中科大CLOVER:让自动驾驶不只是「给答案」,而要学会反复想、认真选、继续改
- 2026-05-17 19:45:17
点击下方卡片,关注“自动驾驶之心”公众号
作者 | Sining Ang等
编辑 | 自动驾驶之心
本文只做学术分享,如有侵权,联系删文
>>自动驾驶前沿信息获取→自动驾驶之心知识星球
如果把自动驾驶规划想象成一次开车决策,它其实不像考试里的单选题,更像现实中的临场判断。
前车突然慢下来,要不要跟着减速?路口还有几秒绿灯,要不要继续通过?旁边有车靠近,是保持车道中心,还是稍微留出更多横向空间?这些问题往往没有唯一标准答案。一个成熟司机不会只记住过去某个人在同一位置怎么开,而是会在脑子里快速形成几个备选方案,再选出最稳妥的一个。
端到端自动驾驶规划也面临类似问题。模型不能只“预测一条轨迹”,它必须学会提出候选、评估候选、选择候选,并在反馈中继续改进候选。
这就是 CLOVER 想做的事。
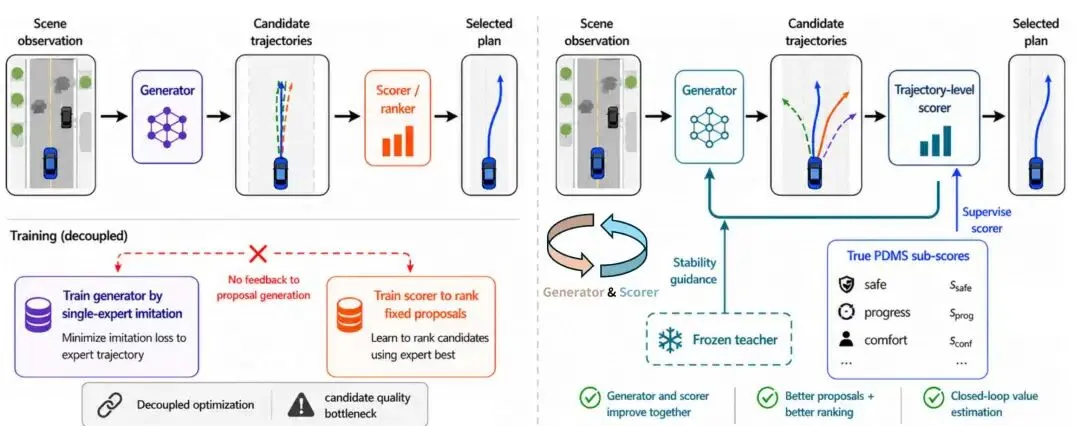
CLOVER 的全称是 Closed-Loop Value Estimation & Ranking。如果翻译得直白一点,就是:让自动驾驶规划形成一个“闭环价值评估与排序”的系统。
它不是简单说“我们要生成更多轨迹”,也不是把重点放在某一种伪标签构造技巧上。CLOVER 真正想强调的是:生成器和评分器不能各干各的,它们应该在训练中形成闭环。
项目地址:https://github.com/WilliamXuanYu/CLOVER 论文标题:CLOVER: Closed-Loop Value Estimation & Ranking for End-to-End Autonomous Driving Planning 论文链接:https://arxiv.org/abs/2605.15120
1. 为什么只会“模仿”还不够?
很多规划模型训练时,会学习日志里的人工驾驶轨迹。这当然有用,因为人类驾驶数据提供了稳定的先验:什么样的速度、转角和位置变化大致合理。
但真实规划的难点在于,历史轨迹并不总是唯一答案。一个场景下,继续前进、轻微减速、保守让行,都可能是合理选择。尤其在评测中,模型面对的是安全、可驾驶区域、碰撞风险、进度、舒适性等综合指标,而不是“和历史轨迹有多像”。
如果模型只盯着一条历史轨迹,它很容易变成一个“复读机”:输出看起来很接近日志,但未必是当前规则评价下最好的规划。
更微妙的是,很多先进规划器其实已经不是只输出一条轨迹了。它们会生成多条候选轨迹,再由评分器挑选一条。这听起来很像人在开车前“想几种方案”。但问题是,评分器往往只在最后一步出现,像一个站在终点的裁判。它会说哪条轨迹好,却没有充分告诉生成器:下次你应该多生成什么样的轨迹。
CLOVER 要把这个裁判请到训练场里。
2. 生成器和评分器,要形成一个循环
我们可以把 CLOVER 理解成四步:
生成器提出 64 条候选轨迹; 评分器估计每条轨迹的规划价值; 系统根据价值排序选择最终轨迹; 训练时,评分器选出的高价值候选反过来指导生成器。
这个循环看似简单,但意义很大。过去,生成器可能只知道“人类过去这样开过”;现在,它还会收到来自规划评价的反馈:哪些候选更安全,哪些候选更舒适,哪些候选更能完成路线目标。
换句话说,CLOVER 让自动驾驶模型不只是“照着过去画一条线”,而是开始学习“什么样的未来更值得选择”。
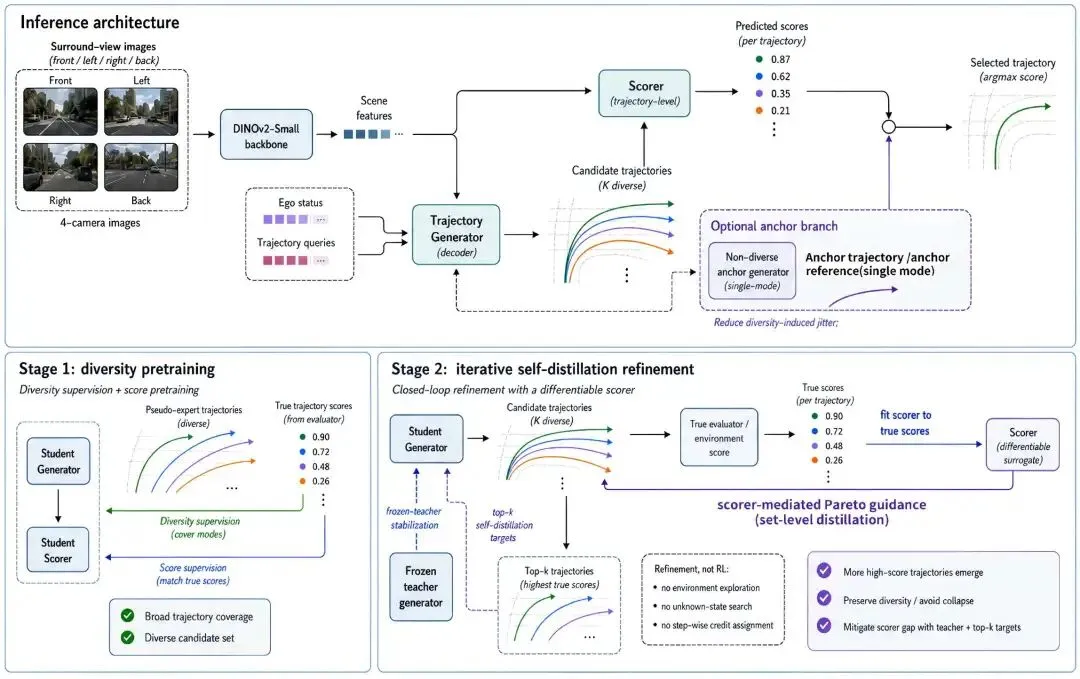
3. 第一步:先让模型有足够多可选方案
想象一个人去餐厅点菜,如果菜单上只有一道菜,那他再懂美食也没法比较。自动驾驶规划也是一样。如果生成器只会给出一堆挤在一起、几乎相同的候选轨迹,评分器再聪明也选不出真正更好的方案。
所以 CLOVER 第一阶段先做一件事:扩展候选空间。
它利用训练阶段可获得的路线中心线、可驾驶区域、未来障碍物占用等信息,生成多种可解释的候选轨迹。比如:
稍微靠左或靠右一点; 保持速度、加速或减速; 提前刹车; 停一下再走; 在边界场景中尝试不同进度。
这些轨迹不是随便生成的。它们会经过可驾驶区域和占用检查,再由规则 evaluator 评分。最终留下的,是一组既有多样性、又有规划意义的候选轨迹。
这里很容易被误解为“CLOVER 主要就是做伪专家标签”。但更准确的说法是:这一步是在为闭环训练铺路。它给生成器一个更宽的候选底盘,让后面的评分器反馈有地方落下去。
4. 第二步:让评分器不只是打分,而是当教练
候选多了以后,新的问题来了:哪些候选值得继续学习?
CLOVER 的做法是训练一个 trajectory-level scorer。这个评分器不是凭空猜好坏,而是学习真实规划 evaluator 给出的子分数,例如安全、可驾驶区域、TTC、进度、舒适性等。
然后,评分器会从候选集合中选出两类重要目标:
top-k 高价值候选; vector-Pareto 候选。
top-k 很好理解,就是综合分数高的候选。vector-Pareto 则更像现实驾驶中的多种合理取舍:有的轨迹更保守,有的轨迹进度更好,有的轨迹更舒适。自动驾驶规划不是单目标游戏,不能只追一个分数,把所有候选压成一种行为。
这就是为什么 CLOVER 不直接让生成器最大化某个 learned score。评分器不是绝对真理,如果盲目追分,模型可能学会钻评分器误差的空子,或者把候选都挤到一个狭窄模式里。
CLOVER 选择更稳妥的方式:保守闭环自蒸馏。评分器负责挑出一组值得学习的候选,生成器在稳定约束下慢慢向这些目标靠近。
5. “评分器不完美”怎么办?
这个问题很现实。任何 learned scorer 都会有误差。那它还能指导生成器吗?
CLOVER 的回答是:可以,但不要求它完美。
评分器不需要每次都把所有轨迹从最好到最差排得完全正确。它只需要做到一件事:它选出来的那组候选,在真实 evaluator 下整体上更好。
论文把这个条件称为 selected-set enrichment。通俗讲,就是评分器选出来的篮子里,好轨迹比例要比原来的候选池更高。只要这个条件成立,并且生成器每次更新不要太激进,那么生成器就会逐步把更多概率质量放到高质量轨迹区域。
实验也支持这一点。在 12,146 个 NAVSIM 场景中,当评分器预测分数高于 0.95 时,对应候选的真实平均分达到 0.9753,真实分数不低于 0.90 的比例达到 96.69%。这说明评分器虽然不必全局完美,但作为“挑选训练目标的教练”是有效的。
6. CLOVER 的成绩
CLOVER 在多个规划评测上取得了强结果:
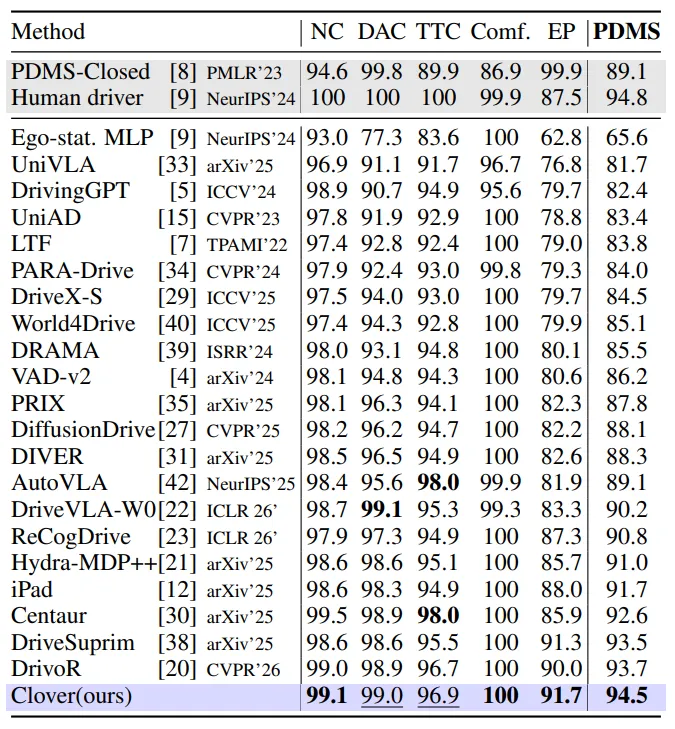
在 NAVSIM v1 上,CLOVER 获得 94.5 PDMS,超过强 baseline DrivoR 的 93.7,接近 human-driver reference 的 94.8。在 NAVSIM v2 上,CLOVER 达到 90.4 EPDMS。在更难的 NavHard two-stage split 上,CLOVER 达到 48.3 EPDMS。
这些数字说明 CLOVER 不只是在普通场景里表现好,也能在更具挑战性的评测设置下保持竞争力。
7. 怎么读这些指标?
如果不是长期关注自动驾驶规划,PDMS、EPDMS、NavHard 这些名字可能会显得有点硬。我们可以把它们理解成不同难度和不同侧重点的“规划考试”。
PDMS 更关注一条规划轨迹是否满足安全、可驾驶区域、碰撞风险、舒适性和进度等要求。它不是简单问“你和人类轨迹差几米”,而是更接近问“你这样开,是否真的像一个合格规划器”。
EPDMS 是更扩展的版本,会加入更多评价维度,尤其是和时间一致性、舒适性相关的要求。对 proposal-selection 方法来说,这类指标更难,因为候选轨迹之间如果切换不稳定,即使每一帧看起来都不错,整体舒适性也可能被扣分。
NavHard 则更像是难题集。它把规划器放到更具挑战性的场景里,考察系统在复杂交互、边界约束和长尾情况中的表现。
所以,CLOVER 在 NAVSIM v1、NAVSIM v2 和 NavHard 上同时取得强结果,说明它不是只适配某一种评分方式,而是在不同规划评价维度下都能保持稳定。
还有一点值得注意:CLOVER 的部署阶段并不需要真实 evaluator。真实 evaluator 只在训练时提供监督,帮助训练可部署的 scorer 和 generator。最终上线时,模型仍然只是根据图像和车辆状态生成候选轨迹,再用学习到的评分器完成排序。
这使得 CLOVER 更像一种训练范式,而不是一个昂贵的推理后处理系统。
8. 更重要的是:候选轨迹整体变好了
如果一个方法只是最后排序更准,生成器本身没有变化,那么它的故事并不完整。CLOVER 的一个重要结果是:它确实改变了候选轨迹集合。

论文分析了每个场景 64 条候选轨迹。结果显示,Stage 1 像是在“打开思路”:Oracle@64 从 0.9933 提升到 0.9976,Pairwise ADE 从 1.80 提升到 5.97,说明候选空间明显变宽。
但只打开思路还不够。Stage 1 也会引入一些低分尾部。于是 Stage 2 接着做“提纯”:Selected PDMS 提升到 0.9448,64 条候选的平均 PDMS 提升到 0.8277,低分候选数量降到 6.83。
这很像一个会反思的驾驶系统:先想到更多可能,再从反馈中学会哪些可能更值得保留。
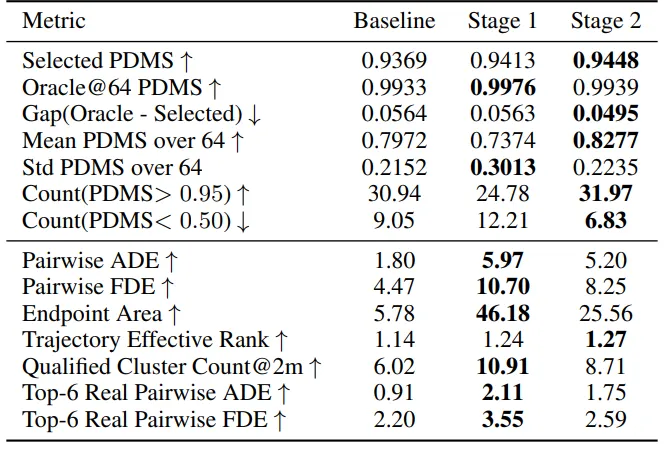
9. 图里能看到什么?
在候选轨迹可视化中,DrivoR baseline 的很多候选轨迹会集中在比较窄的区域里。它们看起来像是同一种想法的细微变化:位置差一点、速度差一点,但整体行为模式接近。
CLOVER 的候选轨迹则明显展开得更充分。它不仅能覆盖当前车道中的不同横向位置,也能覆盖不同进度和速度策略。有些轨迹更积极,有些轨迹更保守,但很多仍然保持较高真实 evaluator 得分。
这一点非常重要。多样性本身并不一定有价值。如果一个模型只是生成很多乱七八糟的轨迹,当然也会显得“很分散”,但规划质量不会提高。CLOVER 追求的是高质量多样性:候选之间有差异,同时这些差异仍然落在可行、安全、有规划意义的范围内。
这也是 Stage 1 和 Stage 2 的分工。Stage 1 负责把可能性打开,Stage 2 负责把打开后的空间整理好。前者像头脑风暴,后者像评审和修改。
10. 消融实验告诉我们什么?
组件消融很清楚地说明,两步都重要。
| 94.5 |
只扩展候选空间,有提升;只做闭环精炼,也有一点提升;两者结合,效果最好。这说明闭环反馈需要一个足够好的候选基础,而宽候选空间也需要后续精炼才能转化为最终规划收益。
Stage-2 的训练方式也很重要。如果试图把 scorer 和 generator 一次性联合更新,结果会崩;如果只做普通自蒸馏,效果会停在 93.8 到 94.0;完整的交替闭环精炼才能达到 94.5。
这背后的直觉很朴素:教练自己也要不断校准。评分器先根据真实 evaluator 学习当前候选的价值,再指导生成器更新;生成器变了以后,评分器又需要重新适应新的候选分布。
11. 它和强化学习有什么不同?
看到“评分器指导生成器”,很多人可能会想到强化学习里的 actor-critic。但 CLOVER 并不是强化学习方法。
强化学习通常需要与环境交互,通过试错探索获得 reward,再更新策略。CLOVER 不做在线试错,也不让车辆在环境中反复尝试。它使用的是已经记录下来的场景,并在这些场景上离线计算规则 evaluator 反馈。
因此,CLOVER 更像是把规划评测器的知识转化成训练信号:scorer 学会近似 evaluator 的子分数,generator 再通过 scorer-selected targets 改进候选分布。
这种方式有两个好处。第一,它避免了在线探索在自动驾驶中可能带来的安全和成本问题。第二,它与现有 logged data 和规则评价体系兼容,可以作为 proposal-selection planner 的训练增强模块。
当然,这也意味着 CLOVER 的能力边界仍然依赖离线场景覆盖和 evaluator 设计。未来如果有更强的场景生成、世界模型或序列级评价器,闭环价值估计还可以继续扩展。
12. 这项工作的意义
CLOVER 的意义不只是刷新一个分数。它指出了端到端自动驾驶规划中一个值得重视的训练范式:
规划器不应该只是从数据中复现历史行为,而应该在候选生成、价值评估、排序选择和自我改进之间形成闭环。
这个闭环有几个优点:
它利用规则 evaluator 的规划知识,但部署时不需要真实 evaluator; 它让 scorer 不只是推理阶段的后处理,而是训练阶段的反馈源; 它改善的是候选分布本身,而不是只换一个 top-1 选择器; 它通过保守蒸馏降低了评分器误差被放大的风险。
13. 总结
CLOVER 可以用一句话概括:
让自动驾驶规划先提出多个可行未来,再用规划价值评估它们,并把评估结果反过来用于生成更好的未来。
它让端到端规划从单向的“输入图像,输出轨迹”,变成一个更接近决策系统的过程:生成、评分、排序、反馈,再生成。
这也是 CLOVER 最有辨识度的地方。它不是单纯多生成轨迹,也不是把伪专家作为主角,而是把闭环价值估计与排序放在了端到端自动驾驶规划训练的中心。
自动驾驶之心
求点赞

求分享

求喜欢

随机文章
-
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
- 方程豹钛7把价格打进20万内,家用插混SUV买它前先想清楚一件事
- 优惠倒计时!【梦幻草原,全程SUV】海拉尔-莫日格勒河-恩和-黑山头-满洲里,呼伦贝尔5天4晚!
- 林肯冒险家油电混动:想买第一台豪华SUV,别只看车标,也要看它省下来的日常成本
- 暑假活动开始了:第一波福利,轿车充500送200,可以洗23次,每次单价21.7…
- 奥迪Q8不是给所有家庭的豪华SUV,90万预算前先想清楚这件事
- 100 万预算:买顶配豪华家用轿车?还是买优质股权?
- 十万出头!奇瑞这台插混,直接把家用SUV的底裤卷掉了
- 好看更好开的复古SUV 马来西亚车媒试驾iCAR V27
- 20-30万,3款大六座SUV,配置技术都很高,家用很香
- 家用SUV“三剑客”深度横评:本田CR-V、大众途观L与丰田荣放,谁才是你的家庭最优解?
