自动驾驶仿真前沿 | 基于CARLA-DGGT的前馈式仿真重建
- 2026-05-15 19:23:17
作者:张峻川
出品:车路漫漫#CARLA #DGGT #3DGS #NuRec #仿真重建 #自动驾驶仿真
一、前言
3DGS技术问世以来,已经在自动驾驶领域吸引了广泛关注。在2026年的今天,3DGS在自动驾驶领域已经得到了大量应用。但单纯的3DGS重建技术始终面临痛点:很多场景重建方法需要针对每个场景进行若干时长的优化,或者极其依赖高精度的相机位姿输入,这在处理大规模路测数据时显然是不够优雅的。
因此一批“前馈式”的场景重建方法崭露头角,以能够实现无位姿一站式场景重建的功能吸引着越来越多自动驾驶从业者的目光。在本项目中,笔者尝试改造小米和清华 AIR发布的DGGT的推理部分代码,将前馈式重建出的场景保存成某种格式的数字资产,并开发了能够根据此数字资产渲染图像的代码dggt engine。
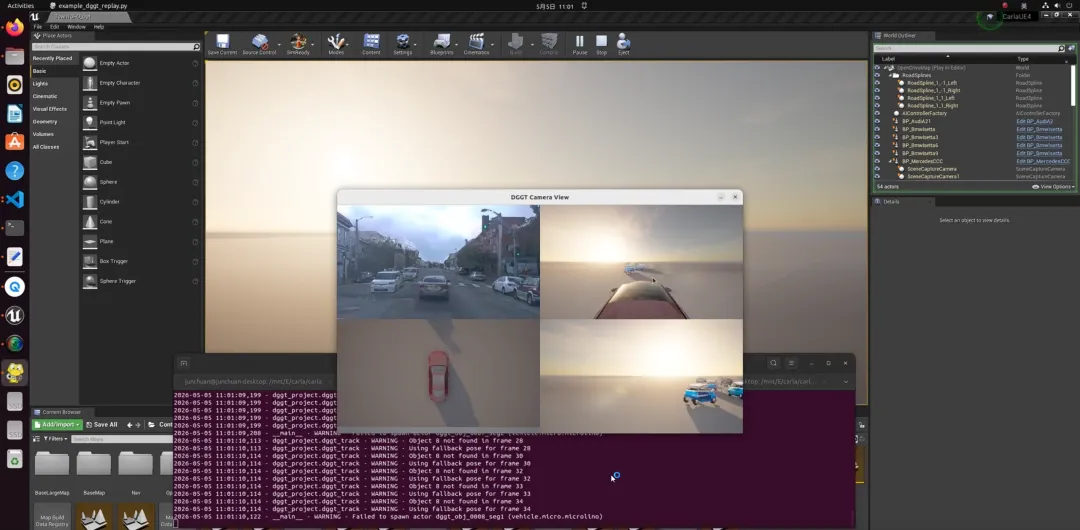
接下来笔者尝试将dggt engine接入自动驾驶仿真软件carla来代替图像渲染的功能。carla官方已经与NVIDIA合作推出了carla-NuRec联合仿真功能(详情请看历史文章最新版CARLA 0.9.16通过NuRec应用3DGS仿真效果抢先看!),但NVIDIA的NuRec渲染引擎本身代码并未开源。本项目尝试复刻carla-NuRec的联合仿真模式,以dggt engine代替NuRec实现一路前视图像的渲染,而物理模拟的部分由carla负责,并保留了场景编辑的可能。
在项目的测试过程中,笔者使用DGGT在waymo数据集上预训练的权重model_latest_waymo.pt,既尝试了推理waymo数据集中的场景,也尝试了直接推理nuScenes数据集中的场景,都可以在后续与carla的联合仿真中取得一定重建效果。
虽然本项目的demo级粗糙实现存在动态物体分离不稳定、长时序重建效果差等问题,但是跨域重建场景与carla的联合仿真仍然说明了前馈式重建方法可能拥有的光明前景:拥有大量路测数据的智驾企业可以以低频率定期训练、微调自己的前馈式模型,在日常测试过程中使用预训练模型根据需求以高频率一站式推理路测场景,然后可以将推理出的场景送入仿真软件,进行场景编辑、联合仿真,不再需要逐场景训练,也便于适配不同参数的相机传感器。
目前carla-dggt项目已经开源,网址:https://github.com/GimpelZhang/carla-dggt

二、DGGT推理管线深度改造
首先介绍基于小米和清华 AIR发布的 DGGT(Driving Gaussian Grounded Transformer) 项目的代码改造。
1. 初识 DGGT:前馈式 4D 重建的魅力
在传统的 3DGS 流程中,我们往往需要先跑 COLMAP 算位姿,再进行耗时的场景训练。而 DGGT 的核心贡献在于它实现了 “前馈式(Feedforward)”且“无位姿(Pose-free)” 的重建。
简单来说,你只需要给它一串没有位姿信息的原始 RGB 图像,模型通过内部的 Transformer 聚合特征,在一次前馈计算中就能直接“预测”出每一帧的相机参数、深度图、动态掩码以及像素级的 3D 高斯属性。它巧妙地将场景拆解为:
静态背景(Static Background):处理近场的路面、建筑。 动态物体(Dynamic Objects):通过专门的运动头(Motion Head)追踪车辆和行人的 3D 轨迹。 天空模型(Sky Model):专门处理无穷远处的背景。
这种“一次前馈、全栈输出”的能力,被笔者称为实现自动驾驶闭环仿真的“最后一片拼图”。
2. 推理代码改造:从“看一看”到“用起来”
虽然 DGGT 的原始推理脚本已经可以生成漂亮的渲染视频,但如果我们想要更进一步——比如把重建出的车辆拿出来在仿真器里“随心所欲”地移动,或者在不同视角下重新渲染场景——原始代码就显得有些捉襟见肘了。
为此,笔者对 DGGT 的 inference.py 进行了较大手术,核心目标是数据资产的标准化导出:
动静分离存储:利用模型预测的动态概率图,将静态场景、动态物体和天空分别导出为独立的 .ply点云文件。局部坐标系重构:为了方便后续在渲染引擎中实时编辑,笔者将动态物体(如小汽车)的坐标从世界坐标系剥离,转化成了以物体质心为原点的局部坐标系,并额外导出了对应的 4x4 位姿矩阵 JSON。 尺度桥接:这是最关键的一点,下文会详细展开。
3. 核心挑战与解决思路
在改造过程中,笔者遇到了两个比较棘手的技术问题,这里和大家分享一下解决逻辑。
A. 尺度恢复:从“相对”到“物理世界”
由于 DGGT 是在无位姿输入下进行预测的,它输出的深度和轨迹天然存在 尺度歧义(Scale Ambiguity)。在模型的眼中,场景可能只有几厘米大,相机也只移动了几个像素的单位。但在 CARLA 或真实的物理世界中,我们需要的是以“米”为单位的精确尺寸。
笔者的解决思路:
在DGGT原始代码的启发下,笔者引入了一个尺度因子计算函数。通过对比模型预测的“相机中心移动轨迹”与数据集自带的“真实 GPS/IMU 轨迹”,计算出两者的比值(Scale Factor)。随后,笔者将这个因子同步作用于位姿平移量、3D 点云位置、高斯球的几何尺寸以及预测的深度值。只有这样,导出的场景才能在仿真器中与真实的车辆蓝图完美匹配,不会出现“车在路面上方悬浮”或者“车辆像蚂蚁一样小”的尴尬场景。在实际应用中,通过实车数据的GPS/IMU轨迹,也是可以得到这种Scale Factor的。
B. 动态物体的“朝向”谜团
在解析导出的动态物体位姿时,笔者发现所有的旋转矩阵竟然都是单位矩阵。这是由于 DGGT 底层表征的特殊性决定的:它预测的是像素级的高斯体,而非物体级的包围盒。虽然我们通过 DBSCAN 算法把点云“凑”成了一辆车,但算法本身并不知道车头在哪。
笔者的解决思路:
目前的做法是保持点云的“世界坐标对齐”。既然数据里没有直接给朝向,我们可以通过计算物体在连续帧之间的位移向量,利用反三角函数来推算其行驶方向(Yaw)。虽然这种方法对于静止不动的物体还是无能为力,但在大多数行驶场景下已经能获得非常自然的视觉效果。
4. 现阶段的局限与反思
虽然目前的改造已经能输出可供渲染引擎使用的资产,但由于笔者水平有限,仍有几个非常严重的问题亟待解决:

目前笔者能想到的解决方案还比较初级,例如通过膨胀(Dilate)动态掩码来减少残留,或者强制只导出第一帧的背景。
以下图1和图2是笔者改造后的inference推理代码保存出的动静态物体分离的情况:

三、CARLA-NuRec 联合仿真架构与原理深度解析
CARLA 在 0.9.16 版本中正式合入了与 NVIDIA NuRec (Neural Reconstruction) 的联合仿真功能。这套方案不仅代表了目前 3DGS 在仿真领域落地的最高工程水平,也为我们之前的改造工作提供了极佳的参考范式。接下来我们就来拆解一下这套官方系统的底层架构与运行逻辑。
1. 系统架构:典型的“客户端-服务端”模型
CARLA-NuRec 的核心设计思想是职责分离:让擅长物理模拟的去跑物理,让擅长神经渲染的去画图。
整个系统由两大部分组成,它们之间通过高性能的 gRPC 协议进行二进制数据交互:

信息通讯链路简述:
在每一个仿真步(Tick)中,CARLA 端的集成脚本会收集当前世界中所有“可感知”对象的状态。这些信息会被打包成一个 RGBRenderRequest 请求。请求里包含了两类关键数据:
相机规格:分辨率、FOV、畸变模型等。 位姿序列:包括自车的精确位姿以及所有动态障碍物(Dynamic Objects)的世界坐标矩阵。
随后,这些数据飞向 Docker 容器,NuRec 引擎在极短时间内完成光栅化渲染,并将结果以 JPEG 或 PNG 流的形式返回给 CARLA。
架构如下图:
CARLA Python Client NuRec Docker Service┌─────────────────────┐ ┌─────────────────────┐│ NurecScenario │ │ gRPC Server ││ NurecRenderer │──gRPC────────▶│ SensorsimService ││ NurecSensor │ (render_rgb) │ Neural Rendering ││ generate_request() │◀──────────────│ (USDZ scene) │└─────────────────────┘ └─────────────────────┘ │ │ 关键数据流: │ ├── RGBRenderRequest (scene_id, PosePair, CameraSpec, DynamicObject[]) │ └── RGBRenderReturn (image_bytes) ▼ scene_id → USDZ文件路径 USDZ内含:rig_trajectories.json, sequence_tracks.json, data_info.json2. 联合仿真的基本运行原理
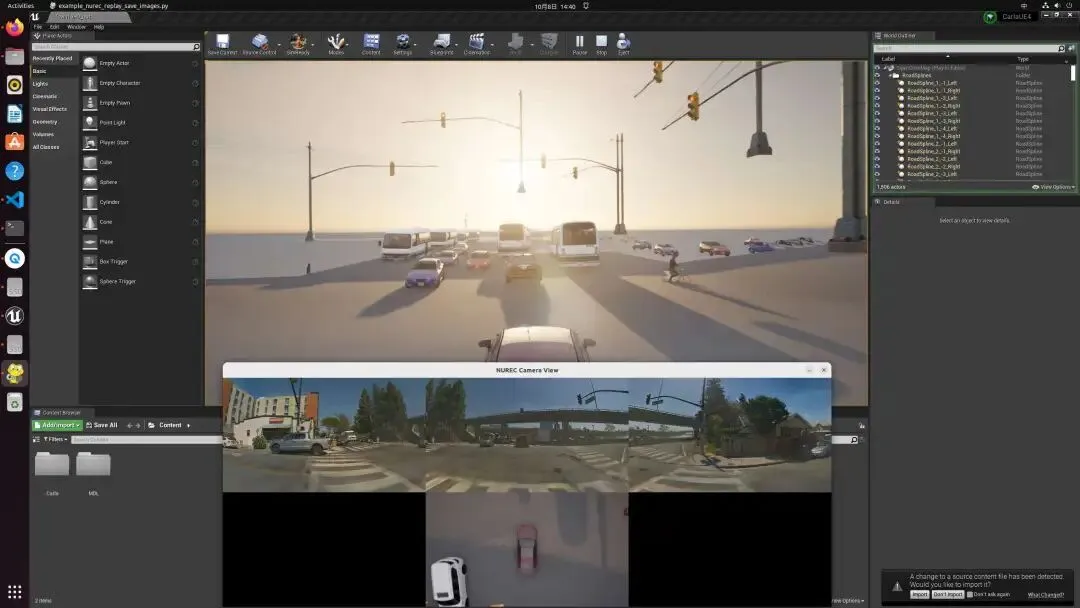
如果你运行官方提供的回放脚本(如 example_nurec_replay_save_images.py),你会发现这其实是一个双同步过程。
A. 场景同步
NuRec 方案并非在 CARLA 默认的“空地”上渲染。它依赖于一种特殊的场景打包文件(USDZ)。系统启动时,CARLA 会从该文件中提取 map.xodr 地图文件来生成物理世界。这意味着,你在 CARLA 里看到的道路边缘、坡度,在 NuRec 渲染出的图像中是严格对应的。
B. 渲染同步
NuRec 引入了一个名为 NurecSensor 的虚拟传感器。它的工作原理如下:
物理更新:CARLA 物理引擎根据上一帧的控制命令(油门、转向)更新主车位姿。 位姿抓取:传感器在 on_world_tick回调中抓取最新的WorldSnapshot。坐标转换:这是最关键的一步。由于 CARLA 使用左手坐标系(虚幻引擎约定),而 NuRec/OpenCV 使用右手坐标系,脚本必须通过 undo_carla_coordinate_transform等函数完成坐标轴的“翻转”和“对齐”。远程渲染:转换后的位姿发送给 NuRec 引擎,渲染出具备光影一致性的图像。
3. 数字资产的秘密:USD、USDA 与 .nurec
深入理解数据集目录中数字资产的作用,是玩转联合仿真的前提。
USDZ (Universal Scene Description Zip):这是一个压缩包,包含了整个场景的所有元数据、几何体、轨迹和模型权重。你可以把它看作是一个“场景快照”。 USDA (USD ASCII):这是一种人类可读的文本文件。它像一份“剧本”,描述了场景里有哪些对象(如静态背景、树木、路灯)、它们的层级关系以及它们引用了哪些原始模型文件。 nurec 格式文件:这是 NVIDIA 专有的神经表示格式。它包含了 3D 高斯点的几何属性(体积数据),通常还会连接对应的物理 Mesh(网格)文件,以便让机器人或车辆在仿真中产生碰撞反馈。 checkpoint.ckpt:这是模型的“大脑”。里面存储了经过数千次迭代训练出的神经网络权重。如果没有它,NuRec 引擎就无法知道那些高斯点应该呈现出什么样的颜色和纹理。 json 轨迹数据:例如 rig_trajectories.json记录了录制时的相机运动,而sequence_tracks.json则记录了周围车辆、行人的动作细节。
四、自研平替:用 DGGT Render Server 挑战 NuRec 官方仿真方案
NuRec 方案虽然强大,但其闭源的 Docker 镜像和复杂的 USDZ 打包格式,对于想要深度定制仿真逻辑的工程师来说,终究是一层“黑盒”。为了打破这层隔阂,笔者以改造后的 DGGT 推理资产 为基础,自研了一套 DGGT Render Server,成功替代了官方架构中的 NuRec Server。以下描述开发过程、那些“非对称对齐”工作,以及目前尚不完美的遗憾。
1. 系统架构:高度对齐的“乐高式”平替
为了能让这套系统无缝接入 CARLA 0.9.16+ 的生态,笔者在设计之初就确立了“接口完全对齐”的目标。

信息通讯链路:
笔者完全复刻了官方的 sensorsim.proto 协议。在每一个仿真步中,客户端会将相机内参、C2W 位姿以及场景中所有动态物体的 4x4 矩阵封装成 RGBRenderRequest 发送给 DGGT 服务端。服务端接收后,通过笔者改造后的推理管线产出的 PLY 资产进行光栅化渲染,最后将图像流传回客户端。
架构如下图:
CARLA Python Client DGGT Rendering Server┌─────────────────────┐ ┌─────────────────────┐│ DggtScenario │ │ gRPC Server ││ DggtRenderer │──gRPC────────▶│ DGGTSensorsimService││ DggtSensor │ (render_rgb) │ gsplat Rendering ││ generate_request() │◀──────────────│ (PLY+JSON scene) │└─────────────────────┘ └─────────────────────┘ │ │ 关键数据流: │ ├── RGBRenderRequest (scene_id, PosePair, CameraSpec, DynamicObject[]) │ └── RGBRenderReturn (image_bytes) ▼ scene_id → DGGT场景目录路径 场景目录结构: ├── gaussians/ │ ├── static_scene.ply │ ├── sky_scene.ply │ └── frame_XXXX_dynamic.ply ├── ego_pose/ │ └── frame_XXXX_ego.json └── dynamic_objects/ └── frame_XXXX_objects.json2. 运行原理与数字资产:3D 场景的“原子化”
不同于 NuRec 使用复杂的 USDZ 二进制包,笔者采用了更加透明的 分离存储架构,这极大地提升了加载效率和灵活性。
static_scene.ply&sky_scene.ply:它们构成了仿真的“舞台背景”,在系统启动时一次性加载到显存中,作为所有帧共享的底色。frame_XXXX_dynamic.ply:这些是动态“演员”的几何外壳。笔者将它们以 局部坐标系 存储,这使得我们可以像操作游戏模型一样,通过 4x4 矩阵随意修改它们的位姿。轨迹与位姿 JSON:记录了原始的相机参数和物体质心位置,作为渲染引擎初始化和循迹的“剧本”。
3. 研发过程中的核心挑战与 Engineering Hacks
在实际联调中,笔者发现官方方案在处理dggt方案时经常会遇到“水土不服”导致翻车。为此,笔者进行了一系列针对性的改进。
A. 坐标系与高度补偿的“零误差”对齐
这是最容易翻车的地方。DGGT 使用 OpenCV 右手系,而 CARLA 是 Unreal 左手系。
坐标链转换:笔者严格遵守了 undo_carla_coordinate_transform的转换链,确保发送给 Server 的位姿与官方逻辑完美契合。地图投影高度补偿 (Z-Offset Snapping):由于 OpenDRIVE 地图与真实轨迹的 Z 轴往往存在微小误差,笔者引入了动态投影逻辑,利用 CARLA API 将车辆“吸附”到路面上,彻底解决了主车在空中“悬浮”或卡在地里的灵异现象。
B. 自车与动态物体的物理“分而治之”
以下都采用官方方案的思路:
混合控制 (Hybrid Control):针对 CARLA 车辆刚生成时的“落地抖动”,笔者仿照官方方案设置了一个预热期:在前 8 帧强制关闭物理引擎,用 set_transform将车稳稳“拖”入正轨,待第 8 帧后再开启物理交由 PID 接管。障碍物“幻影化”:为了避免动态物体因地形起伏产生剧烈抽搐,笔者强制关闭了所有障碍物的物理模拟(Physics=False),让它们像幻影一样顺滑地沿轨迹飞行。
C. 动态朝向(Yaw)的简单推算
DGGT 原始输出的物体旋转全是单位矩阵,这会导致车辆永远“横着走”。
改进思路:既然数据集没给朝向,笔者就通过前后两帧的坐标差 结合 atan2函数,动态推算出车头的行驶方向。这让仿真场景中的转弯动作变得极其丝滑自然。
4. 现有的局限与进阶优化方向
虽然这套方案已经能跑通基本的联合仿真,但显然粗糙的demo离“工业级”还有很大距离:

此外,目前系统强行假设数据集为 10Hz,且在复杂起伏路面上单一的 Z 轴补偿仍可能失效。
最后,我们通过几个视频来看一下carla-dggt的效果:
很明显可以看出:动态物体的大小、种类、位姿都极其不稳定;在长时序的推理需求下,场景重建的质量严重下降。
从一个前馈式算法的 Demo,到一套可交互的闭环仿真系统,这中间充满了“不优雅”的 Hacks 与妥协。虽然目前的 carla-dggt 还是一个稚嫩的“缝合怪”,但它至少给了我们一个无需仰望闭源工具、亲手触算自动驾驶仿真底层的机会。
五、结语
本项目是笔者练习AI coding的“习作”,因此在此做出免责声明:本项目没有任何一行代码是由人类编写的;)
以上,本文完。
随机文章
-
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
- 哈弗猛龙PLUS即将上市,20万级新SUV让“家用硬派”不再两难
- 车市要“爆”!本周多款重磅SUV扎堆上市,准备好钱包了吗?
- 奥迪全新车型,旗舰级全尺寸SUV来了!
- 2026年买激情舒适的SUV,我只看这3款
- 成都经开区“自动驾驶项目”入选“2025年元宇宙典型案例”→
- 新股资讯:“自动驾驶解决方案供应商”驭势科技
- 奔驰豪华SUV“价格屠夫”,从近30万降到17万多,还要啥宝马X1?
- 12.48万买中型SUV,红旗HS5真香还是踩坑?这价格到底靠不靠谱.
- 北京现代首款纯电SUV来了!ELEXIO能救韩系合资吗?
- 别乱买,紧凑型SUV油耗排行,途岳夺冠,CR-V第15,途胜第25名.
