
🐉 龙哥读论文知识星球来了!公众号每日8篇拆解不够看?星球无上限更AI领域论文、资讯、招聘、招博、开源代码,一站式干货,每日2分钟刷完即赚!👇扫码加入「龙哥读论文」知识星球,前沿干货、实用资源一站式拿捏~

龙哥推荐理由:
这篇文章提出了一个非常务实且理论上自洽的端到端自动驾驶规划框架。它直面了"模仿训练"与"规则评估"之间的根本矛盾,并通过闭环自蒸馏的方式,让一个不完美的评分器也能有效引导生成器产生更优质的轨迹。这篇论文不仅在NAVSIM等主流基准上刷新了SOTA,更提出了"选择性集富集"的严格条件,为训练-评估不对齐问题提供了新的解决思路和理论解释。
原论文信息如下:
论文标题:
CLOVER: Closed-Loop Value Estimation & Ranking for End-to-End Autonomous Driving Planning
发表日期: 2026年05月
发表单位: 清华大学AIR(智能产业研究院)联合中国科学技术大学自动化系、北京航空航天大学等
原文链接: https://arxiv.org/pdf/2605.15120v1.pdf
开源代码链接: https://github.com/WilliamXuanYu/CLOVER
自动驾驶规划困境:模仿专家为何“高分低能”?
先问个问题:假如你是个端到端自动驾驶规划模型,你每天的任务就是看传感器数据,然后输出一条未来4秒的行驶轨迹。你的老师(训练目标)只有一个——最小化与人类司机驾驶轨迹的位移误差。听起来挺合理对吧?但真正上路测试时,评估你的是一套叫 PDMS(Planning-Driving Metric Score,规划驾驶度量分数)的规则指标,它考察安全性、可通行性、进度和舒适度。一个与人类轨迹贴得很近的轨迹,可能因为稍偏离车道或与障碍物太近而得分很低;相反,一个离演示轨迹较远的备选方案,反而可能安全高效、得分很高。这就造成了经典矛盾:模仿训练与规则评估的不对齐(training–evaluation mismatch)。
这个问题在“提议选择式规划器”(proposal-selection planners)中尤其突出。这类方法先生成多个候选轨迹,再用一个学习得到的评分器/排序器选出一条最终路径。其最终性能受两个因素牵制:生成器能否覆盖高质量备选?评分器能否准确识别它们?如果只模仿单条人类轨迹,候选集很容易坍缩到单一行为模式,即使同一场景下减速、保持速度或采取不同交互策略都可能合理。而就算有了好的候选集,如果评分器搞反了安全与冒险,最终选择也会翻车。所以,要解决这个困境,必须同时提升候选集覆盖率和评分器质量。
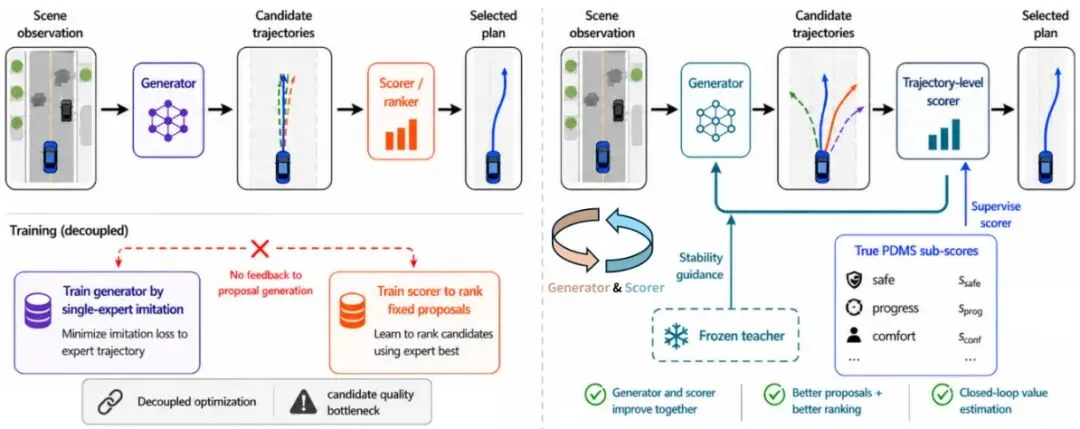
图1: CLOVER 在提议生成与轨迹排序之间构建闭环。左侧:传统提议选择规划器生成候选轨迹并利用学习评分器选择最终方案,但训练时生成器仅通过单专家模仿优化,排序反馈并未显式地将提议分布向更高价值区域重塑。右侧:CLOVER 训练一个轨迹级评分器预测真实规划度量子分数,并通过教师引导的自蒸馏保守地优化生成器。闭环设计提升了候选集覆盖率和排序质量,增加了高质量轨迹被生成和选中的机会。CLOVER破局:构建闭环价值评估框架,优化提议生成与排序
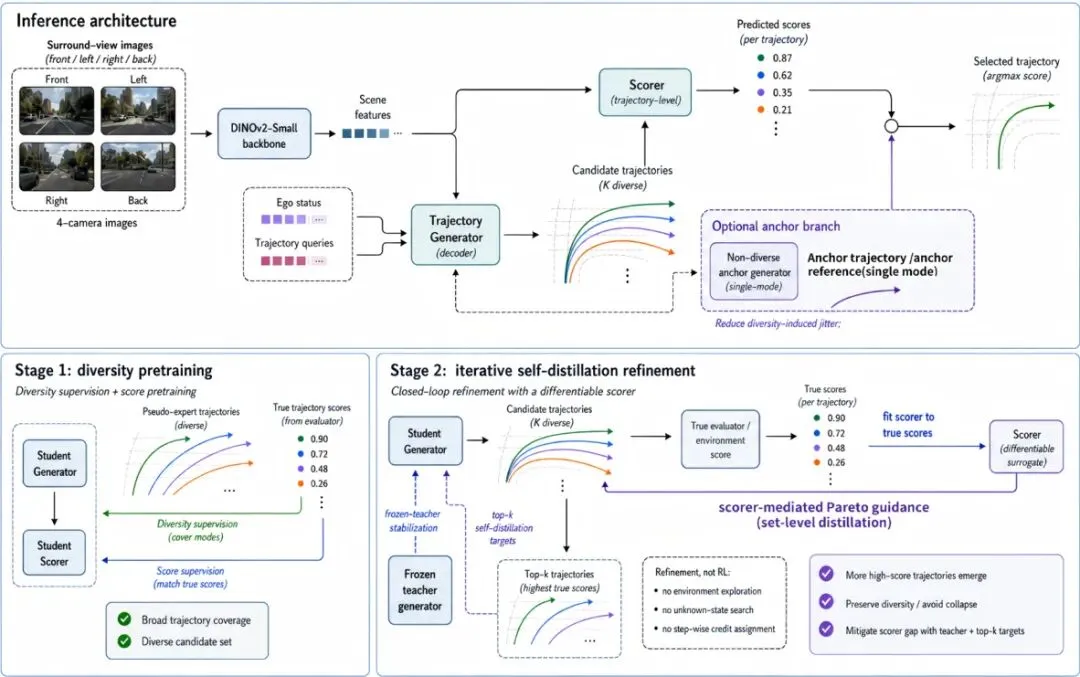
针对上述问题,清华大学AIR团队联合中科大、北航等机构提出了 CLOVER(Closed-LOop Value Estimation & Ranking,闭环价值估计与排序框架)。它的核心思路很直接:让生成器和评分器通过“真实评估器”(rule-based evaluator)的真值反馈进行闭环协作,而不是各自孤立训练。CLOVER 采用轻量级生成器—评分器架构:生成器(Generator)输出 K 个候选轨迹,评分器(Scorer)为每个候选预测规划度量子分数,推理时根据组合预测分数排序并选择最优。所有训练过程仅在离线场景下进行,无需在线环境交互。
具体地,给定观测 o(多视角图像+自车状态),生成器产生 K 个候选轨迹:
其中 Γ_PDMS 是 PDMS 评估规则。训练时,真实评估器 E 提供真值目标用于训练评分器,但推理时不需要 E。图2给出了整体框架。
图2: CLOVER 概述。推理时,多视角图像和自车状态编码为场景特征,生成器产生 K 个候选轨迹,评分器通过预测规划度量子分数进行排序。阶段1:利用评估器过滤的伪专家轨迹扩展提议覆盖。阶段2:通过教师引导的 top-k 和向量帕累托蒸馏以及稳定性正则化,拟合评分器到评估器真值子分数并优化生成器。对于 EPDMS 评估,可选的锚点辅助软重排序模块用于减少近零候选间的多样性抖动。两阶段训练:从扩大候选覆盖到保守自蒸馏的精妙设计
CLOVER 的整个训练分为两大阶段,第一阶段解决“候选类别单一”的问题,第二阶段解决“评分器有效引导生成器”的问题。先来看阶段1。
单条轨迹的模仿训练无法覆盖多模态的驾驶行为。CLOVER 的做法是:为每个场景构建一个训练时专用的“伪专家集合”(pseudo-expert set)。这些伪专家不是简单扰动人类轨迹,而是从可解释的候选轨迹族中生成,利用训练时可获得的中心线、可通行区域地图、未来障碍物占用等先验信息。候选池覆盖了不同横向偏移、加速减速、停-行策略、接近-制动边界等情况。通过轻量级可通行区域和占用检查预过滤,再用评估器评分,最后采用覆盖感知策略(基于评分模式和分箱的贪婪最远点采样)选出至多 M 个伪专家。
图4 展示了伪专家的可视化示例。候选轨迹按真实 PDM 分数着色,高评分候选提供了多模态监督,低评分和边界候选有助于暴露生成器和评分器对不同边缘情况的处理。
图4: 伪专家轨迹候选可视化。展示了在相机视图和鸟瞰图中的代表性伪专家轨迹池,按真值 PDM 分数着色。高评分候选提供了可行的多模态监督,低评分和边界候选帮助暴露生成器和评分器对可通行区域、碰撞、进度和舒适度变化的表现。这些伪专家仅用于阶段1训练,推理时不需使用。
阶段1的损失函数包括三部分:对人类轨迹的模仿损失 L_gt(保留驾驶先验),对伪专家集合的覆盖损失 L_pe(鼓励提议覆盖多模态),以及对评分器的预训练损失 L_score(用评估器真值分数训练评分器)。这一阶段本质上将单轨迹监督扩展到了集合级的覆盖监督,显著提升了候选集的质量上界(oracle upper bound)。
阶段1虽然扩大了候选覆盖,但评分器并未反馈给生成器;如果直接最大化学习分数,容易利用评分器误差或导致多样性坍塌。CLOVER 采用一种交替自蒸馏机制:首先固定生成器,用当前生成的候选集训练评分器(评分器阶段,最小化 L_critic,即预测子分数与评估器真值的误差);然后固定评分器,用教师模型(冻结的生成器)产生提议,评分器从中选出 top-k 和向量帕累托(vector-Pareto)集作为目标,让学生生成器去蒸馏这些目标(生成器阶段)。特别地,还加入了稳定性损失(鼓励学生提议不偏离教师提议太远),构成保守更新。
生成器阶段中,蒸馏特定目标集 A 的集合覆盖损失为:
总的生成器损失 L_gen 包含人类轨迹损失、top-k 蒸馏、帕累托蒸馏和稳定性项。通过这种交替优化,评分器逐步修正生成器,同时稳定性项防止分布漂移,就构成了“保守闭环自蒸馏”。
理论支撑与实证:不完美的评分器如何有效引导生成器
一个关键问题:评分器不可能完美,它指导的生成器更新靠谱吗?CLOVER 提供了一套简洁的理论证明:核心条件是“选择性集富集”(selected-set enrichment)。也就是说,评分器不需要对所有轨迹排序正确,只需要它选出的目标集(top-k 或帕累托集)在真值评估器下统计上比当前提议分布包含更多高质量轨迹即可。定理1给出了严格的条件。
设当前提议的经验分布为 μ_t^o,评分器选择的目标集分布为 ν_t^o,高分数区域 H_o = {τ: R*(o,τ) ≥ r_high}。定义 p_t = μ_t^o(H_o),q_t = ν_t^o(H_o)。若有富集条件 q_t ≥ p_t + ξ_t (ξ_t > 0),且保守更新约束 TV(μ_{t+1}^o, (1-α_t)μ_t^o + α_t ν_t^o) ≤ η_t,则:
只要 α_t ξ_t > η_t,阶段2就能增加高质量轨迹的概率质量。类似地,如果期望分数也满足富集条件(期望分数差 β_t > 0),则更新后期望分数也会提升。
论文进一步提供了实证支持:在12,146个NAVSIM场景中,每个场景64个候选,总体高分候选比例为35.42%;而评分器高置信度(预测得分≥0.95)选中的候选,真值满分(R*=1)的比例高达69.74%,富集差距约34.32%。这直接满足了定理的条件。相关诊断表格如下。
表14: 选择性集富集的实证验证。最坏情况评分器校准过于保守,但高概率可分性、高分数精确度和评分器 top-k 覆盖率支持阶段2蒸馏所需的富集条件。
这些结果说明,CLOVER 的阶段2并非依赖一个完美评分器,而是利用了一个统计上富集的目标选择机制,再结合保守更新,实现了可靠的质量提升。同时,论文在附录中提供了更丰富的理论分析,包括近似单调性、评分器重拟合和帕累托一致性等。
刷新多项SOTA:实验结果与深度剖析
CLOVER 在多个基准上进行了全面评估,包括 NAVSIM v1(PDMS 指标)、NAVSIM v2(EPDMS 扩展指标)、NavHard(困难场景)以及 nuScenes 开环规划。所有实验均基于 DrivoR 风格的生成器-评分器架构(DINOv2 Small 视觉编码器 + LoRA,64 个轨迹提议,4秒预测时域,0.5秒步长)。
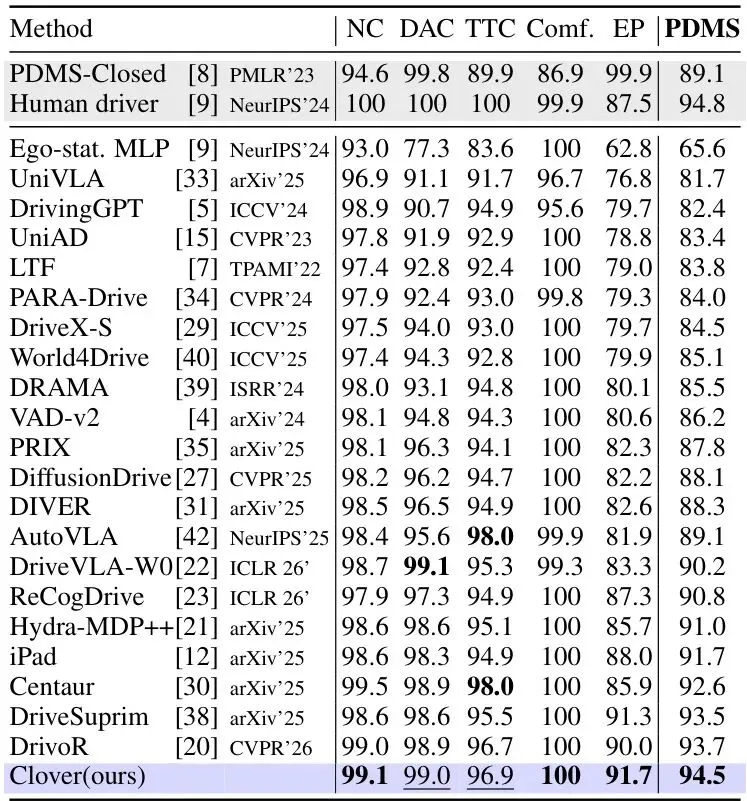
以下是 NAVSIM v1 上的结果(表1)。CLOVER 以 94.5 PDMS 超越所有已发表方法,仅次于人类驾驶员参考值。各子分数均排名前列。
表1: NAVSIM v1 基准。与已发表及近期方法在官方 PDMS 指标下的对比。所有列越高越好。CLOVER 取得最佳 PDMS,各子分数排名第一或第二,几乎达到人类驾驶员参考水平。
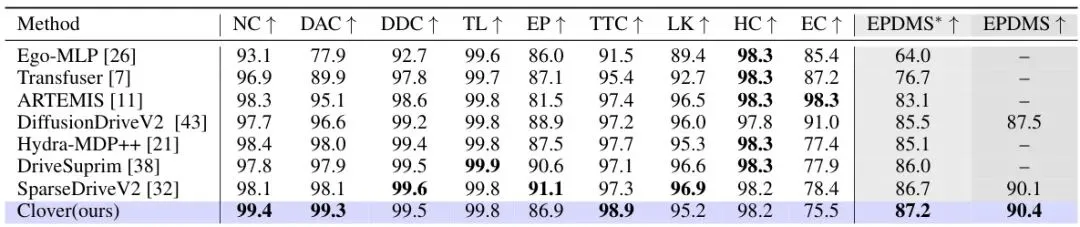
在 NAVSIM v2 EPDMS 上(表2),CLOVER 获得 90.4 EPDMS(更新版评估代码),同样处于领先水平。
表2: NAVSIM v2 EPDMS 在 navtest 上的对比。EPDMS* 表示使用原始评估代码(未应用人类行为过滤修正)的结果,EPDMS 为更新官方实现的结果。所有列越高越好。
在更困难的 NavHard 两阶段评估上(表3),CLOVER 以 48.3 EPDMS 匹配了最强已有报告结果。
表3: NAVSIM v2 navhard-two-stage 对比。Stage-1 和 Stage-2 列报告了两阶段评估的子分数,EPDMS 为最终聚合分数。所有列越高越好。
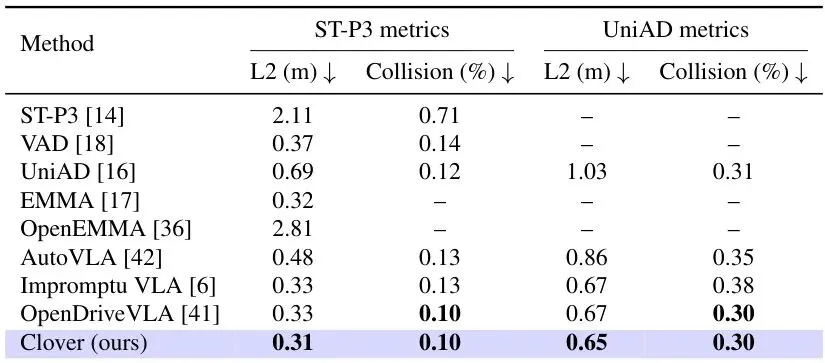
在 nuScenes 开环评估上(表4),CLOVER 取得了最低的 L2 误差和最佳碰撞率,进一步验证了方法的通用性。
表4: nuScenes 开环规划结果。按照 ST-P3 和 UniAD 协议报告 L2 位移误差和碰撞率。所有指标越低越好。该基准用于补充开环验证。
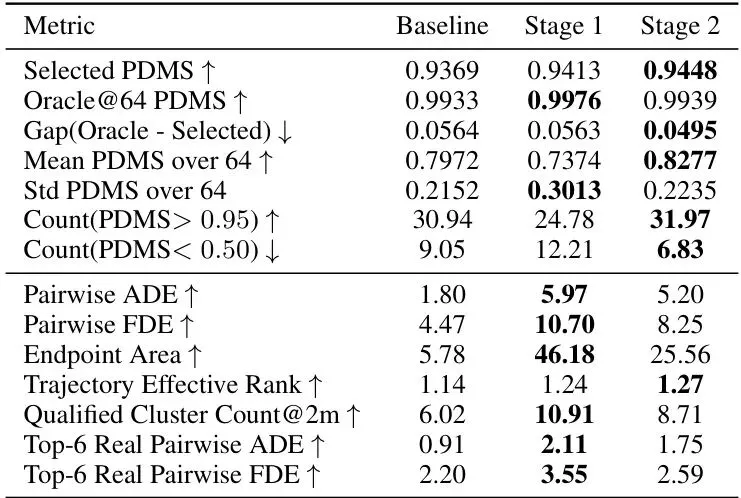
消融实验进一步揭示了各组件的贡献。表5展示了阶段级提议质量和多样性分析:阶段1显著扩大了提议空间并取得最高预言上界(oracle upper bound),阶段2在保留多样性的同时优化了选定分数和整体质量。
表5: 阶段级提议质量与多样性分析。指标基于 12,146 个公共场景的 64 个生成提议。阶段1极大扩展提议空间并达到最高预言上界,阶段2优化了扩展分布,获得最佳选定分数和提议集质量,同时保持远高于基线的多样性。
表6和图3的定性比较也体现了CLOVER在多样性上的显著优势:与DrivoR基线相比,CLOVER的候选轨迹覆盖了更宽的可行分支,并且许多多样化候选在评估器下仍保持高分。
图3: 提议多样性定性对比。与 DrivoR 基线相比(候选集中于狭窄模式),CLOVER 覆盖了更宽的可行轨迹分支。许多多样化候选在评估器下仍然保持高分,说明额外多样性并非来自低质量异常点。
表6的主要组件消融进一步确认:伪专家多样性监督提供了更强的提议集,而闭环精炼在扩展的提议分布基础上最有效。
表6: NAVSIM v1 上的主要组件消融。分别消融伪专家多样性监督和阶段2闭环精炼。多样性监督提供了更强的提议集,闭环精炼在扩展的提议分布基础上最有效。
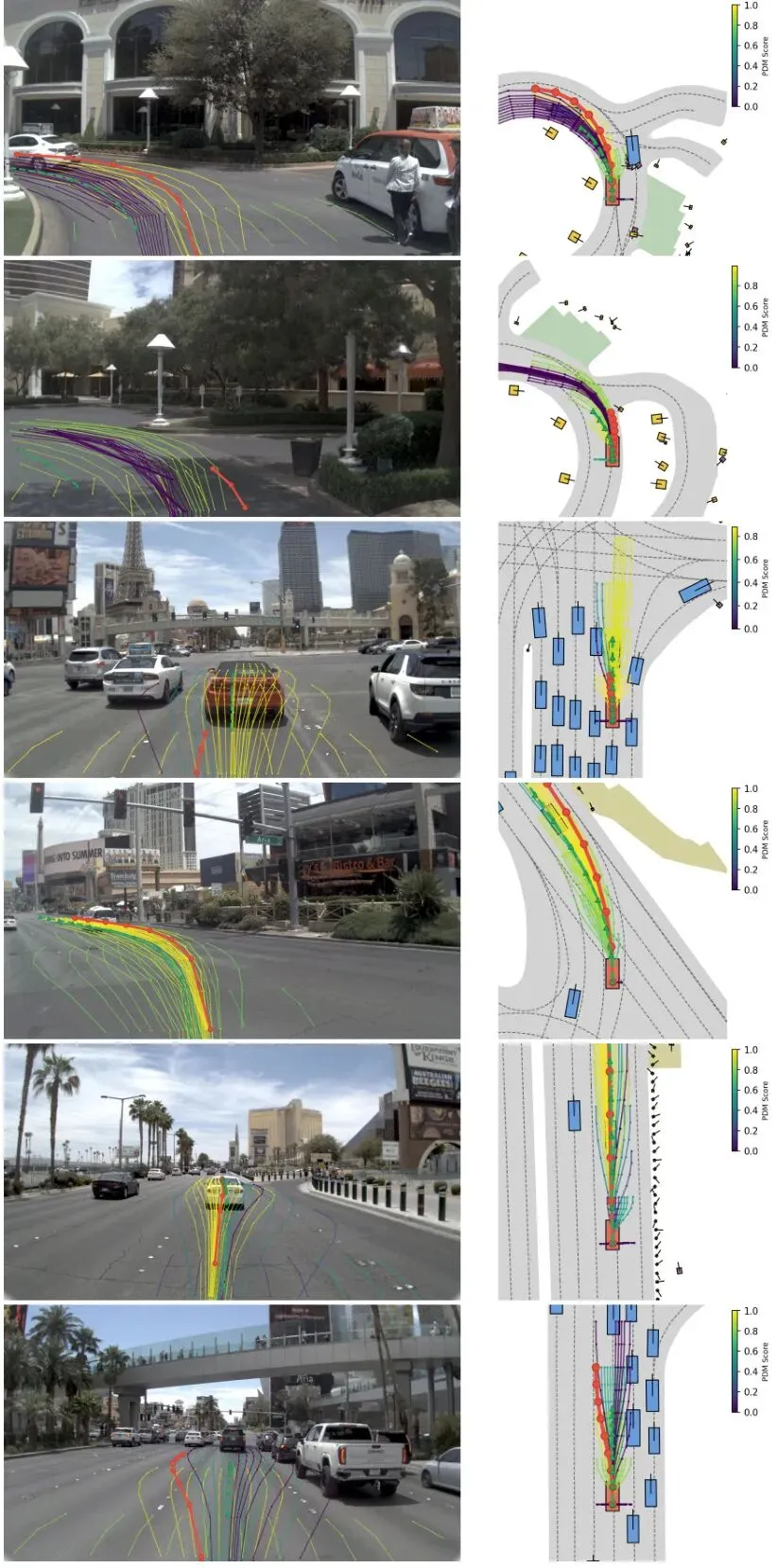
图5展示了6个场景的额外定性比较,进一步验证了CLOVER的一致多样性优势。
图5: 6个场景的额外定性多样性对比。每行左侧两列为 DrivoR 基线,右侧两列为 CLOVER 阶段2后的结果。每种方法展示所有64个候选轨迹,按真值 PDMS 分数着色。在所有场景中,基线候选集中于狭窄模式,而 CLOVER 始终覆盖更宽的可行且高分的候选。
此外,表7和表8分别消融了阶段2的更新方式(交替 vs 联合)和教师目标构建(标量 top-k vs 向量帕累托),确认了交替训练与帕累托目标的有效性。
表7: 阶段2精炼消融。非迭代的联合更新导致严重分布漂移。不使用评分器拟合的自蒸馏保持稳定但性能低于完整的交替优化。表8: 阶段2教师集构建消融。标量真实 PDMS top-k 目标往往将提议集中于狭窄的高分模式;距离惩罚部分恢复多样性,而向量帕累托引导取得最佳 PDMS 且预期能保留更多元的高质量提议模式。龙迷三问
CLOVER中的“闭环”具体指什么?闭环是指生成器和评分器之间形成互相反馈的循环:评分器接收真值评估器反馈来学习,生成器又根据评分器选出的高质量目标集进行蒸馏。整个训练过程将原本孤立的两步(生成候选+排序选择)耦合起来,形成一个自我提升的闭环。
PDMS和EPDMS是什么?PDMS(Planning-Driving Metric Score,规划驾驶度量分数)是一个综合指标,由导航代价(NC)、可通行面积符合度(DAC)、碰撞、时间间隔(TTC)、舒适度(Comf.)和进度(EP)等子分数按规则组合而成。EPDMS(Extended PDMS)是NAVSIM v2引入的扩展版本,增加了更多舒适度相关子指标,并且采用两阶段评估方式(先评估单帧,再评估时间一致性)。
CLOVER相比直接最大化学习奖励为什么更安全?直接最大化学习得到的分数会导致评分器误差被放大(exploit scorer errors),并可能造成多样性坍塌。CLOVER的保守自蒸馏通过稳定性约束(限制学生偏离教师太远)和基于目标集蒸馏(而非标量最大化),让生成器只在统计富集区域内优化,从而避免冒险行为。
如果你还有哪些想要了解的,欢迎在评论区留言或者讨论~龙哥点评
论文创新性分数:★★★★✰
CLOVER 的核心创新在于提出了闭环价值估计与自蒸馏范式,将生成器和评分器通过真值评估器耦合起来,并给出了选择性富集的理论条件。这比简单使用强化学习或直接最大化学习奖励更严谨。伪专家覆盖和保守自蒸馏的设计也颇具匠心,但思想可视为“先扩展再精化”的工程化实现,创新性略逊于完全颠覆性工作,但很实用。实验合理度:★★★★★
实验极为翔实:涵盖了NAVSIM v1/v2、NavHard、nuScenes多个基准,对比了20多种最新方法,消融实验覆盖了每个关键组件(伪专家、两阶段精炼、教师目标构建、重排序等),还提供了种子稳定性、提议质量/多样性统计分析,以及理论条件的实证验证。如此全面的实验令人信服。学术研究价值:★★★★★
本工作为训练-评估不对齐问题提供了一个干净的理论框架(选择性集富集条件),该条件可以推广到其他涉及排序-自蒸馏的领域。伪专家构建方法和保守自蒸馏策略也具有很强的方法学参考价值。对整个端到端驾驶规划社区有重要启发。稳定性:★★★★✰
论文通过三个随机种子实验显示PDMS变化小于0.02,方差极小。但存在两个隐患:1) 训练时需要实时调用评估器评分(CPU密集型),训练稳定性依赖评估器的稳定性;2) 锚点重排序(用于EPDMS)的权重需要网格搜索,不同场景可能存在最佳权重的变化。但整体上,生成器-评分器架构推理时很稳定。适应性及泛化能力:★★★★✰
CLOVER在NAVSIM系列基准和nuScenes开环上都取得了优异结果,说明方法可以在多个数据集和评估协议上有效。但伪专家生成依赖可通行区域地图和障碍物占用等先验信息,如果场景中没有这些信息(如纯视觉仅依赖学习占用预测),可能需要调整。另外,当前仅在驾驶场景验证,泛化到机器人导航等场景还需验证。硬件需求及成本:★★★✰✰
推理时模型约110ms/A100,可以接受。但训练成本较高:需要预先生成伪专家集(计算量未知),阶段1和阶段2交替训练,且阶段2中需要多次调用评估器计算真值分数(CPU密集型)。表19显示训练约需1张A100大约4.5天(含评估器计算),对卡资源要求较高。复现难度:★★★★★
论文代码将开源(已给出GitHub地址:https://github.com/WilliamXuanYu/CLOVER),架构表格(表15-18)详细列出了超参数,训练设置和评估流程清晰。理论上复现难度较低。产品化成熟度:★★★✰✰
模型推理速度快,有潜力用于实车。但当前评估器基于离线规则,实车场景中可能未覆盖的极端情况仍需验证。锚点重排序依赖Anchor模型的稳定性,且需要调参。此外,训练流程复杂(两阶段+交替自蒸馏),产品化时维护更新成本较高。但作为规划模块的候选轨迹排序机制,很有落地前景。1. 伪专家生成严重依赖先验地图信息(中心线、可通行区域等),在无地图场景中不适用。2. 阶段2涉及多次评估器调用,计算成本较高,且评估器规则变化时需重训练。3. 理论分析假设评分器选中的目标集统计富集,但极端场景(如从未见过的复杂交互)下富集条件可能不成立。[1] Sining Ang et al. "CLOVER: Closed-Loop Value Estimation and Ranking for End-to-End Autonomous Driving Planning". arXiv:2605.15120, 2026.[2] NAVSIM: A Closed-Loop Driving Simulation Benchmark. NeurIPS, 2024.[3] DrivoR: Learning Trajectory Scoring for End-to-End Autonomous Driving. CVPR, 2026.[4] DiffusionDrive: Truncated Diffusion Model for End-to-End Autonomous Driving. CVPR, 2025.*本文仅代表个人理解及观点,不构成任何论文审核或者项目落地推荐意见,具体以相关组织评审结果为准。欢迎就论文内容交流探讨,理性发言哦~ 想了解更多原文细节的小伙伴,可以点击左下角的"阅读原文",查看更多原论文细节哦!

欢迎加入龙哥读论文粉丝群,
扫描下方二维码或者添加龙哥助手微信号加群:kangjinlonghelper。
一定要备注:研究方向+地点+学校/公司+昵称(如 自动驾驶+上海+清华+龙哥),根据格式备注,可更快被通过且邀请进群。
🤖 与更多自动驾驶、机器人大佬一起,像CLOVER一样,让你的研究方向在"闭环"中持续精进!
『龙哥读论文』微信群目前包含:图像处理、大模型及智能体、自动驾驶及机器人、AI医疗及AI金融5个群


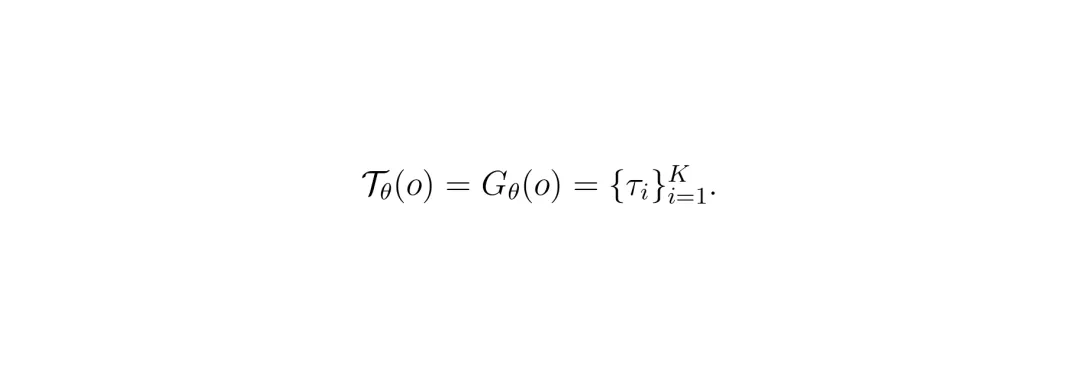
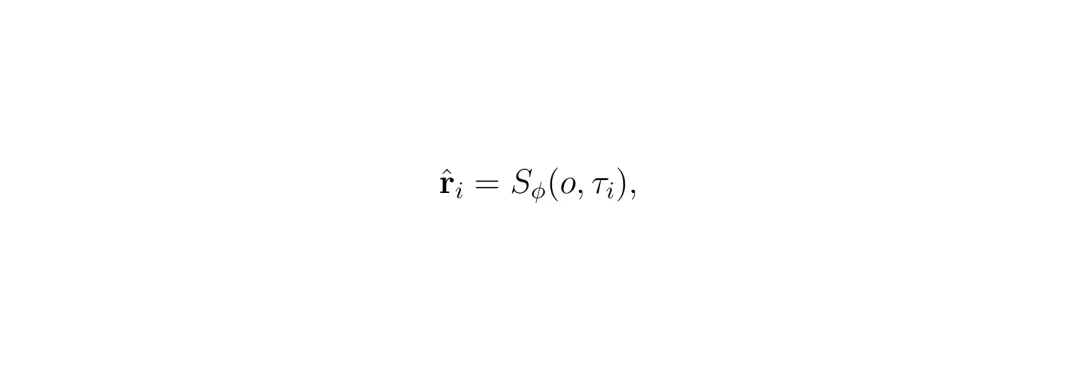
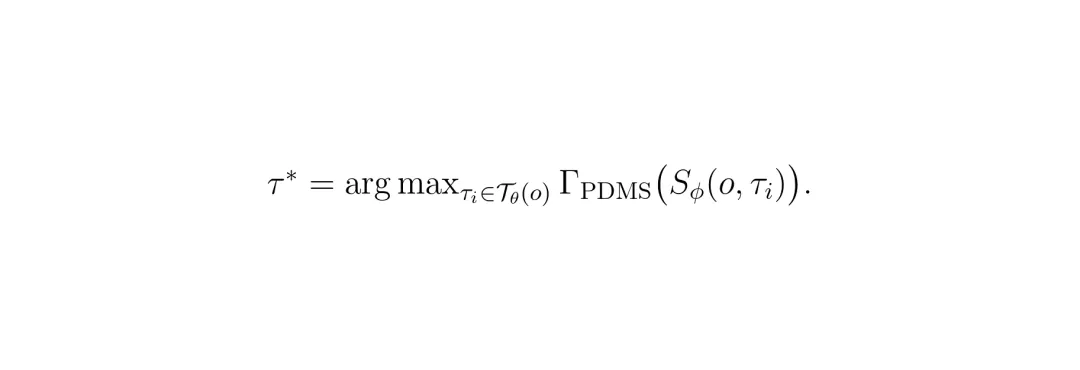
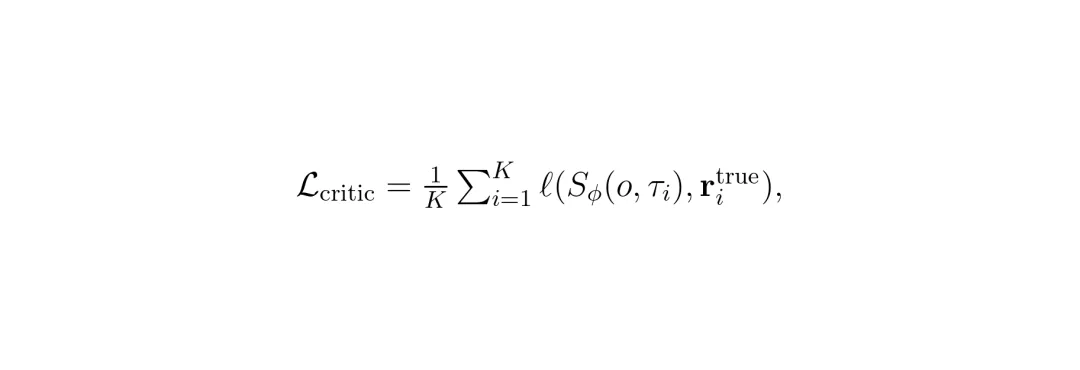
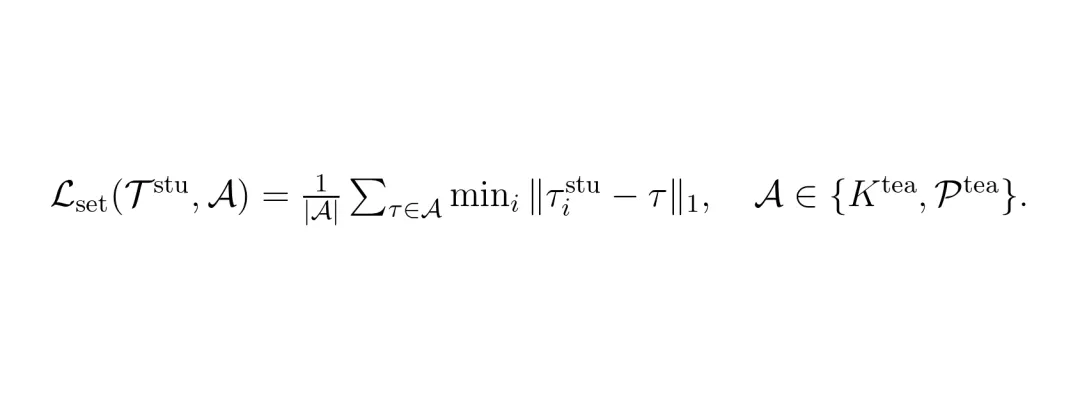
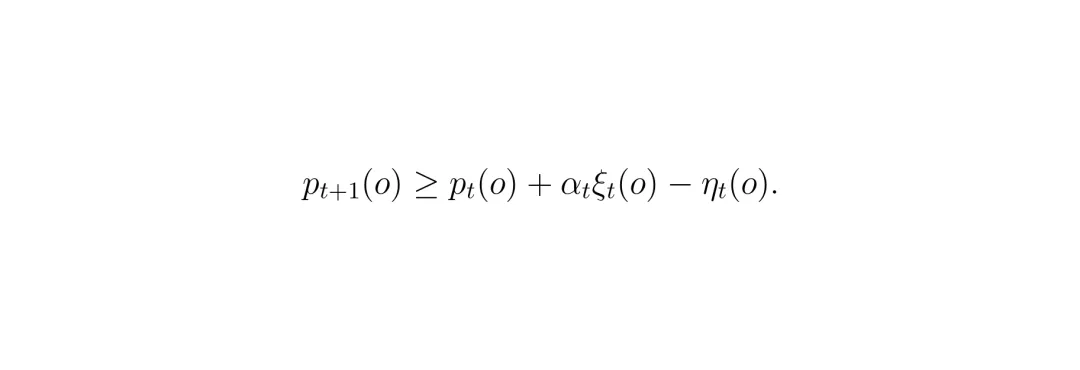







 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
