自动驾驶系统的核心目标是在复杂、动态的交通环境中实现安全的路径规划与车辆控制。从技术架构上看,现代自动驾驶系统高度依赖模块化或端到端的数据驱动算法。深度学习(Deep Learning, DL)技术通过高维非线性特征提取能力,已完全主导了自动驾驶的环境感知模块,并正在逐步重构轨迹预测、决策规划及控制模块。本文将系统性阐述深度学习在自动驾驶各个子系统中的具体应用,并提供对应的代码实现参考。
经典的自动驾驶软件栈采用流水线(Pipeline)架构,主要包含四个串联模块:
环境感知(Perception):处理摄像头、激光雷达(LiDAR)、毫米波雷达等多模态传感器数据,输出目标边界框、语义类别、车道线拓扑等结构化数据。
轨迹预测(Prediction):基于感知输出的动态障碍物历史轨迹,预测其未来T 秒内的运动轨迹概率分布。
决策规划(Planning):综合自车状态、高精地图(HD Map)、环境目标状态,生成一条满足安全性、运动学约束和舒适性的平滑轨迹。
底层控制(Control):通过PID、MPC(模型预测控制)等算法,将规划的轨迹转化为方向盘转角、油门和制动指令。
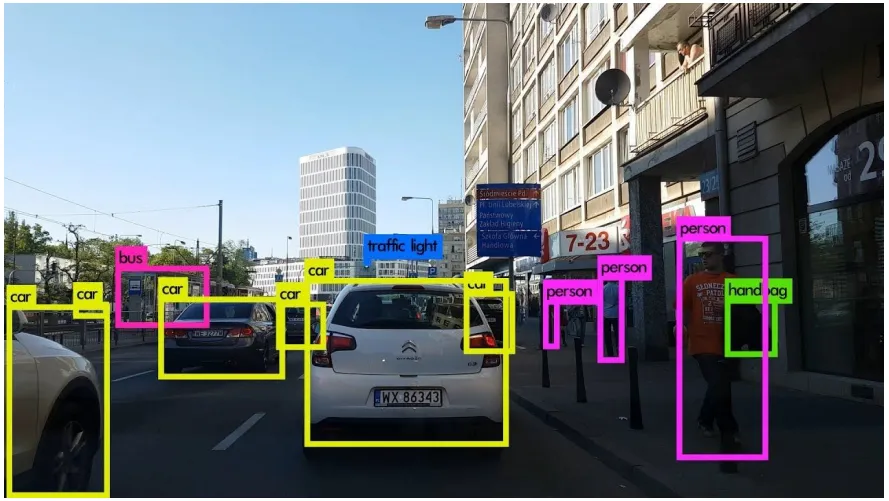
环境感知是深度学习落地最成熟的领域,主要涉及2D/3D目标检测和语义分割。
2D目标检测负责在图像平面 (u, v) 上定位车辆、行人、交通标志等,输出格式为 (x, y, w, h, class, confidence)。目前工业界主流采用YOLO系列(One-stage)以保证低延迟。
算法原理
YOLO算法将输入图像划分为 SxS 的网格,如果某个目标的中心落入特定网格,该网格对应的锚框(Anchor)或锚点(Anchor-free)负责预测该目标的边界框及类别。网络通常由骨干网络(如CSPDarknet)、颈部网络(PANet或FPN)和检测头(YOLO Head)组成。
核心代码实现(基于PyTorch的YOLOv8推理封装框架参考)
以下代码展示了在自动驾驶工程中,如何封装一个支持GPU加速的2D目标检测类。
import torchimport cv2import numpy as npfrom ultralytics import YOLOclassPerception2D: def __init__(self, model_path, conf_thres=0.5, iou_thres=0.45): """ 初始化2D感知模块 :param model_path: 预训练权重路径 (.pt或.engine) :param conf_thres: 置信度阈值 :param iou_thres: NMS(非极大值抑制)的IoU阈值 """ self.device = torch.device('cuda'if torch.cuda.is_available() else'cpu') # 在实际部署中,通常会使用TensorRT引擎而非原生PyTorch模型 self.model = YOLO(model_path).to(self.device) self.conf_thres = conf_thres self.iou_thres = iou_thres def inference(self, image_np): """ 前向推理函数 :param image_np: BGR格式的numpy数组 (H, W, 3) :return: 解析后的检测结果列表 """ # 前处理与推理整合在YOLO对象中 results = self.model(image_np, conf=self.conf_thres, iou=self.iou_thres, verbose=False)[0] detections = [] # 解析预测框坐标、置信度与类别 for box in results.boxes: x1, y1, x2, y2 = box.xyxy[0].cpu().numpy() conf = box.conf[0].cpu().item() cls_id = int(box.cls[0].cpu().item()) detections.append({ "bbox": [x1, y1, x2, y2], "confidence": conf, "class_id": cls_id }) return detections# 使用示例# detector = Perception2D("yolov8n.pt")# frame = cv2.imread("front_camera.jpg")# outputs = detector.inference(frame)
激光雷达输出的是无序的 (x, y, z, r)点云数据。直接对点云使用2D卷积会导致内存爆炸。工业界常用的方法是基于体素(Voxel)或柱体(Pillar)的检测器,如PointPillars、VoxelNet或CenterPoint。
算法原理(以PointPillars为例)
PointPillars将3D空间在 X-Y 平面上划分为网格,形成垂直的“柱子”。然后利用简化的PointNet对每个柱子内的点云提取特征,将其投影为伪图像(Pseudo-image),最后应用标准的2D CNN进行3D边界框预测(输出 x, y, z, w, l, h)。
核心代码实现(点云体素化预处理)
体素化是3D深度学习的第一步,以下代码展示了如何将无序点云网格化。
import numpy as npimport torchdef voxelize_point_cloud(points, voxel_size, point_cloud_range, max_points_per_voxel, max_voxels): """ 点云体素化处理 (PointPillars 预处理核心逻辑) :param points: 输入点云 (N, 4) -> [x, y, z, reflectance] :param voxel_size: 体素大小 [vx, vy, vz] :param point_cloud_range: 感知范围 [xmin, ymin, zmin, xmax, ymax, zmax] :param max_points_per_voxel: 每个体素最多允许的点数 :param max_voxels: 场景中最多允许的体素总数 :return: voxels, coords, num_points_per_voxel """ # 过滤超出感知范围的点 mask = (points[:, 0] >= point_cloud_range[0]) & (points[:, 0] <= point_cloud_range[3]) & \ (points[:, 1] >= point_cloud_range[1]) & (points[:, 1] <= point_cloud_range[4]) & \ (points[:, 2] >= point_cloud_range[2]) & (points[:, 2] <= point_cloud_range[5]) points = points[mask] # 计算每个点所在的体素索引 grid_coords = np.floor((points[:, :3] - point_cloud_range[:3]) / voxel_size).astype(np.int32) # 实际工程中,此处常使用哈希表或C++/CUDA算子进行加速,此处提供Python numpy逻辑版本 voxel_dict = {} for i, coord in enumerate(grid_coords): coord_tuple = tuple(coord) if coord_tuple not in voxel_dict: if len(voxel_dict) >= max_voxels: break voxel_dict[coord_tuple] = [] if len(voxel_dict[coord_tuple]) < max_points_per_voxel: voxel_dict[coord_tuple].append(points[i]) # 构建输出Tensor num_voxels = len(voxel_dict) voxels = np.zeros((num_voxels, max_points_per_voxel, points.shape[1]), dtype=np.float32) coords = np.zeros((num_voxels, 3), dtype=np.int32) num_points_per_voxel = np.zeros((num_voxels,), dtype=np.int32) for i, (coord, pts) in enumerate(voxel_dict.items()): pts_array = np.array(pts) num_pts = pts_array.shape[0] voxels[i, :num_pts, :] = pts_array coords[i] = coord num_points_per_voxel[i] = num_pts return torch.tensor(voxels), torch.tensor(coords), torch.tensor(num_points_per_voxel)# 配置参数# voxel_size = [0.16, 0.16, 4.0]# point_cloud_range = [0, -39.68, -3, 69.12, 39.68, 1]
语义分割为图像中的每个像素分配一个类别标签。在自动驾驶中,这被用于提取静态环境,如可行驶区域(Drivable Space)、车道线、人行道和红绿灯。网络架构常采用编码器-解码器结构(如U-Net、DeepLabV3+)。
核心代码实现(标准U-Net模块)
import torchimport torch.nn as nnclass DoubleConv(nn.Module): """(卷积 => BatchNorm => ReLU) * 2""" def __init__(self, in_channels, out_channels): super().__init__() self.double_conv = nn.Sequential( nn.Conv2d(in_channels, out_channels, kernel_size=3, padding=1, bias=False), nn.BatchNorm2d(out_channels), nn.ReLU(inplace=True), nn.Conv2d(out_channels, out_channels, kernel_size=3, padding=1, bias=False), nn.BatchNorm2d(out_channels), nn.ReLU(inplace=True) ) def forward(self, x): return self.double_conv(x)class SimpleUNet(nn.Module): def __init__(self, n_channels, n_classes): super(SimpleUNet, self).__init__() self.inc = DoubleConv(n_channels, 64) self.down1 = nn.Sequential(nn.MaxPool2d(2), DoubleConv(64, 128)) self.down2 = nn.Sequential(nn.MaxPool2d(2), DoubleConv(128, 256)) self.up1 = nn.ConvTranspose2d(256, 128, kernel_size=2, stride=2) self.conv1 = DoubleConv(256, 128) # 拼接后通道数翻倍 self.up2 = nn.ConvTranspose2d(128, 64, kernel_size=2, stride=2) self.conv2 = DoubleConv(128, 64) self.outc = nn.Conv2d(64, n_classes, kernel_size=1) def forward(self, x): x1 = self.inc(x) x2 = self.down1(x1) x3 = self.down2(x2) # 解码阶段包含跳跃连接 (Skip Connection) x = self.up1(x3) x = torch.cat([x2, x], dim=1) # 在通道维度拼接 x = self.conv1(x) x = self.up2(x) x = torch.cat([x1, x], dim=1) x = self.conv2(x) logits = self.outc(x) return logits # 输出维度: (Batch, Classes, H, W)
单一传感器存在物理限制:摄像头缺乏深度信息,受光照影响大;激光雷达具有精确的几何信息但缺乏色彩和纹理。传感器融合是提高感知鲁棒性的必经之路。
前融合(Early Fusion):在数据级对齐,例如将激光雷达点投影到图像平面,为像素赋予深度通道(RGB-D)。
后融合(Late Fusion):各传感器独立运行检测算法,最后通过卡尔曼滤波(Kalman Filter)在目标级(Object Level)进行状态融合。
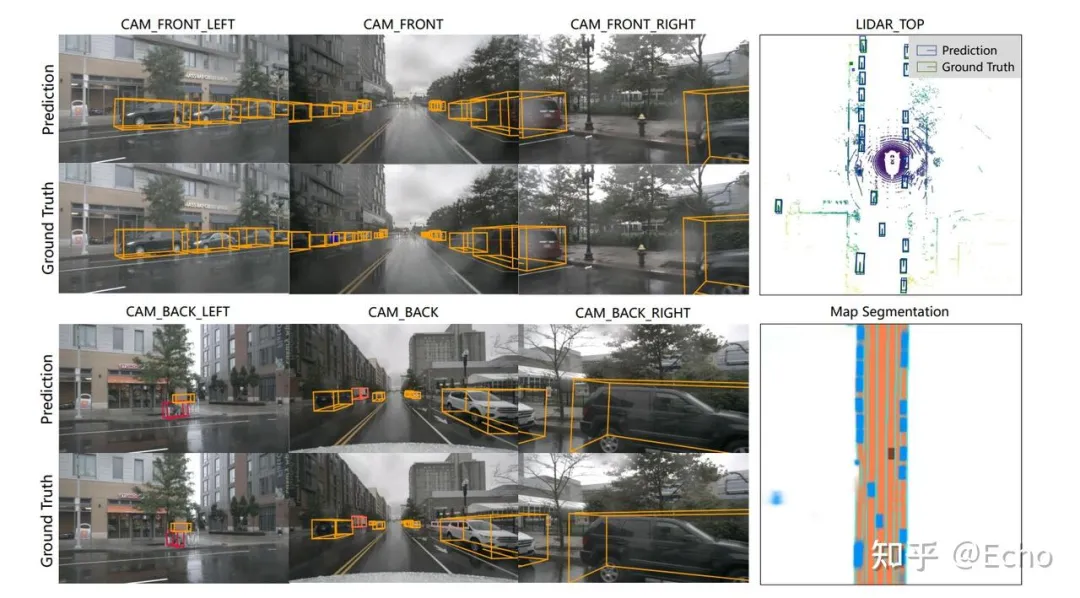
特征级融合(Deep Fusion / BEV):目前工业界最前沿的技术。利用深度学习在特征图层面进行空间对齐。
BEV感知将多视角的摄像头特征转换到自车坐标系下的统一俯视图空间。代表性算法包括BEVDet、BEVFormer。其核心在于视角转换(View Transformation)模块,主要分为两大流派:
Bottom-Up(自底向上):如LSS (Lift, Splat, Shoot),网络预测图像像素的深度分布,将其提升(Lift)为3D视锥体,再通过池化(Splat)压扁到BEV网格。
Top-Down(自顶向下):如BEVFormer,在BEV空间预设3D Query,利用注意力机制(Attention)去多视角图像特征中“索取”对应位置的特征。
核心代码实现(几何变换:相机像素到自车3D空间的投影矩阵运算)
以下代码展示了在进行BEV特征对齐前,必须执行的内外参矩阵运算逻辑。
import numpy as npdef pixel_to_ego_3d(u, v, depth, intrinsic, extrinsic_cam_to_ego): """ 将图像像素坐标转换为自车坐标系下的3D坐标 :param u: 像素横坐标 :param v: 像素纵坐标 :param depth: 该像素对应的深度值 (由LiDAR投影或神经网络预测) :param intrinsic: 相机内参矩阵 (3x3) :param extrinsic_cam_to_ego: 相机到自车的齐次外参矩阵 (4x4) :return: 自车坐标系下的3D坐标 [x_ego, y_ego, z_ego] """ # 1. 像素坐标转相机坐标系下的3D坐标 # 公式: Z_c * [u, v, 1]^T = K * [X_c, Y_c, Z_c]^T pixel_homo = np.array([u, v, 1.0]) intrinsic_inv = np.linalg.inv(intrinsic) # 归一化相机坐标 cam_coord_normalized = intrinsic_inv @ pixel_homo # 乘以真实深度 cam_coord = cam_coord_normalized * depth # 2. 相机坐标转自车坐标 # 构造齐次坐标 [X_c, Y_c, Z_c, 1] cam_coord_homo = np.append(cam_coord, 1.0) # 矩阵乘法: P_ego = T_cam2ego * P_cam ego_coord_homo = extrinsic_cam_to_ego @ cam_coord_homo return ego_coord_homo[:3]# 参数示例# K = np.array([[1000, 0, 960], [0, 1000, 540], [0, 0, 1]])# T = np.eye(4) # 假设相机与自车原点重合,实际中需要标定参数# ego_pt = pixel_to_ego_3d(500, 400, 15.5, K, T)
轨迹预测的输入是障碍物在过去 T_hist时刻的状态序列(位置、速度、偏航角)以及局部高精地图的拓扑结构,输出是未来 T_pred 时刻的多模态(Multi-modal)轨迹概率分布。
早期的轨迹预测多使用循环神经网络(RNN / LSTM / GRU)。车辆的运动被视为时间序列数据。为解决长距离依赖问题并引入地图上下文,当前主流算法转向了图神经网络(GNN,如VectorNet)和Transformer(如Wayformer)。
自动驾驶环境中的行为具有多模态特性(例如在十字路口,前车可能左转、直行或右转)。预测网络通常输出多个轨迹分支及其对应的概率。
核心代码实现(基于LSTM的基线轨迹预测模型)
以下代码实现了一个基础的Encoder-Decoder LSTM模型,用于预测单辆车的未来轨迹。
import torchimport torch.nn as nnclass TrajectoryPredictor(nn.Module): def __init__(self, input_dim=2, hidden_dim=64, output_dim=2, hist_len=10, pred_len=20): """ 基于LSTM的轨迹预测器 :param input_dim: 输入特征维度 (如 x, y) :param hidden_dim: LSTM隐藏层维度 :param output_dim: 输出特征维度 (如 x, y) :param hist_len: 历史轨迹长度 :param pred_len: 预测轨迹长度 """ super(TrajectoryPredictor, self).__init__() self.hist_len = hist_len self.pred_len = pred_len # 编码器:处理历史轨迹 self.encoder = nn.LSTM(input_size=input_dim, hidden_size=hidden_dim, batch_first=True) # 解码器:生成未来轨迹 self.decoder = nn.LSTM(input_size=output_dim, hidden_size=hidden_dim, batch_first=True) # 坐标映射层 self.fc = nn.Linear(hidden_dim, output_dim) def forward(self, hist_traj): """ :param hist_traj: 形状为 (Batch, hist_len, input_dim) 的历史轨迹 Tensor """ batch_size = hist_traj.shape[0] # 1. 编码历史状态 _, (h_n, c_n) = self.encoder(hist_traj) # 2. 解码准备 # 使用历史轨迹的最后一个点作为解码器的初始输入 decoder_input = hist_traj[:, -1, :].unsqueeze(1) # (Batch, 1, input_dim) predictions = [] # 3. 自回归解码 (Autoregressive Decoding) for t in range(self.pred_len): out, (h_n, c_n) = self.decoder(decoder_input, (h_n, c_n)) # 映射到坐标空间 pred_step = self.fc(out) # (Batch, 1, output_dim) predictions.append(pred_step) # 将当前预测作为下一步的输入 decoder_input = pred_step # 拼接所有预测步 # 返回形状: (Batch, pred_len, output_dim) return torch.cat(predictions, dim=1)# 测试代码# model = TrajectoryPredictor()# dummy_history = torch.randn(32, 10, 2) # Batch=32, 时间步=10, 特征=[x,y]# predicted_traj = model(dummy_history)# print(predicted_traj.shape) # 输出应为 torch.Size([32, 20, 2])
传统规划模块主要依赖于基于采样的算法(如A*、RRT)和最优化算法(二次规划QP)。深度学习在规划领域的引入主要通过两种途径:模仿学习(Imitation Learning)和强化学习(Reinforcement Learning)。
行为克隆(Behavioral Cloning, BC)将规划视为一个监督学习问题。输入传感器数据或感知结果,标签是人类驾驶员的真实操作(方向盘转角、踏板深度)或人类驾驶的轨迹。
优点:实现简单,易于利用海量人类驾驶数据。
缺点:存在分布偏移(Covariate Shift)问题。当遇到训练集中未见过的边界情况(Corner Case)时,模型容易崩溃。
DRL将自车视为智能体(Agent),通过在仿真环境中不断试错来最大化累积奖励(Reward)。常用算法包括DDPG、SAC和PPO。
核心代码实现(PPO算法策略网络结构)
在连续动作空间(如自动驾驶的转向和加速度)中,PPO算法会输出动作分布的均值和标准差。
import torchimport torch.nn as nnfrom torch.distributions import Normalclass PPOActorCritic(nn.Module): def __init__(self, state_dim, action_dim, hidden_dim=256): super(PPOActorCritic, self).__init__() # Actor 网络:输出动作概率分布 self.actor_base = nn.Sequential( nn.Linear(state_dim, hidden_dim), nn.ReLU(), nn.Linear(hidden_dim, hidden_dim), nn.ReLU() ) self.actor_mean = nn.Linear(hidden_dim, action_dim) # 动作标准差定义为可学习参数或与状态相关的网络输出,此处设为独立可学习参数 self.actor_log_std = nn.Parameter(torch.zeros(1, action_dim)) # Critic 网络:评估当前状态的价值 (Value) self.critic = nn.Sequential( nn.Linear(state_dim, hidden_dim), nn.ReLU(), nn.Linear(hidden_dim, hidden_dim), nn.ReLU(), nn.Linear(hidden_dim, 1) # 输出标量 V(s) ) def forward(self, state): raise NotImplementedError("使用 get_action 或 get_value") def get_action(self, state): actor_features = self.actor_base(state) action_mean = torch.tanh(self.actor_mean(actor_features)) # 限制均值在[-1, 1] action_std = torch.exp(self.actor_log_std) # 保证标准差为正 # 构建正态分布 dist = Normal(action_mean, action_std) action = dist.sample() action_log_prob = dist.log_prob(action).sum(dim=-1) return action, action_log_prob def get_value(self, state): return self.critic(state)# state_dim 可能是本车速度、前方障碍物距离、车道线偏差等拼成的向量# policy = PPOActorCritic(state_dim=10, action_dim=2) # 动作: [转向, 加速度]
端到端自动驾驶是近年来学术界和工业界共同的攻坚方向(如特斯拉的FSD v12,开源界的UniAD)。
传统的模块化架构中,感知网络的误差会向规划网络传播(Error Propagation),且各模块分别设定损失函数(感知追求IoU,规划追求安全),存在局部
最优问题。 端到端模型直接将传感器数据映射为控制指令或规划轨迹,只保留一个包含深度神经网络的整体函数  。
。
以2023年CVPR最佳论文UniAD为例,其将感知、预测、规划统一在一个Transformer框架内,通过Query传递信息。网络最终依据环境特征联合优化驾驶轨迹。
核心代码参考(端到端框架伪架构)
虽然完整的端到端代码极其庞大,以下代码展示了这种架构在网络前向传播层面的设计思想。
import torchimport torch.nn as nnclass EndToEndAutonomousDriving(nn.Module): def __init__(self): super(EndToEndAutonomousDriving, self).__init__() # 1. 骨干网络:提取多视角图像特征 self.backbone = ResNet_FPN() # 2. BEV转换模块:提取统一空间特征 self.bev_encoder = BEVFormer_Encoder() # 3. 感知任务头 (可选,用于辅助监督) self.detection_head = DetectionHead() self.map_head = MapSegmentationHead() # 4. 规划网络:基于BEV特征直接输出轨迹 # 输入:BEV特征,自车当前状态 (速度、加速度等) self.planner = TransformerPlanner() def forward(self, images, ego_state): # images shape: (Batch, Num_Cams, C, H, W) # 提取2D图像特征 img_features = self.backbone(images) # 融合构建BEV空间特征 bev_features = self.bev_encoder(img_features) # (训练阶段可选) 输出感知结果以计算辅助Loss det_outputs = self.detection_head(bev_features) map_outputs = self.map_head(bev_features) # 规划模块直接基于BEV进行轨迹生成 # 输出规划的轨迹点序列 (Batch, T, 2) planned_trajectory = self.planner(bev_features, ego_state) return planned_trajectory, det_outputs, map_outputs# 实际工程中的Loss计算将包含:# Loss = W1 * L_plan + W2 * L_det + W3 * L_map
尽管深度学习极大地推动了自动驾驶技术的发展,但在实际工程化落地中仍面临严峻挑战。
7.1 长尾问题(Long-tail Problem)
数据驱动的深度学习模型强依赖于训练数据的分布。对于交通环境中的罕见事件(Corner Cases,如高速公路上突然出现的异常抛洒物、极端的暴风雪天气、不符合常规规则的非机动车行为),由于数据集中样本极少,模型极易产生漏检或误判。解决这一问题的方向包括数据闭环系统的建设和自动化数据挖掘。
深度神经网络是一个复杂的黑盒(Black Box)系统。由于内部包含数千万甚至上亿的参数映射,当自动驾驶系统做出错误规划导致事故时,工程师极难反推其引发故障的确切代码行或参数点。这直接阻碍了基于深度学习的端到端自动驾驶系统通过严格的工业级功能安全标准(如ISO 26262)。未来的研究需要关注如何提供具有不确定度估计(Uncertainty Estimation)和可解释注意力的网络结构。
部署大规模Transformer模型(尤其是在进行多摄像头高分辨率BEV特征融合时),需要数以百计的TOPS算力支持。这不仅大幅提升了硬件BOM成本,更带来了严重的功耗及散热问题,尤其对于纯电动汽车而言,自动驾驶计算单元的高功耗将直接削减车辆的续航里程。
深度学习在自动驾驶领域的技术栈已从早期的单一图像检测,向着多模态3D感知、时序时空联合预测、以及端到端联合规划演进。通过合理的算法架构设计与严苛的底层模型部署优化,深度学习正在逐步逼近实现L4级完全自动驾驶的工程要求。






 点击“阅读原文”可查看详情
点击“阅读原文”可查看详情