千里最近被讨论很多。它的智驾路线,相比小鹏和理想也非常「有想法」。
编辑|JeffHill
其实很少有一个领域像自动驾驶这样,受AI发展的影响,在短短数年内经历如此剧烈、甚至带有戏剧色彩的路线大开大合。
回望过去五年,自动驾驶行业先试确定性规则的模块化流水线(Modular Pipeline),试图用精密的工程结构去穷尽物理世界的万千变化;然后,伴随着深度学习的绝对力量与大数据的饱和式灌溉,端到端范式,以优雅且暴力的黑盒,直接用高维非线性函数替代了人类写下的数百万行代码。
而到了2026年的当下,行业在经历了端到端的狂热,正站在一个更为宏大的十字路口——视觉大模型(VLM)与语言大模型(LLM)的混合架构正以前所未有的速度切入智驾系统,推动着整个行业跨越单纯的“感知-行动”映射,走向更深层次的“世界理解”。
智驾系统的泛化能力,正在一级一级与更高的人类基础认知「对齐」。
图片来源于网络
李飞飞之前有个比喻让我印象深刻,自动驾驶汽车是简单的“方盒子”机器人,功能是二维的路面避障。而仅仅只是二维的物理AI的演进,自动驾驶真正迈向L3/L4,理解开车最大的困难不在开车这件事,而是理解背后整个世界和由此产生的因果关联。
2022年之前,自动驾驶系统是传统的模块化流水线(Modular Pipeline),它尝试将一个极其复杂的驾驶任务拆解为四个清晰的线性下游步骤:感知(Perception)、预测(Prediction)、规划(Planning)和控制(Control)。
在这种架构下,感知模块识别图像、点云中的3D边界框;预测模块基于历史轨迹和概率图模型,推演周围障碍物的未来运动可能;规划模块则在有限的物理时空中,在手工设计的代价函数(Cost Function)约束下求解出一条最优轨迹;最后,控制模块通过PID、模型预测控制(MPC)等经典控制理论,将轨迹转化为方向盘转角、油门开度和制动压力。
这一套体系在结构上是清晰且具备强可解释性的,但问题是不同层级联的信息瓶颈与特征损失,误差会阶梯式放大,以及工程复杂度无限膨胀的“代码地狱”:为了解决各种长尾场景,工程师不得不疯狂地在规划模块中打补丁(If-Else规则)。当规则代码累积到数百万行时,不同规则之间的冲突、优先级的混乱就会让整个系统陷入瘫痪。系统升级变成了一种“头疼医头、脚疼医脚”的危险游戏。
模块化流水线撞上了“人工规则的复杂度天花板”,才诞生了端到端的解法。
端到端的核心思想并不复杂,可以用一个极度纯粹的数学公式来抽象:
f : Sensor Data→Control Signal
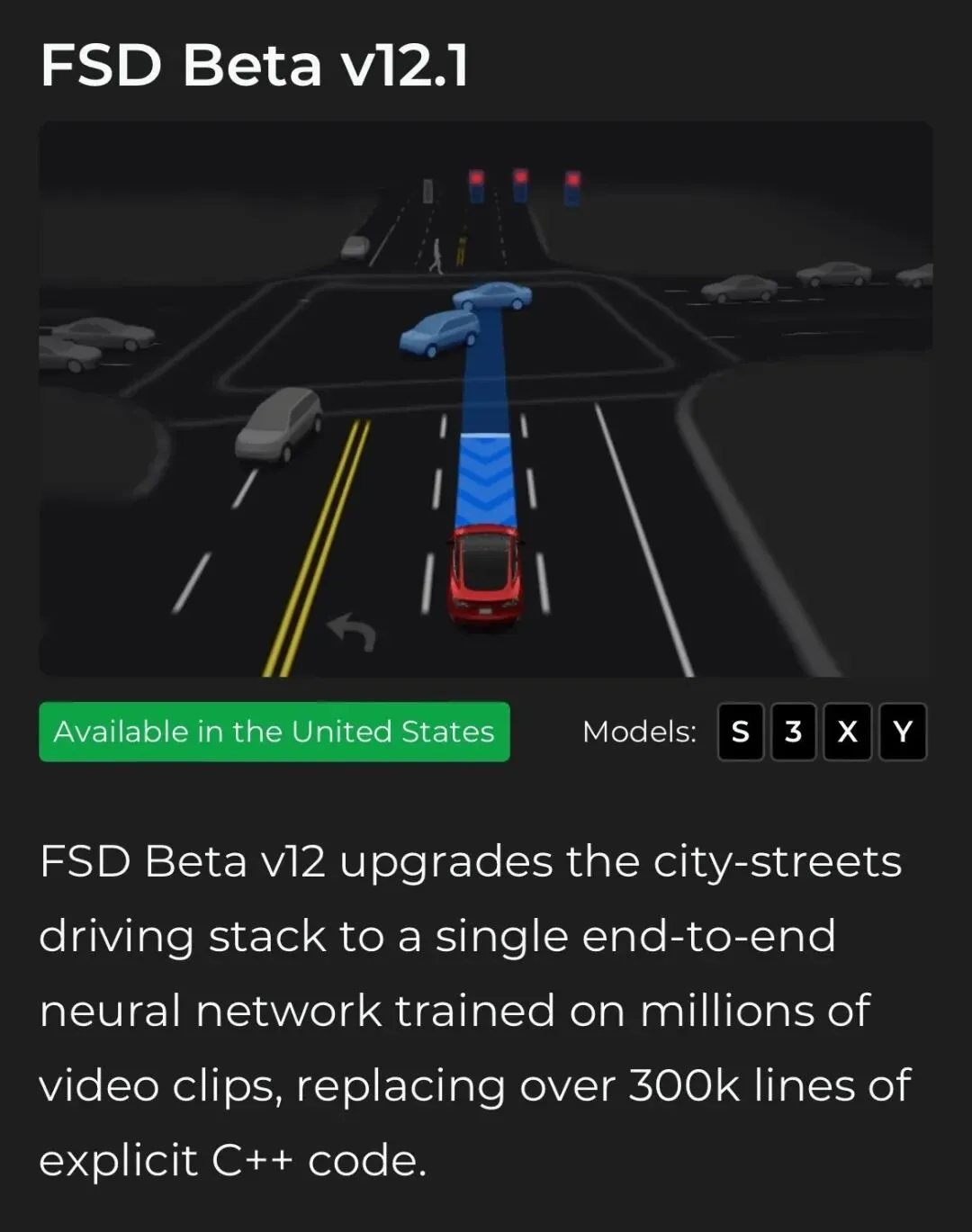
它试图训练一个统一的、深度分层的神经网络,跳过所有中间的人工抽象步骤,直接建立从原始传感器输入(Vision/Lidar/Radar)到车辆控制输出(如转向、加速、制动)的「端到端」直接映射,可以理解为在神经网络的隐藏层中对智驾场景数据的隐式表示进行学习和建模。以特斯拉(Tesla)FSD V12为代表的纯视觉端到端神经网络方案,彻底改变了智驾的底层逻辑。
端到端模型本质上是一个高维非线性函数逼近器(High-Dimensional Non-linear Function Approximator)。它在数学上做的事情,是利用极大似然估计(Maximum Likelihood Estimation),在海量专家驾驶数据集中寻找传感器输入与控制动作之间的统计相关性拟合。
也就是说,模型在本质上只计算条件概率分布:它通过梯度下降,记住了在海量相似的光影图案、像素组合出现时,人类司机的方向盘应该转多少度。它深刻地知道“在类似场景下该怎么做”,却根本不知道“为什么要这么做”。
但相关性并不等同于因果性。在数据分布内,相关性拟合完美无瑕;一旦进入分布外的长尾场景,由于缺乏底层因果逻辑的支撑,模型行为就可能失控。在真实世界的物理空间中,纯粹的 Vision-Action 映射在面对需要“世界模型”与“常识推理”的场景时,会暴露出极度脆弱的底牌。
这就是为什么,即使数据规模不断扩大,端到端仍然难以突破一个“隐形天花板”:泛化能力受限,可解释性不足,安全验证困难。
本质上,E2E解决的是“行为生成”,但没有解决“认知建模”。而自动驾驶真正困难的部分,恰恰在“认知”。这也解释了一个行业共识的转变:单纯依赖Vision-Action的映射,无法支撑L3/L4级别的自动驾驶。
于是,语言模型被引入,成为下一阶段的关键变量。
相比端到端模型拟合从输入到输出、孤立地在像素与控制量之间找统计相关性不同,LLM/VLM 的核心价值在于:它第一次将人类积淀的语言语义、世界知识、常识推理以及长时序因果关系,跨模态地注入到了驾驶系统之中。
语言模型可以显式建模语义、规则和因果链条,这几乎是当下让智驾系统具备类似人类“解释能力”和“推理能力”的唯一路径。然而,让一个满腹经纶的“语言大脑”去直接操纵一辆在物理世界中疾驰的汽车,面临着天然的模态鸿沟:
一是信息形态的冲突:VLM输出的是离散、符号化、低频的文字Token或语义描述;而车辆控制需要的是连续、高频(通常在20Hz以上)、强物理约束的数值信号(如确定性的物理轨迹或控制边界)。
二是工程落地的制约:大模型的参数量庞大,在算力、稳定性、实时性和安全闭环要求极高的智驾场景中,很难直接承担高频的控制任务。
语言模型天生不擅长控制。它输出的是离散的语义Token,而不是连续的控制信号;它擅长思考,却不擅长“肌肉记忆”。这就导致一个现实选择——当前主流方案,不是用语言模型替代端到端,而是把它“外挂”进去。
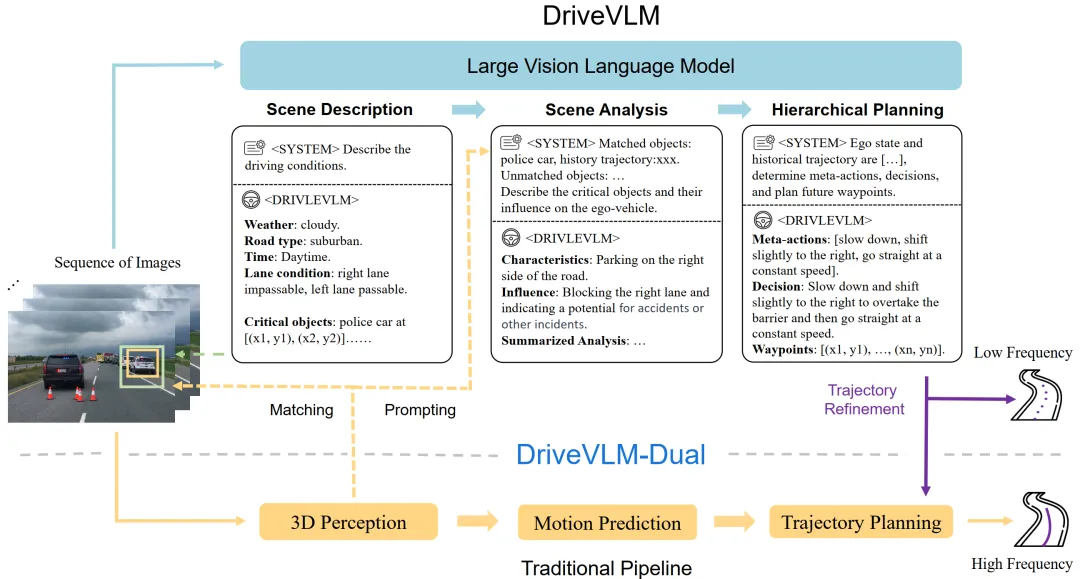
于是,“快慢双系统”成为阶段性最优解,理想汽车2024年到2025年的“端到端+VLM”方案便是这一阶段的典型代表。在其硬件部署中,理想采用了双Orin X芯片的架构,:
理想 DriveVLM 的运行逻辑:
图像输入——>思维链(Chain-of-Thought, CoT)推理——>输出结构化语句(包含场景描述 Scene Description、场景分析 Scene Analysis 和层级规划 Hierarchical Planning)。
为了将慢系统的低频语义规划转化为快系统的高频控制轨迹,理想引入了 Trajectory Refinement,系统利用DriveVLM输出的粗略轨迹作为语义引导,约束并指导快系统进行实时、高精度的空间轨迹生成,从而显著提升了系统在复杂博弈、道路施工等长尾场景下的空间规划精度。
“快慢双系统”虽然显著拉高了智驾的智能上限,但其弊端也很明显:两套系统在物理和算法上依然是割裂的。 信息同步低效、无法进行端到端的联合训练、两者的优化目标往往不一致,这导致系统在面对突发极端场景时,可能出现“大脑想明白了,但身体没跟上”的脱节。而且智驾实际运行中,VLM的慢系统,往往只在一些特殊场景才会进行“思考”,是以某种高阶功能的冗余存在。
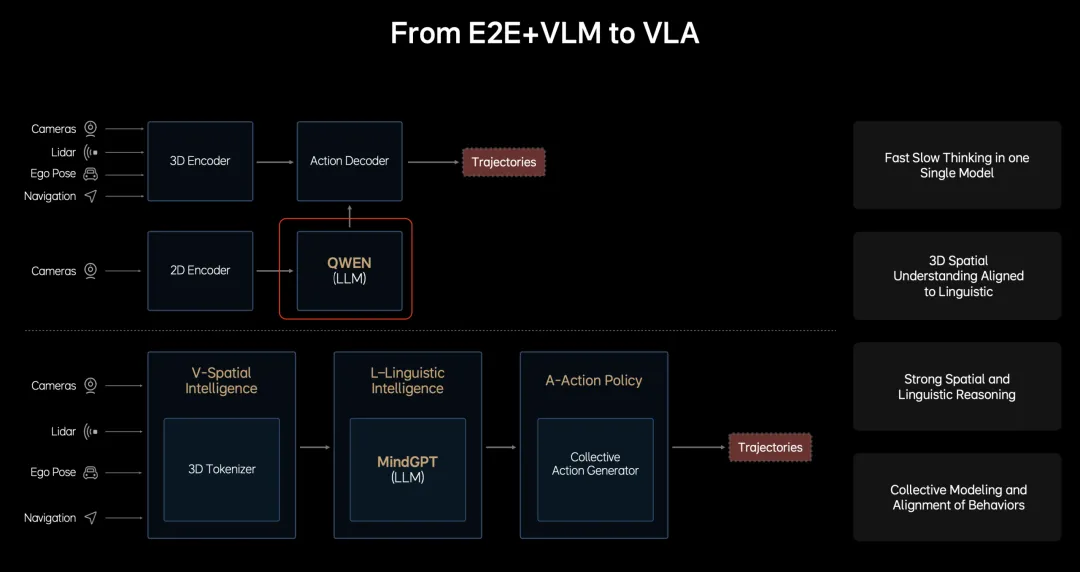
于是,行业开始将目光投向更进一步的统一架构——VLA(Vision-Language-Action,视觉-语言-动作)模型。
在VLA框架中,语言大模型不再是外挂的“独立慢大脑”,而是被彻底内化到了端到端的架构内部,成为整个系统的“中枢神经”。它将驾驶任务拆解为统一流转的三个核心功能模块:
Vision(视觉/多模态感知):负责环境理解。其根本任务是“理解与转换”,通过视觉编码器(如ViT)提取特征。更关键的是,它需要跨模态对齐,将高维的像素结构特征“翻译”成语言模型能够理解的语义序列(Visual Token)。
Language(认知与推理中枢):采用成熟的预训练大模型基座(如LLaMA、Qwen等)。它同时接收文本Token(导航指令、规则先验)和视觉Token,在Transformer层中进行跨模态信息融合与因果链条推理。最终,它不输出连续控制量,而是输出高层的 Action Token(如“减速”、“变道”、“绕行”)以及解释原因的 Reasoning Token。
Action(物理执行引擎):负责将Language模块输出的高层Action Token,在满足车辆动力学和安全边界的前提下,解码为稳定、可执行的底层信号(方向盘转角、油门制动)或高频轨迹点。
一个统一架构的VLA,相比“端到端+VLM”的快慢系统,最大的变化是让LLM/VLM和Vision模块和Action模块形成一个整体,它们可以同步工作,也可以同步优化。
魔鬼藏在细节中,VLA训练过程必须解决多模态对齐、跨模块协同以及多任务优化等一系列问题。VLA 的训练往往不是一次完成的,而是由多个阶段组成,包括视觉表示学习、视觉—语言对齐、决策模型训练以及动作生成训练等。如何设计合理的训练流程,使这些模块既能够各自发挥作用,又能在系统层面协同工作,是VLA研究中的一个核心问题。
VLA还有一个灵魂拷问:实际部署在车上的VLA是一直在思考,还是绝大部分时间还是靠VA?
其实大部分人都会承认一点,VLA 的 L 其实并不是一直在,大部分时间都靠 VA 在工作,并没有用文字去思考。
如果VLA的思考能力并不能做到一直运行,真的遇到紧急的情况,它并没有正在思考,或者来不及思考,那就还是在用「没有脑子」的VA在处理,这样的方案很显然并不能解决真正会导致高风险的 corner case 长尾场景。
未来是端到端、VLM、还是VLA,千里科技说「都不是」。
2025年,千里科技将其品牌全面升级为“Afari”,其官网阐述的内涵颇具野心——“携AI,以致远(Ai - far - Ai)”。这家集结了旷视的原生AI基因、吉利的量产车生态、原华为车BU的知名高管,以及阶跃星辰多模态大模型能力的特殊玩家,在2026年4月的北京发布会宣布了另一种解法:
他们宣布,将抛弃行业目前单纯在算法结构上“缝缝补补”的路线之争,联合阶跃星辰打造行业首个“原生智驾基座模型”。
当行业还在争论“端到端 vs VLM vs VLA”时,千里科技选择了一条更激进、也更底层的路径:它不再纠结架构形式,而是直接重写起点。4月北京的发布会更像是一种技术洞察:自动驾驶不再是一个应用层问题,而是一个基础模型问题。
可能对于千里科技看来,端到端、VLM、VLA都不是关键,真正的分水岭在“基座模型”。行业过去的主流路径,本质上是“通用大模型 + 自动驾驶后训练”,但问题在于,这些模型在“出生时”并不理解驾驶。它们不理解三维空间结构、不理解车辆动力学、不理解交通博弈,也不理解安全边界,后训练可以弥补能力,但无法改变“基因”。
与之互相验证,千里智驾CTO杨沐在年初的2026GTC英伟达大会提出过一个观点:VLA想做好,首先必须是基础模型,而不能只看SFT之后的效果;如果基座不够强,后训练只是放大器,不会凭空创造高上限 。
千里科技的“原生智驾基座模型”正是顺着这条逻辑往下走:先把通用语料、智驾数据、物理世界经验统一到同一基座里,再谈场景迁移、任务对齐和L4演进 。
杨沐在GTC分享里说,端到端方案在L2上已经相对成熟,但到L3/L4,难点不再只是输出轨迹,而是面对大量长尾场景、因果推理、世界生成和安全验证 。如果仔细查看千里科技过去的技术分享,这家公司技术路线图一个非常鲜明的特点:它不是把“VLA”当作概念包装,而是把它当作智驾进入下一阶段的基础工程。
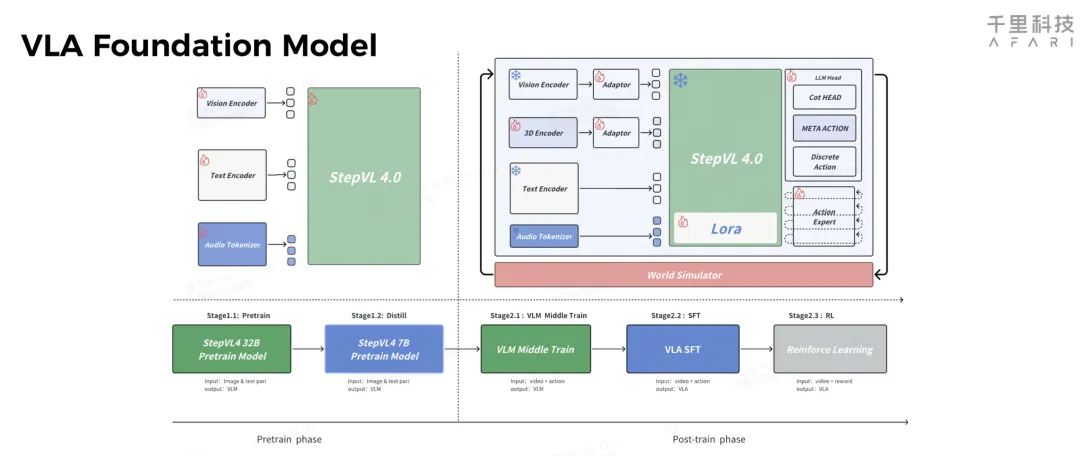
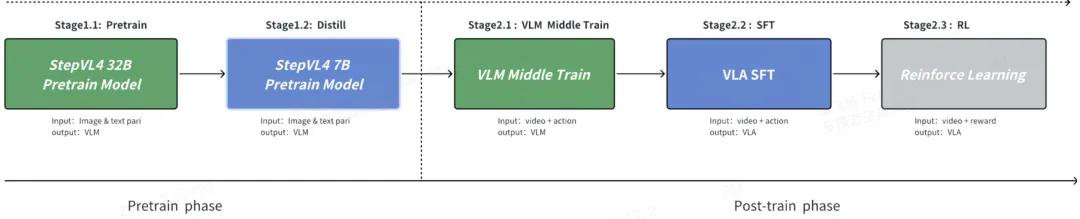
仔细翻阅千里智驾CTO杨沐2026GTC公开演讲的PPT,可以找到VLA Foundation Model 这一页清晰的训练路径:预训练阶段与阶跃星辰从头训一个StepVL 32B模型,蒸馏到7B,然后进行VLM模型数据的middle train,最后是VLA数据的SFT微调和强化学习后训练。
对于未来智驾的发展,千里科技的判断可能是:如果目标是L3/L4,那么模型必须在预训练阶段,就具备对物理世界的原生理解。千里科技提出的“原生智驾基座模型”,它的核心不是在现有模型上做微调,而是在预训练阶段就融合:语言、视觉、驾驶数据与物理世界经验,让模型从一开始就“懂驾驶”。
这也是为什么千里科技会把世界模型、生成式仿真、强化学习、VLA和大模型基座一起看待。它不是在做单点模型,而是在做“数据—仿真—训练—部署—反馈”的全链路闭环 。
千里科技选择在模型训练全周期内深度协同,把通用语料与智驾数据同源输入,这样做的好处是模型在“出生时”就具备物理世界理解,而不是后天补课 。这会直接带来三点收益:一是场景泛化更强,二是因果推理更自然,三是模型更容易在L3/L4的高责任场景里保持稳定 。
千里科技的做法,与千里科技董事长同时也是阶跃星辰董事长印奇的另一个核心判断严丝合缝:L2、L3、L4不是三条路线,而是一条连续演进路径。
印奇在4月的发布会群访中说,“L2级别的量产车体系绝不是一个过渡性的功能产品,它最终是为L4级纯物理AI服务的,两者必须互相联动、同源演进”。传统的智驾路线中,车企往往将L2辅助驾驶与L4无人驾驶割裂为两套相互独立的算法组与硬件方案,而千里科技利用原生智驾基座模型,正在尝试打破了这一阻隔。
L2阶段积累的数据,不是阶段性资产,而是L4能力的训练基础;今天的量产系统,本质上是在为未来的高阶自动驾驶“喂养模型”。如果以基座模型迭代、“智驾大脑”成长,这种更接近第一性原理的视角,自动驾驶的竞争维度会有根本不同:
过去比的是感知精度、规划算法、功能数量; 现在比的是基座能力、数据闭环与系统工程。
千里科技把模型本身的迭代放在中心位置,而不是像理想思考如何在端到端上面外挂VLM,进行Qwen的开源模型微调;或者像小鹏这样拿开源模型和自己的数据做后训练,再跟Vision、Action 模块对齐和同频运行。
千里科技的新解法,本质是把自动驾驶从“功能工程”,推进到建设“智能基础设施”。这家公司笃定的,当行业进入L3/L4阶段,差异会被迅速放大,真正决定上限的,不再是单点能力,而是系统是否具备:
理解世界的能力、推理因果的能力,以及持续进化的能力。
而这三者,恰恰只能从“基座”开始。
过去三年,如果把理想、小鹏、千里连起来看,它们像是在完成自动驾驶迈向L4的三级跳:
第一跳(传统模块化到端到端):行业用高维非线性函数的“直觉暴力”,跳出了数百万行人工规则的代码地狱,解决了“行为生成”的问题。
第二跳(快慢系统到VLA架构):理想、小鹏等先锋通过引入LLM/VLM与VLA架构,尝试为直觉套上“理性与语义”的缰绳,让系统走向对世界因果链条的认知建模。
第三跳(从算法迁移到原生AI底座):千里科技与阶跃星辰的联手,不再纠结于局部的架构拼补,而是直接用原生基座模型重写起点,打造面向通用物理智能的基础设施。
从0到1自建原生智驾基座模型,以及有能力建,有阶跃星辰的多模态基座模型的「战略伙伴」,千里科技在智驾圈确实具备有一定的稀缺性。
举个例子,2个月前,知名汽车博主“不是郑小康”转发了X上面一个社交媒体截图,截图中某大模型圈内人士似乎是要揭下所谓模型自研的“遮羞布”,表示国内许多智能汽车厂商和机器人公司开发的模型使用了Qwen开源模型。
国内目前主流的两种智驾模型方案路线:端到端+VLM以及VLA,在运行中都涉及到一个将传感器输入的视觉和其他多模态信息与语言对齐从而进行推理,语言层模型的中枢部分,几乎可以确定都是以Qwen的开源模型,做SFT和强化学习后训练。
理想汽车是第一个公开承认使用了Qwen的,写在VLM模型介绍的PPT上,它家2B的VLM 大概率是Qwen VL2.5 2B模型。小鹏汽车转向VLA,2.0实现了显著突破,但VLA 1.0大概率也是使用的Qwen VL2.5 7B模型。
千里这家公司今年非常热闹和受关注。先是华为荣耀前CEO赵明空降车圈,然后北京发布会宣布三年800万智驾系统装车量目标,到最近北汽、长安、奇瑞频频被传或采用千里科技的智驾,或成立合资公司。
结合吉利之前的某高管在直播中说,“年底超越特斯拉”。空穴来风未必无因,全新自研基座模型,SFT后有更高能力上限,更流畅、更拟人智驾系统的大招可能正在酝酿中。




 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
