端到端智驾 vs 物理AI:自动驾驶的“模仿高手”与“物理学霸”谁更懂?
2025-2026年,自动驾驶技术像坐了火箭一样飞速迭代。从早期的模块化堆叠,到如今火爆的端到端智驾,再到最新热词物理AI,普通车主可能已经看花眼了。今天这篇科普文,就用大白话帮你捋清楚这两条主流技术路线到底有什么区别,谁更可能是未来的赢家。一、先说端到端智驾:从“看见”直接到“开走”
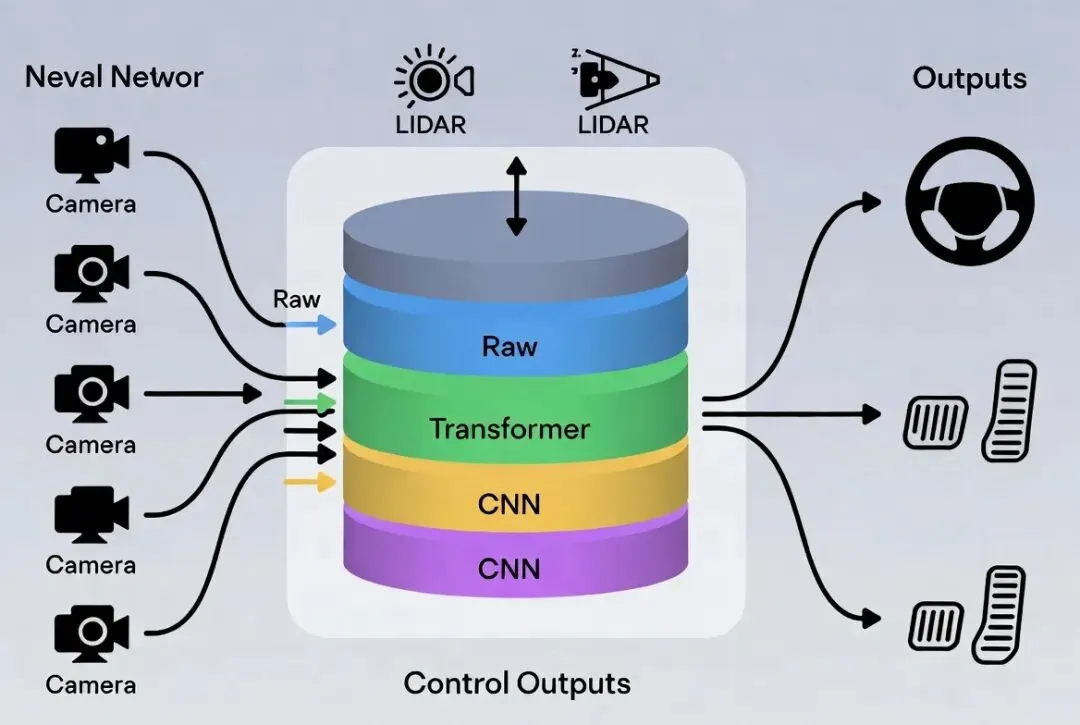
端到端(End-to-End,简称E2E)的核心理念非常简洁:输入原始传感器数据(摄像头画面为主),输出直接就是方向盘转角、油门刹车等控制指令。中间不再拆分成“感知→预测→规划→控制”那么多独立模块,而是用一个(或少数几个)大神经网络“一竿子捅到底”。典型代表:特斯拉FSD早期版本、部分新势力早期端到端方案。1. 为什么突然火了?
全局优化:整个系统朝着“安全舒适驾驶”这一个最终目标训练,避免了模块间误差累积。
数据驱动:海量真实路测数据+模仿学习(学人类司机怎么开),迭代速度快。很多车企宣称能做到几天一次大迭代。
简化架构:减少对高精地图和激光雷达的强依赖,成本更低,响应更快(延迟常低于50ms)。
泛化能力强:在见过类似场景后,对新路况的适应性更好,驾驶风格更“像人”。
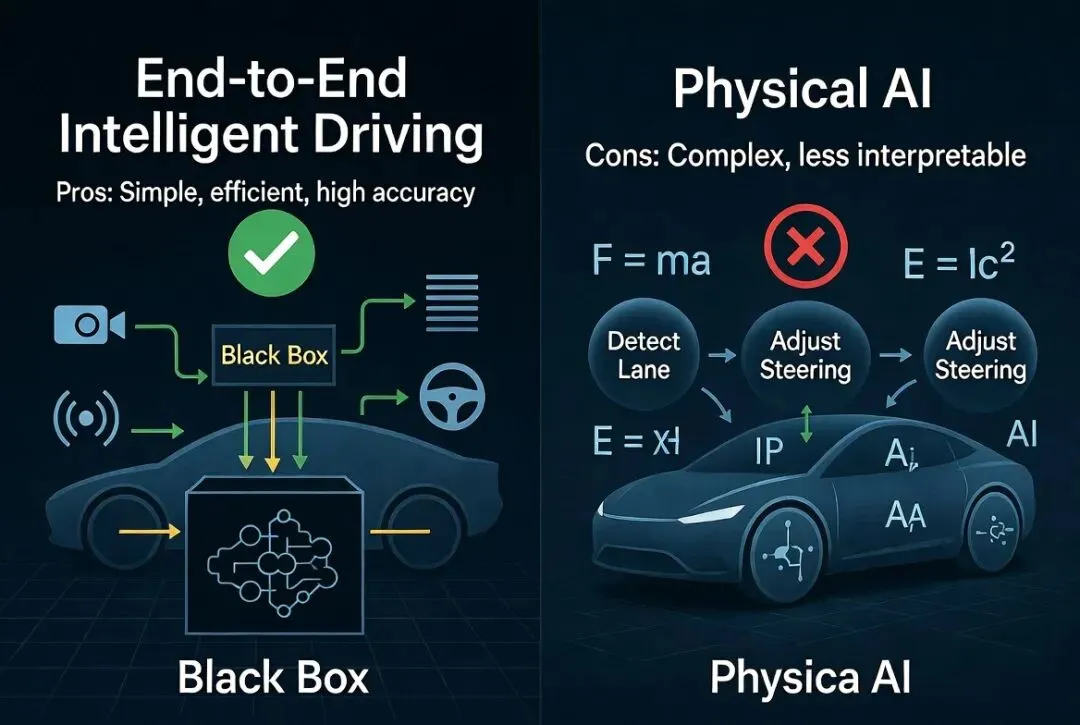
黑箱问题:决策过程不透明,出了问题难调试(为什么突然刹车?模型说“它就是这么想的”)。
长尾场景依赖数据:极端罕见情况(如复杂施工+恶劣天气)需要巨量数据覆盖,否则容易“翻车”。
缺乏显式物理常识:纯靠数据拟合,可能出现不符合物理规律的“幻觉”决策。
二、物理AI:不止会“模仿”,还要“懂物理”
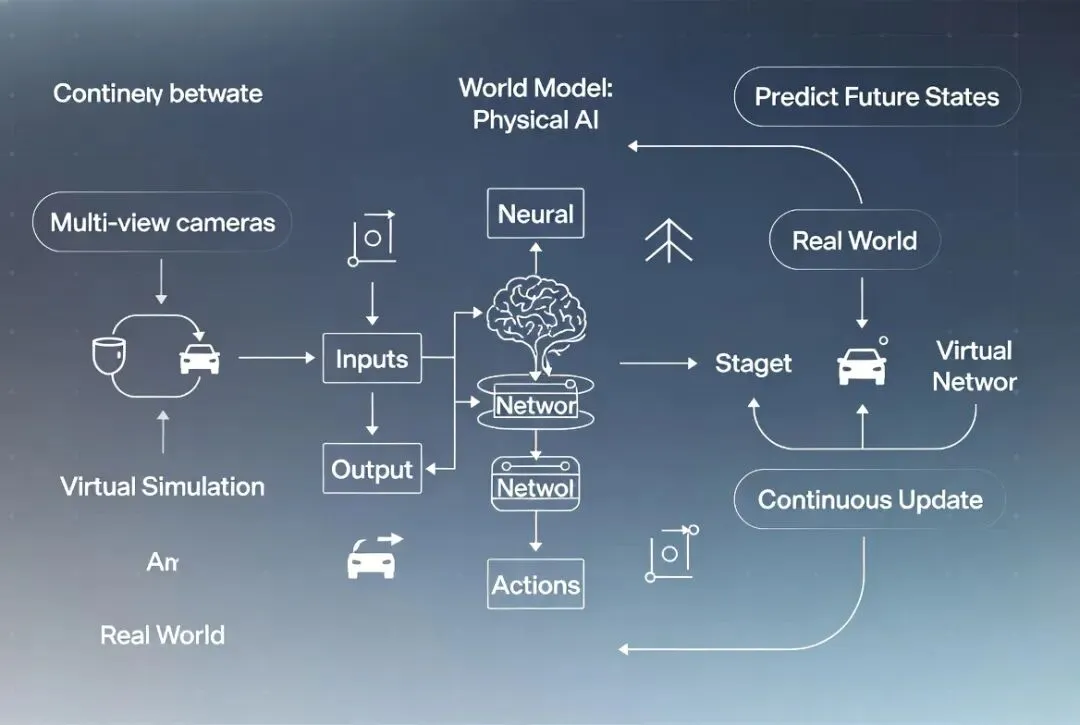
物理AI(Physical AI)是最近一年多行业共识的新方向。它不是简单抛弃端到端,而是在端到端基础上进一步嵌入物理世界理解。简单说,就是让AI不仅“看得到”“学得像”,还要“懂因果”“知物理规律”“会推理”。1. 核心特点
世界模型 + 强化学习:用模拟器生成海量虚拟场景(一天模拟人类几百年驾驶经验),让AI在虚拟世界里“刻意练习”,探索不同动作的物理后果。
VLA架构(Vision-Language-Action):视觉感知 + 语言理解 + 动作执行结合。模型不仅输出控制指令,还能用自然语言解释“为什么这么做”(如“前方施工,前车减速,我选择轻微变道”)。
物理先验嵌入:把重力、惯性、车辆动力学、交通规则等硬知识提前编码进模型底层,而不是全靠后期数据“碰运气”学。
闭环推理:更像人类思考(慢思考、逻辑推理),而非纯直觉反应。
小鹏VLA物理AI、理想MindVLA系列、Momenta等强调世界模型的方案,以及英伟达推动的物理AI方向。三、两大方案正面对比:谁更强?
| | | |
|---|
| 决策速度 | | | |
| 可解释性 | | | |
| 安全/长尾 | | | |
| 迭代效率 | | | |
| 计算需求 | | | |
| 拟人程度 | | | |
| 落地成熟度 | | | |
- 端到端像“天才模仿者”:看无数视频就能开得很溜,但偶尔会犯不符合物理常识的低级错误。
- 物理AI像“物理学霸+老司机”:不但会模仿,还深刻理解“为什么这样开安全”,在没见过的新场景里也能理性决策,更可靠、可控。
四、未来趋势:融合才是王道
目前看,端到端是物理AI的基础,很多物理AI方案本身就是端到端架构的升级版(模块化端到端 → VLA → 统一世界模型)。行业正从“能不能开”走向“开得好不好、安全不安全、解释不解释”。2026年及以后,D2D(车位到车位)全程智驾有望标配,物理AI将在极端天气、山路、复杂园区等场景展现更大优势。同时,世界模型+强化学习+车端实时推理的组合,将让智驾从“辅助”真正走向“自主智能体”。对消费者来说:不用太纠结技术名词,重点看实际体验——接管次数少、驾驶自然、极端场景稳、能解释决策的方案,就是好方案。自动驾驶的下半场,不是传感器和算力的简单堆叠,而是AI对物理世界的真正理解。端到端打开了大门,物理AI正在带领我们走进更聪明、更安全的智能驾驶时代。
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
