自动驾驶的“算力战争”:谁在为马斯克的端到端买单?
都说特斯拉 FSD 今年要进中国,绝大多数人都在聊“谁开车更稳”,咱们今天聊点底层的“血腥”逻辑:自动驾驶竞争的终点,其实是“电力”与“热力学”的竞争。一、 范式转移:从“逻辑推演”到“暴力美学”
特斯拉从 FSD v12 开始,彻底转向了**“端到端(End-to-End)”**架构。这本质上是从“写代码”变成了“练肌肉”:算力饥渴症:传统 L2 级模型只需微量算力,但端到端模型对计算量的需求呈指数级跃升。训练一个成熟的 L4 级模型,算力需求已从 $10^{20}$ FLOPs 级别向 $10^{23}$ 甚至更高进发。暴力推演:这意味着如果你想缩短迭代周期,你需要的不仅是数万张 H100,而是一个极其庞大的、单次电费支出就高达数百万美金的“算力池”。核心逻辑链:模型规模--训练时间--电费/散热成本-- 硬件“能效比”成为核心竞争力。
二、 产业链深挖:谁在解决“电-算-冷”三角循环?
在这个逻辑链下,真正的财富机会藏在那些能打破物理极限的“卖水人”手中:1. 物理层:液冷散热与高配电(基建的“冷热管理”)
当单机柜功耗超过20kW(B200 集群的常态),传统的风冷已触及物理天花板。液冷不再是选项,而是刚需。产业链分析:从“冷板式”向“浸没式”演进,同时高功率配电模块(PSU)的转换效率决定了你能省下多少电费。2. 边缘侧:端侧能效比(“车端”的生存法则)
云端可以堆卡,但车端面临“散热+续航”的双重枷锁。芯片能效比低,意味着车企要支付更昂贵的冷却成本和电池冗余。产业链分析:行业正在从“算力霸权”转向“能效霸权”。专用架构(ASIC)和存算一体技术正在蚕食通用 GPU 的份额。3. 算法层:模型量化与压缩(被低估的“炼金术”)
马斯克强调“推理算力”是瓶颈。如果能将 100GB 的模型无损压缩至 10GB,其商业价值等同于将硬件性能提升了 10 倍。产业链分析:关注模型剪枝、量化(Quantization)以及知识蒸馏技术。这是将“巨型老师模型”塞进“瘦身学生模型”的关键。
三、 盯着“能效比”看,财富就在曲线里
未来 18 个月,我们会看到一个有趣的现象:车企将不再仅仅是“造车”,他们会深度介入能源管理(如 Megapack)。避雷区:没有液冷储备、仅靠买卡堆算力的二线供应商。高溢价区:能降低“单位算力能耗”的硬件,以及具备强“模型压缩”能力的工具链。马斯克的“端到端”梦工厂,不仅需要英伟达和自己家的芯片柴火,更需要 Vertiv 的冷风和 ARM 的精打细算。能源利用率,或许是这个时代最后的护城河。(免责声明:以上内容基于技术推演,不构成投资建议。入市需谨慎,咱们评论区见!)
思考题:你认为未来车企会像特斯拉一样走向全栈芯片自研,还是集体拥抱英伟达的标准化方案?

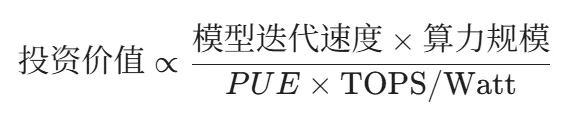
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
