清华AIR开源CLOVER:端到端自动驾驶规划闭环新框架,NAVSIM v1达94.5 PDMS
- 2026-05-22 07:34:34

极市导读
端到端自动驾驶规划的核心矛盾在于训练用单条轨迹模仿,评测却考安全、舒适、进度等多维指标。CLOVER将候选生成与轨迹排序纳入同一闭环,通过伪专家轨迹扩展候选覆盖、保守自蒸馏精炼生成器,在NAVSIM v1上达到94.5 PDMS,距人类驾驶员参考值仅差0.3。 >>加入极市CV技术交流群,走在计算机视觉的最前沿
论文名称: CLOVER: Closed-Loop Value Estimation & Ranking for End-to-End Autonomous Driving Planning - 作者: Sining Ang, Yuguang Yang, Canyu Chen, Yan Wang 单位: 清华大学智能产业研究院(清华 AIR) 项目地址: https://github.com/WilliamXuanYu/CLOVER(已开源)
摘要
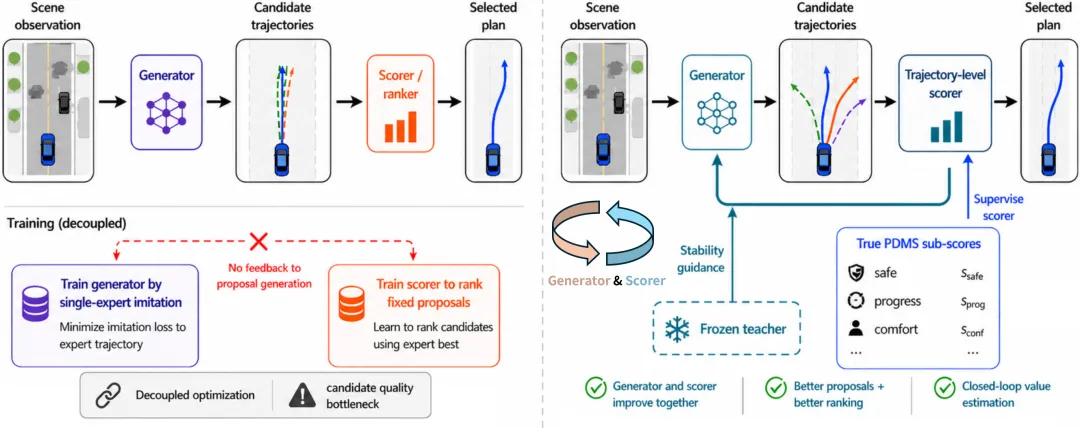
端到端自动驾驶规划器通常通过模仿单条日志轨迹进行训练,却在评测时接受规则化规划指标的检验。这类指标关注安全性、可行性、进度与舒适性,而不只是预测轨迹与人类驾驶轨迹之间的几何距离。由此产生的训练-评测错位,在 proposal-selection 类规划器中尤为明显:最终性能同时依赖候选轨迹集合的覆盖质量,以及评分器对候选轨迹的排序能力。
本文提出 CLOVER,即 Closed-Loop Value Estimation & Ranking。CLOVER 采用轻量级 generator-scorer 结构:生成器输出多条未来自车候选轨迹,trajectory-level scorer 预测规划指标子分数,并在推理阶段根据组合后的预测分数完成排序。训练上,CLOVER 通过 evaluator-filtered pseudo-expert trajectories 扩展候选支持,再通过 conservative closed-loop self-distillation 将评分器反馈用于生成器精炼。实验显示,CLOVER 在 NAVSIM v1 上达到 94.5 PDMS,在 NAVSIM v2 上达到 90.4 EPDMS,并在更具挑战性的 NavHard two-stage split 上达到 48.3 EPDMS。
1. 引言:从单轨迹模仿到规划指标优化
端到端自动驾驶规划的目标,并不是简单复现日志中记录的某一条历史轨迹。对同一个交通场景而言,车辆可能存在多种合理规划:保持速度、轻微减速、选择更保守的横向位置,或在障碍物附近提前制动。只要轨迹满足安全、可驾驶、舒适并能推进路线目标,它就可能是一个有效规划。
然而,许多模型训练时仍以单条 logged trajectory 作为主要监督信号。这种设置稳定且高效,但并不完全对齐现代规划评测。以 NAVSIM PDMS / EPDMS 为例,评价函数包含 no collision、drivable area compliance、time-to-collision、ego progress、comfort、lane keeping、extended comfort 等子项。也就是说,一条与人类日志很接近的轨迹可能因为碰撞或越界而低分;一条偏离日志但更安全、更符合路线目标的轨迹,则可能获得更高分。
这一差异对 proposal-selection planner 尤其关键。这类模型先生成候选轨迹集合,再由评分器选择最终轨迹。因此,模型不仅要“会打分”,还必须“先生成值得被选择的候选”。如果 proposal set 本身缺少高质量模式,评分器只能在有限选项中做局部选择;如果候选丰富但排序不可靠,最终 top-1 轨迹也可能不是最优。
CLOVER 的核心出发点是将候选生成与轨迹排序放入同一个训练闭环中,使评分器不只在推理阶段负责最终选择,也能在训练阶段反向塑造生成器分布。
2. 方法概览
给定多视角相机图像与自车状态,CLOVER 首先通过视觉编码器提取场景特征,再由生成器输出 K=64 条未来自车候选轨迹。每条候选轨迹会被 trajectory-level scorer 预测规划指标子分数,随后按照官方 PDMS / EPDMS 形式组合为排序分数,并选出 top-ranked trajectory。
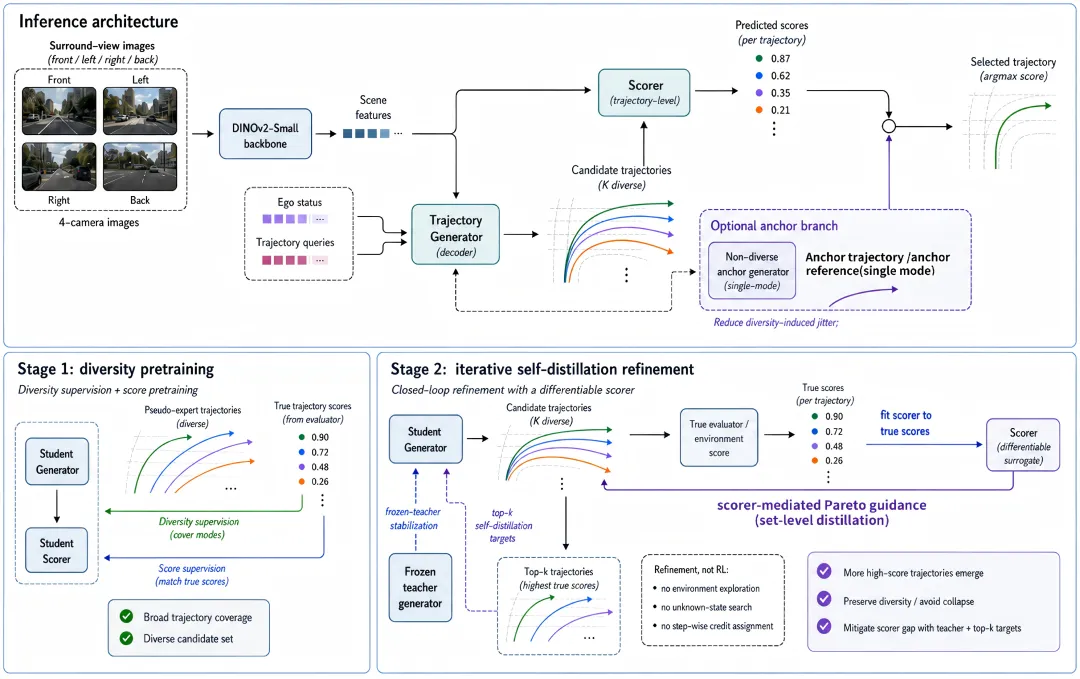
具体实现中,CLOVER 使用 4-camera images,不依赖 LiDAR;视觉编码器采用 DINOv2 ViT-S,并进行 LoRA fine-tuning;规划 horizon 为 4 秒,每 0.5 秒采样一次。CLOVER 的贡献主要发生在训练机制上:真实 evaluator、伪专家生成器与闭环蒸馏过程都只在训练和分析中使用,部署阶段仍然是可直接推理的 generator-scorer 图。在 NAVSIM-v2 设置下,K=64 的模型在单张 NVIDIA A100 上约为 110 ms / scene。
因此,CLOVER 并不是通过推理时引入复杂在线优化来提升指标,而是将规则 evaluator 的规划反馈蒸馏到可部署的 scorer 与 generator 中。
3. Stage 1:Evaluator-filtered Proposal Coverage
闭环优化需要一个基本前提:当前候选集合中必须已有足够多可供选择和学习的高质量模式。如果生成器只在单条日志轨迹附近产生窄分布,评分器即便具备判断能力,也很难引导生成器走向未被覆盖的规划区域。
为此,CLOVER 首先构造 evaluator-filtered pseudo-expert trajectories。它们并不是对日志轨迹进行简单扰动,而是利用训练阶段可获得的 privileged metric-cache 信息生成,包括 route centerlines、drivable-area maps 与 future obstacle occupancy。基于这些信息,系统从多类可解释轨迹族中采样候选,例如:
不同横向偏移,用于覆盖车道内不同空间选择; 加速、匀速、减速等 speed profiles; stop-go 行为; 接近障碍物时的制动轨迹; 边界场景中的 overshoot-style motions。
这些候选会先经过轻量级可驾驶区域与占用检查,再由规则 evaluator 评分。随后,CLOVER 通过 coverage-aware selection 选择具有不同分数模式和几何形态的高质量候选,并使用集合级 coverage supervision 训练生成器。
Stage 1 的目标并不是让模型记住更多“伪标签”,而是将单轨迹模仿扩展为多模态候选覆盖。它保留 logged trajectory 作为驾驶先验,同时把 proposal support 推向更宽的可行空间,为后续闭环精炼提供基础。
4. Stage 2:Conservative Closed-loop Self-distillation
在获得更宽的候选支持后,CLOVER 进一步引入保守闭环自蒸馏,使 scorer 从 inference-time ranker 变为 training-time feedback provider。
Stage 2 采用交替训练:
Scorer fitting:在当前 generator 生成的候选轨迹上运行真实 evaluator,得到规划指标子分数,并用这些子分数监督 trajectory-level scorer。 Generator refinement:固定 teacher,由 scorer 选择 top-k 与 vector-Pareto proposal targets,再让 student generator 在稳定正则约束下覆盖这些目标。
“保守”是该阶段的关键。直接最大化 learned scalar score 可能利用 scorer 误差,也可能让候选分布坍缩到少数高分模式。CLOVER 因此不把 scorer 当作可任意最大化的 reward model,而是把它作为 target selector:从已有候选集合中挑选统计意义上更优的目标,再通过集合级蒸馏将生成器概率质量推向这些区域。
其中,top-k targets 提升高分候选的概率质量;vector-Pareto targets 保留安全、进度、舒适性等多目标之间的权衡;stability regularization 则限制 student distribution 过度偏离 teacher distribution,降低评分器误差被放大的风险。
5. 理论证明:Selected-set Enrichment 如何带来生成器改进
CLOVER 的理论部分回答了一个核心问题:一个并不完美的 learned scorer,为什么仍然可以可靠地改善 generator? 论文并不假设 scorer 在全局轨迹空间内精确,也不要求它对任意候选轨迹两两排序都正确。相反,证明建立在一个更弱、更贴近实际训练过程的条件上:scorer 选出的目标集合,在真实 evaluator 下相对于当前候选分布具有统计富集。
具体地,对每个场景 o,设当前 generator 产生的 K 条候选轨迹构成经验分布:
mu_t^o = 1/K * sum_i delta_{tau_i^t(o)}再设 A_t(o) 为 scorer 选出的目标集合,例如 top-k teacher proposals 或 vector-Pareto teacher proposals;目标集合对应的经验分布记为 nu_t^o。定义真实高分区域:
H_o = { tau : R*(o, tau) >= r_high }其中 R* 表示真实 evaluator 分数。令:
p_t(o) = mu_t^o(H_o)q_t(o) = nu_t^o(H_o)也就是当前候选分布和 scorer-selected target distribution 落入真实高分区域的概率质量。理论证明的关键假设是:
q_t(o) >= p_t(o) + xi_t(o), xi_t(o) > 0这就是 selected-set enrichment:scorer 选出的目标集合中,高分轨迹比例要比当前候选池更高。这个条件比“scorer 全局准确”弱得多,也更容易在实际系统中验证。
接下来,论文将一次 generator refinement 视为向目标分布做保守移动。理想情况下,下一轮分布可写为当前分布与目标分布的混合:
mu_bar_{t+1}^o = (1 - alpha_t) * mu_t^o + alpha_t * nu_t^o其中 alpha_t 表示向 selected targets 靠近的步长。实际 student generator 不会完全等于这一理想混合分布,因此论文用 total variation 距离刻画更新误差:
TV(mu_{t+1}^o, mu_bar_{t+1}^o) <= eta_t(o)在上述两个条件下,可以得到:
p_{t+1}(o) >= p_t(o) + alpha_t * xi_t(o) - eta_t(o)因此,只要 enrichment gain 大于保守更新误差,即:
alpha_t * xi_t(o) > eta_t(o)下一轮 generator 分配给真实高分轨迹区域的概率质量就会增加。这个结论解释了为什么 CLOVER 不需要把 scorer 当作可无限优化的 reward model:它只需要让 scorer 在候选集合中选出统计上更优的目标,并通过稳定约束保证 student update 不过度偏移。
论文还给出期望分数版本的结论。如果 scorer-selected target distribution 的真实期望分数高于当前 proposal distribution:
E_{nu_t^o}[R*] - E_{mu_t^o}[R*] >= beta_t(o) > 0则保守更新后有:
E_{mu_{t+1}^o}[R*] >= E_{mu_t^o}[R*] + alpha_t * beta_t(o) - eta_t(o)多轮迭代时,只要累计收益大于累计误差,真实期望 proposal quality 就会提高:
sum_t alpha_t * beta_t(o) > sum_t eta_t(o)这一证明与 CLOVER 的训练设计逐项对应:
Stage 1 通过 evaluator-filtered pseudo-expert coverage 扩展 proposal support,使候选池中存在足够多高质量模式; scorer fitting 使用真实 evaluator 子分数校准 trajectory-level value estimation,使 scorer-selected targets 具备统计富集; generator refinement 只蒸馏 top-k 与 vector-Pareto targets,而不是直接最大化单一 learned scalar score; stability regularization 对应证明中的 eta_t(o),用于限制 student distribution 偏离 teacher distribution 的幅度。
附录还进一步连接了高分区域概率与 Oracle@K。若 K 条候选可以视作从 mu_t^o 中采样,则至少一条候选落入高分区域的概率为:
A_K(p_t) = 1 - (1 - p_t)^K该函数随 p_t 单调增加。因此,当 Stage 2 增加 generator 对高分区域的概率质量时,它不仅提高了平均候选质量,也提高了候选集合中出现高质量轨迹的下界,从而有助于提升 Oracle@K。再结合 scorer refitting 减少 ranking regret,最终 deployed top-1 轨迹也更可能接近 proposal set 中的真实高分模式。
论文进一步在 NAVSIM evaluation PKL 上验证 selected-set enrichment 假设,统计范围为 12,146 个场景、每个场景 64 条候选轨迹。结果显示,最强的 worst-case calibration 条件确实过于保守:在 per-scene elite/reject (0.05/0.05) 协议下,只有 10.64% 的场景满足 gamma_o > 2 epsilon_max,o。但 Stage-2 蒸馏实际需要的是更弱的统计富集条件,而这一条件得到了更充分支持。
在 elite/reject (0.01/0.01) 协议下,分别有 92.50%、82.37% 和 71.56% 的场景满足 gamma_o > 2 epsilon_p75,o、gamma_o > 2 epsilon_p90,o 和 gamma_o > 2 epsilon_p95,o。也就是说,虽然最坏情况校准很难保证,但在高概率分位数意义上,scorer 对高质量候选与低质量候选具有较稳定的区分能力。进一步地,当将真实高分组定义为 R* >= 0.95、低分组定义为 R* <= 0.50 时,pairwise ranking accuracy 达到 94.72%,说明 scorer 通常能够把真实高分轨迹排在低分轨迹之前。
高置信 scorer proposals 的真实质量也明显更高。当预测分数 s >= 0.90 时,真实平均分为 0.9529,且 P(R* >= 0.90)=90.16%;当阈值提高到 s >= 0.95 时,真实平均分进一步达到 0.9753,P(R* >= 0.90)=96.69%,满分比例 P(R*=1)=69.74%。相比之下,整个 proposal pool 的满分 proposal 占比为 35.42%。若以满分区域 H={tau:R*(tau)=1} 作为高分区域,则高置信 scorer-selected proxy 的富集差值为:
q - p = 69.74% - 35.42% = 34.32%这直接对应理论中的 q_t(o) >= p_t(o) + xi_t(o),即 scorer-selected targets 在真实 evaluator 下相对于原 proposal pool 具有显著富集。
Top-k 覆盖结果也支持同一结论。scorer Top-1 的 mean best R* 为 0.9448,oracle gap 为 0.0495;scorer Top-8 的 mean best R* 提升到 0.9656,oracle gap 降至 0.0283;scorer Top-16 的 mean best R* 进一步达到 0.9730,oracle gap 降至 0.0209。随着 target set 变大,真实高分覆盖增强、oracle gap 逐步缩小,说明 Stage 2 并不是依赖单个可能有误差的最高分预测,而是在 scorer 选出的目标集合中获得统计意义上的高质量富集。
因此,论文的实证验证与理论假设形成闭环:Stage 1 提供非零且较充分的高分支持;scorer 在高概率意义上能够区分高低质量候选;高置信与 Top-k scorer-selected targets 在真实 evaluator 下显著富集。CLOVER 的 Stage 2 正是在这样的 proposal space 中,将生成器概率质量重新分配给 evaluator-enriched targets,而不是盲目最大化一个 learned scalar score。
6. 主实验结果
CLOVER 在 NAVSIM v1、NAVSIM v2 EPDMS、NavHard two-stage split 与补充的 nuScenes open-loop evaluation 上进行评估。主结果如下图所示。
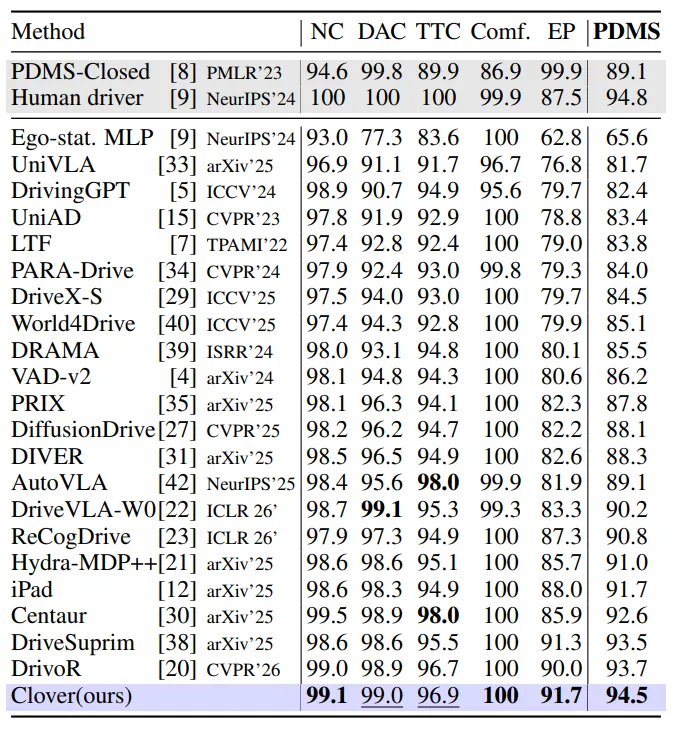
在 NAVSIM v1 上,CLOVER 达到 94.5 PDMS,超过强 generator-scorer baseline DrivoR 的 93.7,并接近 human-driver reference 的 94.8。该结果并非来自单一子指标取巧,CLOVER 在多个子项上均位于第一或第二,显示出整体规划质量的提升。
在 NAVSIM v2 上,CLOVER 使用更新后的官方实现达到 90.4 EPDMS。在更具挑战性的 navhard-two-stage split 上,CLOVER 达到 48.3 EPDMS,匹配当前最强报告结果。补充的 nuScenes open-loop 评测也显示,CLOVER 在 ST-P3 protocol 下达到 0.31 m L2 / 0.10% collision,在 UniAD protocol 下达到 0.65 m L2 / 0.30% collision。
7. 消融实验:候选覆盖与闭环精炼互补
组件消融表明,CLOVER 的两个阶段缺一不可。
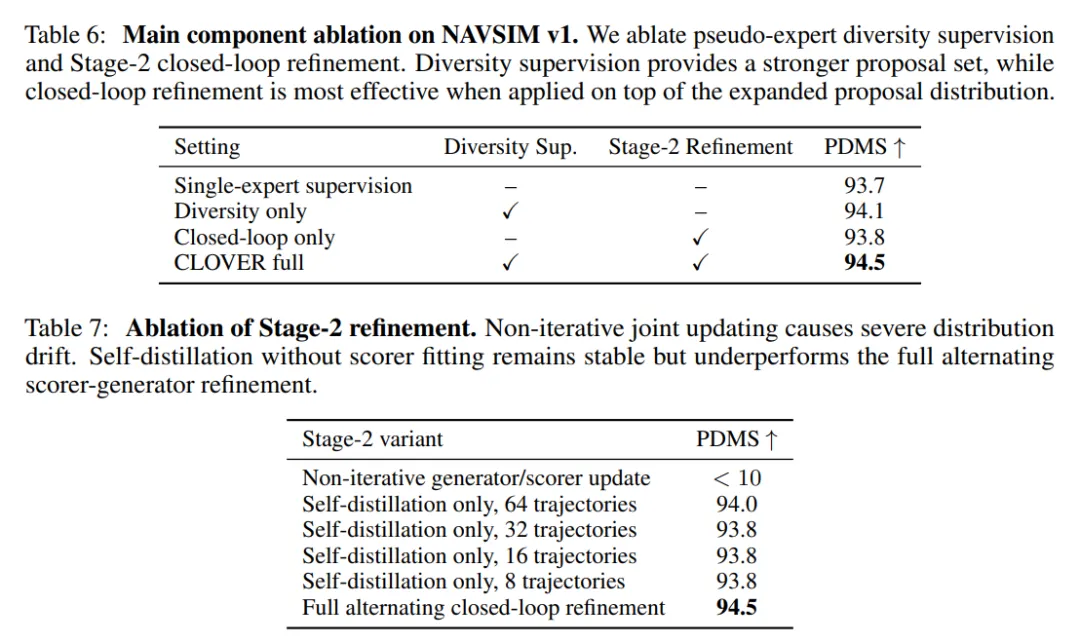
仅加入 diversity supervision 时,PDMS 从 93.7 提升到 94.1,说明更宽的候选支持本身有效。仅做 closed-loop refinement 时,提升较为有限,说明如果 proposal support 不足,scorer 反馈缺少充分发挥空间。完整 CLOVER 同时具备 proposal expansion 与 scorer-guided refinement,因此达到 94.5。
Stage-2 训练策略的消融也支持这一结论。非迭代式 generator/scorer update 会出现严重崩溃,PDMS 低于 10;纯 self-distillation 虽然稳定,但最高约为 94.0;只有 alternating scorer fitting 与 generator refinement 构成完整闭环,才能稳定达到 94.5。
teacher target 的构造同样重要。只使用 scalar top-k 容易集中到较窄的高分模式;加入距离抑制可以部分缓解;vector-Pareto targets 进一步保留多目标权衡,因此同时获得更好的规划分数与更高的高质量候选多样性。
8. Proposal Distribution Analysis
如果一个方法只是更换排序器,而不改变候选集合本身,那么性能收益通常会受到 proposal set 上界限制。CLOVER 的分析显示,闭环训练真正改变了 generator 产生的候选分布。

在共同的 12,146 个 NAVSIM 场景上,对每个场景 64 条候选轨迹进行真实 PDMS 分析,可以观察到清晰的阶段分工。
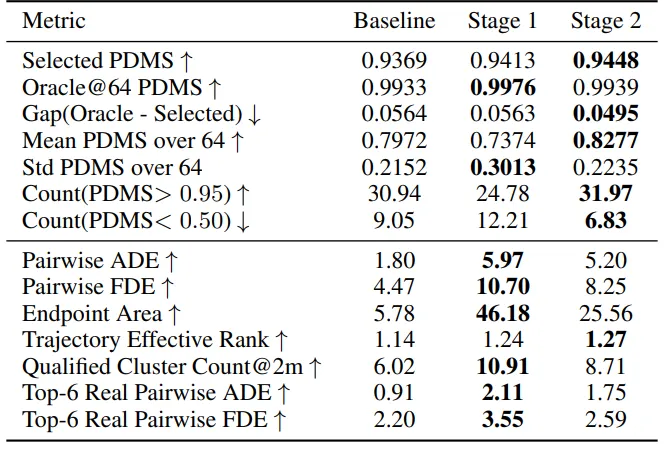
Stage 1 是 expansion stage:它显著提高 Oracle@64 与几何多样性,使模型能够覆盖更丰富的空间与速度模式,但也引入了更多低质量尾部。Stage 2 是 refinement stage:它提升 scorer-selected top-1、提高候选平均质量、减少低分候选,同时保留显著高于 baseline 的多样性。
这说明 CLOVER 的收益并不只是“最后选得更好”,而是来自更强的候选分布:模型生成了更多可评价、可排序且高质量的规划候选。
总结
CLOVER 针对端到端自动驾驶规划中的训练-评测错位,提出了闭环价值估计与排序框架。它通过 evaluator-filtered pseudo-expert trajectories 扩展候选覆盖,再通过 conservative closed-loop self-distillation 将 scorer 反馈用于 generator refinement。
最终,CLOVER 在不增加部署阶段复杂度的前提下,同时改善候选覆盖、候选质量、排序可靠性与最终规划指标。
一句话概括:
CLOVER 的核心不是简单生成更多轨迹,而是让端到端规划形成候选生成、价值估计、排序选择与自我改进的闭环。
公众号后台回复“数据集”获取100+深度学习各方向资源整理
极市干货
点击阅读原文进入CV社区
收获更多技术干货
随机文章
-
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
- 自动驾驶的"E2E 时代"——从Tesla FSD到NVIDIA COSMOS
- 20多万的SUV,谁买谁懂?但这台车,可能只有”自己人”才能驾驭
- 豪华家庭SUV又一力作震撼上市 魏牌 V9X 起售34.98万
- 【交通】上海轨道交通全自动驾驶线路,你乘坐过几条?
- 路虎揽胜:从农场车到豪华SUV,它为什么能一路进化到今天
- 轿车是需求,奥德赛是归宿
- 28.98万起,买奥迪中大型纯电SUV
- 大众旗下全新入门纯电SUV——斯柯达Epiq,全方位解读
- 凯迪拉克DeVille X SUV、福特探险者越野版、道奇Ramcharger:2026年这3台豪华越野,先别急着下单
- 9.98万的半固态纯电SUV,吹爆了,能卖爆吗?
