过去,自动驾驶领域有两条相对独立的技术路线:
VLA(视觉-语言-动作):负责看懂场景,直接输出驾驶动作
世界模型:负责预测接下来会发生什么,模拟未来场景
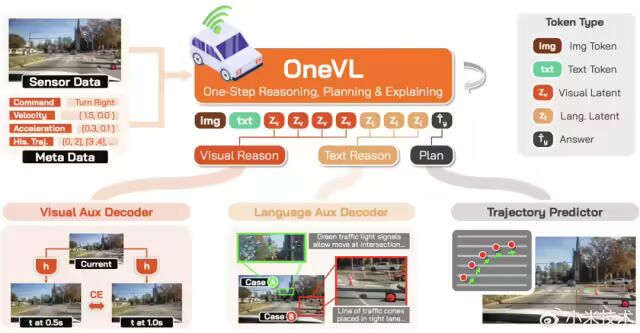
Xiaomi OneVL 做了一件开创性的事——通过“潜空间推理”,首次把这两条路线塞进了同一套框架。它既有 VLA 的强推理能力,又大幅提升了推理的速度和精度。
用官方的话说,这是一种“一步式潜空间语言视觉推理框架”,在速度上对齐“仅答案”预测,在精度上超越显式的思维链方案。
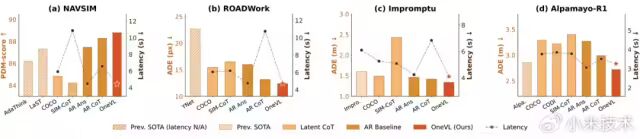
成绩单有多硬?
在覆盖感知、推理与规划的主流测试基准上,Xiaomi OneVL 全面刷新了潜推理方法的性能上限。
更重要的是,它提供了双维度可解释性:
🗣️语言维度:能用文字说明“为什么这样开”
👁️视觉维度:能用预测画面展示“接下来会发生什么”
这对于自动驾驶的安全性和信任度来说,意义非凡。
开源,开得很彻底
小米不仅把论文发了,还把模型权重、训练代码、推理代码全部开源,可直接取用:
| 资源 | 链接 |
|---|
| 📄 技术报告 | https://arxiv.org/abs/2604.18486 |
| 🌐 项目主页 | https://Xiaomi-Embodied-Intelligence.github.io/OneVL |
| 💻 开源代码 | https://github.com/xiaomi-research/onevl |
在自动驾驶的星辰大海里,小米这次递出来的不只一个模型,更是一套“统一语言”。当 VLA 和世界模型不再各说各话,当决策既能讲清道理又能画出未来,我们离真正可信赖的智能驾驶,又近了一步。开源,让这条路走得更快。
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
