自动驾驶和机器人的视觉感知模式一直被视角鲁棒性问题困扰,遇到未见过的相机安装位置模型就无法适配,需要重新采集数据做补充训练。这样不仅成本高、模型迭代周期长,而且有些项目不具备数据采集的条件,直接影响项目实施,亟待解决模型的视角鲁棒性问题,提升在不同视角下的泛化性。根据平时看论文积攒的一些思路在AI的协助下做了一些总结,希望对遇到类似问题的朋友提供一些思路,欢迎留言区探讨。
一、问题的本质:3D-2D投影的「阿喀琉斯之踵」
视觉为中心的自动驾驶与机器人感知,核心任务是从2D图像中推断3D世界信息。这一过程的数学基础是3D-2D投影——相机内外参决定了三维空间点如何映射到二维像素平面。也正因如此,模型天生对「相机配置」极度敏感。
密歇根大学与UC Berkeley团队在ICLR 2025的工作UniDrive中给出了直观的量化结果:当BEVFusion-C模型训练于6×80°相机配置、测试于6×60°配置时,检测精度暴跌至1.8%;即便是相机高度从1.6m变化到1.8m或2.5m,传统模型也会出现超过10%的性能滑坡。NVIDIA在ICCV 2023的研究同样发现,BEV分割模型在相机俯仰角仅减少10°时,IoU就会下降17%。
这背后的根本矛盾在于:现有模型在训练时隐式地「记住」了特定相机的几何映射关系,而非真正学会3D空间的物理规律。当相机配置改变,这种「死记硬背」立刻失效。
二、路线一:堆数据——从朴素采集到智能合成
2.1 最朴素的思路:多配置数据采集
最直接的方案是「用数据硬刚」——收集不同高度、不同俯仰角、不同焦距的相机数据,让模型在训练阶段见多识广。这种方法对模型架构零改动,但代价极高:需要为每一种目标车型重新采集、标注数据,周期长、成本高,且无法覆盖所有可能的配置组合。
2.2 新视角合成(NVS):用算法「造」数据
既然真实数据采集昂贵,学术界自然转向新视角合成(Novel View Synthesis, NVS)——利用已有视角的图像和几何信息,生成新相机配置下的合成图像,从而低成本扩充训练数据。
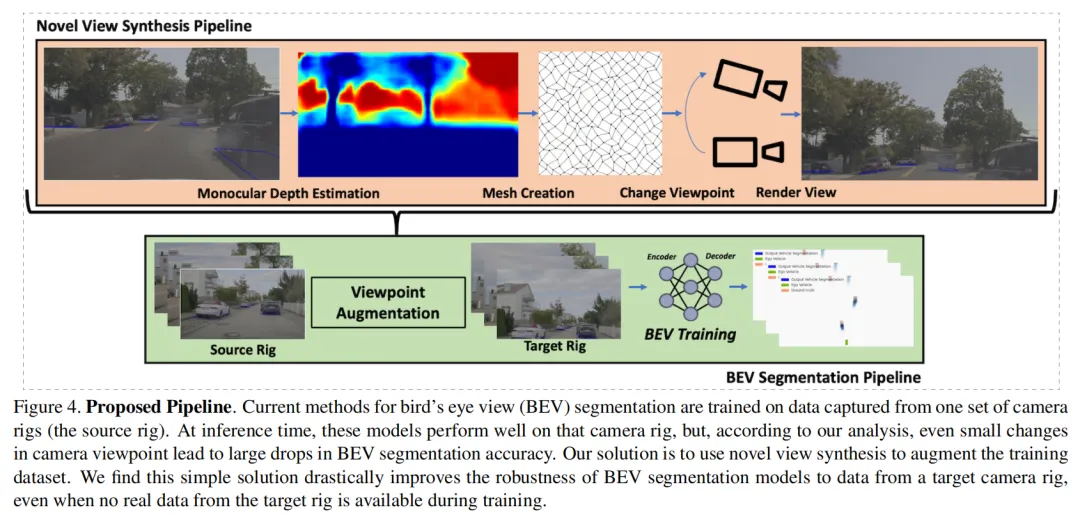
2.2.1 NVIDIA WorldSheet方案:单目深度→Mesh→视角变换→渲染
NVIDIA的WorldSheet方案(ICCV 2023)是这一方向的早期代表性工作。其核心NVS流程可分为四步,全部在相机坐标系内完成:
Step 1:单目深度估计。基于WorldSheet方法,用一个ResNet-50网络从输入图像 预测每个像素的深度,以及每个顶点的偏移量。WorldSheet的目标是将一个的平面网格根据预测深度和顶点偏移「warp」到3D场景中,构建场景Mesh,其中 为mesh面片。
Step 2:LiDAR监督深度优化。与纯视觉NVS不同,该方法利用自动驾驶车辆采集时同步记录的LiDAR数据,将LiDAR点云渲染为稀疏深度图 作为真值监督。同时采用两种自动掩码策略:用预训练的天空分割网络屏蔽天空区域(深度设为无穷远),用MaskRCNN屏蔽近距离车辆(因LiDAR安装位置高于相机,通常看不到近处车辆底部)。深度监督包含两部分损失:
- 直接深度损失:预测深度与LiDAR真值的L1误差;
- 渲染深度损失:将相邻帧 的预测深度投影到当前帧 的视角后,与当前帧LiDAR真值比较,取像素级最小损失(Minimal Loss),以处理动态场景中的遮挡问题。
Step 3:Mesh构建与纹理映射。利用预测的深度 和顶点偏移 ,将2D图像平面上的网格变形为3D Mesh。然后通过可微分纹理采样器,将原始图像的RGB像素强度「splat」到Mesh的UV纹理图上,形成带纹理的3D场景表示。
Step 4:目标视角渲染。给定源视角图像 和目标相机位姿 ,将Step 3构建的Mesh从源视角投影到目标视角,渲染出目标视角图像 。由于自动驾驶场景使用120°鱼眼相机采集,渲染后需将图像rectify到50°视角,因此视野外的缺失区域无需inpainting。
整个流程的坐标系转换链条是:源相机坐标系(通过深度估计)→ 3D Mesh(世界坐标系隐含)→ 目标相机坐标系(通过目标外参投影渲染)。本质上是用单目深度将2D图像「提升」到3D空间,再在新的相机外参下「投影」回2D。
实验表明,该方法能恢复平均**14.7%**的IoU损失;在俯仰角-10°的严苛场景下,CVT模型的IoU从0.014(直接部署)恢复至0.165(接近无视角变化的0.170)。
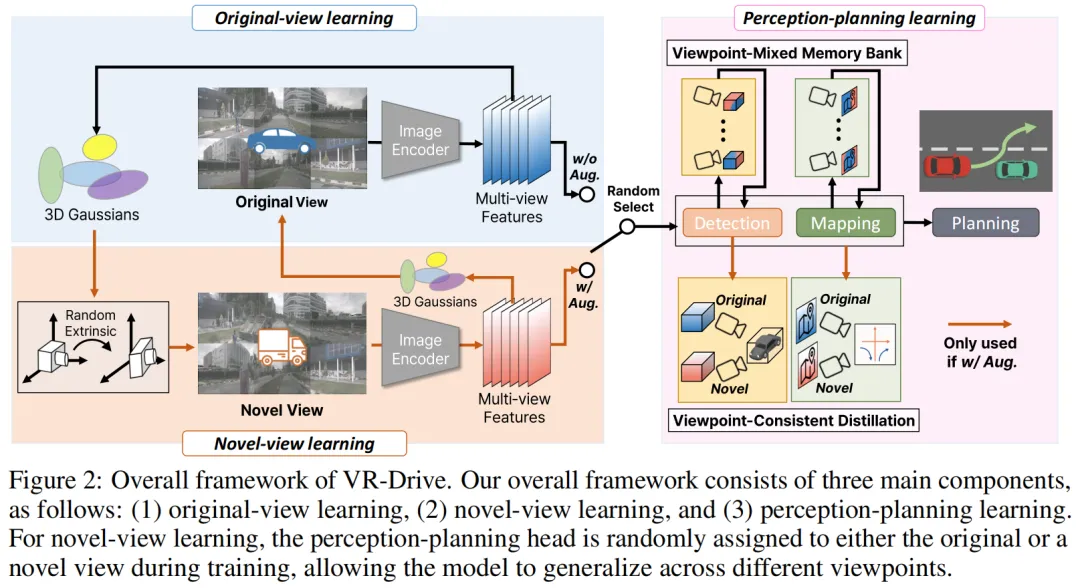
2.2.2 VR-Drive:前馈式3D高斯泼溅的在线视角增强
VR-Drive(NeurIPS 2025)则将NVS与端到端自动驾驶深度融合,其核心创新是前馈式3D高斯泼溅(feed-forward 3DGS),无需针对每个场景单独优化。整个新视角生成流程如下:
Step 1:深度估计与3D位置推断。将深度估计作为端到端自动驾驶的辅助任务,从多视角图像中提取特征后,预测深度图 。每个高斯基元的位置 直接从深度图推断——对于图像中的每个像素,其3D位置由该像素的深度值和相机内参共同决定,即从图像平面坐标 通过内参 反投影到相机坐标系下的3D点 。
Step 2:高斯基元参数预测。给定深度图 和图像特征图 ,通过一个由多层卷积组成的高斯网络(Gaussian Network),像素级地预测每个高斯基元的剩余参数:
协方差矩阵 由 和 组合构造。这种像素级前馈预测取代了传统3DGS中基于Structure-from-Motion的逐场景优化,使得在线推理成为可能。
Step 3:随机外参采样与新视角渲染。在训练时,从预设的扰动范围内随机采样相机外参(extrinsics)——包括高度、俯仰角、纵向深度等变化。利用Step 1-2生成的高斯基元集合 ,通过3D高斯泼溅的可微分光栅化器,从新的相机外参视角渲染出多视角特征图 。渲染过程本质上是将3D高斯基元从相机坐标系(由深度和内参定义)变换到新的相机坐标系(由随机采样外参定义),再投影到图像平面。
Step 4:循环重建与知识蒸馏。为了增强鲁棒性,VR-Drive引入循环重建损失:从原始视角生成高斯基元→渲染新视角→再从新视角重建高斯基元→渲染回原始视角,强制双向一致性。同时,通过Viewpoint-Consistent Distillation,利用原始视角中可靠的实例特征(通过3D anchor点采样)指导新视角的特征学习,确保规划相关的表示在视角变化下保持一致。
2.3 小结
「堆数据」路线的本质是通过扩大训练分布来覆盖测试分布。NVIDIA WorldSheet通过「深度估计→Mesh构建→视角变换→渲染」的传统图形学pipeline实现离线数据扩充;VR-Drive则通过「前馈3DGS」将这一过程端到端化,支持在线训练时增强。两者的上限取决于深度/几何估计的准确性,而NVS技术正在将这一上限从「真实世界采集」推向「算法无限生成」。
三、路线二:统一视角——虚拟相机的「中间件」哲学
与其让模型适应无数种相机,不如把所有相机「翻译」成同一种标准语言。这就是统一视角路线的核心思想:在训练和推理时,都先把原始图像转换到一个固定的「虚拟相机」空间,模型只学习和推理这个标准化空间,最后再映射回实际坐标系。
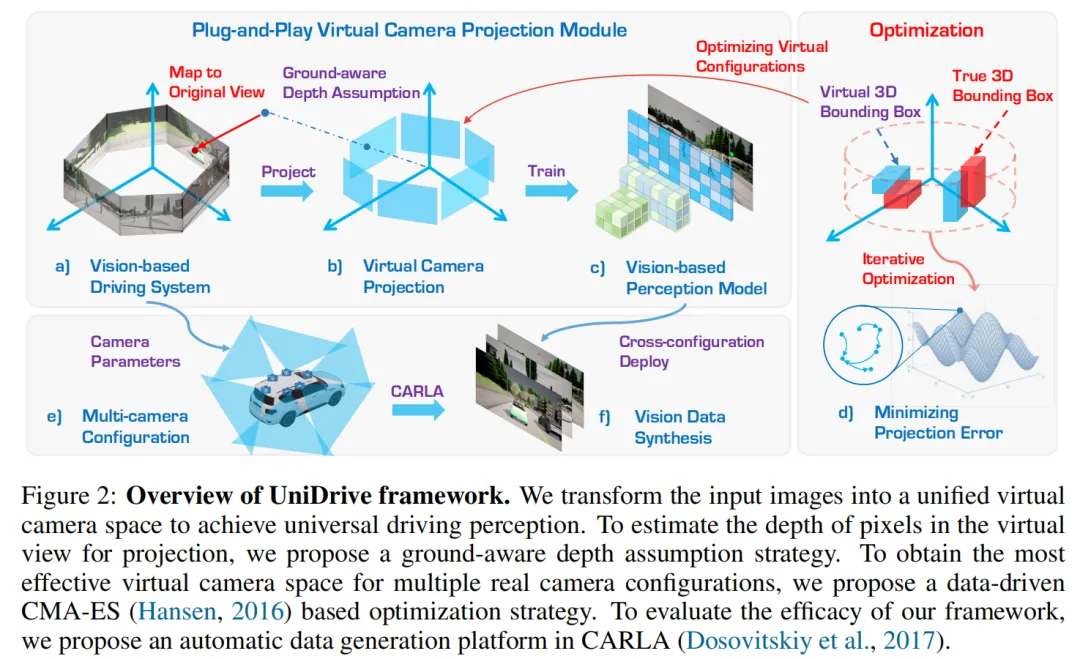
3.1 UniDrive:地平面感知的虚拟投影
UniDrive(ICLR 2025)是这一方向的奠基性工作。其训练时虚拟相机图像的生成过程涉及三个关键环节:
Step 1:部署统一虚拟相机空间。UniDrive定义了一组统一虚拟相机(Unified Virtual Cameras),用内参矩阵 和外参矩阵 描述。这组虚拟相机构成一个标准化的坐标系,作为模型训练和推理的「中间层」——无论输入来自何种真实相机配置,都先转换到这个统一空间,模型只「认识」虚拟相机。
Step 2:地平面感知深度估计(Ground-Aware Depth Assumption)。将原始图像投影到虚拟视角的核心难点在于:需要知道原始图像中每个像素在虚拟视角下的深度,才能正确重投影。UniDrive提出地平面假设来解决这一问题:假设地面是一个平面(在自动驾驶场景中这是合理假设),利用原始相机的外参(特别是高度和俯仰角)估计每个像素到地面的距离,从而推断其在3D空间中的位置。具体而言,对于原始图像中的像素,结合相机高度 和俯仰角 ,计算该像素射线与地平面的交点,得到该点的3D坐标(在原始相机坐标系下)。
Step 3:虚拟视角图像生成。得到原始图像中像素的3D位置后,利用虚拟相机的内参 和外参 ,将这些3D点投影到虚拟相机的图像平面,生成虚拟视角图像。坐标系转换链条为:原始相机坐标系(通过地平面假设获得3D点)→ 世界坐标系(中间过渡)→ 虚拟相机坐标系(通过虚拟外参投影)。这一过程对每张输入图像独立进行,无需多视图几何或深度传感器。
Step 4:虚拟配置优化。为了找到最优的虚拟相机配置(包括虚拟相机的高度、俯仰角、焦距等),UniDrive提出了一种数据驱动的优化策略,通过CMA-ES(协方差矩阵自适应进化策略)最小化原始相机与虚拟相机之间的期望投影误差。也就是说,虚拟相机的参数不是人为设定的,而是通过优化算法自动搜索得到的,使得来自不同原始相机的图像在投影到虚拟空间后失真最小。
实验结果极具说服力:在CARLA模拟器中,当相机高度从1.6m变化到1.8m时,BEVFusion-C性能下降超过10%,而UniDrive仅下降3.0%;面对最大的内参差异(6×80°→6×60°),UniDrive的性能下降最多也只有9.8%,远优于基线模型的近乎失效。更重要的是,UniDrive的虚拟投影模块可以作为即插即用组件,直接嵌入到现有3D感知方法中。
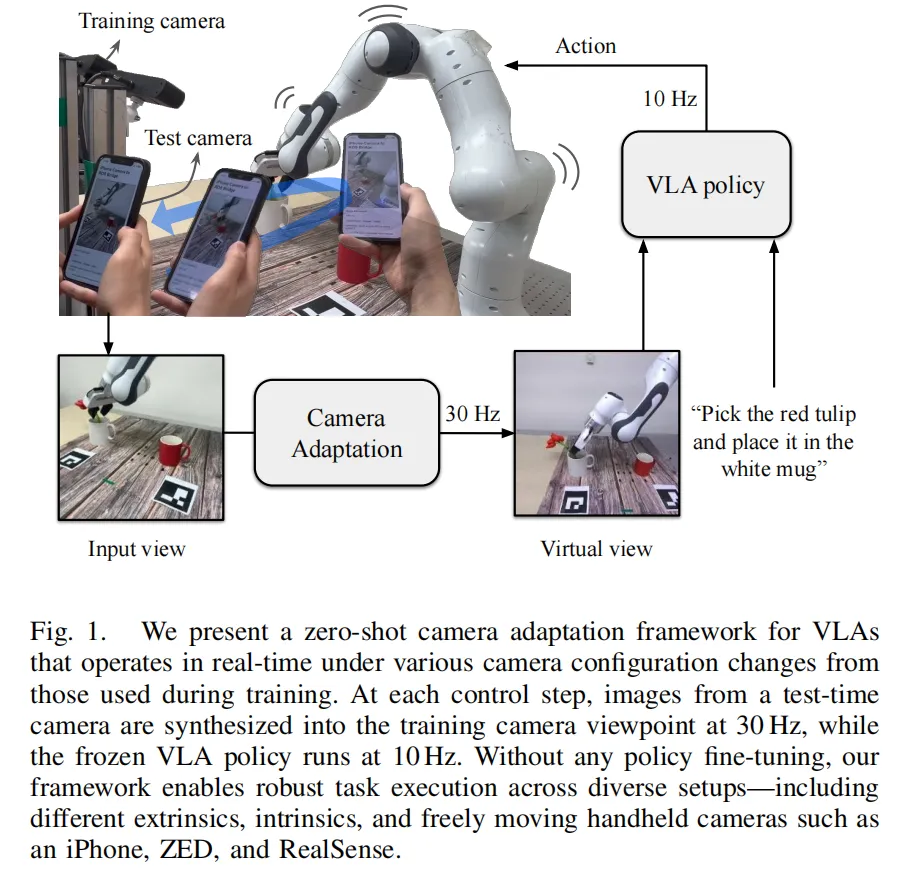
3.2 AnyCamVLA:测试时实时「校正」视角
如果说UniDrive是在训练时统一视角,AnyCamVLA(2026)则把统一视角做到了测试时。其测试时视角转换的详细过程如下:
Step 1:问题定义。设训练时相机参数为 (包含内外参),测试时相机参数为 。两者均已知且表达在同一坐标系下(通过标定获得)。目标是:在测试时,将当前相机捕获的图像 转换为「看起来像是从训练相机 拍摄的」合成图像 ,再输入冻结的VLA策略。
Step 2:LVSM前馈视角合成。AnyCamVLA使用**LVSM(Large View Synthesis Model)**作为相机适应模块 。LVSM是一个decoder-only的前馈新视角合成模型,其输入包括:
LVSM在单次前向传播中输出合成图像 。与NeRF等需要逐场景优化的方法不同,LVSM的推理延迟仅为36.55ms(在RTX 4090上合成2个新视角,256×256分辨率,BF16混合精度),对应约27 FPS,足以满足实时机器人控制需求(VLA通常运行在10Hz)。
Step 3:坐标系转换与相机参数处理。LVSM的核心能力在于同时处理外参变化(相机位姿:高度、俯仰角、偏航角、平移)和内参变化(焦距、主点、畸变)。在AnyCamVLA的框架中,测试相机和训练相机的参数被表达在同一世界坐标系下,LVSM学习的是从「源相机配置」到「目标相机配置」的几何映射关系,而非简单的2D图像warping。这使得它能够处理大范围的视角偏移(实验验证可达15cm平移和60°旋转)。
Step 4:冻结策略推理。合成图像 被直接送入预训练且冻结的VLA策略 ,生成动作 。由于策略参数完全不变,不存在灾难性遗忘风险,且无需任何额外的机器人演示数据或微调。
在真实世界实验中,AnyCamVLA甚至支持手持相机(如iPhone、ZED、RealSense)自由移动的场景——通过ArUco标记实时估计手持相机的位姿,持续进行视角合成,底层策略完全感知不到相机的动态变化。
3.3 小结
统一视角路线的优雅之处在于解耦:模型不再直接面对千变万化的真实相机,而是面对一个固定的虚拟相机。UniDrive通过「地平面假设+投影优化」在训练时建立虚拟空间;AnyCamVLA通过「LVSM前馈合成」在测试时实时校正视角。两者的挑战在于:UniDrive的投影对远离地面的高处物体(如交通标志、桥梁)精度受限;AnyCamVLA则依赖视角合成质量,在源视角与目标视角差异过大或存在大面积遮挡时可能失效。
四、路线三:显式编码相机参数——把几何先验写进模型DNA
把相机内外参作为几何空间先验,直接注入模型特征空间,让模型学会「利用」相机参数而非「过拟合」到某一组参数。
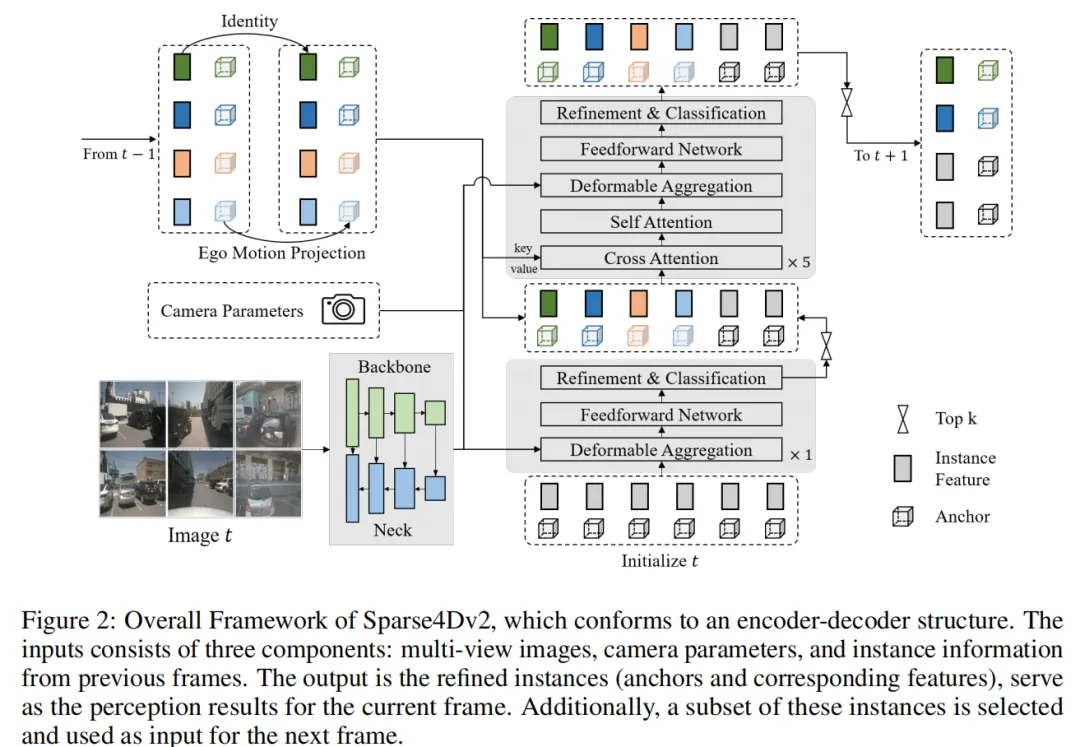
4.1 Sparse4D v2:相机参数显式编码
在Sparse4D v1中,相机参数的信息是隐式嵌入到Deformable Aggregation全连接层的权重中的。这带来两个问题:一是当交换两幅输入图像的顺序时,权重顺序不会相应变化,影响感知性能;二是当对相机参数进行大规模数据增强时,这种隐式表示的收敛速度会显著受影响。
Sparse4D v2的改进非常直接:将相机内外参显式输入网络,把「输出空间到图像坐标空间的变换矩阵」映射为一个高维特征向量(camera embed),然后将其加到实例特征上,再用融合后的特征计算各视图的权重。这种显式编码使得模型对相机参数的变化有了结构化的感知能力,而非死记硬背。
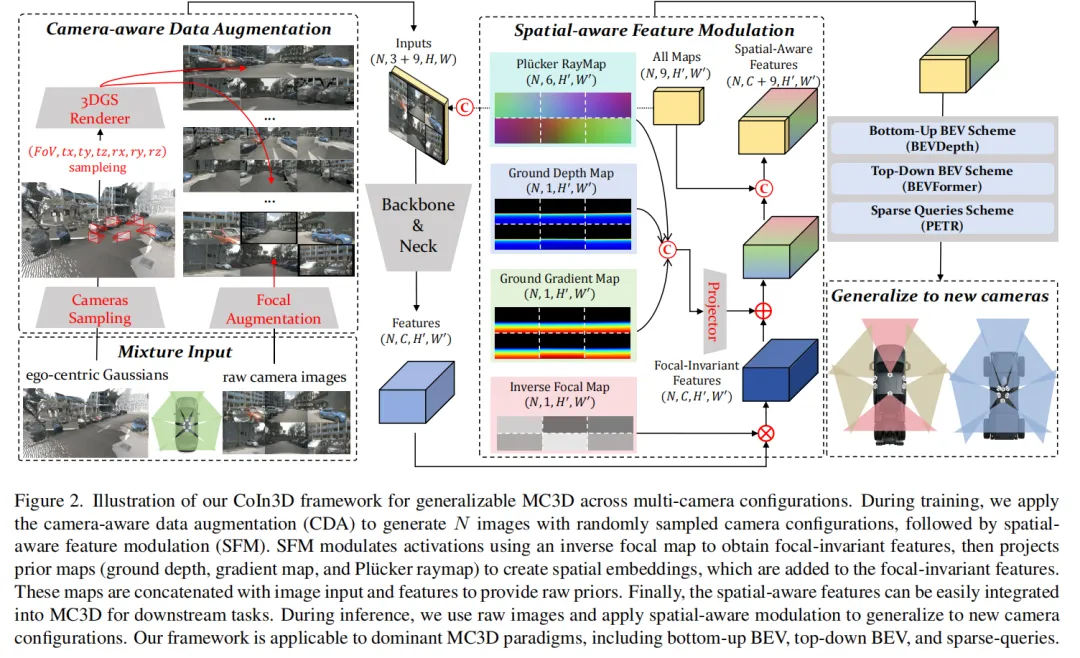
4.2 CoIn3D:空间感知特征调制(训练与推理双阶段方案)
CoIn3D(CVPR 2026)进一步将显式编码相机参数的思想系统化,并提出了训练时数据增强 + 推理时特征调制的双阶段方案 。
训练阶段:Camera-Aware Data Augmentation (CDA) + Spatial-Aware Feature Modulation (SFM)
Step 1:训练无关的3DGS构建(CDA核心)。CoIn3D的CDA是一种无需训练的动态新视角图像合成方案,其pipeline分为四步:
- 利用4D标注将LiDAR序列分解为背景和动态物体;
- 通过TSDF积分重建背景mesh和物体mesh,并修复为封闭表面;
- 根据标定参数和标注将背景与物体mesh组合,渲染出每个相机的精确深度图(mesh-rendered depth具有度量精确性和环视一致性);
- 构建辅助资产(物体纹理点模型和相机盲区纹理),通过序列内图像的深度匹配进行纹理检索;
- 将RGB-D图像投影到自车空间得到纹理点云,附加纹理资产后,构建自车-centric高斯(ego-centric Gaussians)。每个高斯的协方差矩阵设为 (无旋转、固定半径),不透明度为1,颜色为原始RGB。这种表示本质上是一种点渲染方案,但借用了3DGS的快速光栅化,渲染速度可达450 fps 。
Step 2:随机配置采样与图像合成。在训练时,从预设范围内随机采样新的相机配置(内参、外参、阵列布局),利用Step 1构建的自车-centric高斯从新视角渲染出增强图像 。这使得模型在训练阶段就能「见到」各种虚拟相机配置下的场景外观。
Step 3:空间感知特征调制(SFM)。将增强后的图像输入backbone和neck提取特征 后,CoIn3D通过SFM嵌入四种空间先验:
- 逆焦距图(Inverse Focal Map):用焦距平方的倒数 对特征进行像素级归一化,消除不同焦距导致的物体像素尺寸歧义。归一化后的特征为 ;
- 地面深度图(Ground Depth Map):编码相机高度信息;
- 地面梯度图(Ground Gradient Map):编码俯仰角信息;
- Plücker光线图(Plücker Ray Map):提供相机配置的全局表示。
这三种先验图与逆焦距调制后的特征拼接,形成空间感知特征,再输入下游的MC3D检测范式(BEVDepth、BEVFormer或PETR)。
推理阶段:仅SFM,无CDA
在推理时,CoIn3D不执行CDA(因为测试时无法预先构建3D高斯资产),而是直接输入原始图像,仅应用SFM进行特征调制。由于SFM在训练时已经让模型学会了「焦距归一化 + 几何先验嵌入」的跨配置表示,因此推理时只需将测试相机的实际配置参数(焦距、高度、俯仰角等)输入SFM,即可生成与训练时兼容的空间感知特征,实现向新配置的泛化 。
CoIn3D的通用性很强,实验覆盖了nuScenes、Waymo、Lyft三大数据集,且可即插即用到BEVDepth、BEVFormer、PETR三种主流范式 。
4.3 小结
显式编码相机参数的本质,是把模型的「隐式过拟合」转化为「显式推理」。当模型能够直接读取焦距、高度、俯仰角等几何信息时,它就不再需要「猜测」当前相机的特性,而是可以基于物理规律进行跨视角泛化。这条路线的关键在于:如何设计既紧凑又充分的几何表示(如Plücker坐标、地面梯度),以及如何将这些表示与图像特征有效融合(相加、拼接、注意力调制)。
五、路线四:引入显式3D表征——用深度图搭建「伪LiDAR」桥梁
如果说「显式编码相机参数」是在特征层面注入几何意识,那么「引入显式3D表征」则是在数据层面直接给模型提供3D结构信息——最常见的方式就是深度图。深度图将2D像素与3D空间建立显式对应,让模型在推理时拥有「伪LiDAR」的3D感知能力。
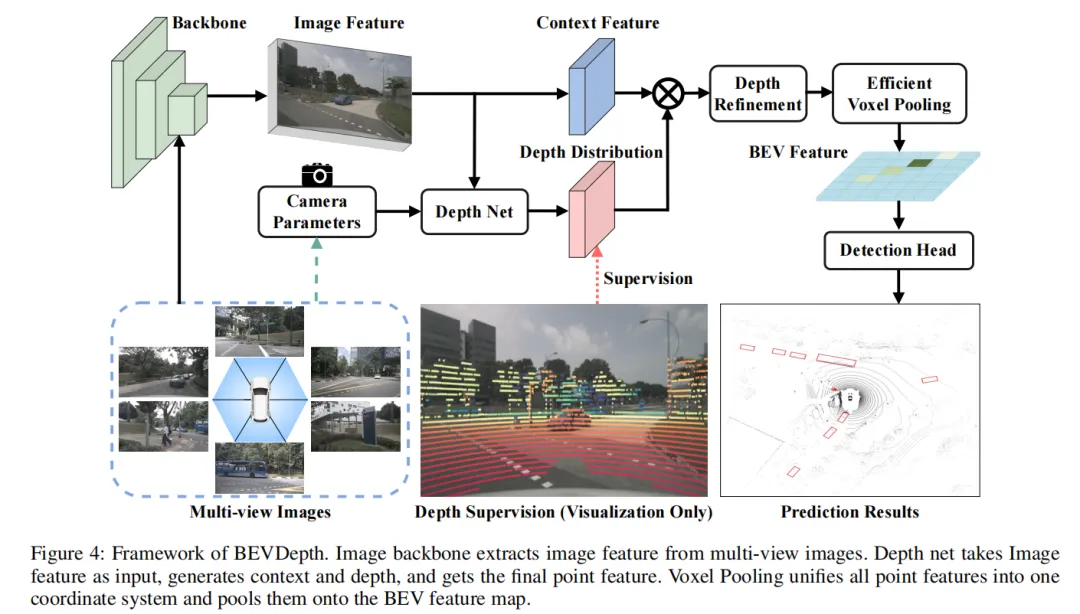
5.1 BEVDepth:相机感知的深度监督(训练与推理双阶段方案)
BEVDepth(2022)是引入显式3D表征的开创性工作。其核心洞见是:现有BEV检测方法(如LSS)的深度估计是隐式学习的,仅靠最终的检测损失监督,导致深度质量极差——即使检测mAP达到30,深度估计的AbsRel误差仍高达3.03 。BEVDepth通过训练时LiDAR深度监督 + 推理时纯视觉深度预测的范式解决了这一问题。
训练阶段:LiDAR深度真值生成 + 显式深度监督 + 相机感知DepthNet
Step 1:LiDAR深度真值生成。BEVDepth利用同步采集的LiDAR点云 生成相机视图下的密集深度真值 。具体而言,对于第 个相机,利用LiDAR到相机的旋转矩阵 、平移向量 和相机内参 ,将LiDAR点投影到相机视图 :
进一步转换为2.5D图像坐标 。若某点云投影未落入第 个视图,则直接丢弃。随后通过min pooling和one-hot编码(联合记为 )将稀疏投影点压缩为与预测深度同形状的密集真值 。
Step 2:相机感知的深度预测(DepthNet)。BEVDepth的DepthNet不仅接收图像特征,还显式编码相机内外参。具体做法是将内参通过MLP映射到高维特征(如128维),外参( 和 )同样通过MLP编码,两者拼接后形成相机标定特征,再通过SENet(Squeeze-and-Excitation)模块对图像特征进行通道级加权 。这使得深度预测能够感知当前相机的几何特性。
Step 3:深度修正子网络(Depth Refinement Module)。由于LiDAR与相机之间存在标定误差,以及在线外参扰动,直接投影的LiDAR深度真值可能与图像像素不完全对齐。BEVDepth不追求精确的标定修正,而是通过扩大感受野来补偿对齐误差,使得偏移的深度真值仍能关注到正确的图像特征位置 。
Step 4:深度损失与端到端训练。深度预测 通过Binary Cross Entropy(或Focal Loss)与 比较。同时,修正后的深度与图像特征结合,通过Voxel Pooling统一到BEV空间,再由BEV编码器和检测头进行端到端训练。
推理阶段:纯视觉输入,无需LiDAR
在推理时,BEVDepth仅接收多视角图像作为输入,不再需要任何LiDAR数据 。流程为:
- DepthNet利用训练时学到的相机感知能力,从图像特征预测深度分布;
- 结合相机内外参,将图像特征沿深度方向「提升」到3D视锥空间,生成伪点云特征;
- 通过Efficient Voxel Pooling(GPU并行实现,比LSS的cumsum trick快80倍)将3D点特征池化到BEV平面 ;
这一「训练时LiDAR当老师,推理时纯视觉上岗」的范式,使得BEVDepth在nuScenes测试集NDS达到60.0%,首次将纯相机方案与LiDAR方案的性能差距缩小到10%以内 。
5.2 3D Foundation Model Priors:DA3驱动的无增强视角鲁棒性
千叶大学与SUZUCA.AI团队在2026年的工作**《Towards Viewpoint-Robust End-to-End Autonomous Driving with 3D Foundation Model Priors》提出了一种无需数据增强、无需修改相机配置、无需微调策略**的视角鲁棒性方案,其核心是将预训练3D基础模型的几何先验知识注入端到端自动驾驶模型 。
该工作选择**DA3(Depth Anything 3)**作为3D先验来源——一个以DINOv2为视觉骨干的3D基础模型,支持任意数量输入视图且无需已知相机位姿,在相机位姿估计和几何重建上均达到SOTA,超越了VGGT等前代方法 。
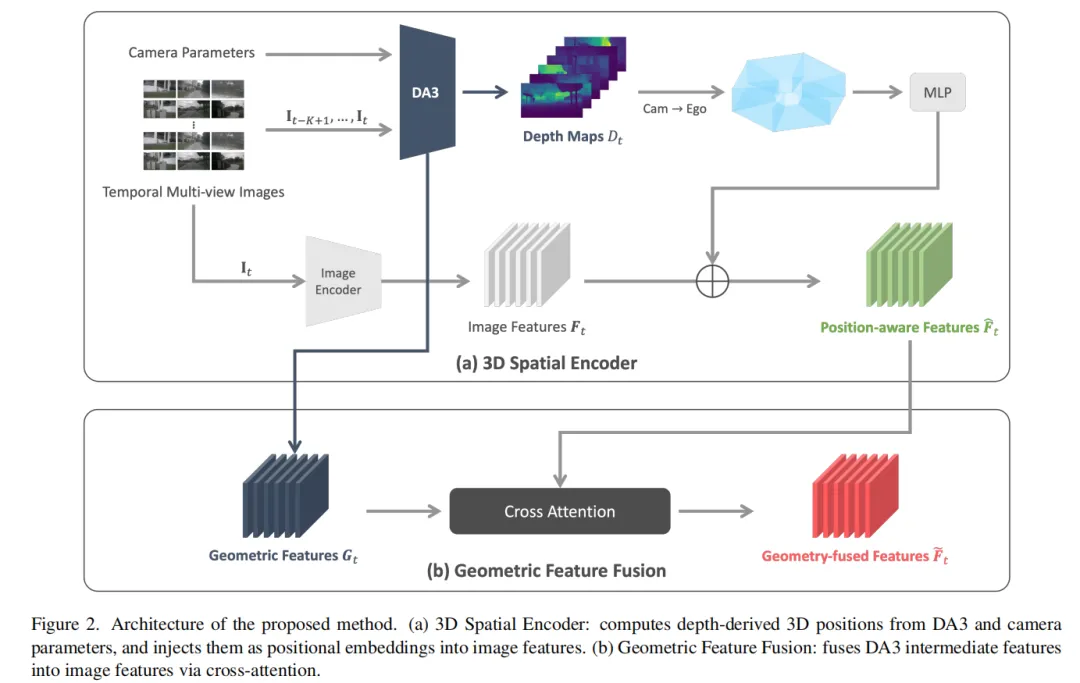
方案架构:两个核心模块
该方案将DA3作为冻结的辅助编码器,与端到端自动驾驶模型(基于VR-Drive框架)并行运行,通过两个模块注入几何先验:
模块一:3D Spatial Encoder(3D空间编码器)
该模块为每个图像像素赋予显式的3D空间位置信息:
- Step 1:单目深度预测。DA3对当前帧的每个相机图像预测深度图 ;
- Step 2:3D反投影。结合当前相机的内参 和外参(旋转、平移),将每个像素反投影到**自车坐标系(ego coordinate system)**下的3D位置。对于深度值为 的像素:
- Step 3:位置编码。对3D坐标应用正弦位置编码(SPE, Sinusoidal Positional Encoding),再通过MLP映射为与图像特征同维度的位置嵌入;
- Step 4:特征融合。将位置嵌入**直接加到(element-wise add)**图像backbone提取的图像特征上,使模型在感知语义信息的同时获得该像素在3D空间中的绝对位置线索 。
模块二:Geometric Feature Fusion(几何特征融合)
该模块将DA3学到的通用几何知识传递到下游任务:
- 提取DA3的中间层特征(蕴含3D结构、表面法向、场景布局等几何信息);
- 通过Cross-Attention机制将这些几何特征与图像backbone的特征融合(Query为图像特征,Key和Value为DA3几何特征);
- 融合后的特征既保留了图像的语义信息,又注入了预训练模型学到的「世界几何规律」。
训练与推理的统一流程
该方案在训练阶段和推理阶段的流程完全一致:
- DA3(冻结)并行处理图像,输出深度图 和中间层几何特征;
- 3D Spatial Encoder利用 和相机参数生成3D位置嵌入,加到图像特征上;
- Geometric Feature Fusion通过Cross-Attention将DA3几何特征融入图像特征;
- 增强后的特征输入端到端规划框架,训练时通过行为克隆损失优化,推理时直接输出规划动作。
整个过程中无需LiDAR、无需视角合成、无需虚拟相机投影,也无需对策略网络进行任何微调。
实验发现
在VR-Drive视角扰动基准上的实验表明,该方法在俯仰角(pitch)和高度(height)扰动下性能退化明显减小,但在**纵向平移(depth +1.0m)**场景下改善有限。消融实验发现,3D位置编码显式依赖于相机外参 是主要瓶颈——当测试时相机外参变化(如纵向平移改变了 ),基于 计算出的3D位置 也随之变化,导致位置编码本身失去了视角不变性 。
这揭示了一个关键结论:「引入显式3D表征」本身还不够,3D表征必须与相机外参解耦。未来需要构建BEV、体素或高斯-based的显式3D中间表征,先将图像特征提升到与相机无关的3D空间,再在3D空间中进行场景理解和规划,从根本上消除视角依赖 。
5.3 小结
引入显式3D表征的本质,是给模型提供「3D脚手架」。无论是BEVDepth用LiDAR监督训练深度估计,还是DA3论文用预训练基础模型在线生成深度图,核心都是让模型在2D图像之外获得额外的3D结构信息。这条路线的挑战在于:
- 3D表征与相机外参的耦合——如果3D位置仍然依赖当前相机的外参计算,那么视角变化时3D表征本身也会「漂移」。
因此,「显式3D表征」与「统一视角」或「替换3D主干」的结合,可能是这一路线走向成熟的关键。
六、路线五:替换主干网络——从「看图说话」到「看几何决策」
前四条路线都保留了传统的2D图像编码器(如ResNet、ViT)作为主干,只是在数据输入或特征融合阶段引入几何信息。而第五条路线则更加激进:直接替换视觉主干,用预训练的3D几何特征提取器取代2D图像特征提取器。
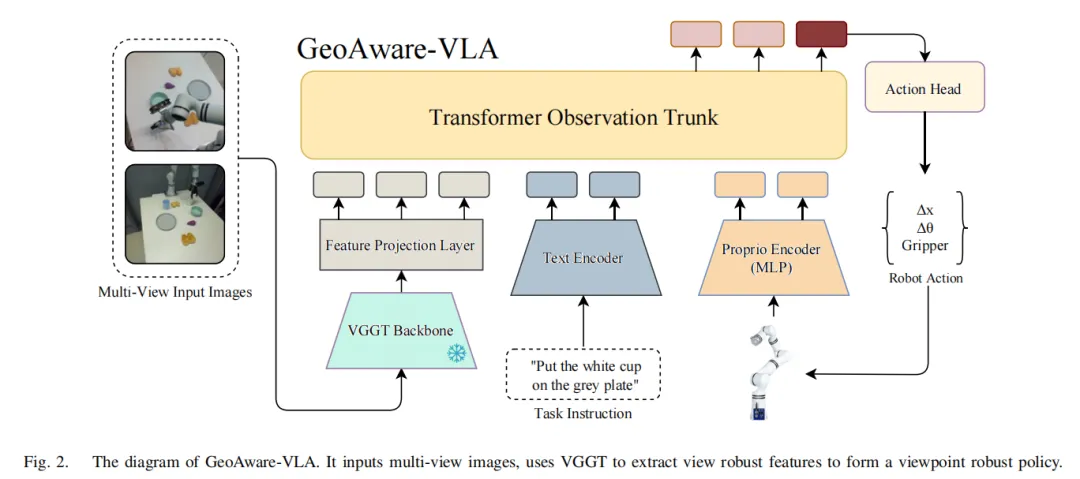
6.1 Geo-aware-VLA:冻结VGGT作为几何之眼
Geo-aware-VLA(2025)的核心改动极其简洁:将标准可训练的视觉编码器(如DINOv2、SigLIP)替换为冻结的预训练几何视觉模型VGGT(Visual Geometry Grounded Transformer)。VGGT是一个被显式优化用于丰富3D表示的模型,其预训练任务包括:相机参数估计、多视图深度预测、密集点云重建、以及点跟踪。
6.1.1 VGGT主干的使用方式
Geo-aware-VLA对VGGT的使用遵循「冻结主干 + 可训练投影层」的范式:
(1)移除预测头,提取中间层特征。VGGT原始模型包含多个任务特定的预测头(如相机位姿预测头、深度预测头等)。在Geo-aware-VLA中,这些预测头被全部移除,仅保留主干网络作为特征提取器。VGGT的一个关键特性是:它输出多层特征张量(a list of feature tensors from multiple intermediate layers),这些特征捕获了从低级视觉到高级几何信息的层次化表示。
(2)选择 个均匀间隔的中间层。设VGGT共输出 层特征,Geo-aware-VLA从中选择 个均匀间隔的中间层(evenly spaced intermediate layers)用于后续处理。对于每个相机视角,第 个被选层的特征维度为 ,其中 是视觉token的序列长度, 是VGGT的隐藏维度。
(3)逐层1D卷积 + 池化 + 拼接 + MLP投影。对于每个相机视角,Geo-aware-VLA设计了一个**可训练的视觉投影层(Vision Projection Layer)**来适配冻结的VGGT特征:
- 逐层处理:对每层选中的特征 ,先通过一个独立的1D卷积网络(包含可训练的卷积层和ReLU激活),再通过**自适应平均池化(Adaptive Average Pooling)**将该层特征压缩为单个向量 ;
- MLP投影:最后通过一个多层感知机(MLP)生成最终的视觉嵌入 。
数学表达为:
这一设计的巧妙之处在于:VGGT的各层特征分别编码了不同层次的几何信息(如浅层可能编码边缘和纹理,深层编码3D结构和相机几何),通过1D卷积和池化独立处理每层,再拼接融合,既保留了层次化几何信息,又通过轻量级的可训练参数适配到下游策略网络。
6.1.2 与原有VLA网络的适配
Geo-aware-VLA的整体架构分为三个阶段:感知编码(Sensory Encoding)→ 策略解码(Policy Decoding)→ 动作生成(Action Generation)。
在感知编码阶段,视觉观测 经过上述VGGT+投影层处理,生成视觉嵌入;语言指令 通过预训练的句子Transformer编码;本体感知状态 (末端执行器位姿和夹爪状态)通过两层MLP编码。三者拼接后输入GPT风格的Transformer策略解码器,最终生成动作 。
这意味着,Geo-aware-VLA对原有VLA网络的改动仅限于视觉编码器部分:将原来的可训练RGB编码器(如ResNet或ViT)替换为「冻结VGGT + 可训练投影层」,策略解码器(Transformer trunk + action head)完全保持不变。这种「即插即用」的替换使得该方法可以应用到任何基于RGB的VLA策略上。
实验表明,这种替换在仿真和真实机器人精细操作任务中均带来显著提升,在未见视角上的成功率提升可达2倍。当然,代价是推理延迟增加约40%,因为VGGT的计算开销大于标准视觉编码器。
6.2 小结
替换主干网络是从「表征根源」解决问题:如果输入给模型的特征本身就是视角无关的3D几何表示,那么模型自然就不存在2D视角鲁棒性问题。Geo-aware-VLA通过「冻结VGGT多层特征 + 逐层1D卷积池化 + MLP投影」的轻量适配方案,实现了对现有VLA架构的最小侵入式改造。这条路线的上限取决于3D几何预训练模型(如VGGT、DA3)的能力,以及它与下游任务的适配效率。随着3D基础模型的快速发展,这一方向可能成为终极解法之一。
七、总结:五条路线的博弈与融合
| | | | |
|---|
| 堆数据 | | Nvidia WorldSheet、VR-Drive | | |
| 统一视角 | | | | |
| 显式编码参数 | | | | |
| 显式3D表征 | | BEVDepth、DA3 Foundation Model | | |
| 替换主干 | | | | |
这五条路线并非互斥,反而正在走向融合。一个理想的未来框架可能是:
- 输入层:用VGGT或DA3等3D几何主干提取视角无关的初始特征;
- 编码层:将当前相机的内外参通过Plücker坐标、地面梯度等显式表示编码为几何嵌入,与3D特征融合;
- 适配层:通过虚拟相机投影将多源特征统一到一个标准BEV空间;
- 表征层:构建显式3D中间表征(BEV、体素、高斯),解耦场景理解与相机外参;
- 训练层:利用feed-forward 3DGS在线合成极端视角数据,持续扩充模型见过的配置分布。
视角鲁棒性问题的本质,是2D视觉与3D物理世界之间的映射脆弱性。无论是通过数据、投影、参数编码、3D表征还是表征升级,所有路线的终极目标都是同一个:让模型理解三维空间的物理规律,而非仅仅记住某个特定相机的像素映射。当自动驾驶模型从「轿车型号专属」走向「任意车型通用」,当机器人策略从「实验室固定机位」走向「真实世界手持相机」,视角鲁棒性将不再是锦上添花的优化项,而是决定技术能否规模化落地的硬门槛。
参考论文速览
- UniDrive: Towards Universal Driving Perception Across Camera Configurations (ICLR 2025)
- AnyCamVLA: Zero-Shot Camera Adaptation for Viewpoint Robust Vision-Language-Action Models (2026)
- VR-Drive: Viewpoint-Robust End-to-End Driving with Feed-Forward 3D Gaussian Splatting (NeurIPS 2025)
- Towards Viewpoint Robustness in Bird's Eye View Segmentation (ICCV 2023)
- Sparse4D v2: Recurrent Temporal Fusion with Sparse Model (2023)
- CoIn3D: Revisiting Configuration-Invariant Multi-Camera 3D Object Detection (CVPR 2026)
- BEVDepth: Acquisition of Reliable Depth for Multi-view 3D Object Detection (2022)
- Towards Viewpoint-Robust End-to-End Autonomous Driving with 3D Foundation Model Priors (2026)
- GeoAware-VLA: Implicit Geometry Aware Vision-Language-Action Model (2025)
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
