Armor推荐理由
很多自动驾驶数据集都在堆相机、LiDAR、雷达,但真实道路上的失败常常不是因为“看不见”,而是因为强光、低光、颠簸、声音事件这些状态改变了传感器本身的可靠性。
MIPD 的价值在于把这些平时被当作背景噪声的因素单独记录下来,让算法有机会知道自己为什么会漏检、为什么框会整体偏移。
对做 4D 雷达和多传感器融合的人来说,这篇论文最值得带走的判断是:下一代感知数据集不能只标目标,还要标出传感器失手时的环境条件。
原论文信息
论文标题: MIPD: A Multi-Sensory Interactive Perception Dataset for Embodied Intelligent Driving
发表日期: 2025年08月在线发表,2025年11月正式刊出
发表单位: 北京化工大学、北京同仁医院、燕山大学、中国科学院自动化研究所、北京理工大学珠海学院、清华大学
期刊: IEEE Transactions on Intelligent Transportation Systems
原文链接: https://arxiv.org/abs/2411.05881
开源代码: https://github.com/BUCT-IUSRC/Dataset__MIPD
通讯作者: Tianyu Shen,北京化工大学
问题引入:自动驾驶不是只靠“眼睛”
一辆自动驾驶车在傍晚通过校园路口,前方有行人、自行车和停车车辆。相机画面还能看见目标,但太阳低角度照进镜头,图像对比度被压低;车轮刚好压过减速带,车身抖了一下,点云和图像之间的空间对齐也开始变差。
这时算法的失败并不完全来自目标太小或网络不够强。更本质的问题是:传感器看到的世界已经被环境状态改写了,但数据集通常没有把这种“改写”记录下来。
第一个难点是感知可靠性会随环境变化。 相机怕低光、逆光和眩光;LiDAR 点云密度高,但在颠簸时容易出现跨传感器对齐误差;4D 雷达有速度和远距离优势,但点云稀疏,单靠它很难给出稳定的细粒度轮廓。
第二个难点是传统数据集更像“目标清单”,不是“失效原因清单”。 KITTI、nuScenes、Waymo 这类数据集给了图像、点云、标注框和轨迹,但光照强度、车身振动、声音事件这类状态往往缺席。算法训练完以后知道某帧错了,却很难知道错在低光、颠簸,还是模态融合策略本身。
第三个难点是多模态融合常常只融合“主传感器”。 相机、LiDAR、雷达是主体,光照、振动、声音被当成外围变量。MIPD 的反直觉之处在于,它把外围变量拉回感知链路,让算法在判断目标前先获得环境状态。
现有方案大致卡在几个位置:
🚗 相机单模态方法:图像信息丰富,但遇到逆光、夜晚和强反射时,目标置信度会明显下降。
📡 LiDAR 或 4D 雷达方法:几何和速度信息更稳定,但 LiDAR 成本高,4D 雷达点云稀疏,单独使用都容易遇到信息缺口。
🔗 相机+LiDAR/雷达融合方法:常规融合能提升精度,但如果不知道当前帧发生了强光或颠簸,融合模块仍可能把低质量模态当成正常输入。
所有方法共同面对的矛盾是:算法一直在融合传感器,却很少显式建模“传感器为什么会不可靠”。
化繁为简的妙招:从“多模态目标标注”到多感官状态记录
MIPD 的核心不是提出一个更复杂的检测网络,而是重新定义自动驾驶数据集应该记录什么。
过去的数据集像给车装了更好的眼睛。MIPD 更像给车加了一套身体感知:它既看前方目标,也记录当时的光有多强、车身抖得多厉害、环境里有没有声音事件、车辆速度如何变化。这样一来,算法不只学习“这是什么目标”,还可以学习“什么环境条件会让这个目标变难识别”。
关键洞察是:环境状态不是噪声,而是解释感知失败的变量。
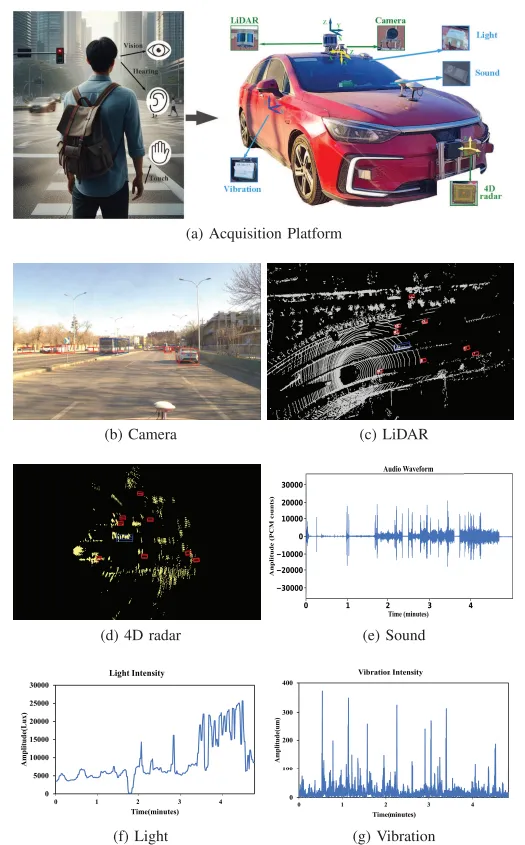
论文作者把采集系统扩展到高分辨率相机、80线 LiDAR、4D 雷达、IMU、光照传感器、四个振动传感器和声音采集传感器。相机、LiDAR、4D 雷达负责回答“目标在哪里”;光照、振动和声音负责回答“这一帧为什么难”。
同步和标定是这个数据集能不能用的底座。论文采用 LiDAR-Camera 和 LiDAR-4D Radar 离线联合标定,传感器对齐误差控制在 3 cm 以下;两台工业计算机分别管理主传感器和环境传感器,通过 PTP 协议以及共享物理事件进行跨系统时间校验,传感器时间偏差控制在 5 ms 以内。
这个数字的工程意义很直接。3 cm 的空间误差对车辆级 3D 检测还可以接受,5 ms 的时间误差对 10 Hz 相机/LiDAR 和 20 Hz 4D 雷达来说也没有离开常规融合窗口。MIPD 至少不是把一堆异步数据简单堆在文件夹里。
算法核心步骤:先采状态,再看目标,再解释失效
MIPD 的工作流程可以拆成三个阶段。
多感官同步采集。 采集车同时记录相机图像、LiDAR 点云、4D 雷达点云、IMU、光照、振动、声音和车速。主传感器负责前向目标感知,环境传感器记录当前道路和光照状态。
结构化标注与格式整理。 数据集采用 KITTI 格式,提供 3D bounding box、类别标签和 tracking ID。图像保存为 PNG,LiDAR 和 4D 雷达保存为 PCD 点云,光照和振动保存为 XLSX,声音保存为 WAV。
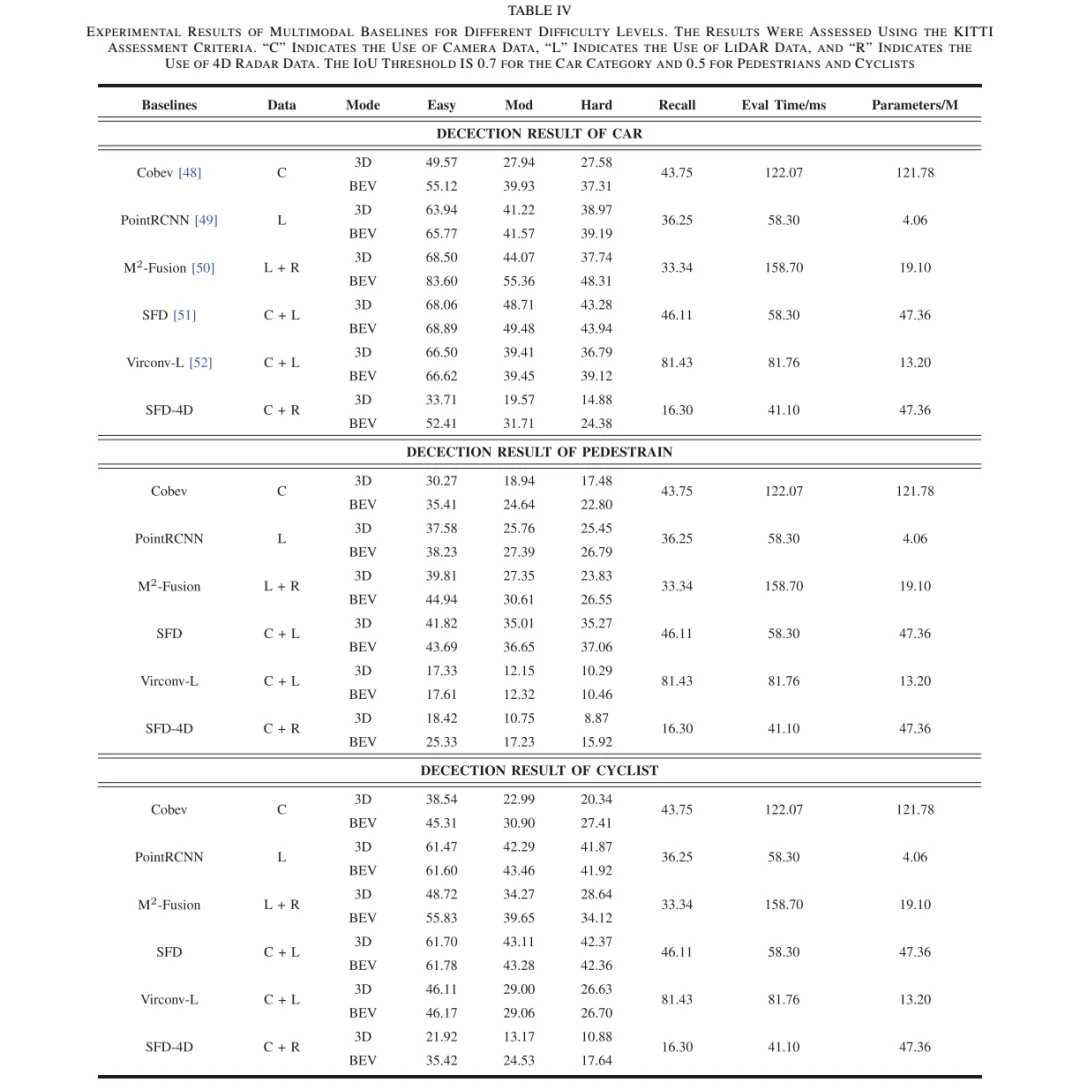
用 baseline 验证数据集价值。 论文没有停留在“我们采了很多传感器”这一步,而是用 CoBEV、PointRCNN、M2-Fusion、SFD、VirConv-L、SFD-4D 等模型测试单模态和多模态检测效果,再额外做光照/振动消融实验。这个设计的重点是证明新模态能影响检测结果,而不是只增加文件大小。
性能全面领先:不是精度碾压,而是失效解释能力增强
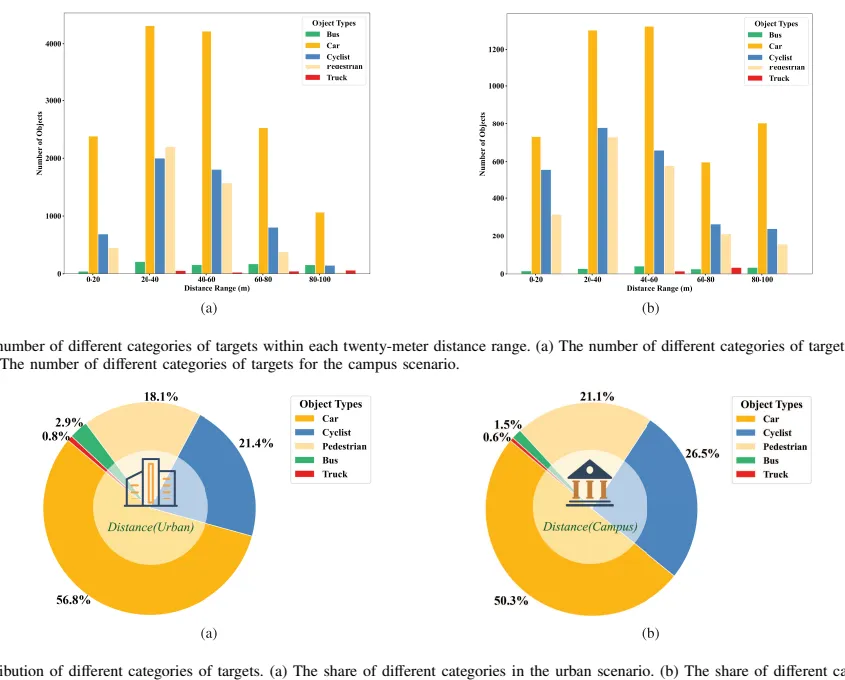
MIPD 一共包含 126 段连续序列,许多序列超过 20 秒;从约 20,000 帧同步数据中人工标注 8,568 帧,包含 90,983 个目标。对数据集论文来说,这个规模不算超大,但它的差异点在于多感官同步,而不是单纯拼帧数。
在目标分布上,城市场景车辆占 56.8%,校园场景车辆占 50.3%;校园里行人和自行车占比更高,分别达到 21.1% 和 26.5%。这意味着数据集不是只覆盖高速道路上的车辆检测,还包含低速、混行、近距离目标密集的场景。
baseline 结果也暴露了一个现实问题:相机方法在复杂光照下会明显吃亏。以 Car 类别 BEV Easy 为例,CoBEV 只有 55.12%,SFD-4D 的 Camera+4D Radar 为 52.41%,而 M2-Fusion 的 LiDAR+4D Radar 达到 83.60%。这里不能简单理解为“雷达融合一定更强”,更准确的判断是:当相机质量被光照拖低时,点云模态的稳定性会变得更关键。
速度方面,SFD 的评估时间为 58.30 ms,VirConv-L 为 81.76 ms,M2-Fusion 为 158.70 ms,SFD-4D 为 41.10 ms。论文中提到基于伪点云的相机融合方法检测率可超过 20 Hz,而 M2-Fusion 大约 7 Hz。
工程可行性翻译: 58 ms 级别意味着单模型推理大约对应 17 Hz,已经接近低速自动驾驶或离线评估可用区间,但对量产车完整感知栈来说还要留出跟踪、预测、规划和控制时间。158 ms 级别约等于 6 Hz 到 7 Hz,更适合研究验证,不适合直接塞进高频闭环感知链路。MIPD 的价值因此不是给出一个可直接上车的实时算法,而是提供能评估算法在光照和颠簸下是否可靠的数据基础。
从仿真到实测:光照和振动确实改变检测结果
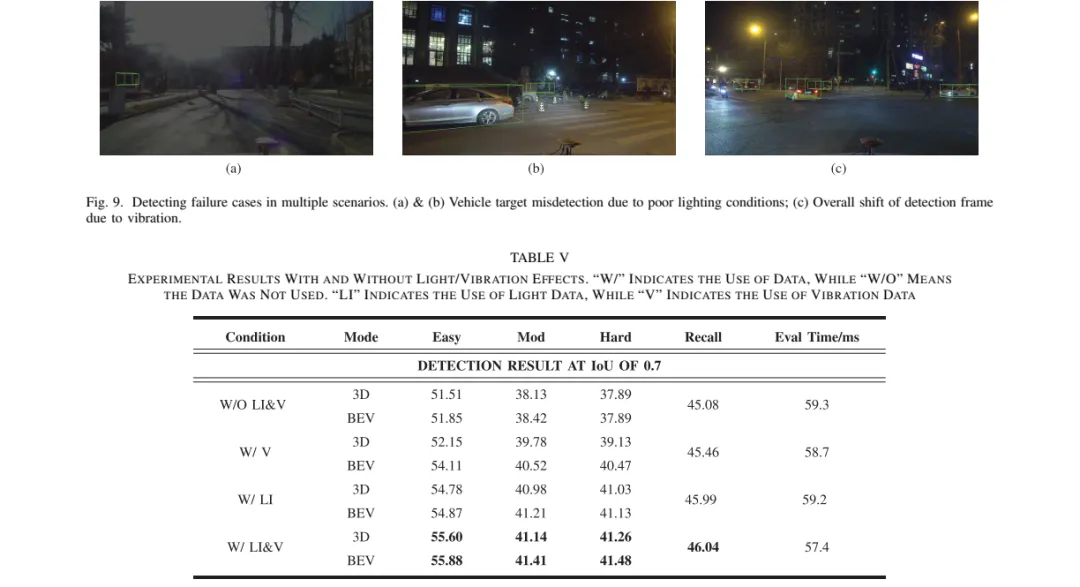
论文最有说服力的一组实验,是把光照和振动接入 SFD 模型后的消融对比。作者选择下午时段 2,300 帧数据,因为这一时段光照和振动变化更强。
在 IoU = 0.7 条件下,不使用光照和振动时,BEV Easy/Mod/Hard 分别为 51.85%、38.42%、37.89%。同时加入光照和振动后,三个指标变为 55.88%、41.41%、41.48%,分别提升 2.65%、1.95%、2.48%。
单独加入光照也有效:BEV Easy 达到 54.87%,相对不加入环境数据提升 1.55%。单独加入振动时 BEV Easy 为 54.11%,提升 0.88%。更关键的是,加入这些低维环境状态后,推理时间仍稳定在 57.4-59.3 ms。
这组数字不算夸张,但工程含义明确:光照和振动不是“锦上添花”的元数据,而是能进入模型、改变检测结果的信号。它们的收益目前只有几个百分点,说明方法还很初级;但在安全系统里,几个百分点可能正好对应低光路口和颠簸路段里的漏检减少。
未来展望
MIPD 把自动驾驶感知从“多传感器融合”推向“多感官状态建模”。这条路的意义在于,车不只要知道外部世界是什么,还要知道自己当前感知这个世界的条件是否可靠。
对 4D 雷达方向来说,MIPD 的启发在于:雷达不一定只是相机和 LiDAR 的替补。它可以和光照、振动、声音一起构成一种“鲁棒性解释层”。当相机低光失效、LiDAR 与图像对齐变差时,雷达速度维和环境状态数据可以帮助系统判断该相信哪一种模态。
下一步更值得做的是跨模态交互,而不是简单 concat。比如光照强度可以动态调节相机特征权重,振动强度可以提示融合模块放宽图像和点云的空间对应,声音事件可以作为急刹、碰撞或特殊场景的时间触发信号。
论文也承认当前数据集仍有规模和传感器类型限制。作者计划继续加入驾驶轨迹、事件相机和更复杂场景,把任务从 3D 检测、跟踪延伸到路径规划和决策。这意味着 MIPD 更像第一版基础设施,而不是终局答案。
Armor三问
为什么不直接用更强的相机+LiDAR融合模型,而要加光照和振动?
更强的融合模型只能在输入数据质量足够稳定时发挥作用。低光会降低图像置信度,颠簸会破坏跨传感器空间对齐,这些问题不是单纯加深网络就能稳定解决。光照和振动的作用是给模型提供失效条件,让模型知道当前帧的相机或点云是否需要降权。
光照和振动提升只有两三个点,这个收益够不够?
从论文数字看,它还不是决定性提升,不能包装成检测能力跨代升级。但在低光和颠簸场景中,这类信号指向的是长尾风险。对安全系统来说,平均精度提升不大不代表价值低,关键要看它是否集中减少高风险场景下的漏检和框偏移。MIPD 目前给出了方向证据,还需要更大规模长尾验证。
MIPD 对 4D 雷达研究最直接的价值是什么?
它提供了一个更接近真实部署的比较框架。4D 雷达的优势常在恶劣光照、远距离速度估计和低成本冗余感知中体现,但如果数据集没有记录光照和车身状态,这些优势很难被准确评估。MIPD 把环境状态显式记录下来,有利于判断 4D 雷达在什么条件下真正补上了相机和 LiDAR 的短板。
Armor测评
学术/科研价值: ★★★★☆
这篇论文的突破口在于把自动驾驶数据集的问题从“收集更多主传感器数据”推进到“记录感知失效条件”。它没有突破物理边界,而是把光照、振动、声音等相邻信号接入多模态感知评估链路。复现基础相对友好,论文声明将开放数据和开发套件,但具体仓库状态仍需发布前确认;主要门槛在于多传感器同步、标定和环境状态数据的有效使用方式。
工业/工程价值: ★★★★☆
工程价值集中在真实道路鲁棒性评估。低光、逆光、颠簸会分别影响图像质量和跨传感器对齐,MIPD 把这些因素变成可量化输入,并给出 3 cm 以内空间标定误差、5 ms 以内时间偏差、57.4-59.3 ms 推理时间这类系统级指标。它还不是车规级闭环验证数据集,但已经比只给图像和点云的数据集更接近真实部署问题。
商业/产品价值: ★★★☆☆
产品价值适合落在车厂、Tier1 和感知算法供应商的鲁棒性测试环节(例如验证同一检测模型在夜晚、强光、减速带路段中的稳定性)。它不要求替换主传感器,更多是把低成本环境状态传感器接入数据闭环,因此部署阻力相对可控。短期商业缺口在于数据规模、地域多样性、天气覆盖和与量产感知栈的接口验证仍不足。
可能的问题: MIPD 目前规模小于 Waymo、nuScenes 这类大数据集,且实验主要验证 3D 检测,对端到端规划和决策的支撑还偏弱。光照和振动的利用方式也比较初级,主要通过插值、MLP 和特征拼接接入模型,距离真正根据环境状态动态调整融合策略还有距离。
主要参考文献
Li, Z., Zhang, T., Zhou, M., Tang, D., Zhang, P., Liu, W., Yang, Q., Shen, T., Wang, K., & Liu, H. (2025). MIPD: A Multi-Sensory Interactive Perception Dataset for Embodied Intelligent Driving. IEEE Transactions on Intelligent Transportation Systems. DOI: 10.1109/TITS.2025.3593298.
本文仅代表个人理解及观点,不构成任何论文审核或项目落地推荐意见,具体以相关组织评审结果为准。论文内容如有理解偏差,以原文为准。欢迎就论文内容交流探讨,理性发言哦~
对4D雷达、多传感器融合和自动驾驶鲁棒性感知感兴趣的朋友,欢迎关注Armor知道公众号!

 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
