从近期顶会工作可以看出,仿真模型不能只在离线数据上预测得像,更要在真实滚动过程中表现稳定,能够处理多车博弈、行人穿行、复杂路口、并线让行等动态交互问题,减少碰撞、越界和违反交通规则等不真实行为。
这一趋势说明,自动驾驶仿真的核心正在从生成一段合理轨迹升级为训练一组可信交通智能体。强化学习微调、自博弈训练和中心参考模型等方法,开始被用于约束仿真智能体的行为边界,让模型既能保持真实驾驶分布,又能直接对齐安全性、真实感、规则遵守率和目标到达率等闭环指标。换句话说,仿真系统不再只是数据增强工具,而是在成为自动驾驶测试、长尾场景构造和策略验证的重要训练环境。我整理了10篇自动驾驶仿真 相关前沿论文,附官方代码,扫描下方二维码领取!
扫码回复“自动驾驶仿真”
免费获取全部论文+开源代码
CVPR 2026 | RLFTSim: Realistic and Controllable Multi-Agent Traffic Simulation via Reinforcement Learning Fine-Tuning
自动驾驶仿真正在从轨迹预测走向闭环智能体训练。RLFTSim关注的核心问题是:现有交通仿真模型虽然能在离线数据上生成合理轨迹,但进入闭环滚动后容易出现误差累积,导致碰撞、越界、违反交通规则等不真实行为,难以支撑自动驾驶测试与长尾场景验证。
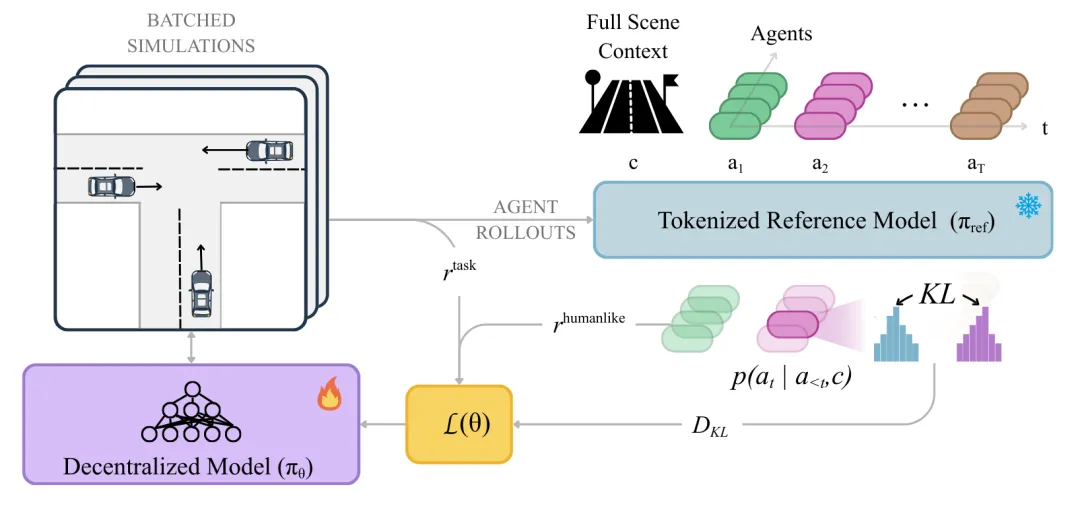
为此,论文提出一种面向多智能体交通仿真的强化学习微调框架。它不是从零训练模型,而是在预训练仿真器基础上继续后训练,直接利用真实感、交互质量、碰撞约束、地图约束等闭环指标作为优化信号,让仿真智能体在滚动过程中更接近真实驾驶行为。方法上,论文还引入低方差奖励构造,使原本稀疏的真实感评价指标更适合强化学习优化,从而提升训练效率。
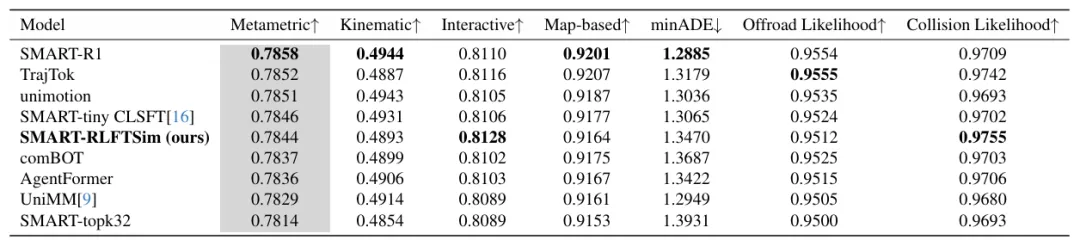
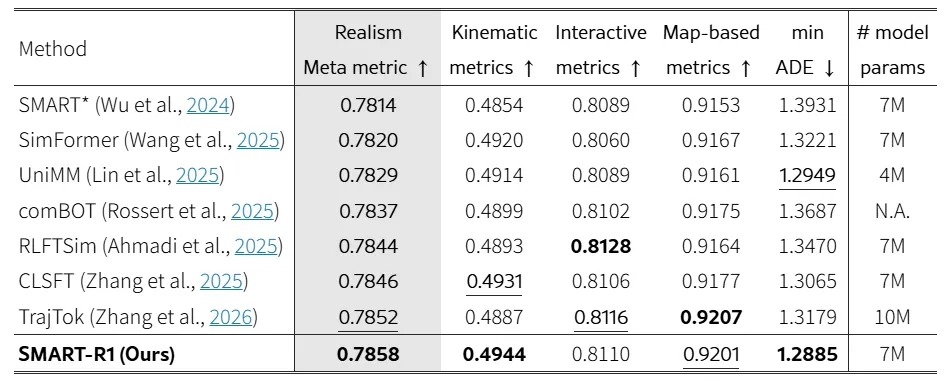
这篇工作的主要创新在于:把强化学习后训练引入交通仿真模型,使模型不再只拟合离线轨迹分布;将真实感和安全性指标直接转化为训练目标;在较少训练数据下仍能提升多智能体交互质量。实验结果显示,该方法在Waymo仿真挑战基准中提升了整体真实感,尤其改善了交互指标和碰撞相关表现。
它的研究价值在于说明:自动驾驶仿真不再只是生成轨迹或扩充数据,而是在成为训练可信交通智能体的重要环境。未来,强化学习微调、闭环指标对齐和可控场景生成,将是自动驾驶仿真冲顶会的重要方向。
扫码回复“自动驾驶仿真”
免费获取全部论文+开源代码
ICLR 2026 | Advancing Multi-agent Traffic Simulation via R1-Style Reinforcement Fine-Tuning
自动驾驶仿真正在从轨迹模仿走向闭环智能体训练。这篇工作关注的核心问题是:传统交通仿真模型大多依赖监督学习,在离线数据上能拟合真实轨迹,但进入闭环滚动后容易出现误差累积、分布偏移、碰撞、越界和交通规则违规等问题,导致仿真行为不够真实。
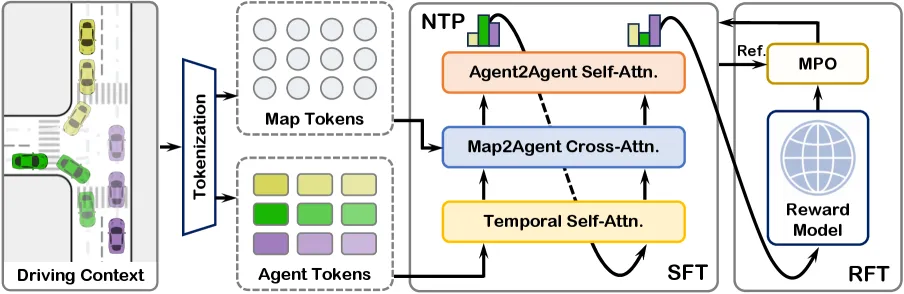
为此,论文提出一种面向多智能体交通仿真的R1式强化学习后训练框架。方法先通过行为克隆学习基础驾驶分布,再进行闭环监督微调缓解滚动误差,随后引入强化学习微调,让模型直接对齐真实感、安全性和交互质量等评价指标,最后再通过监督微调恢复真实数据分布,避免策略偏移。
它的主要创新在于:将R1式强化学习后训练迁移到自动驾驶仿真;提出面向指标的策略优化方法,而不是简单照搬通用强化学习算法;通过监督微调—强化微调—再监督微调的流程,在指标优化和分布保持之间取得平衡。实验表明,该方法在Waymo仿真智能体挑战中提升了真实感指标,并在碰撞、越界、红绿灯违规等安全关键指标上表现更好。
这篇工作的研究价值在于说明:自动驾驶仿真不能只追求轨迹预测误差,而要直接优化闭环表现。未来,强化学习后训练、指标对齐、多智能体交互建模和可信交通智能体训练,将成为自动驾驶仿真冲顶会的重要方向。
扫码回复“自动驾驶仿真”
免费获取全部论文+开源代码
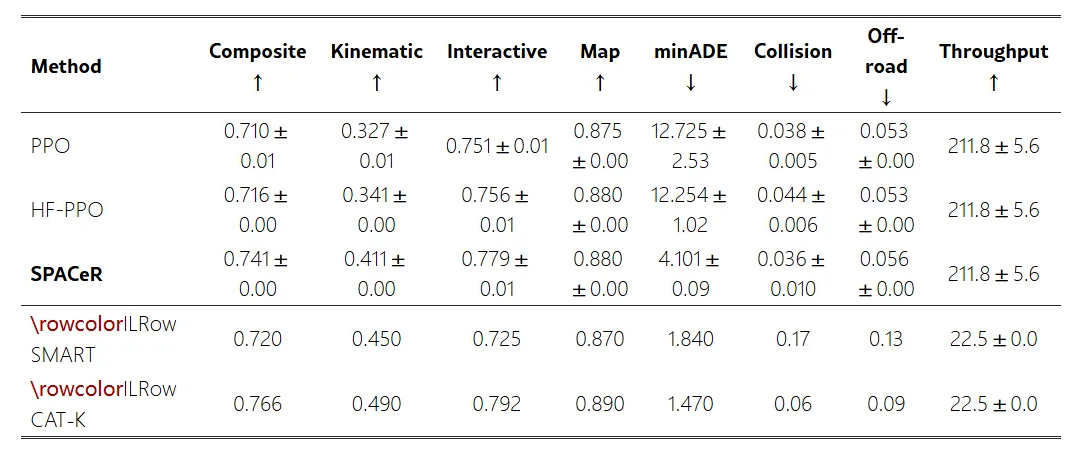
ICLR 2026 | SPACeR: Self-Play Anchoring with Centralized Reference Models
自动驾驶仿真正从离线轨迹复现走向闭环交通智能体训练。这篇工作关注的核心问题是:大型模仿学习模型虽然真实感较强,但推理成本高、闭环反应能力有限;传统自博弈强化学习虽然高效、可交互,却容易偏离真实人类驾驶分布,生成不自然甚至不安全的交通行为。
为此,论文提出一种中心参考模型锚定的自博弈强化学习框架。方法先利用预训练运动模型提供人类驾驶分布先验,再用它约束去中心化自博弈策略训练,使智能体在追求目标到达、避免碰撞、减少越界的同时,保持接近真实驾驶风格。最终执行策略采用轻量化去中心化结构,每个智能体基于局部观测行动,从而兼顾闭环交互能力和推理效率。
它的主要创新在于:将预训练参考模型引入自博弈强化学习,缓解策略偏离真实驾驶行为的问题;把动作似然和分布对齐转化为训练信号,让仿真智能体既“像人”又“能互动”;同时显著降低模型规模和推理成本,更适合大规模自动驾驶闭环测试。
这篇工作的研究价值在于说明:未来自动驾驶仿真不能只追求生成轨迹真实,而要训练可交互、可扩展、可用于规划器评估的交通智能体。强化学习后训练、自博弈、多智能体交互和真实驾驶分布约束,将成为自动驾驶仿真冲顶会的重要方向。
扫码回复“自动驾驶仿真”
免费获取全部论文+开源代码







 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
