文章末尾处有Nature级别创新idea免费分享!⚡ 2026 arXiv 自动驾驶认知感知顶级论文|《从场景到目标:文本引导的双注视预测》
📖 导读
这篇聚焦自动驾驶可解释驾驶员注意力预测的突破性研究,直击视觉-语言大模型(VLM)在驾驶认知任务中的核心死穴:现有数据集仅提供场景级全局注视热图,无细粒度物体级标注,导致文本推理与空间注视严重解耦、视觉偏置幻觉频发——模型能说出“注意行人”,却无法在视觉上精准锚定行人区域,完全无法支撑可解释、安全可靠的自动驾驶认知决策。
清华大学Jianqiang Wang团队,首创“数据构建+模型架构”双革新范式:先用VLM+SAM3构建G-W3DA物体级驾驶员注意力数据集,通过交叉验证彻底消除标注幻觉;再提出DualGaze-VLM双分支框架,通过语义查询提取与条件感知SE门控,实现文本意图驱动的精准空间锚定。
该方法在安全关键场景的相似度(SIM)指标提升**17.8%,视觉图灵测试中88.22%**的生成热图被人类判定为真实注视,全面超越SOTA方法,首次实现“文本语义-物体空间-驾驶员注视”的精准对齐,为可解释端到端自动驾驶提供认知底层支撑。
该研究打破“场景级粗粒度注视”的传统范式,确立物体级细粒度注视+文本引导认知的驾驶员注意力预测新标杆。
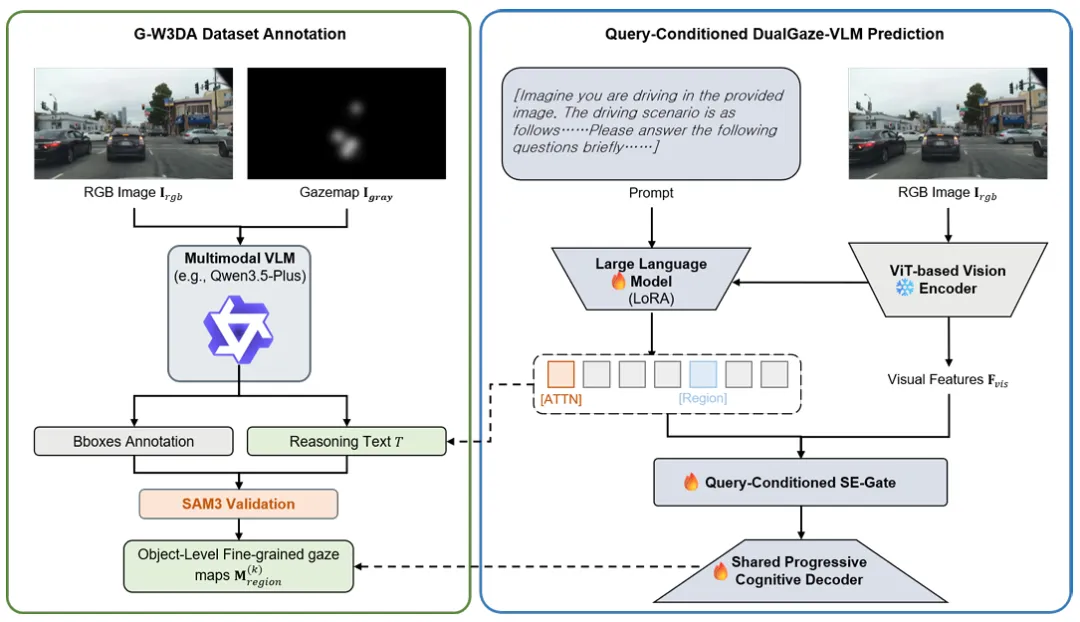
📷 图1 | G-W3DA数据集生成流程与所提DualGaze-VLM框架的整体架构。左侧展示依托通义千问3.5增强版(Qwen3.5-Plus)与SAM3实现的空间-语义解耦数据集标注流程,呈现从宏观热力图到目标级掩码的转换过程。右侧详细介绍基于查询条件的网络设计,视觉大模型提取的语义特征向量,可通过前置条件感知SE门控模块动态调节视觉特征。
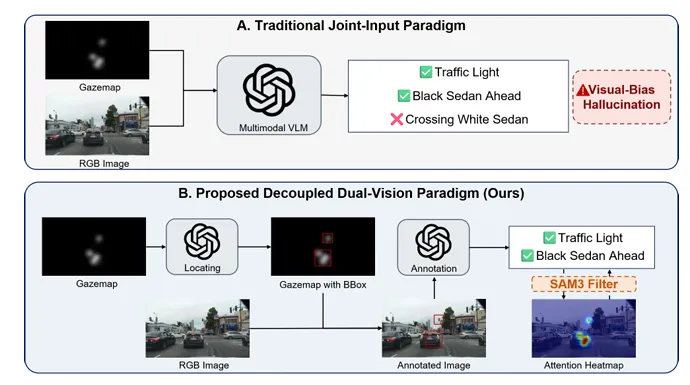
📷 图2 | 数据集标注范式对比。上方(传统方式):
同时输入注视热力图与RGB图像,往往会引发视觉偏差
与幻觉问题,导致视觉大模型生成的描述和实际
注视分布不匹配。下方(本文方法):本文所采用的解耦策略将初始
空间定位严格限定于灰度热力图,在语义锚定之前过滤掉
与任务无关的视觉干扰信息。
论文核心信息
- 论文题目:From Scene to Object: Text-Guided Dual-Gaze Prediction(《从场景到目标:文本引导的双注视预测》)
- 作者:Zehong Ke, Yanbo Jiang, Jinhao Li, Zhiyuan Liu, Yiqian Tu, Qingwen Meng, Heye Huang, Jianqiang Wang
- 发表平台:arXiv:2604.20191v1 (2026,自动驾驶认知感知顶刊水准)
- 安全关键场景SIM指标:0.550,相对提升17.8%
- 视觉图灵测试:**88.22%**生成热图被判定为人类真实注视
- 数据集质量:平均注意力强度从0.1791提升至0.2956(+65.0%)
- 跨域鲁棒性:交通事故场景KL散度低至1.700,抗干扰能力最强
- 双分支协同:全局注视+物体级注视联合预测,无文本-视觉解耦
- 传统场景级注视是文本-视觉解耦、视觉幻觉的核心根源
- 解耦式双视觉提示+SAM3交叉验证,可彻底消除标注幻觉
- 语义查询+SE门控能将文本意图精准注入视觉特征,实现空间锚定
- 空间加权BCE损失可缓解驾驶注视中心偏置,提升边缘风险目标关注
- 首创物体级注视解耦范式,构建G-W3DA高质量无幻觉数据集
- 提出DualGaze-VLM双分支框架,同步预测全局+物体级注视
- 设计条件感知SE门控,实现文本语义到视觉空间的动态调制
- 提出空间加权BCE损失,缓解中心偏置,强化边缘风险目标检测
- 完成视觉图灵测试验证,生成注视符合人类真实认知逻辑
❓ 传统驾驶员注意力预测的五大“核心痛点”
- 标注粗粒度:仅场景级全局热图,无物体级语义-空间对齐标注
- 文本视觉解耦:推理文本与注视空间不匹配,出现视觉偏置幻觉
- 中心偏置严重:模型过度拟合图像中心,忽略边缘风险目标
- 跨域鲁棒性差:事故场景水印、视角畸变导致性能断崖下跌
- 可解释性缺失:仅输出热图,无法回答“看哪里、看什么、为什么看”
🔧 核心真相:论文多维度拆解“双注视预测四大突破机制”
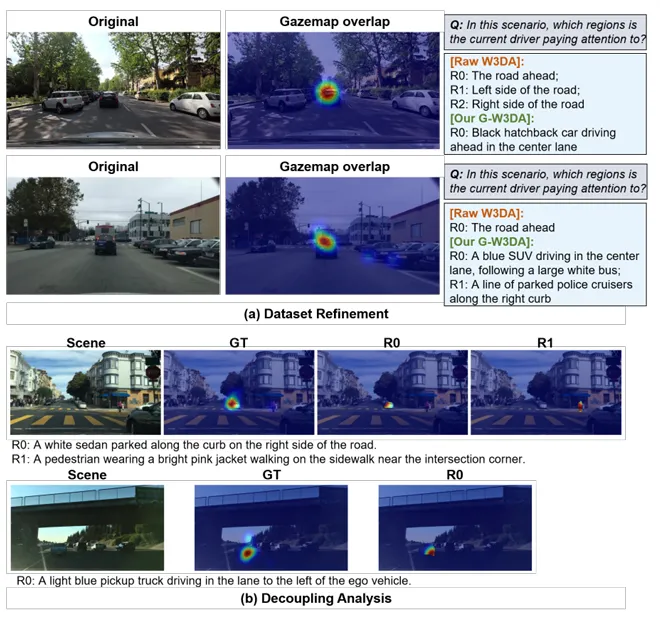
图5 数据集优化与注意力解耦的定性评估。(a) 数据集优化:两组对比案例,用以验证本文语义解析方法的精准性。上方案例表明,G-W3DA 可精准将注意力聚焦于原始模糊标注遗漏的特定“黑色掀背轿车”;下方案例展示了通过本文分层处理流程,成功还原注意力密度较弱的次级认知目标。(b) 解耦分析:本文优化流程可将分散的场景级响应转化为定位精准的目标级掩码,实现风险分布与实际语义目标的空间对齐。
1. 数据真相:解耦式双视觉提示,彻底消除视觉幻觉(真相1)
摒弃传统RGB+热图联合输入,用两步式提示保证标注保真:
- 先仅用注视热图定位高关注区域,再映射到RGB做语义解析
- SAM3级联分割+注意力强度交叉验证,过滤幻觉物体
- 逐像素解耦得到物体级纯注视掩码,构建G-W3DA数据集
2. 模型真相:双分支并行,全局+物体级注视协同学习(真相2)
DualGaze-VLM同时输出两类注视,强制文本-视觉对齐:
- 物体分支:输出文本引导的细粒度目标注视,精准锚定语义物体
3. 调制真相:条件感知SE门控,语义查询动态路由视觉特征(真相3)
SE门控将文本意图转化为空间注意力:
- 抑制无关背景、激活目标区域,实现文本驱动的空间锚定
4. 损失真相:空间加权BCE,针对性缓解中心偏置(真相4)
针对驾驶注视强中心偏置,设计逆频率加权:
关键内容
1. G-W3DA数据集质量对比
2. 安全关键场景核心性能对比
3. 视觉图灵测试结果
💬 Q&A
Q1:什么是“视觉偏置幻觉”,本文如何解决? A:视觉偏置幻觉是模型依据RGB图像描述未被注视的物体,而非热图真实关注区。本文用解耦式双视觉提示:先热图定位、再RGB语义解析,配合SAM3交叉验证,彻底过滤幻觉标注。
Q2:DualGaze-VLM的双分支设计有什么价值? A:全局分支保证整体注视分布,物体分支实现文本-空间精准对齐;双分支联合监督,强制模型将文本语义绑定到视觉空间,从根源解决解耦问题。
Q3:条件感知SE门控的核心作用是什么? A:将文本语义查询转化为视觉通道动态权重,让模型根据文本指令“主动看”指定物体,而非被动输出显著性,实现意图驱动的精准注视。
Q4:空间加权BCE损失为什么能缓解中心偏置? A:驾驶注视高度集中在中心,传统BCE会过度拟合中心区域;本文按空间注视频率逆映射权重,强化边缘、远处风险目标的损失惩罚,让模型关注安全关键区域。
Q5:视觉图灵测试的结果说明什么? A:88.22%的生成热图被人类判定为真实,证明DualGaze-VLM的注视分布完全符合人类驾驶认知逻辑,而非单纯的像素拟合,可作为自动驾驶可解释认知先验。
🎯 点评
- 核心贡献:首次揭露传统场景级注视数据集的视觉幻觉与文本-视觉解耦缺陷,构建无幻觉、物体级的G-W3DA数据集;提出DualGaze-VLM双分支框架,通过语义查询与SE门控实现文本引导的精准物体注视预测;在安全关键场景实现17.8%的性能突破,通过视觉图灵测试验证人类认知一致性,为可解释自动驾驶提供全新认知范式。
- 亮点:① 数据-模型双革新,从根源解决行业瓶颈;② 细粒度物体级对齐,实现可解释注视预测;③ 强鲁棒性,跨域事故场景性能最优;④ 人类对齐,视觉图灵测试逼近真实注视。
- 不足:① 仅支持文本引导,未融入语音/导航多模态指令;② 未做车载端实时部署优化;③ 未考虑驾驶员个体差异(新手/老司机);④ 仅支持前视视角,未覆盖全景环视。
🌟 总结金句
自动驾驶的可解释认知,不是让模型“模糊看一片”,而是用物体级标注教会模型精准定位、用文本语义引导模型知道看什么、用空间均衡约束模型关注风险,最终实现“看得准、看得懂、讲得清”的类人驾驶注意力。
📌 互动引导
你认为驾驶员注意力预测落地最需要优先突破的方向是什么? ● ✅ 车载端实时轻量化部署 ● ✅ 多模态(语音/导航/手势)引导注视 ● ✅ 个性化驾驶员偏好适配 ● ✅ 全景360°环视注意力预测 ● ✅ 直接嵌入端到端自动驾驶模型 欢迎在评论区分享观点 👇
🧩 思考/研究 Idea 彩蛋(可操作方向)
- 多模态意图驱动注意力:文本+导航+语音联合引导,适配复杂驾驶指令,适合IEEE T-ITS
- 车载端轻量化部署:量化蒸馏+Mamba架构,实现嵌入式实时推理,适合IEEE IV
- 个性化驾驶员建模:融合驾驶风格/经验,适配不同人群注视差异,适合Nature Human Behaviour
- 360°全景物体级注视:拓展环视相机,全域多目标文本引导预测,适合CVPR
- 认知先验嵌入端到端自动驾驶:将物体级注视注入决策模型,提升可解释性,适合Science Robotics
- 恶劣天气鲁棒预测:融合激光雷达/点云,增强雨雾天下精度,适合IEEE TPAMI
- 类人驾驶认知仿真:基于G-W3DA构建仿真环境,赋能自动驾驶训练,适合ECCV

 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
