摘要:人工智能已成为自动驾驶系统(ADS)、机器人等安全关键领域不可或缺的组成部分。近期自主系统的架构正朝着端到端(E2E)单体架构方向发展,例如大语言模型(LLM)与视觉语言模型(VLM)。本文首先回顾不同架构方案,然后评估失效模式与影响分析(FMEA)、故障树分析(FTA)等常用安全分析方法的有效性。我们展示如何针对基础模型的复杂特性(尤其是其构建与使用隐式表示的方式)改进这些技术。本文提出HySAFE‑AI——面向AI系统的混合安全架构分析框架,这是一种适配传统方法以评估AI系统安全性的混合框架。最后,本文对未来工作提出展望,并为未来AI安全标准的演进提供建议。
原文作者:Mandar Pitale,Jelena Frtunikj,Abhinaw Priyadershi,Vasu Singh,Maria Spence
原文标题:HySAFE-AI: Hybrid Safety Architectural Analysis Framework for AI Systems: A Case Study
编译:猿东东,猿西西
将人工智能(AI)集成到自动驾驶、医疗、工业机器人等安全关键领域,可显著提升效率与决策能力。然而,包括大语言模型与视觉语言模型在内的基础模型(FM),因其黑盒架构与动态行为难以分析,复杂性与不透明性带来了全新的安全挑战。
基础模型的广泛部署凸显出在确保安全可靠运行方面存在显著缺口。与传统领域专用AI模型不同,基础模型的可解释性有限,难以追溯决策过程并识别潜在失效点。这种透明度不足引发了其在安全关键场景适用性的担忧。
自动驾驶AI系统架构演进
自动驾驶系统传统上采用模块化架构,感知、预测、规划、控制等组件相互独立。模块化架构虽具备可解释性优势,但存在固有局限,影响系统鲁棒性,原因如下:
- 独立模块间接口与交互管理复杂;
- 模块间错误级联传播。
端到端(E2E)模型通过统一的全可微架构,直接将传感器数据映射为控制指令,基于海量驾驶数据训练,解决了上述局限。端到端系统简化了开发、降低组件集成难度,但因其“黑盒”特性带来严重的可解释性问题,导致失效分析与安全保障难度大幅提升。
混合架构结合模块化与端到端的优势,在端到端可训练框架中保留可识别的模块 [30],在减少组件间信息损失的同时实现可解释性。
本文贡献
安全关键系统的安全保障传统上依赖成熟的分析方法,包括FMEA、FTA、事件树分析(ETA)、系统理论过程分析(STPA)、关键路径分析(CPA)。这些方法在评估传统工程系统与架构清晰的领域专用AI应用时效果良好。但基于基础模型的AI系统因规模、复杂度、不透明性与结构透明度缺失,带来重大挑战。本文针对基础模型相关安全挑战开展以下工作:
- 指出传统安全分析在端到端自动驾驶系统中的局限性;
- 结合面向基础模型系统的原则与技术,对传统分析方法进行增强;
- 构建具备足够细节、可支撑有效分析的端到端参考架构,并应用改进后的分析方法。
本节详细介绍端到端参考架构,对比分析AI模型在感知到控制全栈的集成方式,并指出现有安全标准与安全分析方法应用于隐空间驱动架构时的关键局限。
端到端参考架构
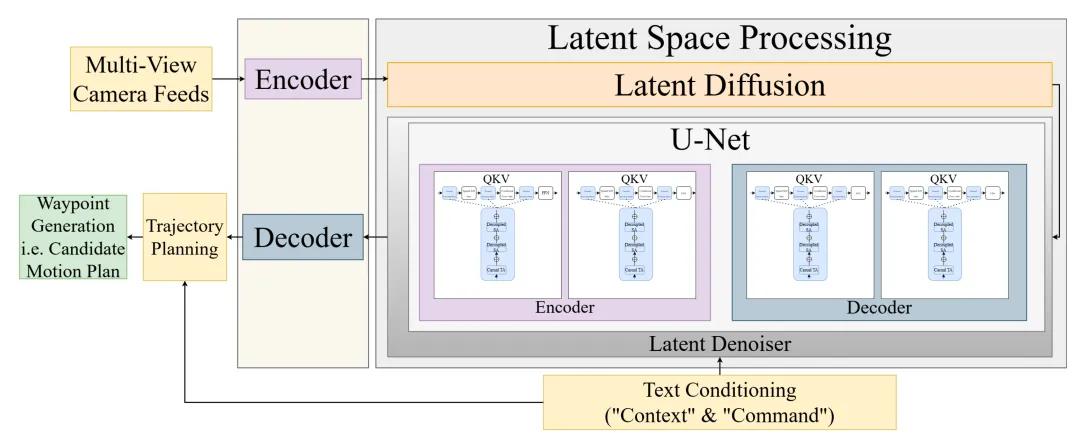
生成式自动驾驶模型(GenAD、GAIA‑1、GAIA‑2)共享统一架构蓝图,包含三大核心组件:
- 隐空间建模:所有模型均在压缩隐空间中运行以提升计算效率。GenAD采用冻结的变分自编码器(VAE)与UNet去噪模块;GAIA‑1将多模态输入离散化为令牌序列;GAIA‑2采用时空分解Transformer,空间压缩比32倍。
- 生成式主干网络:隐空间去噪器迭代优化受损特征。GenAD使用带时序推理模块的UNet;GAIA‑1/2采用基于Transformer的世界模型——GAIA‑1使用自回归离散令牌,GAIA‑2使用84亿参数的连续隐空间Transformer。
- 多模态条件输入:对场景控制与可解释性至关重要。GenAD通过BLIP2/CLIP实现文本条件输入;GAIA系列使用语义提示控制场景元素与自车轨迹。
- 视频合成与推理:GenAD通过MLP轨迹解码从去噪隐空间生成视频;GAIA‑1使用扩散解码器;GAIA‑2通过滑动窗口重建多摄像头视频。所有模型均支持可控场景生成,能力各有差异。
图1所示参考架构整合GAIA‑2与GenAD组件,实现统一的自动驾驶仿真与运动规划。
注:U‑Net、隐空间去噪器等组件可通过量化降低内存与计算开销,便于在资源受限的车载硬件上部署大模型。但量化可能导致精度损失,需开展严谨的安全分析,避免安全关键场景性能下降。
AI模型在自动驾驶中的当前应用
自动驾驶栈在感知、定位、预测、规划、控制各层集成多样化AI模型架构。传统卷积神经网络(CNN)仍是实时安全关键环境的核心。基础模型(FM)——大规模多模态AI系统——可实现感知、定位、预测、规划的深度集成,提升泛化能力。CLIP等视觉语言模型(VLM)提升语义理解能力;大语言模型(LLM)在推理与规划领域展现出新兴潜力。控制层仍主要依赖传统AI模型,以满足严苛的时延与稳定性要求。
传统AI模型仍是感知、控制等实时任务的基础,而基础模型推动规划与感知领域的创新。视觉语言模型弥合视觉与语言鸿沟,但尚未在感知、规划、控制等层独立使用。大语言模型有望成为自主系统的“大脑”,在复杂场景中实现类人决策与自适应能力。
传统安全标准与AI扩展
IEC 61508与ISO 26262提供基础安全框架,但缺乏AI专项指导。ISO 21448(预期功能安全SOTIF)将其扩展至自主系统,解决性能局限与意外场景问题,强调数据相关安全措施(如离线训练的过程FMEA)与可解释性分析以评估机器学习决策,但对架构安全分析指导有限。面向AI的标准如ISO/PAS 8800(汽车领域)、ISO/IEC TR 5469(跨行业)提出定制化安全生命周期,强调数据质量、不确定性量化与AI安全属性(鲁棒性、可解释性)。ISO/PAS 8800要求在全开发阶段开展安全分析,并为基于AI的系统中现有安全分析技术提供参考指导。ISO/TS 5083:2025中关于AI安全的内容与ISO/PAS 8800基本一致。制定中的ISO/IEC TS 22440‑1强调AI技术选型必须基于安全影响分析,综合考虑模型规模、实时性、不确定性评估与可解释性。制定中的ISO/IEC AWI TS 25223聚焦AI系统不确定性量化方法。这些标准提供基础框架,但未针对基础模型特性制定专项条款。
现有AI安全分析方法
FMEA‑AI 将FMEA适配于AI公平性分析,应用于行人与人体检测等场景,但缺乏架构分析。文献综述FMEA/FTA在AI中的应用,发现多数研究聚焦领域专用故障,而非AI固有失效、AI专属资产或风险,未开展新的分析工作。文献识别机器学习专属错误,对视觉导航系统开展定性危害分析与FMEA,提出高层安全需求,但未开展详细组件分析。文献聚焦社会技术系统(包括前沿AI)的系统级危害,不适用于识别复杂、不透明基础模型的固有失效模式。
传统安全分析对AI系统的根本局限
传统安全分析方法(FMEA、FTA)针对组件边界清晰、失效机理明确的系统设计。从基本原理看,这些方法应用于AI/基础模型系统时存在三大关键局限:
- 抽象不兼容:FMEA与FTA在组件或功能层工作,失效状态离散;而AI/基础模型系统在连续隐空间中使用分布式表示,“失效”表现为统计偏差而非二态跃迁。
- 因果不透明:FMEA与FTA假设事件间存在可追溯的因果关系,而AI/深度神经网络/基础模型中数百万参数相互作用,无明确因果链。
- 时序动态性:传统分析假设系统行为长期稳定,而AI/深度神经网络/基础模型系统的行为依赖上下文,随输入序列、环境与运行设计域(ODD)因素变化。
这些根本局限要求提出新方法,兼顾基础模型系统的独特特性,同时保持与现有安全工程实践的兼容性。
HySAFE‑AI以架构透明度为基本前提,通过两项方法学扩展直接解决上述局限:
- 前提条件:架构透明度
本文安全分析方法要求对基础模型系统架构的不同层级与表示维度具备充分可见性。尽管基础模型在运行时仍为“黑盒”,但系统化安全分析需要访问架构实体,以识别失效传播路径。
多层级抽象
本文在架构实体(从原始输入到隐空间)范围内系统分析基础模型系统,使安全分析可追踪跨系统边界的失效传播。
AI专属失效分类
本文建立标准FMEA引导词(如“值错误”“值缺失”)与通用AI失效模式(如幻觉、分布偏移、量化效应)的系统映射。这些AI失效模式可跨领域通用,领域专属表现则描述其在特定场景(本文为自动驾驶)中的具体形态。例如,通用AI失效模式“幻觉” 在自动驾驶系统中具体表现为“预测图像中出现不存在的物体或智能体(如障碍物、行人)”;“时序推理失效”在汽车领域表现为“其他道路使用者运动预测错误”。量化效应——为提升硬件效率降低模型精度导致的通用AI失效模式——可映射至FMEA引导词“值缺失”,在自动驾驶领域表现为“异常光照条件下道路边界无法正确检测”。
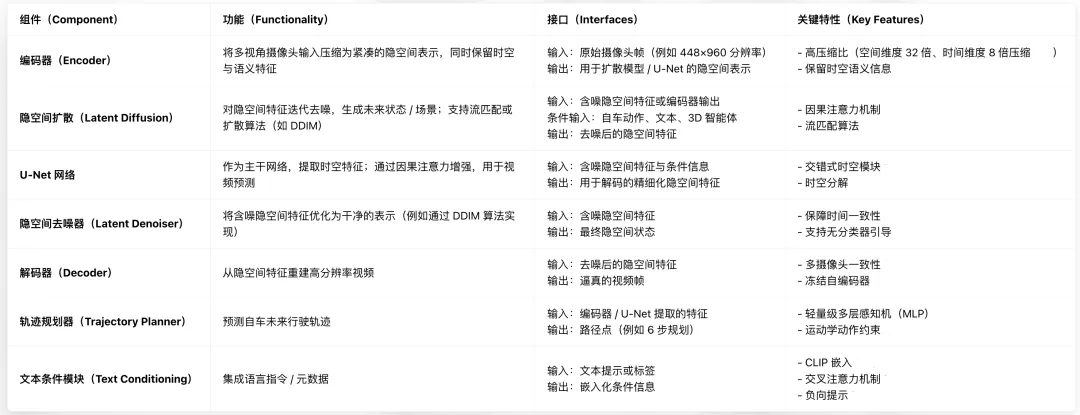
表2“AI失效模式(FMEA引导词)”列系统映射上述及其他AI专属失效模式与对应传统FMEA引导词。该映射确保现有安全框架在底层技术演进时仍可适用。HySAFE‑AI通过系统性扩展FMEA框架纳入AI专属失效模式并关联成熟引导词,实现结构化、可解释的风险评估,衔接AI模型行为与传统安全工程实践。
表2:HySAFE‑AI FMEA(含AI专属失效模式与FMEA引导词)
(注:S-严重度,O-发生度,D-可检测度;分值范围1-10;RPN = S×O×D)
在传统故障树分析(FTA)中,端到端AI组件通常在故障树中表示为单个节点,体现其“黑盒”特性。HySAFE‑AI扩展传统FTA,纳入表示隐空间错误、时序预测错误等的失效路径,可识别端到端栈不同模块及模块间交互引发的失效场景。
通过这种增强型 FMEA/FTA方法,HySAFE‑AI既保留经典安全分析的严谨性,又应对AI系统的规模、复杂度与不透明性,避免安全措施冗余,确保基于基础模型的自动驾驶栈保持鲁棒、可靠,并符合不断演进的安全标准。
参考架构用例:HySAFE‑AI实操演示
下述FMEA分析识别关键AI专属失效模式,包括幻觉与时序预测错误。虽非穷尽分析,这些示例(风险优先数RPN 100–252)凸显无专用安全措施时,基于基础模型的自主系统存在的关键脆弱点,同时纳入量化等性能优化带来的失效模式。RPN值基于专家判断,前三大RPN值的原因如下:
- 隐空间去噪器——量化激活:RPN最高(252),严重度(S=9)高,因虚假物体检测可能触发紧急避让,引发严重事故;发生度(O=7)高,因分布外输入问题频发;检测难度(D=4)高,因量化伪影可能生成看似合理但不存在的物体,难以检测。
- 隐空间去噪器:检测难度略低(D=3),但在影响决策前已存在风险。
- 因果时序注意力:系统错误预测道路使用者行为时失效,严重度(S=9)高,因轨迹估计错误可能引发碰撞;发生度(O=7)高,因异常场景挑战频发;检测难度(D=4)高,因区分合理与错误运动预测需要复杂验证。
- 训练数据集——陈旧性:RPN 216,严重度9,因缺失新型道路使用者(如电动滑板车、新型自行车)可能导致严重事故;发生度(O=6)中等,因适应道路环境演进需要时间;检测难度(D=4)高,因难以区分数据集陈旧与对抗输入导致的性能下降。
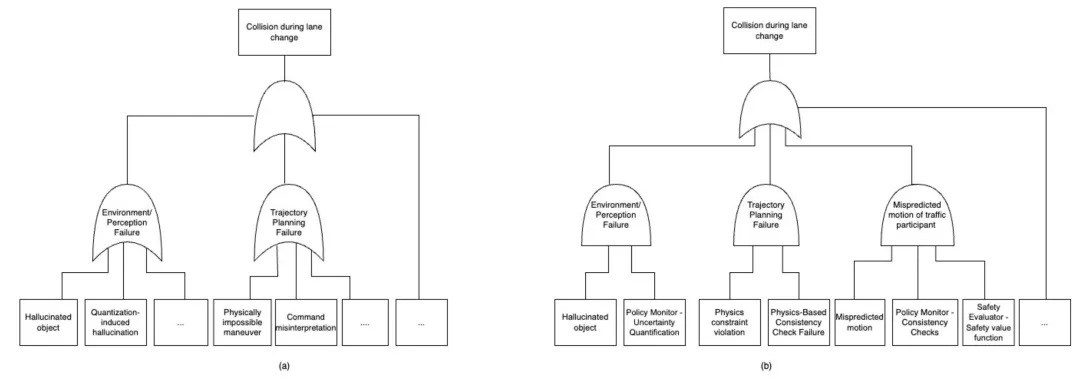
图2 (a) 的FTA图局部展示感知与运动规划失效如何共同导致不安全结果,凸显端到端参考架构中的逻辑依赖与单点失效。
图2:(a) HySAFE-AI故障树分析(FTA);(b)加入缓解措施的 HySAFE-AI故障树分析(FTA)
HySAFE‑AI结果:融合栈模型
参考架构FMEA中识别的高RPN值与FTA失效,需要架构级安全缓解措施,如表3所示。此外,表4的FMEA展示如何通过架构措施(如策略监控器、安全评估器等安全感知组件)系统性缓解参考架构的AI/机器学习专属失效模式,显著降低RPN值。该局部分析通过精选示例证明,传统安全机制(如冗余、合理性检查)可适配解决AI/机器学习失效,同时保留基础模型的预测能力。图2 (b) 的FTA图展示如何通过架构措施系统性缓解参考架构的AI/机器学习专属失效模式,使单点失效变为双点或多点失效。
表4:HySAFE‑AI应用缓解措施后的FMEA分析(D、RPN:负值代表风险改善)
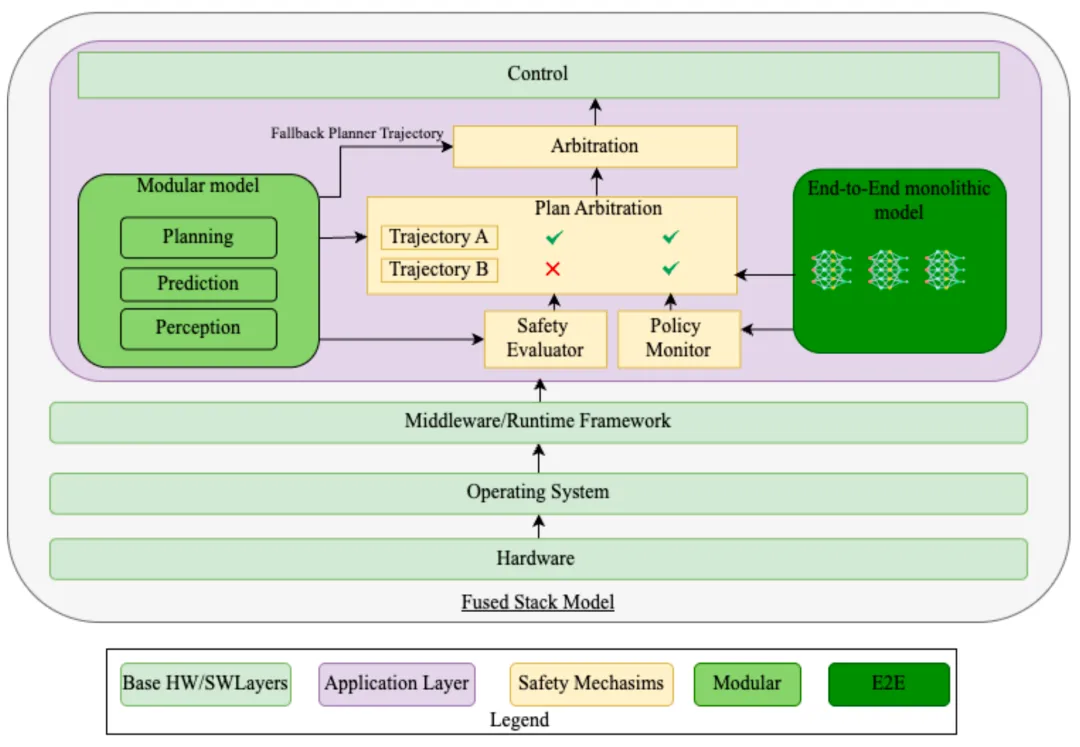
缓解措施应用后的架构如图3所示。策略监控器通过分布外检测与不确定性量化,基于置信度评估端到端规划器可靠性。安全评估器应用基于规则与物理推导的检查,拒绝不安全轨迹。规划仲裁器选择同时通过策略监控器与安全评估器检查的最高置信度轨迹。与反应式轨迹跟踪系统可对比轨迹不同,该方法通过AI与物理结合的安全保障对规划进行预验证。
自动驾驶系统中的端到端AI模型面临可解释性、验证复杂度、因果混淆、隐空间错误等核心挑战。为解决这些问题,本文提出HySAFE‑AI,一种将传统FMEA/FTA方法适配AI专属风险的混合安全分析方法。通过集成不确定性量化、量化感知训练、实时策略监控,可降低安全关键失效风险。融合架构将基础模型与安全评估器结合,在确保鲁棒性的同时符合ISO/PAS 8800、ISO 26262等功能安全标准指导。该融合架构通过集成运行时安全机制(如基于不确定性量化的策略监控器、安全评估器、仲裁器等)提升端到端自动驾驶系统安全性,但会引入计算开销,可能影响对驾驶实时性至关重要的时延。
未来工作将聚焦:
- 全面分析端到端自动驾驶系统失效模式;
- 基于危害提出设计级或运行时缓解措施,提升自动驾驶系统中基础模型的安全性。
- 与标准组织协作对制定混合AI安全架构指导(技术报告或规范)至关重要。
免责声明:文中观点仅供分享交流,文章版权及解释权归原作者及发布单位所有,如涉及版权等问题,请您联系TechApe@yeah.net告知,我们会在第一时间做出处理。