾驶其实经历了一个很典型的演进。
最早的端到端,是从图像直接学控制,本质上还是 imitation learning 的简单映射。但方法在进步,训练范式也在变。
以前大家更容易把数据看成“越多越好”的资源;现在随着模型变大、训练更贵、指标更复杂,数据逐渐变成了一种需要调度、需要预算、需要策略分配的资产。
尤其是在自动驾驶里,一个 clip 的价值并不单一:它可能对车道保持有帮助,对可行驶区域也有帮助,但对 comfort 未必是正收益;一个拥堵路口的 clip 可能主要提升 collision 相关指标,而一个弯道 suburban 场景 clip 则更关注 planner 的路线跟踪和车道保持。
所以不同数据域,对不同评测任务,提升斜率是不一样的。
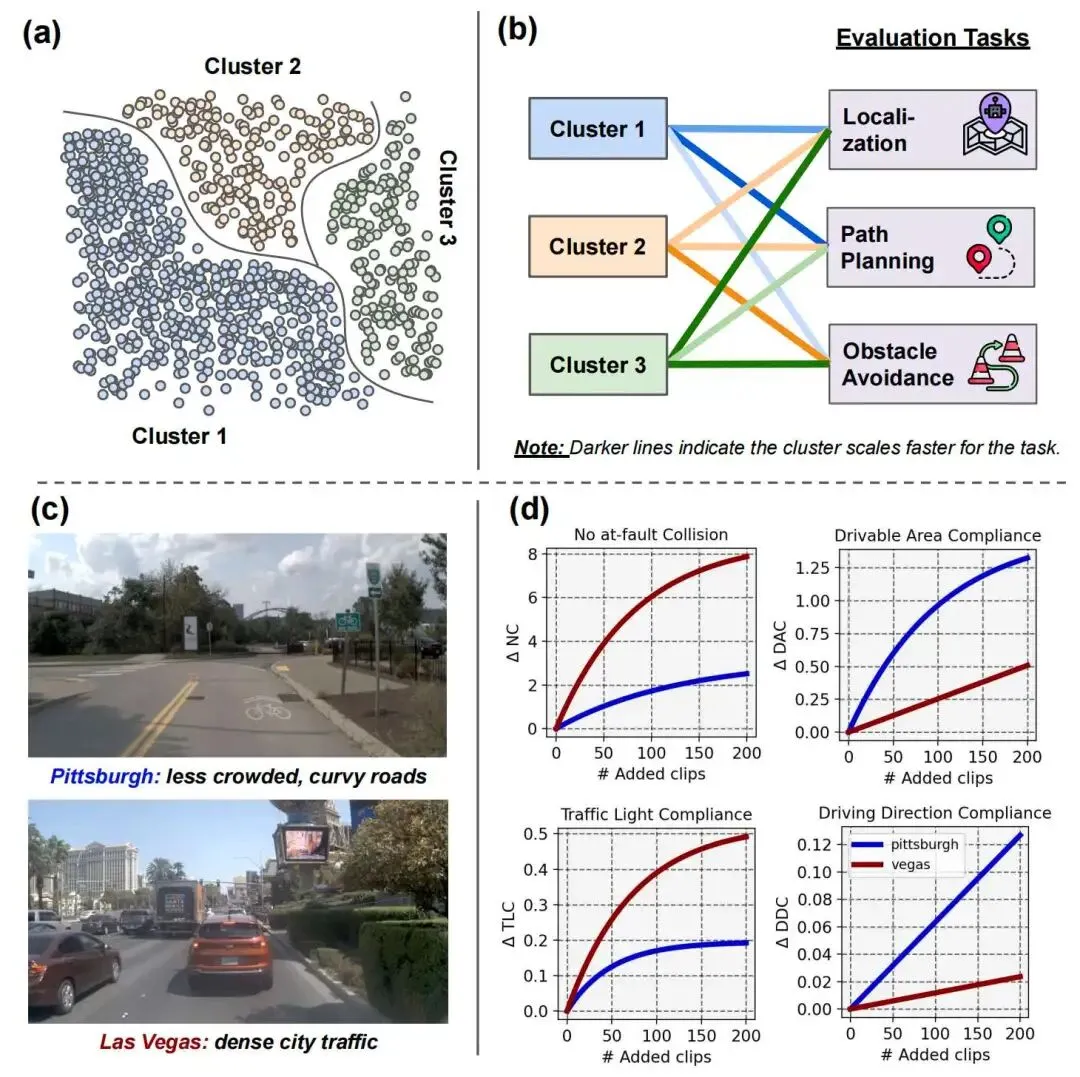
所以,自动驾驶的数据闭环,要从“数据回流”,升级成 “知道什么数据该先收集、该多收、该什么时候停”。
它第一次正面回答数据闭环的收益建模问题。
二、MOSAIC 是怎么做的
MOSAIC 的方法论可以拆成三步:聚类、建模、分配。
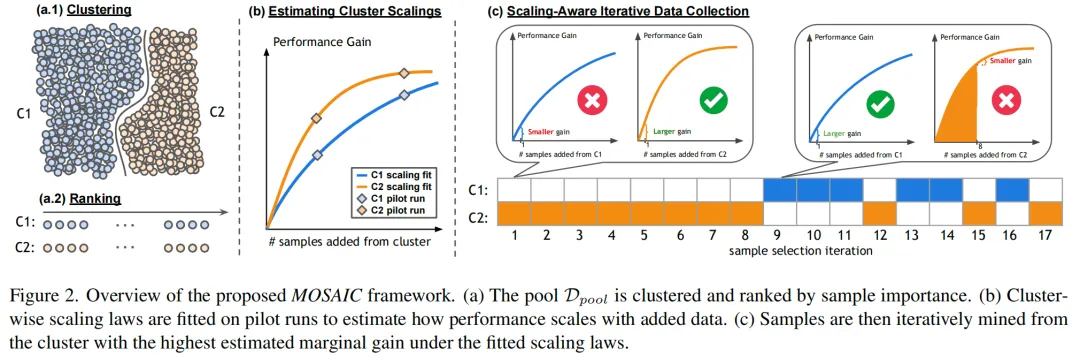
1. 先把“样本”变成“数据域”
MOSAIC先定义了一个总体目标。给定当前训练集 、数据池 和预算 ,希望从数据池里挑一个子集 ,使得模型重训后在多指标聚合效用函数 上尽可能高:
其中 表示第 个评测指标, 则把这些指标聚合成最终要优化的总目标。对自动驾驶来说,这个总目标就是 EPDMS。
但这个目标直接做很难,因为单个样本对多项指标的影响太细碎、太不稳定。所以 MOSAIC 先做了一件非常关键的事:不直接在样本级求解,先把数据池划成若干“影响模式相似”的簇。
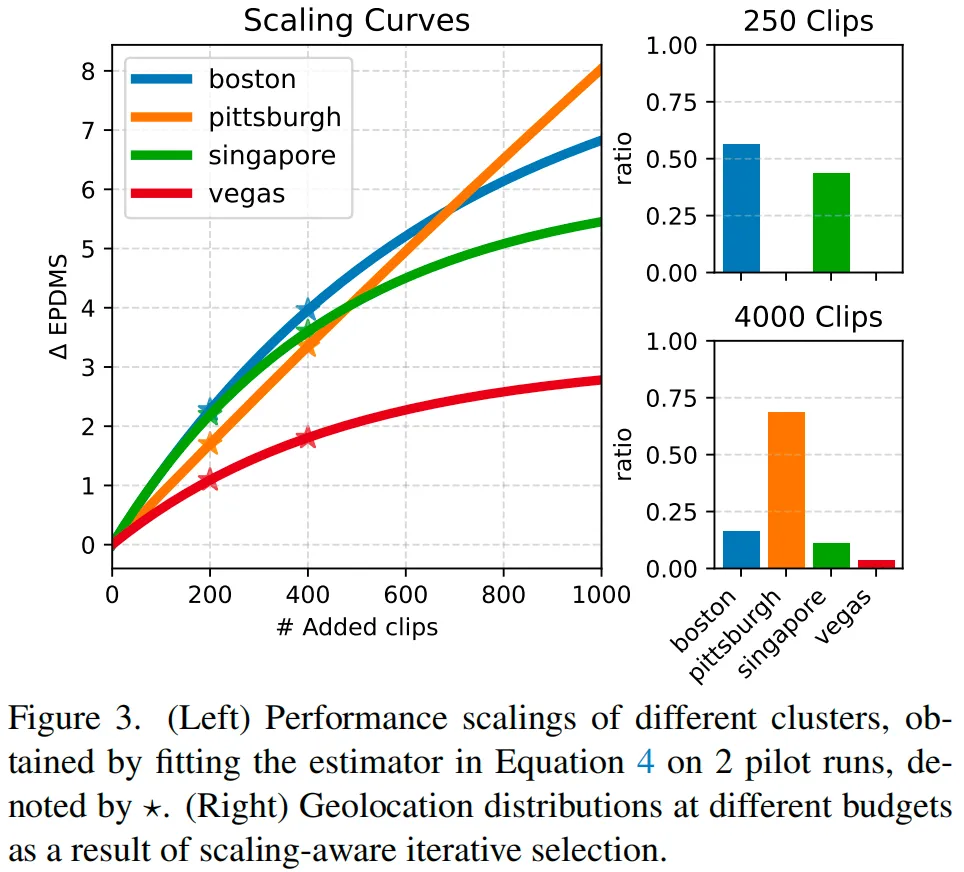
比如在自动驾驶里,可以把 clip 粗分成高速、复杂路口、平稳本地道路,或者按地理位置划成 Boston、Pittsburgh、Singapore、Vegas,不同城市天然对应不同路况、交通密度和规则分布。
2. 再在每个簇内部排序
光分群还不够。因为同一个簇里,也不是每条数据都一样重要。MOSAIC 在每个簇里面再按重要性程度对样本排序。
这个分数的本质是:当前模型在该样本上的综合表现有多差、得出潜在收益有多大。在自动驾驶设定里,它使用与多指标效用相关的样本级评分来完成 ranking。
这一步比较好理解。
你已经知道“拥堵城区场景”需要继续优化,但在这个大类里,也要先补最能暴露模型问题的那些 clip,而不是一股脑平均吃进去。
所以到这里,MOSAIC 已经完成了两层重组:
第一层,把数据按“场景作用方式”分域;第二层,把每个域里的数据按“优先级”排队。
3. 最关键的一步:给每个数据域拟合收益曲线
MOSAIC 真正有意思的地方,在第三步。
它没有直接问“Boston 这个簇重要吗”,而是问:
如果继续往训练集里加 Boston 的数据,它还能带来多大收益?收益会不会很快饱和?
于是他们把问题改写成 mixture optimization。设从第个簇里取个样本,总预算满足,目标变成:
然后用一个近似,把整体收益拆成各个簇的独立贡献之和:
也就是说,先假设每个簇的主要收益可以近似独立估计,再分别给每个簇拟合一条 scaling curve。MOSAIC使用的是饱和指数函数:
这里的 表示这个簇理论上最多能给总效用带来的提升上限, 则表示它的饱和速度。一个簇如果前期提升很快,说明它是低数据 regime 的“高性价比数据”;如果它饱和得慢,说明它更适合在后期继续深挖。
这一步特别像在给不同数据域算“投资回报曲线”。当前阶段哪部分数据的边际收益更高,就优先使用。
4. 最后按边际收益,一条一条加数据
有了每个簇的收益曲线之后,后面的策略就很顺了。
设当前已经从第 个簇取了 个样本,那么再多取一个的边际收益可以写成:
每一轮,都选那个 最大的簇,再从这个簇当前排名最靠前、还没被选走的样本里拿一个。如此循环,直到预算用完。
这就让数据分配从静态占比,变成了一个动态的、收益驱动的采样过程。
MOSAIC 使用闭环指标 EPDMS 来做,当然对于各家而言,量产上关注什么指标,可以直接进行适配。
三、实验结果
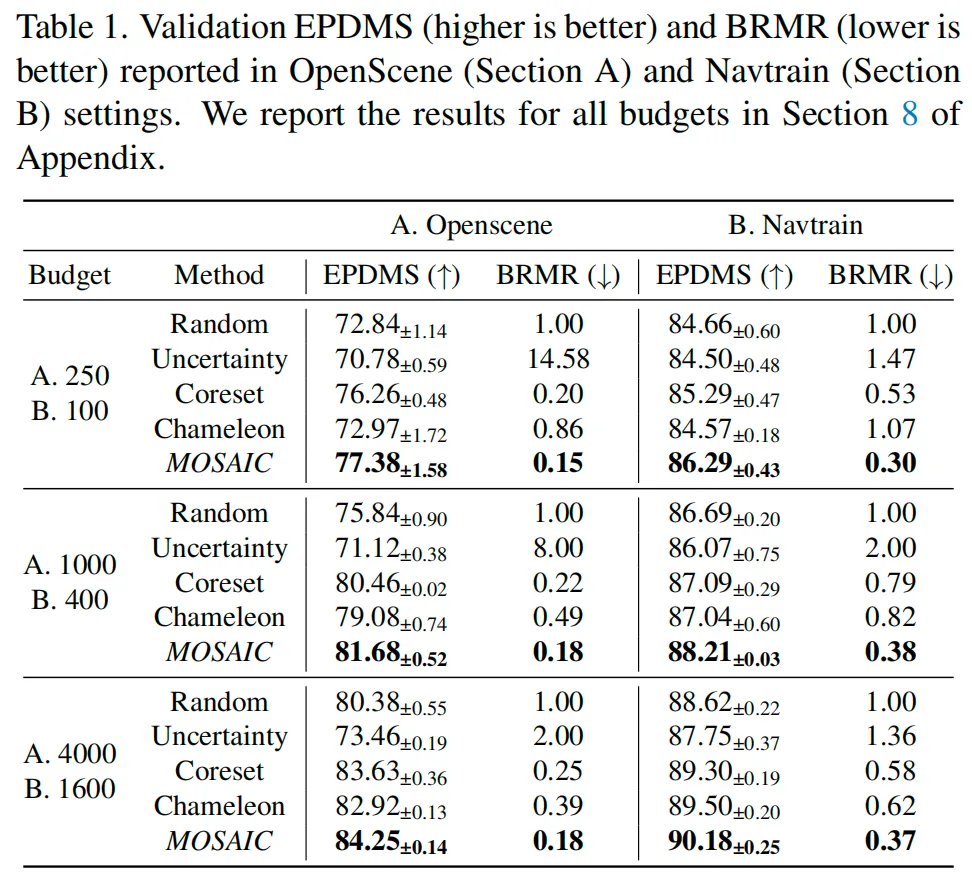
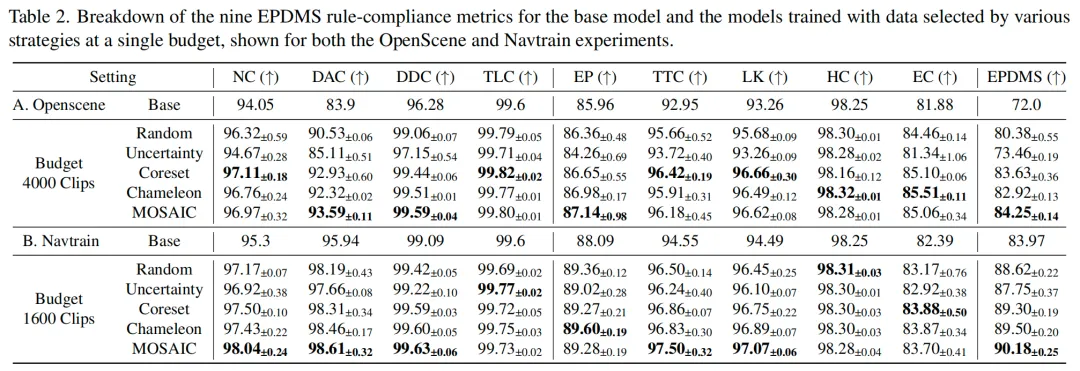
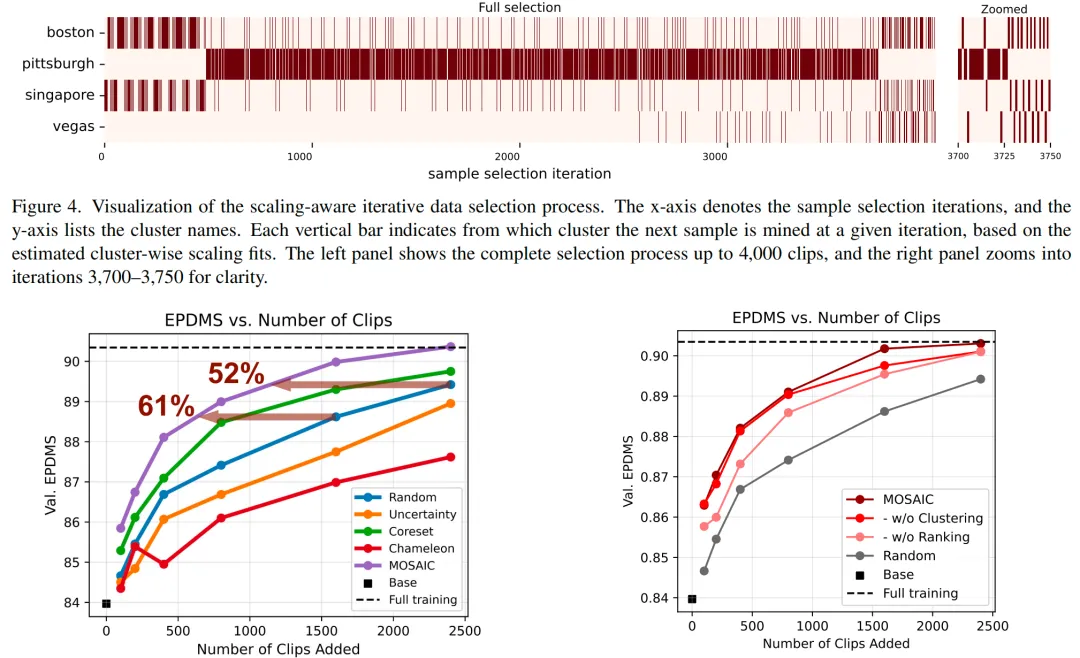
MOSAIC 相比基线可用最多约 80% 更少的数据达到同等效果,并且达到 full-training performance 时可以少用 42% 的样本。
四、横向看,MOSAIC 比现有方法到底多做了什么
相比业内目前一次次手动尝试数据配比的方案,MOSAIC 最大的贡献是将这个过程升级为动态的、收益驱动的采样过程:
★即显式建模某类数据对某组驾驶指标的提升速率。
这一步还是比较关键的。因为自动驾驶的数据价值,从来都不是均匀的。一个弯道 clip,和一个城市密集交通 clip,不只是“长得不一样”,而是它们对 planner 的训练作用本来就不一样。
MOSAIC 做的,本质上是把这种“作用方式差异”从经验判断,变成了可估计、可计算、可迭代优化的对象。
所以,这篇工作对工业界的借鉴意义,可能比中稿CVPR的意义更大。
★评测 → 分簇 → 小规模试投 → 拟合收益曲线 → 按边际收益追加数据 → 再评测。
这个结构对工业界至少有三层价值。
第一层,是训练预算层面。
当训练已经进入大模型、海量 clip 阶段,42% 的样本节省不只是“少标一点”,更是少一大块训练算力、存储、蒸馏和回归测试成本。
第二层,是数据运营层面。
过去很多车企的数据闭环,很大一部分精力是在收集bad case。但 bad case 回收之后,真正难的是:这个 bad case 该归到哪个桶里?它能提升哪项能力?同类样本还值不值得继续采?MOSAIC 其实在给这件事建立“记账体系”。
以后数据团队和算法团队之间讨论的,可能会变成“这个 case 属于哪条收益曲线、当前边际收益还有多高”。
第三层,是量产 OTA 节奏层面。
真实车端迭代不可能每次都大规模重训全量数据,更多时候是定向补齐某些缺口场景。MOSAIC 这种方法特别适合用来做下一轮训练的数据配比决策。它给出的不是拍脑袋答案,而是带着评测反馈的收益估计。
五、怎么评价 MOSAIC
NV的这篇工作,还是很扎实的。站在量产的角度,是在提醒整个自动驾驶行业一件事:
当端到端训练走到海量数据时代,真正稀缺的,不再只是数据本身,而是理解数据收益结构的能力。
数据闭环作为自动驾驶的底座,这件事情本身还有很多需要优化的地方,而模型做的更大只是这其中的一环。
MOSAIC 让数据闭环第一次开始像一个有收益函数、有边际分析、有预算意识的系统。
这篇工作的价值,可能恰恰就在这里。
它在回答另一个更值得被思考的问题:
当我们已经有很多数据之后,到底有没有能力把下一份数据,花在刀刃上。
自动驾驶之心


求点赞

求分享

求喜欢


