先看一段视频:
目前市面上最常见的商用辅助驾驶,一般都会遇见两种情况,要么反应慢半拍,前车急刹还在往前冲;要么突然猛打方向、莫名急停。
自动驾驶大模型的推理,一直在快和准之间做取舍。这次小米推出了Xiaomi OneVL一步式潜空间语言视觉推理框架,目的就是解决上面说的问题。它直接把全套模型权重、训练和推理代码全部开源,全世界开发者免费用。
一、过去的自动驾驶,为啥又慢又笨?
先打个最通俗的比方:自动驾驶大模型做决策,就像学生做数学题。
过去行业有两种主流解法:
- 显式思维链(CoT):相当于按步骤来。每一步推理要明明白白写出来,答案准,但写步骤太费时间。放到开车上,就是每一个决策都要逐字逐句想清楚再说,延迟高,遇到突发情况反应不过来。
- 仅答案预测:相当于蒙答案。跳过部分思考过程,直接出结果。速度是快了,但对错全靠运气,完全没有因果判断能力。你不知道它为啥突然变道,也不知道它下一秒会不会撞墙。
后来有个折中方案:潜空间思维链(Latent CoT)。在心里打草稿,不用写出来,直接出答案。这样既能保留思考过程,又能压缩时间。
但之前的潜空间方案,始终没突破瓶颈:要么草稿打得太潦草,答案精度还是赶不上写步骤的学霸;要么还是要分步骤打草稿,速度上不去。
小米OneVL这次改了种方式:心里打草稿又快又准,第一次全面超过了写步骤的显式推理,速度还和蒙答案的学渣一样快。
二、让模型“心里有数”,一步想清楚
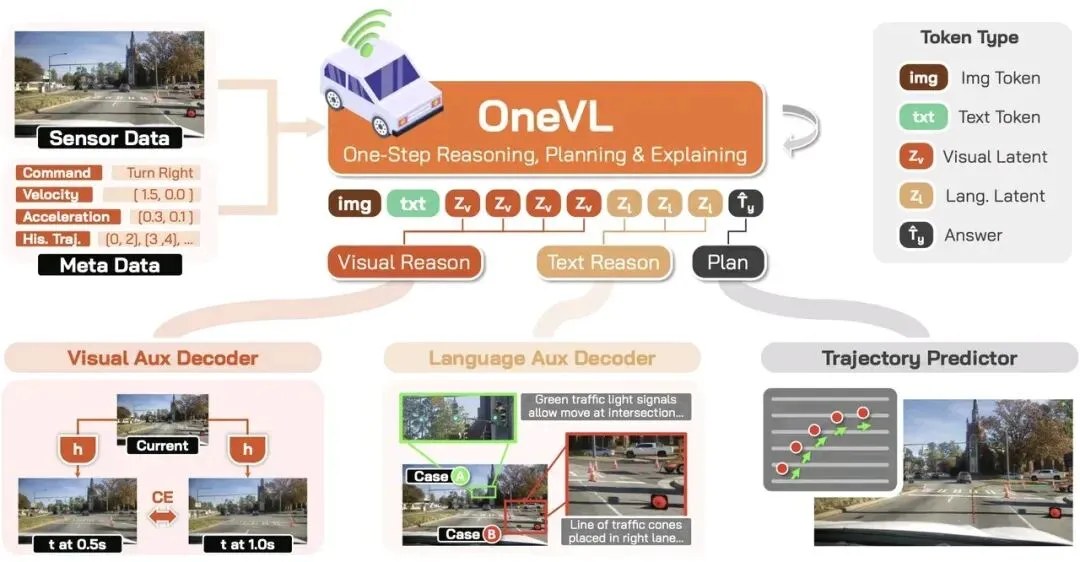
OneVL是它第一次把自动驾驶领域两条完全独立的技术路线——VLA和世界模型,通过潜空间推理统一到了同一套框架里。
简单说,它让自动驾驶模型像老司机一样思考:不只是看见眼前的路,还要预判接下来会发生什么,然后做出最优决策。
主要依靠三个核心技术:
1. 两套系统,各司其职
人在开车的时候,脑子里同时在想两件事:一是别人会怎么动,二是我该怎么开。
OneVL给模型也配了两种方式:
- 视觉潜空间token:专门编码场景的物理因果,比如车辆运动、道路变化、障碍物移动;
- 语言潜空间token:专门编码驾驶意图的语义,比如右转、保持车速、避让行人。
它不用把这些想法逐字念出来,而是在自己的机器内部语言里快速整合,做到心里有数,而不是边说边想。
2. 训练时带双导师,推理时全丢掉
很多人担心心里打草稿会变成黑箱,不知道模型是怎么想的。小米的解法很聪明:训练的时候加监督,推理的时候全扔掉。
训练阶段,给模型配两个“监考老师”:
- 视觉解码器:盯着它预判未来0.5秒、1秒的画面对不对,这是世界模型能力;
- 语言解码器:盯着它的思考过程能不能翻译成人类能懂的文字,保证它不是瞎想。
等模型练熟了,真正上路的时候,这两个解码器全部移除,额外开销就没了。既保证了训练时的精度和可解释性,又实现了推理时的极致速度。
3. 预填充式一步推理,快到极致
之前的潜空间推理,还是要一步步打草稿。小米直接搞了个一次性打包思考:把所有要用到的历史轨迹、传感器数据、驾驶指令,一次性预填充进上下文,并行计算,一步就出最终决策。
速度有多夸张?
- 比显式CoT最高快2.3倍;
- 挂载轻量化变体后,延迟仅0.24秒(4.16Hz);
- 这个速度,只有传统VLA自回归推理的5.4%,完全满足量产车的实时性要求。
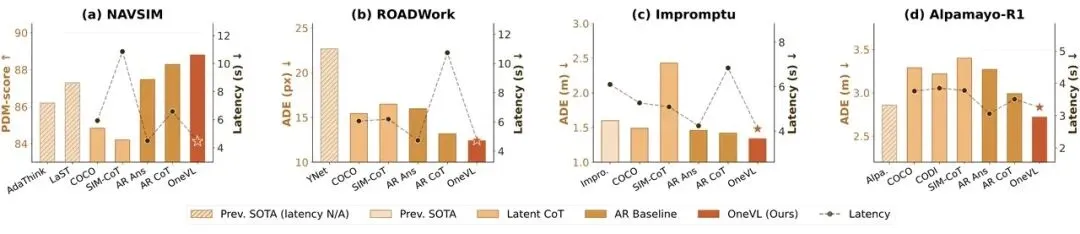
所有测试全第一,量产直接能用
技术好不好,数据说了算。在涵盖感知、推理、规划的所有主流自动驾驶基准测试上,OneVL数据确实不错:
- ROADWork、Impromptu、Alpamayo-R1三项基准全部达到SOTA;
- 在最核心的NAVSIM测试中,PDM-score达到88.84,首次在潜空间推理中超越显式CoT;
- 是目前唯一一个在所有基准上全面超越显式自回归CoT的隐式推理方法。
更重要的是,它解决了自动驾驶最让人诟病的“黑箱问题”。虽然推理的时候不用写步骤,但你随时可以让它把心里的草稿拿出来:
- 既能用文字告诉你:因为绿灯亮了,且路口无行人,所以我将以1.5m/s的速度通过;
- 还能给你展示它预判的接下来1秒的路况画面,让你直观看到它觉得接下来会发生什么。
三、全面开源
最让人意外的是,小米没有把这个技术藏起来,而是直接全面开源了模型权重、训练代码和推理代码。
这意味着,全世界的车企、科技公司、开发者,都可以免费用OneVL来优化自己的自动驾驶系统。不用再从零开始摸索潜空间推理的路线。
这不是一次简单的技术发布,而是给整个自动驾驶行业指了一条新路:原来VLA和世界模型不用各走各的,潜空间推理真的能做到“精度超越显式CoT,速度对齐仅答案预测。
PS:


 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
