
🐉 龙哥读论文知识星球来了!公众号每日8篇拆解不够看?星球无上限更AI领域论文、资讯、招聘、招博、开源代码,一站式干货,每日2分钟刷完即赚!👇扫码加入「龙哥读论文」知识星球,前沿干货、实用资源一站式拿捏~

龙哥推荐理由:
这是一篇相当硬核的对抗攻击文章,来自香港城市大学团队。它直击当前端到端自动驾驶系统安全测试的痛点——多数攻击只盯着转向,忽略了速度控制,且攻击模式单一。UniAda不仅同时搞定了转向和加速,而且攻击扰动是人眼几乎无法察觉的通用型,这意味着它可以在不“改头换面”的情况下,让一整段驾驶视频里的车都“发疯”。论文方法设计精巧,实验结果扎实,对自动驾驶安全领域的研究者和工程师来说,都是极具价值的硬核参考。
原论文信息如下:
论文标题:
UniAda: Universal Adaptive Multi-objective Adversarial Attack for End-to-End Autonomous Driving Systems
发表日期:
2026年04月
发表单位:
香港城市大学(City University of Hong Kong),中山大学
原文链接:
https://arxiv.org/pdf/2604.23362v1.pdf
开源代码链接:
https://github.com/UniAdaRepo/UniAda/
自动驾驶系统的“暗箭”:通用多目标对抗攻击,揭秘UniAda如何同时欺骗转向与加速
想象一下,你正坐在一辆自动驾驶汽车里,车子平稳地行驶在市区道路上。突然,在你完全没察觉的情况下,一个极其微小的“暗箭”悄悄潜入了摄像头画面——它小到你肉眼根本无法发现,但汽车的大脑(深度学习模型)却被它彻底欺骗了。结果呢?方向盘猛地一打,车速突然飙升,一场事故可能就此酿成。这不是科幻电影,而是正在发生的现实威胁。
对抗攻击(Adversarial Attack)一直是深度学习安全领域的热点。简单说,攻击者通过给输入图片施加人眼不可察觉的微小扰动,就能让模型输出完全错乱的结果。在图像分类任务中,可以让模型把“狗”认成“猫”;在自动驾驶这类回归任务中,则可以让模型输出离谱的方向盘角度和车速。
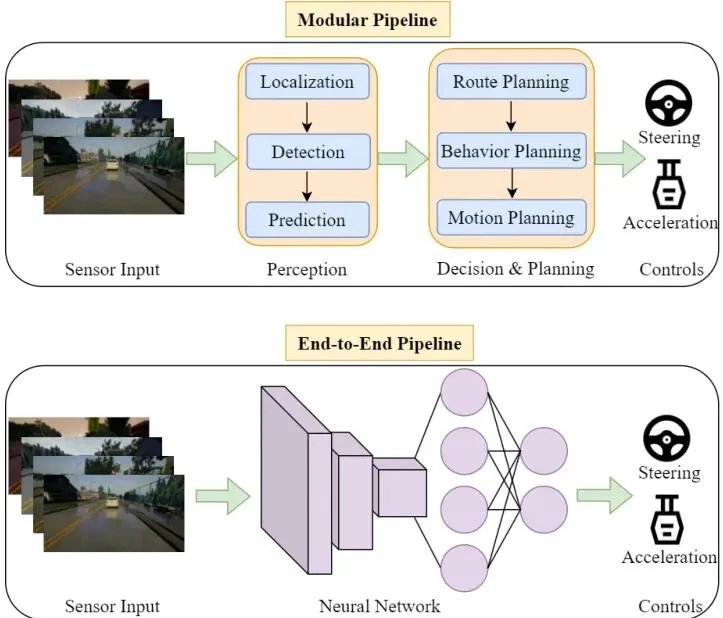
目前的端到端(End-to-End, E2E)自动驾驶系统(ADS)采用深度学习模型直接处理摄像头图像,输出转向和加速/制动控制信号。这类系统虽然表现亮眼,但安全漏洞令人担忧。现有对抗攻击研究大多只盯着转向角度,完全忽略了速度控制,这好比一个试驾员只测试方向盘,却对油门和刹车不管不顾,显然不符合实际驾驶安全需求。图1:模块化ADS流水线(上)与基于深度学习的端到端ADS流水线(下)概览
来自香港城市大学和中山大学的研究团队带来了一个“大杀器”——UniAda(Universal Adaptive Multi-objective Adversarial Attack)。这是首个能够同时欺骗转向(Steering)和加速(Acceleration)两个控制量的通用性对抗攻击方法。更绝的是,它生成的扰动是“图像无关”的——同一张扰动贴上去,一整段视频里的画面全都会被带偏,堪称“一贴灵”。
先来看看对抗攻击到底有多“恐怖”。下图展示了在图像分类和回归任务上,一个微小扰动如何彻底改变模型输出。图2:对抗攻击在图像分类和回归任务上的示例。扰动τ的像素值已缩放以可见。
在分类任务中,一张拉布拉多犬图片加上扰动后,模型竟然以27.46%的置信度认为这是“萨路基犬”。而在回归任务(自动驾驶)中,原始图像预测转向角0.1°,加扰后直接飙到21°,车辆瞬间偏离路线。UniAda要做的,就是生成这种既能骗转向又能骗速度的通用扰动。
从局限到突破:UniAda如何超越现有方法,实现更全面的攻击测试
现有的对抗攻击方法存在三大局限:仅攻击转向控制、测试场景单一、生成的扰动要么是图像相关要么容易被人眼察觉。例如,DeepBillboard只在包含广告牌的特定场景下起效;DeepManeuver只在模拟器内测试,完全没有现实世界的验证;而PhysGAN生成的扰动是贴在广告牌上的图案,非常不自然。更重要的是,这些方法都只针对转向角一个控制量,对速度控制视而不见。
UniAda彻底打破了这些限制。它的核心创新在于:多目标优化 + 自适应权重 + 通用性。团队设计了一个联合优化函数,同时最小化转向和加速两个目标的损失,并通过自适应权重方案(Adaptive Weighting Scheme, AWS)动态调整两个目标的权重,确保两者“齐头并进”而不是偏向一方。
具体来说,UniAda希望找到这样一个通用扰动τ,它施加到几乎每一张输入图像上,都能让模型的输出偏离真实值大于某个阈值。数学上,对于回归问题,通用扰动满足:
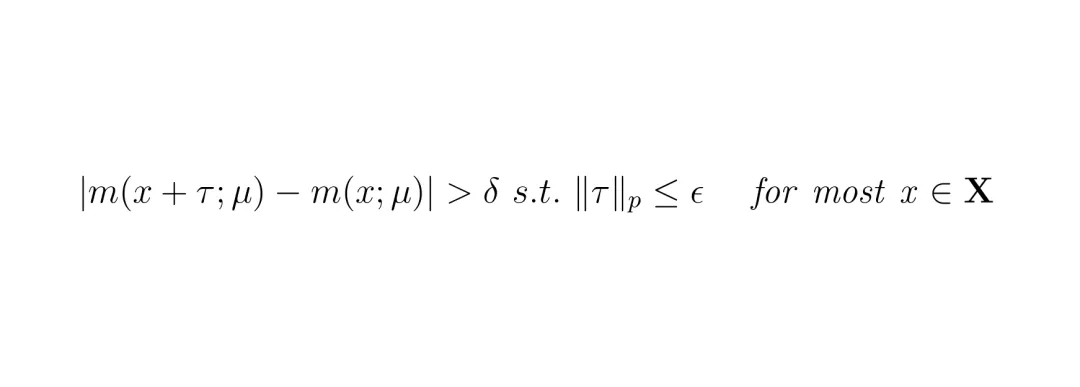 其中δ是预定义的误差阈值,ε是扰动幅度上限(Lp范数约束),保证扰动不被肉眼察觉。
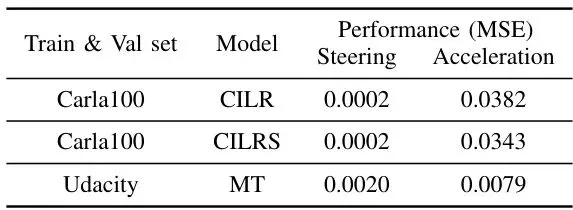
为了验证UniAda的效果,团队选择了14个市区驾驶视频,来自Carla100(模拟)、KITTI、Udacity、Dave(真实世界)四个数据集,攻击三个最先进的端到端自动驾驶模型:CILRS、CILR、MotionTransformer,并与五个基线方法(DeepManeuver、DeepBillboard、Perturbation Attack、FGSM、UniEqual)进行对比。其中UniEqual是UniAda去掉AWS后的等权重版本,用于消融验证。
其中δ是预定义的误差阈值,ε是扰动幅度上限(Lp范数约束),保证扰动不被肉眼察觉。
为了验证UniAda的效果,团队选择了14个市区驾驶视频,来自Carla100(模拟)、KITTI、Udacity、Dave(真实世界)四个数据集,攻击三个最先进的端到端自动驾驶模型:CILRS、CILR、MotionTransformer,并与五个基线方法(DeepManeuver、DeepBillboard、Perturbation Attack、FGSM、UniEqual)进行对比。其中UniEqual是UniAda去掉AWS后的等权重版本,用于消融验证。精准的“平衡术”:自适应权重方案AWS如何在多目标攻击中权衡利弊
多目标优化中最棘手的问题就是如何平衡各个目标。如果给转向和加速分配固定的权重(比如各0.5),可能导致一个目标被过度训练而另一个被忽略。传统的网格搜索又太耗时。UniAda提出的自适应权重方案(Adaptive Weighting Scheme, AWS),灵感来自Chen等人[25]的工作,能够在每次迭代中根据梯度信息动态调整权重,让两个目标始终保持相似的训练速率。
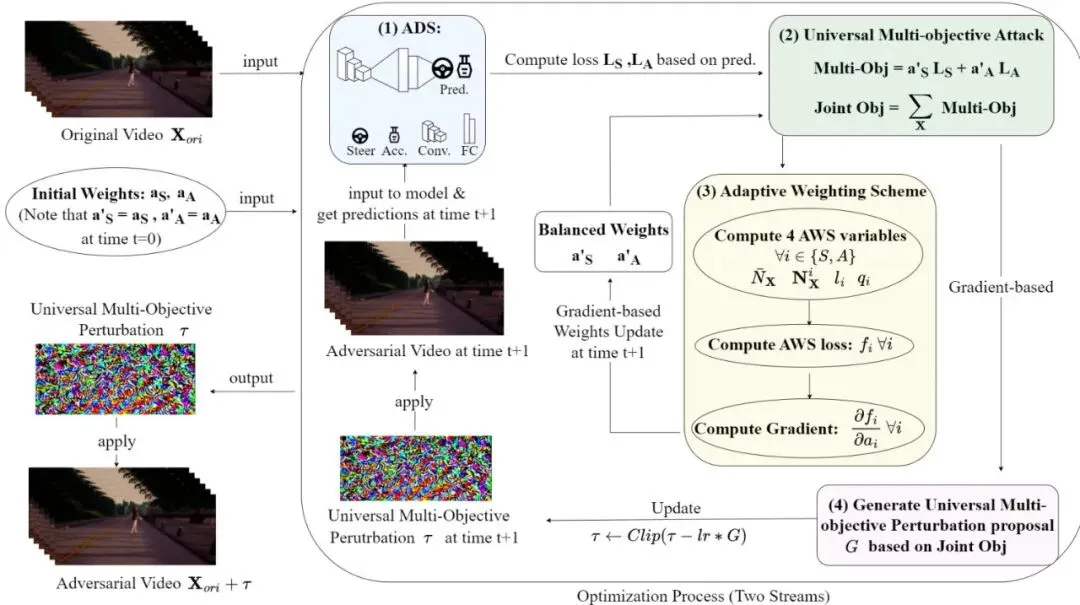
下图展示了UniAda的整体架构,包含通用多目标攻击(绿色部分)和自适应权重方案(黄色部分)两个并行优化流。图3:UniAda概览。攻击方法包含两个主要优化流:通用多目标攻击(绿色)和自适应权重方案(黄色),后者迭代地平衡各目标权重以确保相似的训练速率。
首先定义每个目标i(转向S或加速A)的损失函数,采用指数形式放大预测差异:其中di=±1表示攻击方向(偏大或偏小),β控制尖锐程度,N为视频帧数。然后综合所有目标得到多目标损失:
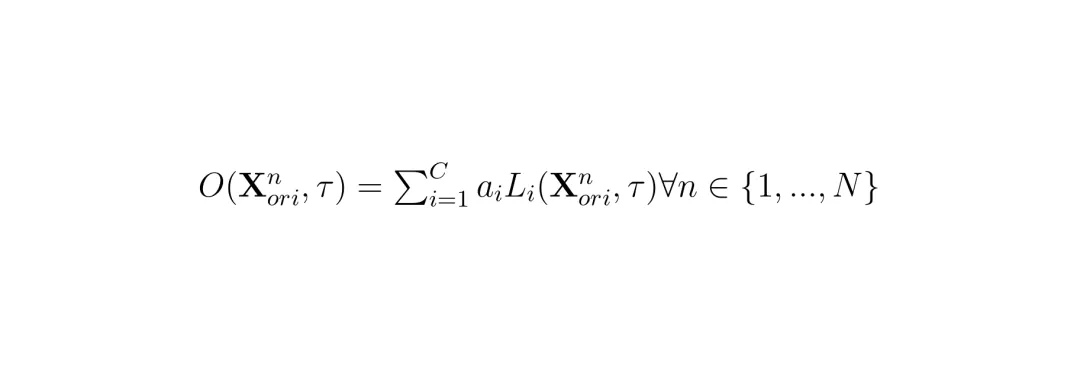 ai是每个目标的权重,由AWS动态更新。接着,UniAda通过迭代梯度下降最小化联合目标函数,生成通用扰动:
ai是每个目标的权重,由AWS动态更新。接着,UniAda通过迭代梯度下降最小化联合目标函数,生成通用扰动:
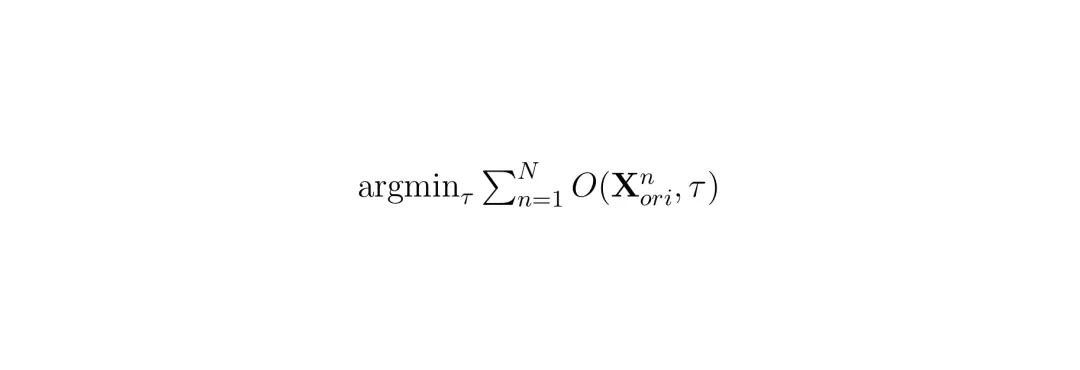 AWS在每个时间步计算四个关键变量:目标特异性范数、目标平均范数、损失比和相对逆训练速率,然后计算AWS损失并更新权重。其核心公式如下:
AWS在每个时间步计算四个关键变量:目标特异性范数、目标平均范数、损失比和相对逆训练速率,然后计算AWS损失并更新权重。其核心公式如下:
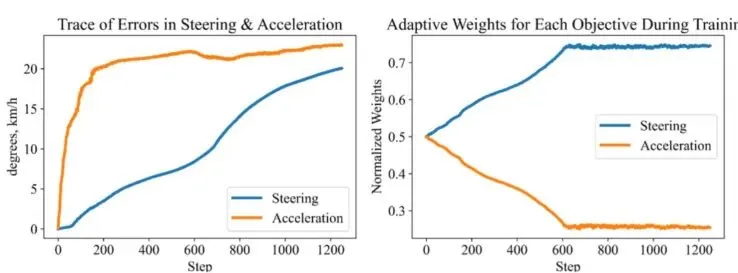
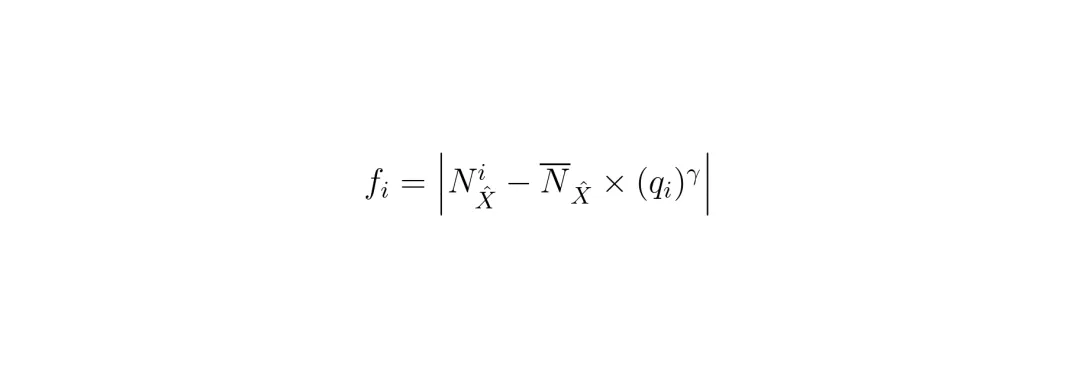 AWS通过梯度下降调整权重,使得训练较慢的目标获得更大权重,训练过快的目标权重被削弱。下图的实证分析清楚展示了AWS的效果:左图显示随着迭代进行,转向和加速的误差同步增加(而不是一个涨一个跌);右图显示两个目标的权重在训练前期剧烈波动,最终稳定在0.5附近,说明AWS成功找到了平衡点。图6:UniAda攻击CILRS“Black Car”视频的均值误差(左)和AWS归一化权重(右)轨迹
团队还通过统计学t检验对比UniAda和其等权重变体UniEqual,结果(表VII和表VIII)显示在大多数情况下UniAda显著优于UniEqual,证明了AWS的贡献。表VII:均值误差的P值结果(CILRS、CILR和MT模型)。加粗表示p≤0.05,正/负/等号表示UniAda优于/劣于/等于UniEqual。表VIII:成功率的P值结果(CILRS、CILR和MT模型)。‘NA’表示UniAda与UniEqual性能相同,无法计算。
AWS通过梯度下降调整权重,使得训练较慢的目标获得更大权重,训练过快的目标权重被削弱。下图的实证分析清楚展示了AWS的效果:左图显示随着迭代进行,转向和加速的误差同步增加(而不是一个涨一个跌);右图显示两个目标的权重在训练前期剧烈波动,最终稳定在0.5附近,说明AWS成功找到了平衡点。图6:UniAda攻击CILRS“Black Car”视频的均值误差(左)和AWS归一化权重(右)轨迹
团队还通过统计学t检验对比UniAda和其等权重变体UniEqual,结果(表VII和表VIII)显示在大多数情况下UniAda显著优于UniEqual,证明了AWS的贡献。表VII:均值误差的P值结果(CILRS、CILR和MT模型)。加粗表示p≤0.05,正/负/等号表示UniAda优于/劣于/等于UniEqual。表VIII:成功率的P值结果(CILRS、CILR和MT模型)。‘NA’表示UniAda与UniEqual性能相同,无法计算。攻防兼备:UniAda在现实与模拟场景中的卓越表现
实验部分才是最令人兴奋的。团队使用两个关键指标评估攻击效果:均值误差(Mean Error, ME)和成功率(Success Rate, SR)。ME计算了所有帧上攻击方向di乘以预测差异的平均值;SR则统计超过给定阈值δi的帧的比例。
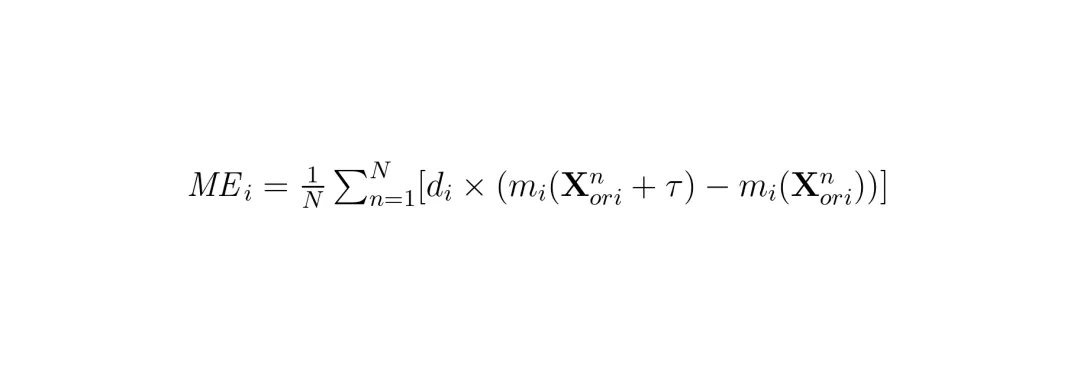 MEi = (1/N) Σ[di × (mi(Xorin+τ) - mi(Xorin))]
MEi = (1/N) Σ[di × (mi(Xorin+τ) - mi(Xorin))]
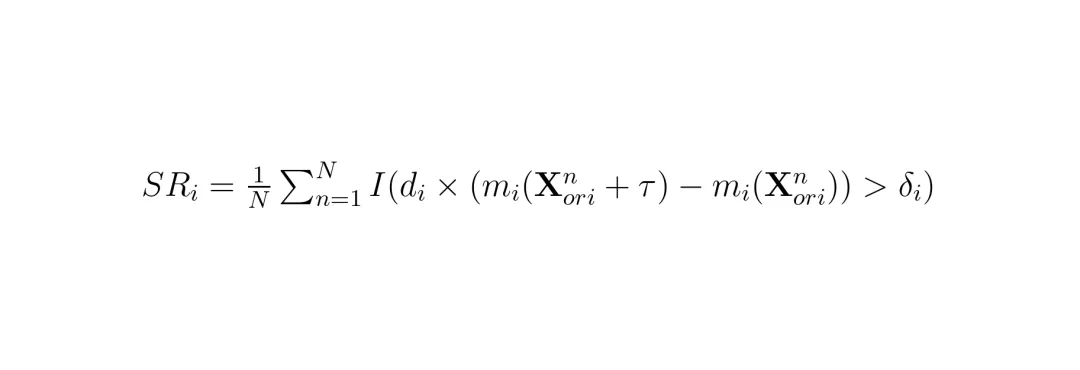 SRi = (1/N) ΣI(di × (mi(Xorin+τ) - mi(Xorin)) > δi)
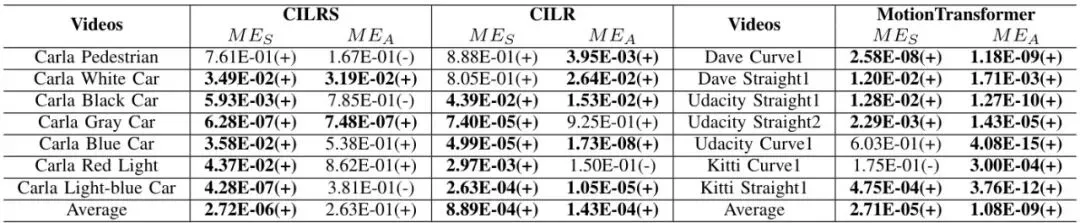
在模拟场景(7个Carla100视频)中,UniAda在CILRS和CILR模型上均取得了最高的转向均值误差:CILRS:29.2°,CILR:25.6°,比单目标SOTA方法DeepManeuver分别高6.6°和8.6°。而加速方面,UniAda也达到了平均22 km/h的误差(Perturbation Attack仅7 km/h)。下表显示了完整的均值误差结果。表IV:模拟视频的均值误差结果(CILRS和CILR模型)
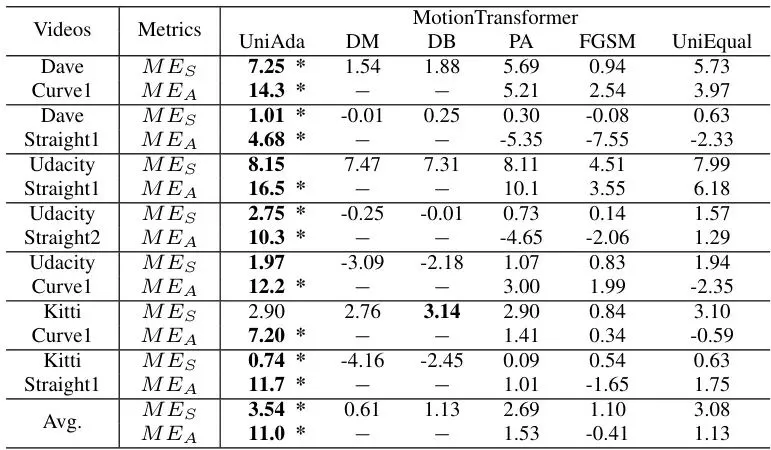
更令人惊喜的是真实世界测试。团队将UniAda部署到MotionTransformer模型上,使用7个真实驾驶视频(包括KITTI、Udacity、Dave)。结果如下表所示,UniAda的转向均值误差平均达到3.54°(虽然数值小,但考虑到真实场景下MotionTransformer本身预测就很精准,3.54°的偏差已经足以让车辆偏离车道),加速误差平均11 km/h。表V:真实世界7个驾驶视频的均值误差结果(MotionTransformer模型)
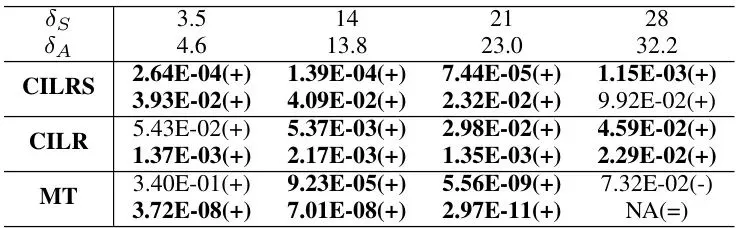
在成功率方面,UniAda更是碾压全场。对于转向阈值δS=3.5°,UniAda平均成功率为96.3%,而DeepManeuver仅41.8%。即使将阈值提高到28°,UniAda仍能保持35%的成功率。下表展示了完整的多阈值成功率对比。表VI:所有测试视频的平均成功率。CILRS和CILR结果基于7个Carla100视频平均,MT结果基于7个真实世界视频平均。
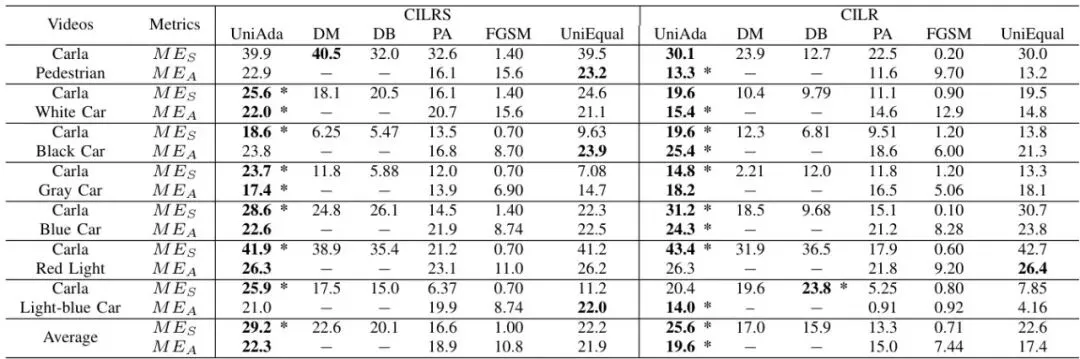
消融研究(表IX)进一步验证了每个组件的必要性。去掉AWS(UniEqual)后,转向和加速的误差均明显下降;去掉多目标优化(只攻击一个目标),另一个目标几乎不受影响——说明多目标优化确实同时影响了两个目标。表IX:CILRS和MT模型上的消融研究,结果平均测试视频
下图直观展示了UniAda生成的对抗图像:第一行为模拟视频,第二行为真实世界视频。人眼几乎看不出与原始图像的区别,但蓝色箭头(对抗输出)与红色箭头(原始输出)方向迥异,底部的加速计数值也发生了显著偏移。图5:UniAda生成的对抗图像。第一/二行分别来自模拟/真实世界视频。蓝色/红色箭头表示对抗/原始预测的转向角。右下角显示加速误差。
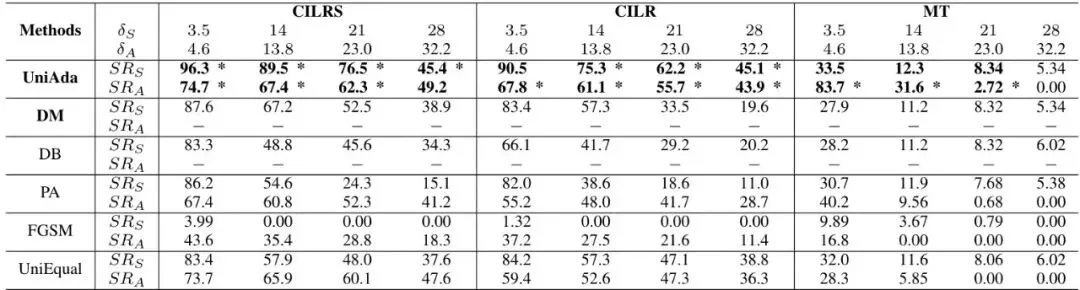
此外,团队还验证了对抗扰动的可迁移性(Fig.7):将UniAda对CILRS生成的扰动直接应用到CILR模型上,仍能产生有效的攻击效果,说明UniAda找到的扰动具有一定的模型无关性。图7:对抗攻击的可迁移性:UniAda、DM(DeepManeuver)、PA(Perturbation Attack)的转向(上)和加速(下)均值误差。注意DM的MEA不可用。
SRi = (1/N) ΣI(di × (mi(Xorin+τ) - mi(Xorin)) > δi)
在模拟场景(7个Carla100视频)中,UniAda在CILRS和CILR模型上均取得了最高的转向均值误差:CILRS:29.2°,CILR:25.6°,比单目标SOTA方法DeepManeuver分别高6.6°和8.6°。而加速方面,UniAda也达到了平均22 km/h的误差(Perturbation Attack仅7 km/h)。下表显示了完整的均值误差结果。表IV:模拟视频的均值误差结果(CILRS和CILR模型)
更令人惊喜的是真实世界测试。团队将UniAda部署到MotionTransformer模型上,使用7个真实驾驶视频(包括KITTI、Udacity、Dave)。结果如下表所示,UniAda的转向均值误差平均达到3.54°(虽然数值小,但考虑到真实场景下MotionTransformer本身预测就很精准,3.54°的偏差已经足以让车辆偏离车道),加速误差平均11 km/h。表V:真实世界7个驾驶视频的均值误差结果(MotionTransformer模型)
在成功率方面,UniAda更是碾压全场。对于转向阈值δS=3.5°,UniAda平均成功率为96.3%,而DeepManeuver仅41.8%。即使将阈值提高到28°,UniAda仍能保持35%的成功率。下表展示了完整的多阈值成功率对比。表VI:所有测试视频的平均成功率。CILRS和CILR结果基于7个Carla100视频平均,MT结果基于7个真实世界视频平均。
消融研究(表IX)进一步验证了每个组件的必要性。去掉AWS(UniEqual)后,转向和加速的误差均明显下降;去掉多目标优化(只攻击一个目标),另一个目标几乎不受影响——说明多目标优化确实同时影响了两个目标。表IX:CILRS和MT模型上的消融研究,结果平均测试视频
下图直观展示了UniAda生成的对抗图像:第一行为模拟视频,第二行为真实世界视频。人眼几乎看不出与原始图像的区别,但蓝色箭头(对抗输出)与红色箭头(原始输出)方向迥异,底部的加速计数值也发生了显著偏移。图5:UniAda生成的对抗图像。第一/二行分别来自模拟/真实世界视频。蓝色/红色箭头表示对抗/原始预测的转向角。右下角显示加速误差。
此外,团队还验证了对抗扰动的可迁移性(Fig.7):将UniAda对CILRS生成的扰动直接应用到CILR模型上,仍能产生有效的攻击效果,说明UniAda找到的扰动具有一定的模型无关性。图7:对抗攻击的可迁移性:UniAda、DM(DeepManeuver)、PA(Perturbation Attack)的转向(上)和加速(下)均值误差。注意DM的MEA不可用。挑战与展望:白盒攻击的局限性与未来对抗防御方向
UniAda无疑在攻击测试领域迈出了一大步,但也必须清醒地看到它的局限性。首先,UniAda属于白盒攻击,即攻击者需要完全掌握目标模型的结构、权重等内部信息。在实际场景中,攻击者很难获得如此细节的信息,因此UniAda更适合作为软件测试和安全性验证的工具,而非真正的恶意攻击手段。
其次,虽然UniAda在多个数据集和模型上表现优异,但所有测试视频均为市区场景,未包含高速公路、夜间、雨雾等更复杂的环境。通用扰动在这些域外场景下是否还能保持效果,有待进一步验证。
另外,论文中设置的扰动幅度ε仅为2或5(像素值0-255),非常微小。如果防御方法采用输入预处理(如JPEG压缩、去噪)或对抗训练,UniAda的攻击效果可能会大打折扣。未来的工作可以探索如何突破这类防御,或者将UniAda扩展到黑盒攻击场景。
从防御角度看,UniAda的提出也为自动驾驶系统的研发者敲响了警钟:在部署之前,必须用类似的多目标、通用性攻击方法对系统进行充分的压力测试。毕竟,现实世界的攻击者远比想象中聪明。
龙迷三问
这篇论文解决什么问题?现有对抗攻击方法对端到端自动驾驶系统的测试存在三个不足:只关注转向控制,忽略速度控制;测试场景单一(多数限定于高速公路或广告牌场景);攻击扰动要么是图像特异的(不能通用),要么容易被人眼识别。UniAda通过生成通用性(图像无关)、人眼不可察觉的对抗扰动,同时诱导转向和加速两个控制量产生错误输出,从而更全面地暴露系统的安全漏洞。
AWS(Adaptive Weighting Scheme)是什么?它是如何工作的?AWS是UniAda中提出的自适应权重方案,用于在多目标优化时动态调整每个目标的权重。它通过计算每个目标在当前迭代中的梯度范数、损失比等变量,生成一个AWS损失,然后对权重进行梯度下降更新。权重较大意味着该目标当前训练不足,需要投入更多资源;权重较小则说明该目标已过度训练,需要减少其影响。AWS确保所有目标以相近的速率被优化,避免某些目标被忽略。
Universal Perturbation(通用扰动)和Image-specific Perturbation(图像特异扰动)有什么区别?图像特异扰动是针对单张图片生成的,只能欺骗该图片对应的模型输出,换一张图片就失效了。通用扰动则是对一个数据分布(例如一段驾驶视频中的所有图像)统一的,施加到该分布中绝大部分图片上都能成功欺骗模型。UniAda的通用扰动是对整个输入视频一次性优化得到的,可以持续诱导视频每一帧的转向和加速预测出错。
如果你还有哪些想要了解的,欢迎在评论区留言或者讨论~龙哥点评
论文创新性分数:★★★★☆
UniAda首次将多目标优化引入端到端自动驾驶系统的通用对抗攻击,同时欺骗转向和加速两个控制量,并提出了自适应权重方案,具有较高的创新性。但单目标攻击已有较多相关工作,多目标优化本身也不是全新概念,因此给四星。实验合理度:★★★★★
实验设计非常扎实。包含了模拟和真实世界两种场景,涵盖三个不同架构的模型(CILRS、CILR、MotionTransformer),与五个基线方法对比,并采用了均值误差和成功率两个指标,还进行了统计显著性检验和消融研究。基线选择合理,实验设置公平,结果可信。学术研究价值:★★★★★
该工作为自动驾驶系统的安全测试提供了全新视角,揭示了仅测试转向控制的不足。方法中的AWS对于多目标优化问题具有通用启发意义,可以迁移到其他需要平衡多个目标的对抗攻击或机器学习任务中。论文实验充分,为后续研究提供了可靠基准。稳定性:★★★☆☆
作为白盒攻击,UniAda在已知模型上表现稳定,但在面对不同模型架构(如Transformer vs CNN)时攻击强度差异较大(CILRS上ME达29°,MotionTransformer上仅3.54°)。此外,扰动对输入预处理(如缩放、压缩)的鲁棒性未测试,稳定性有待进一步验证。适应性以及泛化能力:★★★☆☆
测试场景仅限于市区道路,未涉及高速公路、乡村、夜间等更复杂的驾驶环境。虽然验证了在多个数据集(Carla100、KITTI、Udacity、Dave)上的效果,但这些数据集风格相近。对不同光照、天气条件的泛化能力未测试。给三星是因为目前证据不足以证明其在广泛场景下依然有效。硬件需求及成本:★★★★☆
UniAda的对抗扰动生成是离线进行的,不需要实时计算。论文中训练一个扰动需要250个epoch,每个epoch处理5张图像的mini-batch,计算成本较低,在普通GPU上几分钟即可完成。一旦扰动生成,攻击时只需叠加到图像上,几乎无计算开销。因此硬件需求合理。复现难度:★★★★★
论文已经开源代码(GitHub: https://github.com/UniAdaRepo/UniAda/),并详细列出了所有超参数(表I)和实验细节,数据集均为公开数据集。复现难度很低,给满分。产品化成熟度:★★☆☆☆
UniAda目前仍属于学术研究范畴。要在产品级自动驾驶系统中实际应用,需要先解决几个问题:白盒假设在实际场景中难以满足;对抗扰动的物理可实现性(如通过现实世界的贴纸实现)未验证;防御方法的对抗训练可显著降低其攻击效果。因此,目前更适合作为测试工具而非攻击武器。可能的问题:论文未讨论对抗扰动的物理可实现性(如通过打印海报贴在路边能否生效),且未对防御方法(如对抗训练)的鲁棒性进行测试。另外,仅使用均值误差作为主要指标,对于极端情况(如最大误差)的分析不足。部分表格(如表IV)缺少加速的均值误差结果,略显遗憾。[1] A. Bojarski et al., “End to End Learning for Self-Driving Cars,” 2016.[10] Z. Zhou et al., “DeepBillboard: Systematic Physical-World Testing of Autonomous Driving Systems,” in ICSE, 2020.[15] I. J. Goodfellow et al., “Explaining and Harnessing Adversarial Examples,” in ICLR, 2015.[21] M. Von Tessin, “DeepManeuver: Adversarial Maneuver Generation for Autonomous Driving,” in ASE, 2020.[24] S. Moosavi-Dezfooli et al., “Universal Adversarial Perturbations,” in CVPR, 2017.[25] Z. Chen et al., “GradNorm: Gradient Normalization for Adaptive Loss Balancing in Deep Multitask Networks,” in ICML, 2018.[28] K. Pei et al., “DeepXplore: Automated Whitebox Testing of Deep Learning Systems,” in SOSP, 2017.[36] Y. Li et al., “A Survey of Adversarial Attacks on Autonomous Driving Systems,” IEEE TIV, 2022.*本文仅代表个人理解及观点,不构成任何论文审核或者项目落地推荐意见,具体以相关组织评审结果为准。欢迎就论文内容交流探讨,理性发言哦~ 想了解更多原文细节的小伙伴,可以点击左下角的"阅读原文",查看更多原论文细节哦!

🔥 UniAda的攻击确实有点东西。想更深入了解自动驾驶系统安全、对抗攻击等前沿干货吗?
欢迎加入龙哥读论文粉丝群,
扫描下方二维码或者添加龙哥助手微信号加群:kangjinlonghelper。
一定要备注:研究方向+地点+学校/公司+昵称(如 自动驾驶+上海+清华+龙哥),根据格式备注,可更快被通过且邀请进群。
『龙哥读论文』微信群目前包含:图像处理、大模型及智能体、自动驾驶及机器人、AI医疗及AI金融5个群,自动驾驶群等你来畅聊!



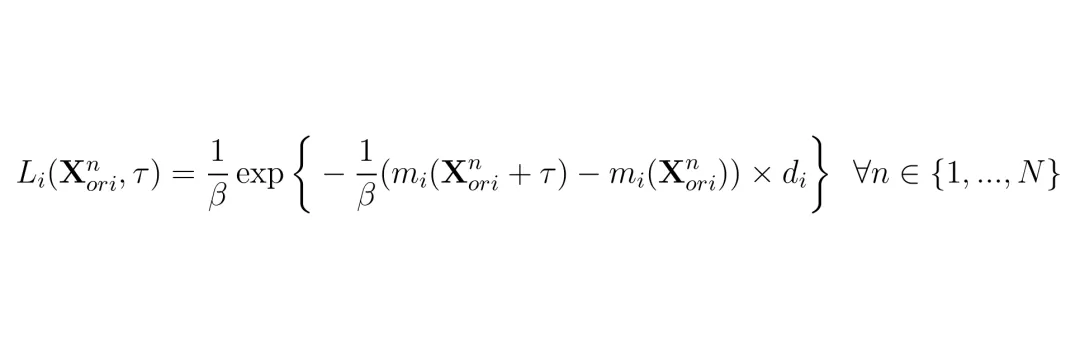


 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
