当我们谈论自动驾驶的时候,很多人还停留在 “摄像头识别红绿灯、雷达躲避障碍物” 的初级认知里。
但如今,自动驾驶早已驶入发展深水区,行业竞争从简单的辅助驾驶功能比拼,转向了底层智能逻辑的角力,而世界模型,正是撬开下一代自动驾驶天花板的关键钥匙。
今天我们来聊聊它究竟会怎样改变我们未来的出行方式。
一、世界模型:给汽车装一个 “会预判的大脑”
我们可以先抛开复杂的学术定义,用人的逻辑来理解世界模型。
普通人开车,从来不是只盯着眼前的几米路况:看到前方路口有行人在路边低头玩手机,我们会提前预判他会不会突然横穿马路;前方车辆减速,我们会提前松油门预留安全车距;哪怕路边突然窜出小猫小狗,我们也能下意识做出避险反应。
这份 “理解世界运行规律、预判未来变化、提前做出最优决策” 的能力,就是人类天生的 “世界模型”。
而自动驾驶里的世界模型,本质就是给汽车打造一套同款能力。
和大语言模型学习文字逻辑类似,自动驾驶世界模型会通过海量真实路况数据做无监督学习,先把摄像头、激光雷达、高精地图等多模态传感器收集的画面,压缩提炼成统一的特征信息,在模型内部构建出一套对真实道路世界的完整认知,吃透车辆、行人、路况、天气之间的运行底层规律。
完成学习之后,它就不再只是 “看见什么就反应什么”,而是可以主动预测:
3 秒之后周边车辆会往哪个方向变道、路口行人接下来的移动轨迹、雨天路面摩擦力变化带来的刹车距离改变等等。
再通过解码器,把预测结果转化为车辆看得懂的控制指令、行驶规划,让汽车真正做到 “未卜先知”,而不是等危险临近才被动补救。
二、三大核心价值,彻底解决自动驾驶行业痛点
看懂了基础原理,你就会明白,世界模型不是一个花哨的技术概念,它精准击中了当前自动驾驶落地最难的几座大山,从训练、测试到实际行驶全链路赋能。
第一,破解行业最大难题:
稀缺场景数据。 自动驾驶想要足够安全,就必须见过成千上万种极端、罕见的危险场景。
但现实里,99% 的路况都是常规平稳路况,暴雨、大雾、夜间无灯路段、突发横穿的行人、连环复杂变道等长尾危险场景,不仅数量极少,人工采集成本极高,还伴随着巨大的安全风险。
而世界模型可以自主生成无限逼真的虚拟驾驶场景,完美复刻真实世界的物理规则和细节特征。不需要上路实测,就能批量补齐现实里难以采集的样本,给自动驾驶模型提供取之不尽的训练素材,从根源解决数据短板。
第二,打造无限安全的全真测试场。
一款自动驾驶功能正式上车之前,必须经过百亿公里级别的严苛测试验证。过去行业大多采用实车路测,不仅周期长、成本高,很多极限危险场景也根本没办法真人反复实测。
世界模型生成的虚拟场景,就成了完美的闭环仿真测试工具。工程师可以在虚拟环境里,无限次复现极端工况,反复打磨算法应对能力,不断迭代优化、闭环验证性能。既大幅压缩研发测试周期、降低成本,也彻底规避了实车测试的安全隐患,让装车落地的自动驾驶算法,经过千锤百炼。
第三,直接端到端指导智能驾驶决策。
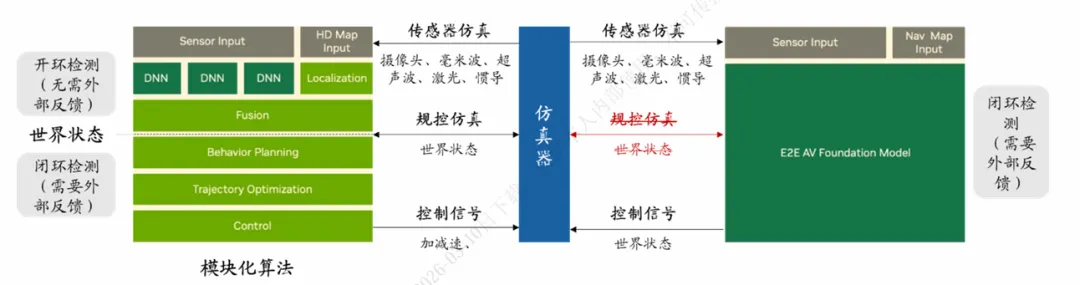
传统自动驾驶的流程,是感知、规划、控制模块拆分运行,一步一步传递指令。而多模态世界模型,可以直接输出完整的驾驶策略,打通从感知路况到最终车辆控制的全链条,让车辆的决策更连贯、反应更顺滑,真正实现拟人化的流畅、安全驾驶行为。
三、端到端浪潮来袭,世界模型成为必选项
如今自动驾驶正式进入深水区,端到端方案已经成为公认的未来主流发展方向,世界模型的战略重要性被无限放大。
一方面,端到端模型的性能提升,和数据体量、丰富度深度绑定。
模型越大、能力越强,对场景丰富度、长尾场景覆盖度、3D 细节标注精度的要求就越苛刻。
现实世界数据采集成本居高不下,危险场景更是可遇不可求,靠传统路测采集数据的模式,早已跟不上模型迭代速度。
这时,可以自主批量生成高精度合成数据的世界模型,就成了行业破局的最优解,既是逼真场景的生成器,也是未来路况的精准预测器。
另一方面,端到端架构彻底重构了传统仿真验证逻辑。
在过去模块化算法时代,行业可以拆分环节单独验证:感知模块单独检测识别结果,规控模块单独输入场景、验证决策性能,闭环测试门槛相对较低。
但端到端时代,感知、规控彻底合二为一,整个算法像一个完整的黑箱。想要完成全流程闭环测试,不仅要求仿真环境极致还原真实路况,还要能完美复刻算法和环境之间的实时反馈互动。
当下虽然 NeRF、3D 高斯等新兴仿真算法层出不穷,但想要完整覆盖自动驾驶全流程、实现全场景闭环测试,依然难度极高。而世界模型,恰恰是目前业内公认,最有能力攻克这一难题的最优解决方案。
四、行业全面提速,世界模型落地脚步越来越近
巨大的行业价值,也让全球头部企业、科技巨头都开始全力押注世界模型赛道,落地进程正在飞速提速。
特斯拉早在 2023 年 CVPR 行业大会上,就公开介绍自家端到端模型,明确提出要搭建完整的 4D 神经网络世界模型,让车辆真正理解真实世界的运行底层逻辑,大幅提升智能预判能力。
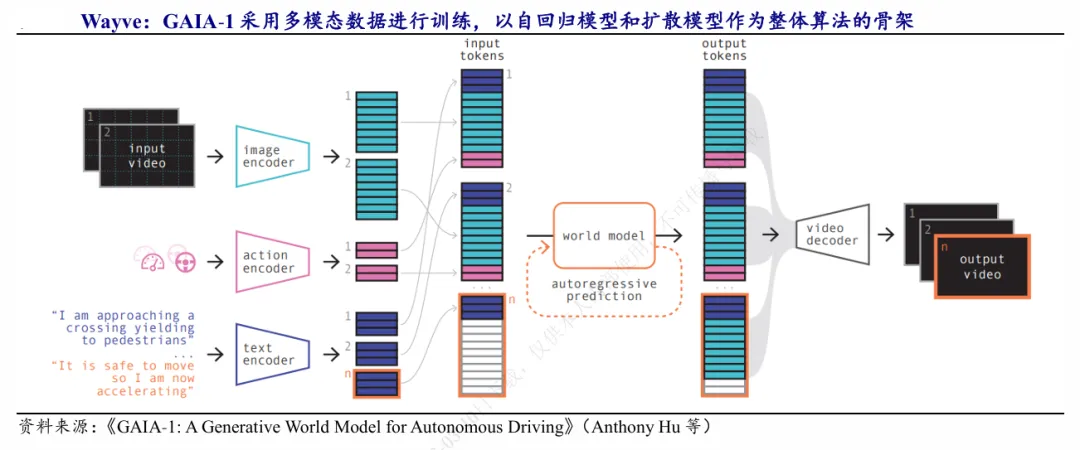
英国自动驾驶企业 [Wayve.ai](Wayve.ai),早早在 2023 年就推出 GAIA-1 世界模型,仅依靠视频、文本、动作三类基础输入,就可以自主生成高度逼真的完整驾驶视频场景,技术落地走在了行业前列。
英伟达也在 2024 年 GTC 技术大会上,公布了自家世界模型领域的全新技术突破。它可以把传感器数据、文字天气信息、非机动车、2D/3D 检测框、道路布局等海量多模态信息,统一输入模型完成训练,精准预测未来的完整路况变化。
只需要一个基础自动驾驶模型,就可以稳定生成多个摄像头视角下的未来驾驶场景,还原真实度达到了行业顶尖水平。
不难预见,接下来的几年里,世界模型将会成为自动驾驶体系里的核心标配。它会持续赋能算法训练、仿真测试、实车决策全流程,彻底改写整个智能出行行业的底层逻辑。
很多人会问:世界模型普及之后,自动驾驶距离完全解放双手还有多远?
客观来说,世界模型不是一蹴而就的魔法,没办法立刻让全自动驾驶全面落地。但它相当于给自动驾驶装上了人类一样的前瞻思维和全局认知能力,让汽车从只会 “被动应对眼前状况” 的机器,变成了可以 “主动理解世界、预判未来、智慧决策” 的真正智能体。
从靠海量实车试错,到靠智能模型提前预知风险;从零散的功能拼接,到完整的全局智能,世界模型正在悄悄掀起自动驾驶的新一轮技术革命。
等到这项技术真正成熟普及,我们坐上汽车、输入目的地,全程安心解放双手的全智能出行时代,就真的离我们不远了。

 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
