只要理解自动驾驶,你就看见了 AI 真正的下一层
ChatGPT 火了之后,AI 很容易被压成一个聊天框:你问一句,它答一句。
但 AI 真正的形状,在另一条线上更清楚。
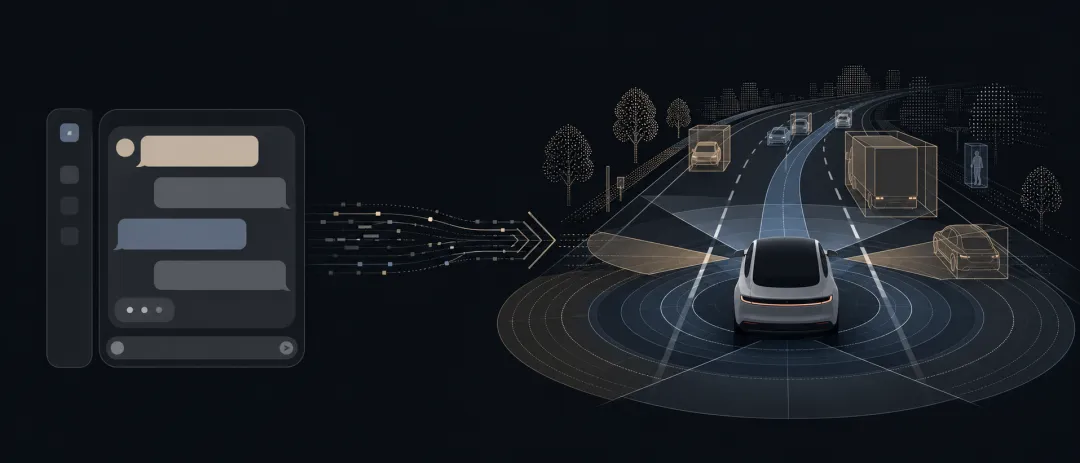
ChatGPT 是会说话的 AI,自动驾驶是会行动的 AI。它们真正相似的地方,不是都贴着 AI 标签,而是都在把现实输入数字化、从数据里学规律、再给出判断或动作。
聊天 AI 让普通人看见了 AI,自动驾驶让我们看见了 AI 的下一层。
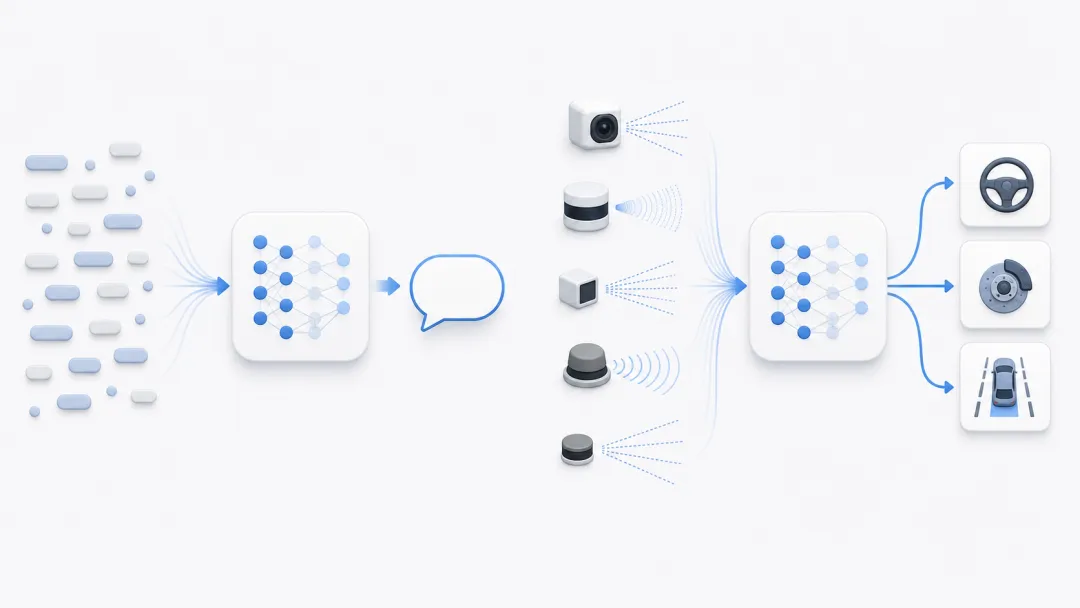
一个在说话,一个在开车
ChatGPT 的回路很短:文字进,文字出。模型把句子切成自己能处理的表示,再根据上下文,预测下一段该怎么说。
自动驾驶面对的不是一句话,而是摄像头、毫米波雷达、车速、车道线、红绿灯、行人。但底层路径是同一种:
现实输入 → 数字化表示 → 模型学到的规律 → 输出(语言 / 动作)
一个在语言世界里预测"接下来怎么说",一个在道路世界里判断"接下来怎么开"。两边在做同一件事——把经验里的规律,压进一个能被持续训练的模型里。
自动驾驶的三种形态,也是 AI 的三种形态
把自动驾驶的演进粗略拆开,会看到三类典型做法。
模块化路线。 像一支分工清楚的工程团队:感知识别路面与行人,预测推断别人会怎么动,规划决定自己怎么走,控制把决策交给方向盘和刹车。优点是清楚、稳定、可解释。华为这类量产智能驾驶方案,更准确的说法是"模块化、工程化 AI 系统",不是一堆简单规则,也不是单一算法堆起来的产物。
视觉端到端。 不再把驾驶切成很多环节,而是让模型从摄像头画面直接学习驾驶动作,Tesla FSD v12、Wayve 是常被讨论的代表。架构变简单,模型能从海量真实数据里抓到一些人工规则写不清的细节。代价也明显:依赖数据质量、更像黑箱,极端天气、逆光、遮挡、少见路况都还在持续考验它,远谈不上把所有边界情况都解决掉。
VLA:Vision-Language-Action。 视觉、语言、动作。它想再往前一步——临时路牌写着"前方施工,请靠右行驶",普通视觉模型只看到牌子和锥桶,VLA 试图把视觉信息和语言语义接起来,再变成动作。这并不等于车已经像人一样理解世界,更准确的描述是:用多模态模型,把"看见什么、这是什么意思、该怎么做"放进同一个学习框架里。是新尝试,不是已成立的能力。
这件事跟普通行业有什么关系
聊天 AI 让我们第一次大规模感受到机器可以处理语言;自动驾驶让我们看见机器也能处理物理世界里的连续判断。
工业视觉检测在同一条线上。过去质检靠人眼、靠师傅经验、靠一遍遍复检;现在摄像头加模型,可以持续识别划痕、缺口、尺寸异常、装配问题。它不会上热搜,但在工厂里每天都在把重复判断,变成稳定的系统输出。
值得回头问自己的问题,不是"AI 能不能帮我写稿",而是:自己行业里那些每天反复发生、依赖经验的判断,有没有数据、有反馈、有可验证的结果?如果有,它就有机会被训练成一个系统。
销售线索筛选、设备故障预测、产品瑕疵识别、客服工单分流、供应链风险预警——背后都是同一种能力:从数据里学规律,再给出判断。
当模型不只回答问题,而是开始参与行动,产业层面真正的变化才刚开始。
和我们相关的
你所在的行业里,哪一类每天反复做的判断,最有可能被训练成一个系统?欢迎在评论区写下来。