想做自动驾驶,论文看了不少,笔记记了很多,热点方向也大概知道一些,但一到找创新点、写综述、定选题,还是很容易没头绪。
问题往往不是你不够努力,而是阅读路径一开始就偏了:先盯单篇方法,容易被局部创新带着走;先看零散结果,容易忽略整个领域研究范式的变化。
因此,非常推荐大家去看看这份自动驾驶资料,它能够很好地解决你的问题!
它不只是简单整理了 CVPR、ICLR、ICCV、AAAI、ICRA 等顶会顶刊146篇前沿论文和代码;更重要的是,它按照自动驾驶当前的研究脉络做了系统分类!通过这份资料,你可以更快看清感知、预测、规划、端到端、世界模型、多模态大模型等方向分别在关注什么问题、有哪些思路值得跟进。不管你是刚入门、在做综述,还是想追踪前沿、寻找研究切口,都很实用!
扫描下方二维码,回复「146自驾」
免费获取全部论文合集及项目代码
VLA 多模态大模型+自动驾驶
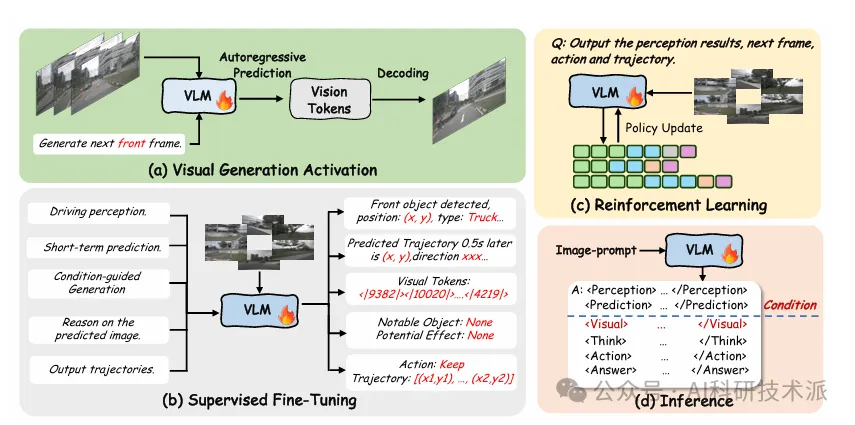
【CVPR26】Learning Vision-Language-Action World Models for Autonomous Driving
内容:这篇论文提出面向自动驾驶的VLA‑World统一框架,融合视觉‑语言‑动作(VLA)模型的推理能力与世界模型的时序预测能力,通过视觉预训练、有监督微调、GRPO 强化学习三阶段训练,先依据短期轨迹生成未来帧,再对自生成的未来画面做反思推理以修正规划轨迹,同时构建 nuScenes‑GR20K 专用数据集,实验表明该模型在轨迹规划、未来帧生成、动作预测上均超越现有 VLA 与世界模型基线,碰撞率与 FID 得分最优,安全性与可解释性显著提升。
世界模型 & 4D 驾驶表征
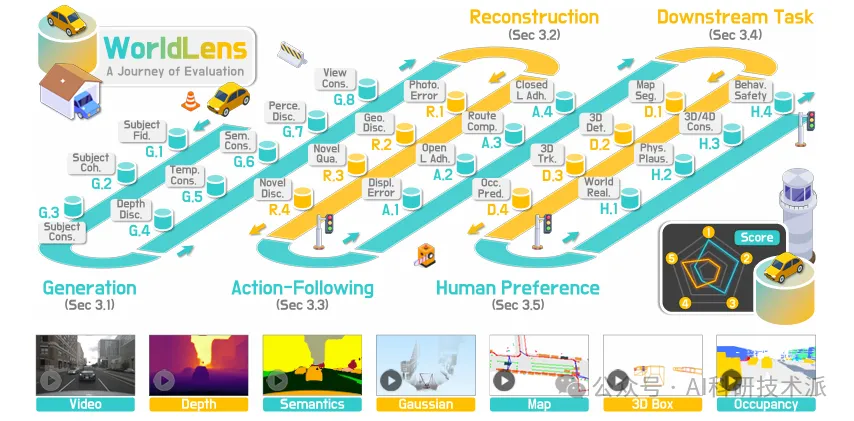
【CVPR26】WorldLens: Full-Spectrum Evaluations of Driving World Models in Real World
内容:该论文提出面向世界模型的WorldLens综合评测框架,从生成质量、4D 重建、指令跟随、下游任务适配、人类偏好五大维度全面评估,解决以往仅聚焦视频画质、忽略落地实用性的问题,配套公开评测工具包,为自动驾驶等场景的世界模型研发提供标准化、实用化的评价体系。
端到端自动驾驶
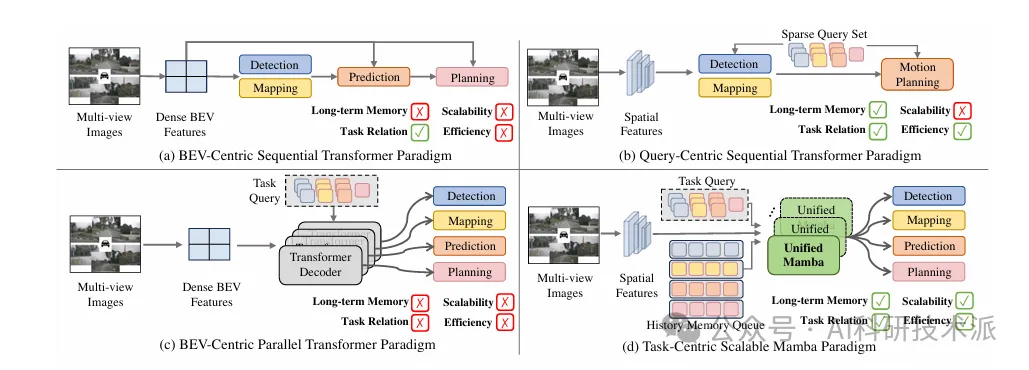
【ICLR26】DriveMamba: Task-Centric Scalable State Space Model for Efficient End-to-End Autonomous Driving
内容:论文提出DriveMamba,一种面向高效端到端自动驾驶的任务中心化可扩展 Mamba 架构,摒弃传统 Transformer 的时序感知‑预测‑规划串行范式与稠密 BEV 特征,将图像与任务输出转为稀疏 Token 并按 3D 空间排序,通过统一 Mamba 解码器并行实现视角对应学习、动态任务关系建模与长期时序融合,搭配轨迹引导的双向局部到全局扫描保留自车空间局部性;模型具备线性复杂度、低显存占用与易堆叠扩展优势,在 nuScenes 与 Bench2Drive 上实现更低轨迹 L2 误差、碰撞率与更高推理帧率,综合性能与效率超越主流 BEV‑Centric、Query‑Centric 方法。
扫描下方二维码,回复「146自驾」
免费获取全部论文合集及项目代码
轨迹预测 & 运动规划
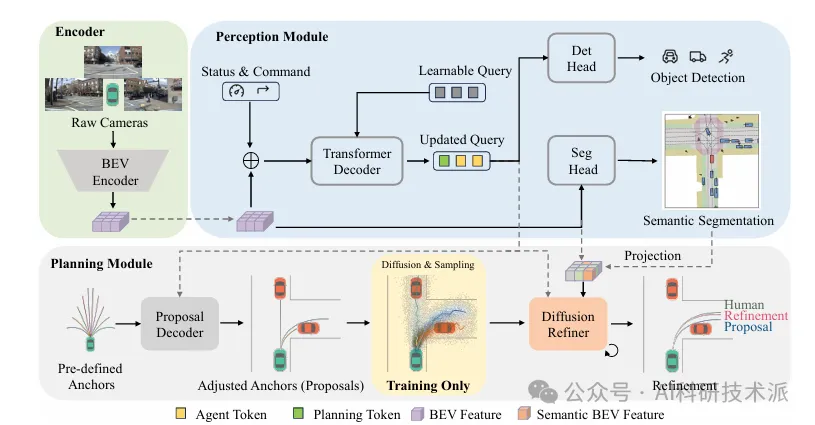
【AAAI26】DiffRefiner: Coarse to Fine Trajectory Planning via Diffusion Refinement with Semantic Interaction for End to End Autonomous Driving
内容:这篇论文提出面向端到端自动驾驶的DiffRefiner两阶段轨迹规划框架,先由基于 Transformer 的提议解码器从预定义轨迹锚点回归生成粗轨迹,再通过带细粒度语义交互的扩散精炼器迭代去噪优化;核心设计Fine‑Grained Semantic Interaction Module,融合可行驶区域语义与动态交通参与者信息,让轨迹更好贴合场景约束,在 NAVSIM v2 与 Bench2Drive 上刷新 SOTA,兼顾生成式方法的多模态优势与判别式方法的稳定初始化,推理高效且安全性更强。
3D感知&多传感器融合
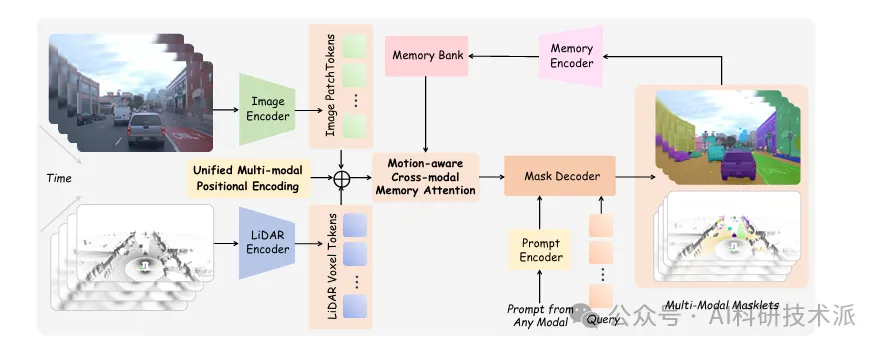
【ICCV25】SAM4D: Segment Anything in Camera and LiDAR Streams
内容:该论文提出SAM4D,是面向相机与激光雷达流的4D 可提示分割基础模型,通过统一多模态位置编码实现跨模态特征对齐,搭配运动感知跨模态记忆注意力提升时序一致性,并构建含 30 万 + 标注的Waymo‑4DSeg数据集与自动化数据引擎,可高效完成自动驾驶场景下的2D‑3D 联合、跨模态提示、时序连贯分割任务。
扫描下方二维码,回复「146自驾」
免费获取全部论文合集及项目代码